










昨天写完视觉论文之后(嵌入式设备中的视觉识别项目),就在考虑要不要把识别的一些源码放出来,因为感觉没事的时候识别一下还蛮有意思的,也可以给想做视觉相关东西的同学们一点思路。
所以这篇文章就是来论述一下自己检测识别人脸的原理,放些实时检测的源码可以用来日常玩耍~
注:答主是准大三学生,视觉方面纯粹是自学的,与此同时也借鉴了很多网上的帖子,在此感谢各路大神,如果有什么觉得可以改进的地方也可以在评论区里提出
关于检测人脸
我使用了opencv自带的人脸级联分类器,识别出人的脸部,眼睛和嘴部,因为人脸级联分类器中自带微笑级联分类器,所以顺带着完成了微笑识别的任务,并在框上标出
如果只是检测到人脸和眼睛:
import cv2
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
# 调用摄像头摄像头
cap = cv2.VideoCapture(0)
while (True):
# 获取摄像头拍摄到的画面
ret, frame = cap.read()
faces = face_cascade.detectMultiScale(frame, 1.3, 5)
img = frame
for (x, y, w, h) in faces:
# 画出人脸框,蓝色,画笔宽度微
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源
face_area = img[y:y + h, x:x + w]
eyes = eye_cascade.detectMultiScale(face_area)
# 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
for (ex, ey, ew, eh) in eyes:
# 画出人眼框,绿色,画笔宽度为1
cv2.rectangle(face_area, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 1)
# 实时展示效果画面
cv2.imshow('frame2', img)
# 每5毫秒监听一次键盘动作
if cv2.waitKey(5) & 0xFF == ord('q'):
break
# 最后,关闭所有窗口
cap.release()
cv2.destroyAllWindows()如果想检测到人脸是否在微笑:
import cv2
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
smile_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_smile.xml')
# 调用摄像头摄像头
cap = cv2.VideoCapture(0)
while (True):
# 获取摄像头拍摄到的画面
ret, frame = cap.read()
faces = face_cascade.detectMultiScale(frame, 1.3, 2)
img = frame
for (x, y, w, h) in faces:
# 画出人脸框,蓝色,画笔宽度微
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源
face_area = img[y:y + h, x:x + w]
## 人眼检测
# 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
eyes = eye_cascade.detectMultiScale(face_area, 1.3, 10)
for (ex, ey, ew, eh) in eyes:
# 画出人眼框,绿色,画笔宽度为1
cv2.rectangle(face_area, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 1)
## 微笑检测
# 用微笑级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
smiles = smile_cascade.detectMultiScale(face_area, scaleFactor=1.16, minNeighbors=65, minSize=(25, 25),
flags=cv2.CASCADE_SCALE_IMAGE)
for (ex, ey, ew, eh) in smiles:
# 画出微笑框,红色(BGR色彩体系),画笔宽度为1
cv2.rectangle(face_area, (ex, ey), (ex + ew, ey + eh), (0, 0, 255), 1)
cv2.putText(img, 'Smile', (x, y - 6), 3, 1.2, (0, 0, 255), 2, cv2.LINE_AA)
# 实时展示效果画面
cv2.imshow('frame2', img)
# 每5毫秒监听一次键盘动作
if cv2.waitKey(5) & 0xFF == ord('q'):
break
# 最后,关闭所有窗口
cap.release()
cv2.destroyAllWindows()
效果其实还挺好的:

