






Queue——队列
不管学习什么数据类型,它的源码永远是最宝贵的教科书。
定义:队列的定义与栈很相似。队列(简称队)是一种操作受限的线性表,其限制为仅允许在表的一端进行插入,而在另一端进行删除。
通常把进行插入的一端称为队尾(rear),把进行删除的一端称为队头或队首(front)。
向队列中插入的新元素称为进队或入队,新元素进队后就成为新的队尾元素;从队列中删除元素称为出队或离队,出队后,其直接后继元素就称为队首元素。
队列的插入和删除操作分别是在表的一端进行的,每个元素必然按照进入的次序出队,所以又把队列称为先进先出表
其抽象数据类型定义如下:
ADT Queue{
数据对象:
D = {
a
i
a_i
ai | 0
⩽
i
⩽
n
−
1
\leqslant i \leqslant n-1
⩽i⩽n−1,
n
⩾
0
,
a
i
n\geqslant 0,a_i
n⩾0,ai为E类型}
数据关系:
R = {r}
r = {<
a
i
a_i
ai,
a
i
+
1
a_i+1
ai+1> |
a
i
a_i
ai,
a
i
+
1
a_i+1
ai+1
∈
\in
∈D,
i
=
0
i=0
i=0,···,
n
−
2
n-2
n−2}
基本运算:
boolean empty():判断队列是否为空,空则返回真,否则返回假
void push(E e):进队,将元素e进队作为队尾元素
E pop():出队,从队头出队一个元素
E peek():取队头,返回队头元素值但并不出队
}
【例1】若元素进队顺序为1234,能否得到3142的出队序列?
解:不能!进队顺序为1234,则出队顺序只能是1234(先进先出)。
队列的顺序存储结构及其基本运算算法的实现
由于队列中元素的逻辑关系与线性表相同,所以可以借鉴线性表的两种存储结构来存储队列。
当队列采用顺序存储结构存储时,分配一块连续的存储存储空间,用data数组来存放队列中的元素,另外设置两个指针,队头指针(front)和队尾指针(rear)。
为了简单,这里使用固定容量的数组data(容量为常量Max_Size),如下图所示。采用顺序存储结构的队列称为顺序队。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-D3NYdCoN-1691764078352)(数据结构.assets/13a734b085544dffca0cb10886536ae.jpg)]](https://img-blog.csdnimg.cn/6671b1697be64bd780f1e2ed876de9a6.jpeg)
顺序队又分为以下两种
- 非循环队列
- 循环队列
1.非循环队列
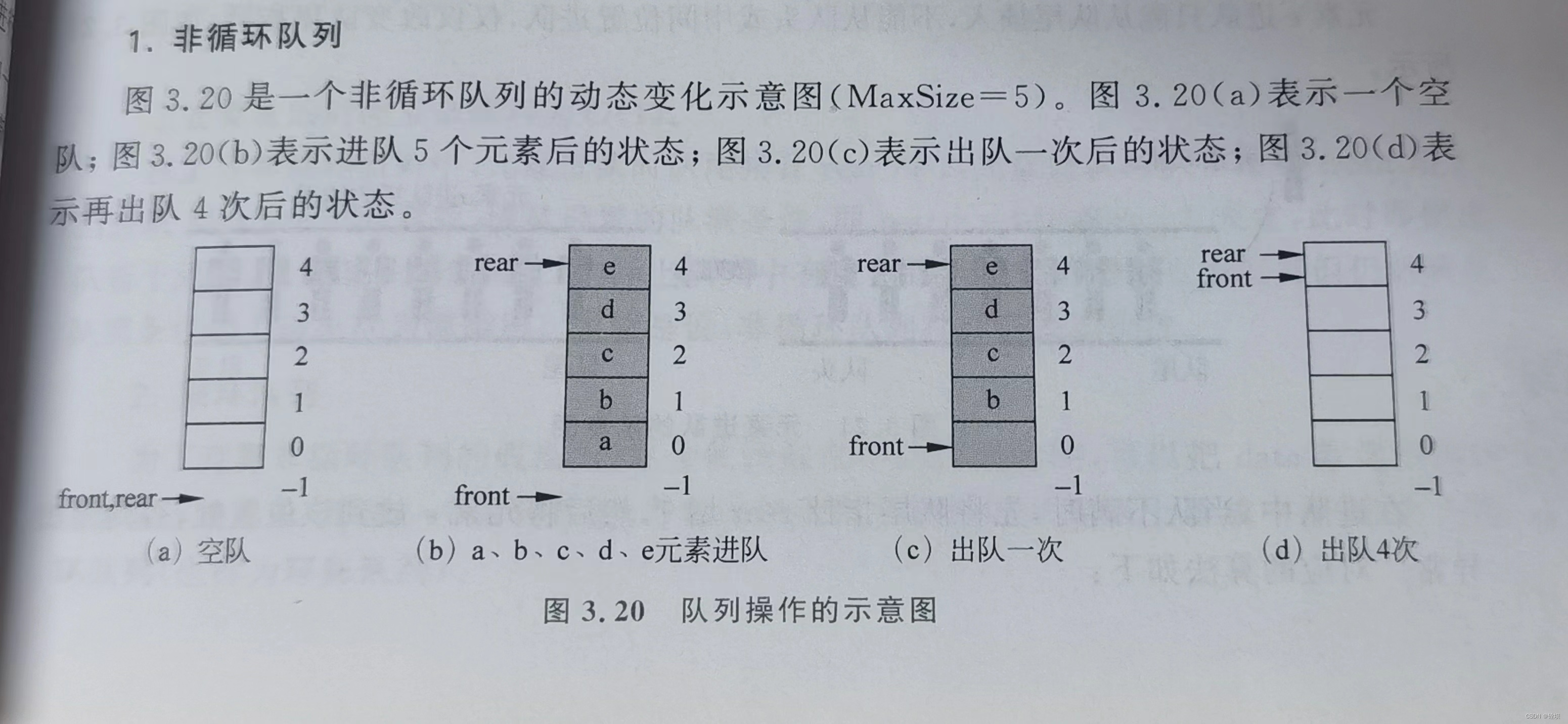
从图中我们可以大致看出非循环队列的四要素:
(1)队空条件为front == rear,上图(a)和(d)满足该条件
