







目录
第一章 引言
编译过程和编译程序的结构
编译过程:
含义一:将源程序转换为目标程序的各个步骤
源程序->(编译器)->目标文件
源程序->(编译器) ->汇编语言程序->(汇编器)->目标文件
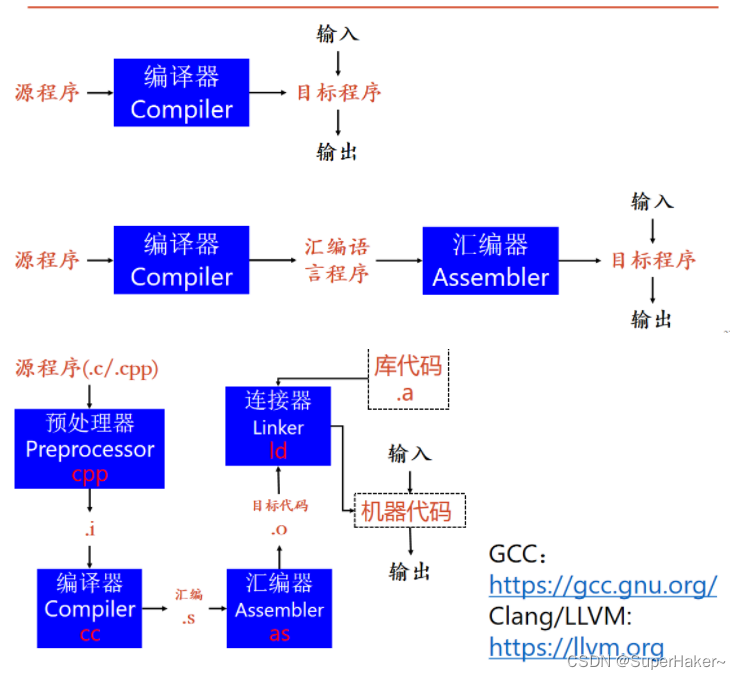
对于具体的语言,比如C,会有预处理和链接。c语言提供的编译预处理功能主要有三种:宏定义、文件包含和条件编译。对源程序正式编译前由预处理程序完成的。预处理之后的文件.i结尾。连接过程将多个目标文以及所需的库文件(.so等)链接成最终的可执行文件(executable file)。具体的c语言编译过程可以看这篇文章
含义二:将源程序转换为目标程序各阶段
| 计算机语言编译阶段 | 自然语言翻译阶段 |
|---|---|
| 1. 词法分析 | 1. 词汇学习 |
| 2. 语法分析 | 2. 句子结构分析 |
| 3. 语义分析 | 3. 句义分析 |
| 4. 中间代码生成 | 4. 译文草稿 |
| 5. 代码优化 | 5. 译文修饰 |
| 6. 目标代码生成 | 6. 译文定稿 |
编译程序结构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yuzMz1NF-1686813309918)(file://C:\Users\27796\AppData\Roaming\marktext\images\2023-06-15-14-44-53-image.png?msec=1686811493345)]](https://img-blog.csdnimg.cn/61e05fea94f044e485a5743a75a3730e.png)
各阶段的任务
词法分析:
从左至右扫描字符流的源程序、分解构成源程序的字符串,识别出(拼)一个个的单词(Token/word)。两个字:分词。
Token分以下几类 :变量是标识符,数值为相应的数值类型,保留字为关键字,运算符,界符
①字面量(literal):3 ‘Hello,world’
②保留字(reserved word): if while
③标识符(identifier): 字母打头,后跟字母,数字等
④运算符(operater): + - < <= &&
⑤界符等类型: , ; ( ) [ ] { } .