摁q键即可退出人脸检测
关于识别人脸身份
我用的是基于lbph的人脸识别算法
一开始是想把图片转化成数组之后形成yml文件之后训练,最后识别人脸,但发现这样识别的话因为自己收集的图片过少,形成数据量少,置信度会比较高(60多),如果混杂很多张人脸识别的时候识别会不准确(自己采用了一个人脸识别的数据集混合识别多张人脸),感觉不太满意
所以最后还是选择了将图像直接带入训练,最后识别人脸(我的代号是Maintain,维修人员):
首先,关于获取人脸图像
我们利用级联分类器上面对人脸画框的方式,将框内的人脸照片保留下来,按k键保存照片:
import cv2
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
# 调用摄像头摄像头
cap = cv2.VideoCapture(0)
while (True):
# 获取摄像头拍摄到的画面
ret, frame = cap.read()
faces = face_cascade.detectMultiScale(frame, 1.3, 5)
img = frame
for (x, y, w, h) in faces:
# 画出人脸框,蓝色,画笔宽度微
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源
face_area = img[y:y + h, x:x + w]
eyes = eye_cascade.detectMultiScale(face_area)
# 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
for (ex, ey, ew, eh) in eyes:
# 画出人眼框,绿色,画笔宽度为1
cv2.rectangle(face_area, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 1)
k = cv2.waitKey(100)
if k == ord("z") or k == ord("Z"): # 如果输入z
# 将当前帧保存为图片
img_name = "enlian7.jpg"
print(img_name)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image, [int(cv2.IMWRITE_PNG_COMPRESSION), 9])
break
# 实时展示效果画面
cv2.imshow('frame2', img)
# 每5毫秒监听一次键盘动作
if cv2.waitKey(5) & 0xFF == ord('q'):
break
# 最后,关闭所有窗口
cap.release()
cv2.destroyAllWindows()其次,关于人脸身份识别
在保存七张照片后,我们对人脸进行训练和识别
我们将这七张照片带入程序进行训练,并通过摄像头读取人脸,识别人脸身份
这里需要注意:
我们需要筛选出来一个灰色通道作为感兴趣区域进行预测,程序才可以运行
import cv2
import numpy as np
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_eye.xml')
# 调用摄像头摄像头
cap = cv2.VideoCapture(0)
images=[]
images.append(cv2.imread('D:\PycharmProjects\shijuecv\enlian\enlian1.jpg',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('D:\PycharmProjects\shijuecv\enlian\enlian2.jpg',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('D:\PycharmProjects\shijuecv\enlian\enlian3.jpg',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('D:\PycharmProjects\shijuecv\enlian\enlian4.jpg',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('D:\PycharmProjects\shijuecv\enlian\enlian5.jpg',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('D:\PycharmProjects\shijuecv\enlian\enlian6.jpg',cv2.IMREAD_GRAYSCALE))
images.append(cv2.imread('D:\PycharmProjects\shijuecv\enlian\enlian7.jpg',cv2.IMREAD_GRAYSCALE))
labels=[3,3,3,3,3,3,3]
recognizer=cv2.face.LBPHFaceRecognizer_create()
recognizer.train(images,np.array(labels))
while (True):
# 获取摄像头拍摄到的画面
ret, frame = cap.read()
faces = face_cascade.detectMultiScale(frame, 1.3, 5)
img = frame
for (x, y, w, h) in faces:
# 画出人脸框,蓝色,画笔宽度微
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
# 框选出人脸区域,在人脸区域而不是全图中进行人眼检测,节省计算资源
face_area = gray[y:y + h, x:x + w]
eyes = eye_cascade.detectMultiScale(face_area)
# 用人眼级联分类器引擎在人脸区域进行人眼识别,返回的eyes为眼睛坐标列表
for (ex, ey, ew, eh) in eyes:
# 画出人眼框,绿色,画笔宽度为1
cv2.rectangle(face_area, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 1)
label, confidence = recognizer.predict(face_area)
print('label=', label)
print('confidence=', confidence)
if label == 3:
print("这个人是维修人员")
cv2.putText(img, 'Maintain', (x, y - 6), 3, 1.2, (0, 0, 255), 2, cv2.LINE_AA)
# 实时展示效果画面
cv2.imshow('frame2', img)
# 每5毫秒监听一次键盘动作
if cv2.waitKey(5) & 0xFF == ord('q'):
break
# 最后,关闭所有窗口
cap.release()
cv2.destroyAllWindows()效果是这样的:

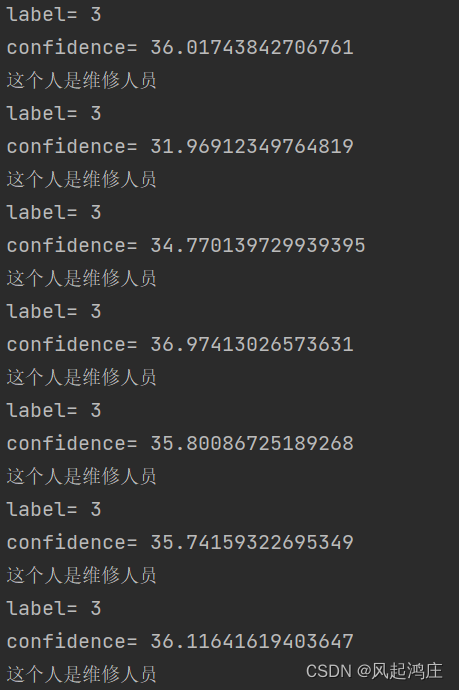
ok,效果良好,谢谢大家
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