(2)队满(队上溢出)的条件为rear == MaxSize - 1(因为每个元素进队都会让rear增加1,当rear达到最大下标时就不能再增加了,上图(c)和(d)满足该条件
(3)元素e进队的操作是先将队尾指针增加1,然后将元素e放在该位置上(进队的元素总是在尾部插入的)
(4)出队的操作是先将队头指针front增加1,然后再取出该位置的元素(出队的元素总是从头部出来的)
说明:为什么让front指向队列中当前队头元素的前一个位置?因为再front增加1后,该位置的元素已经出队(即被删除)了。
非循环队列的泛型类SqQueueClass定义如下:
class SqQueueClass<E> { //非循环队列的泛型类
final int MAX_SIZE = 100; //假设容量为100
private E[] data; //存放队列中的元素
private int front,rear; //队头、队尾指针
public SqQueueClass(){ //构造方法
data = (E[])new Object[MAX_SIZE];
front = -1;
rear = -1;
}
//队列的基本运算算法
/**(1)
* 判断队列是否为空
* 若满足front == rear条件则返回true,否则返回false
* @return
*/
public boolean empty(){
return front == rear;
}
/**(2)
* 元素进队方法
* 在进队时,先判断队列是否已满,不满时,先将队尾指针rear增加1,然后再将元素e放到该位置处
* @param e
*/
public void push(E e){
if (rear == MAX_SIZE)
throw new IllegalArgumentException("队列已满");
rear++;
data[rear] = e;
}
/**(3)
* 出队方法
* 在出队时,先判断队列是否为空,不为空时,先将队头指针加1,并返回该位置的元素值
* @return
*/
public E pop(){
if (empty())
throw new IllegalArgumentException("队列为空");
front++;
return (E)data[front];
}
/**(4)
* 取队头元素方法
* 与出队相似,但并不是删除(出队),使用不需要移动队头指针
* @return
*/
public E peek(){
if (empty())
throw new IllegalArgumentException("队列为空");
return (E)data[front+1];
}
}
2.循环队列
为了克服非循环队列的假溢出,充分使用数组中的存储空间,可以把data数组的前端和后端连接起来,形成一个闭环的循环数组,即把存储队列元素的表从逻辑上看成是一个环,称为循环队列(也称为环形队列)。
一个关键问题——循环队列队空和队满时的判断条件是什么?