词法分析的结果是二元组:(token的类型, token的值),
double f = sqrt(-1);
(1)保留字 double
(2)标识符 f
(3)赋值号 =
(4)标识符 sqrt
(5)左小括号 (
(6)单目负号 -
(7)整型常数 1
(8)右小括号 )
(9)分号 ;
词法分析的过程,其实就是对一个字符串进行模式匹配的过程.联想正则表达式
int foot (int a) {
int b = a + 3;
return b;
}
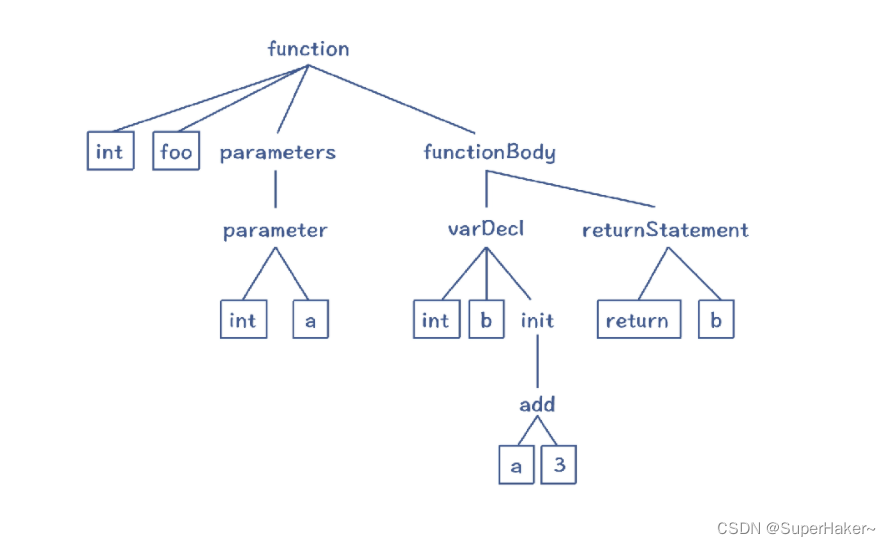
语法分析
把 Token 串,转换成体现语法规则的、树状的数据结构,这个数据结构叫做抽象语法树
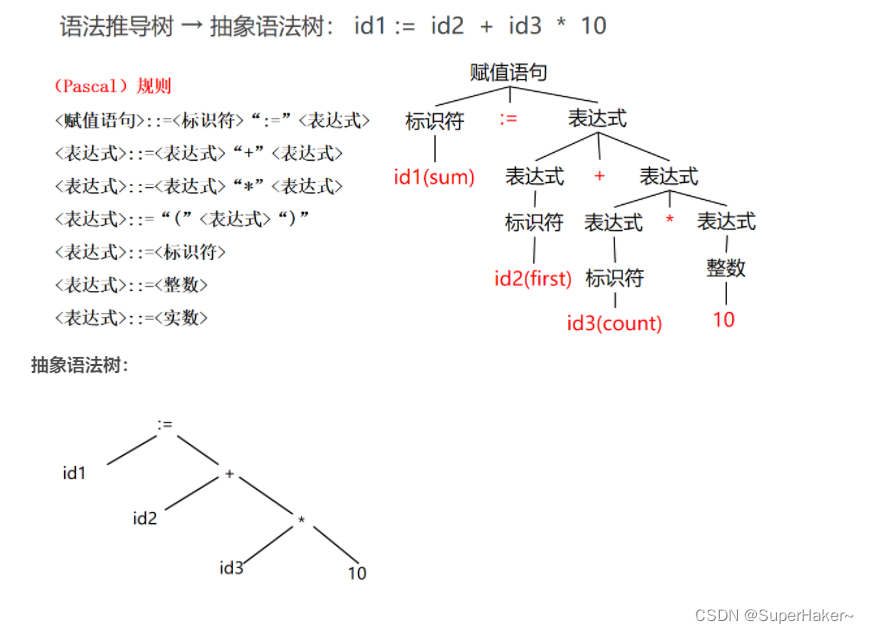
语义分析 根据语法树,深度遍历AST
语法分析的任务是判断源程序在结构上是否正确,是上下文无关的;
语义分析的任务是判断结构正确的源程序所表达的意义是否正确,是上下文有关的。(程序解析和人理解的出入)
根据语义分析,将复杂语句解析为多条简单的语句
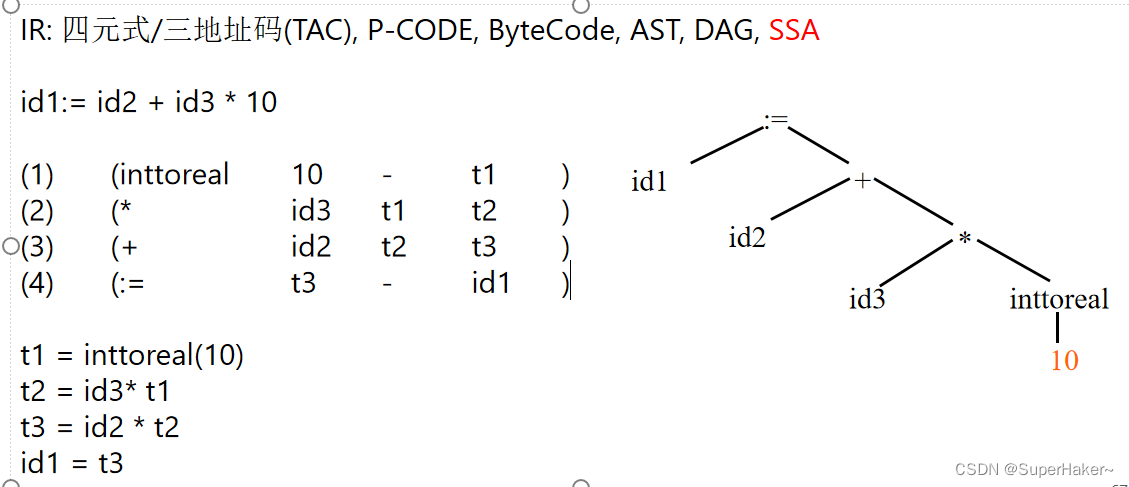
代码优化
删除不必要的,替换效率低的
目标代码生成
- 选择合适的指令,生成性能最高的代码。
- 优化寄存器的分配,让频繁访问的变量(比如循环变量)放到寄存器里,因为访问寄存器要比访问内存快 100 倍左右。