还是传统的front == rear?如果进队速度远高于出队速度,那么队尾指针很快就赶上了队头指针,甚至在队满时满足front == rear,所以用这种方法已经无法区分队空和队满了。
实际上循环队列的结构与非循环队列相同,也需要通过front == rear表示队列状态,一般是采用他们的相对值(|front - rear|)实现的。若data数组的容量为m,则队列的状态一共有m+1种,分别是队空、队有1个元素、队有2个元素、……、队有m个元素(队满)。front和rear的取值范围均为0~m-1,这样|front - rear|只有m个值,显然m+1种状态不能直接用|front - rear|区分,因为必定有两种状态不能区分。为此可以让队列种最多只有m-1个元素,这样队列恰只有m种状态,就可以通过front和rear的相对值区分所有状态了。
在规定队列种最多只有m-1个元素时,设置队列为空的条件仍然是front == rear。当队列有m-1个元素时,必有(rear+1) % MAX_SIEZE == front(相当于试探性进队一次,若rear达到(追上)front,则认为队满了)。
因此循环队列的四要素总结如下:
(1)队空条件为 rear == front
(2)队满条件为 (rear + 1) % MAX_SIZE == front
(3)元素e进队时, rear = (rear+1) % MAX_SIZE,将元素e放置在该位置
(4)元素出队时, front = (front + 1) % MAX_SIZE,取出该元素位置
下图说明了循环队列的几种状态,这里假设MAX_SIZE = 5![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KVoiBcok-1691764078353)(数据结构.assets/6742bd5ec56343d7db1761c1de005e1.jpg)]](https://img-blog.csdnimg.cn/3446f55eda174284a5c121917ea59d94.jpeg)
循环队列的泛型类CSqQueueClass定义如下:
//与非循环队列相比其实改动很小,主要体现在%的使用,使用%能够才能够体现处循环所在
class CSqQueueClass<E>{ //循环队列泛型类
final int MAX_SIZE = 100; //假设容量为100
private E[] data; //存放队列种元素数组
private int front,rear; //队头队尾指针
public CSqQueueClass(){ //构造方法,做一些初始化操作
data = (E[])new Object[MAX_SIZE];
front = 0;
rear = 0;
}
/**(1)
* 判断队列是否为空
* 若满足front == rear条件则返回true,否则返回false
* @return
*/
public boolean empty(){
return front == rear;
}
/**(2)
* 元素进队方法
* 在进队时,先判断队列是否已满,不满时,先将队尾指针rear增加1,然后再将元素e放到该位置处
* @param e
*/
public void push(E e){
if ((rear+1) % MAX_SIZE == front)
throw new IllegalArgumentException("队列已满");
rear = (rear+1) % MAX_SIZE;
data[rear] = e;
}
/**(3)
* 出队方法
* 在出队时,先判断队列是否为空,不为空时,先将队头指针加1,并返回该位置的元素值
* @return
*/
public E pop(){
if (empty())
throw new IllegalArgumentException("队列为空");
front = (front+1) % MAX_SIZE;
return (E)data[front];
}
/**(4)
* 取队头元素方法
* 与出队相似,但并不是删除(出队),使用不需要移动队头指针
* @return
*/
public E peek(){
if (empty())
throw new IllegalArgumentException("队列为空");
return (E)data[(front+1) % MAX_SIZE];
}
}
循环队列的应用算法设计
【例1】在循环队列泛型类CSQueueClass中增加一个求元素个数的算法size()。对于一个整数循环队列qu,利用前面出现的队列基本运算和size()算法设计进队和出队第k( k ⩾ 1 k\geqslant1 k⩾1),队头元素序号为1)个元素的算法