- 在不改变运行结果的情况下,对指令做重新排序,从而充分运用 CPU 内部的多个功能部件的并行计算能力。
符号表管理
符号表管理
- 记录源程序中使用的各种符号名称,
- 收集符号的属性信息,类型、作用域、分配存储信息
- 登录:扫描到说明语句就将标识符登记在符号表中
- 查找:在执行语句查找标识符的属性,判断语义是否正确
出错管理
错误处理
- 报告出错信息,排错
- 恢复编译工作
阶段的组合:前后端划分的意义
前端主要由与源程序有关但与目标机无关的那些部分组成。这些部分通常包括词法分析、语法分析、语义分析与中间代码的产生,有些代码优化工作也可包括在前端。后端包括编译程序中与目标机有关的那些部分,如与目标机有关的代码优化和目标机的生成等。
将编译过程划分成前端和后端,主要目的是在多种源语言和多种目标语言的开发过程中,可以灵活搭配组合,消除重复开发的工作量,提高编译系统的开发效率。
编译和解释的区别?(AOT/JIT)
编译: 先翻译后执行,保存目标程序, 一次翻译, 多次执行。
解释: 边翻译边执行,即翻译一句就执行一句,翻译完毕也执行完毕,只保存源程序无需保存完整的目标程序。执行一次需要翻译一次。
编译型的语言包括:C、C++、Delphi、Pascal、Fortran
解释型的语言包括:Java、Basic、javascript、python
题目
各种概念的考察,词法语法语义分析区分
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