解:第一步:对于前面的循环队列,队头指针指向队中队头元素的前一个位置,队尾指针指向队中队尾元素,可以求出队中元素个数=| rear - |front-1| + 1 | = | rear - |front-1+1| | = | rear - front |,如果不想用MATH.abs可以 = (rear - front + MAX_SIZE) % MAX_SIZE,至于为什么用分配律拆开就知道了。
因此size()算法如下:
public int size(){ //返回队中元素个数
return (rear - front + MAX_SIZE) % MAX_SIZE;
}
第二步:出队第k( k ⩾ 1 k\geqslant1 k⩾1)个元素e的算法思路时出队前k-1个元素,并且边出边进,直到出队第k个元素e,使其不进队,为了不干扰原来的队列顺序,剩下的元素要完成边出边进的操作。算法如下:
public static Integer popk(CSqQueueClass<Integer> qu, int k){
Integer temp, e = 0;
int size = qu.size();
if(k<1 || k>n)
throw new IllegalArgumentException("参数错误");
for(int i = 1;i <= n;i++){ //循环处理队列中所有元素
temp = qu.pop(); //出队元素temp
if(i!=k)
qu.push(temp); //将非第k个元素进队
else e = temp; //取第k个出队的元素
}
return e;
}
【例2】对于循环队列来说,如果知道队头指针和元素个数,则可以通过它们计算出队尾指针,也就是说可用用队中元素个数代替队尾指针。设计出这种循环队列的判断空、进队、出队和取队头元素的算法。
解:本例的循环队列包含data数组、队头指针front和队中元素个数count。初始时front = count = 0。队空条件为count == 0;队满条件为count == MAX_SIZE;元素e进栈操作是先根据队头指针和元素个数求出队尾指针rear,将rear循环增1,然后将元素1放在rear处;出队操作是先将队头指针循环增1,然后取出该位置的元素。设计对应的循环队列泛型类CSqQueueClass如下
class CSqQueueClass<E>{
final int MAX_SIZE;
private E[] data;
private int count;
public CSqQueueClass(){
data = (E[])new Object[MAX_SIZE];
front = 0; //队头指针
count = 0; //元素个数
}
public boolean empty(){ //判断是否为空
return count == 0;
}
public void push(E e){ //元素e进队
int rear;
rear = (front + count) % MAX_SIZE;
if(count == MAX_SIZE)
throw new IllegalArgumentException("队列已满");
rear = (rear + 1) % MAX_SIZE;
data[rear] = e;
count++;
}
public E pop(){ //出队元素
if(empty())
throw new IllegalArgumentException("队列为空");
count--;
front = (front + 1) % MAX_SIZE;
return (E)data[front];
}
public E peek(){ //取队头元素
if(empty())
throw new IllegalArgumentException("队列为空");
return (E)data[(front + 1) % MAX_SIZE];
}
}
说明:本队列设计的循环队列中最多可保存MAX_SIZE个元素。
从上述循环队列的设计可用看出,如果将data数组的容量改为可用拓展的,新建更大容量的数组newdata后,不能像顺序表、顺序栈那样简单地将data中的元素复制到newdata中,需要按队列操作,将data中所有元素出队后进队到newdata中,这里不再详述。
总结:
对于队列的运算操作,我们要熟悉那四项基本操作:空、进、出、取。所有的操作都是在这四则基本算法的基础上进行拓展的,还要知道循环所要用到的核心运算符——%是如何使用的。















 550
550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









