







之前打下了理论基础,现在才是开始学习构建实际服务器的知识。
0.1 进程概念及应用
利用之前学习到的内容,我们可以构建按序向第一个客户端到第一百个客户端提供服务的服务器端。当然,第一个客户端不会抱怨服务器端,但如果每个客户端的平均服务时间为0.5秒,则第100个客户端会对服务器端产生相当大的不满。
并发服务器端的实现方法
即使有可能延长服务时间,也有必要改进服务器端,使其同时向所有发起请求的客户端提供服务,以提高平均满意度。而且网络程序中数据通信时间比CPU运算时间占比更大,因此,向多个客户端提供服务是一种有效利用CPU的方式。接下来讨论同时向多个客户端提供服务的并发服务器端。下面列出的是具有代表性的并发服务器端实现模型和方法。
1️⃣ 多进程服务器:通过创建多个进程提供服务。
2️⃣ 多路复用服务器:通过捆绑并同一管理I/O对象提供服务。
3️⃣ 多线程服务器:通过生成与客户端等量的线程提供服务。
先讲解第一种方法:多进程服务器。这种方法不适合在Windows平台下讲解,因此将重点放在Linux平台。若各位不太关心基于Linix的实现,可以直接跳到第12章。
接下来了解多进程服务器实现的重点内容——进程,其定义如下:
“占用内存空间的正在运行的程序”
假设各位需要进行文档相关操作,这时应打开文档编辑软件。如果工作的同时还想听音乐,应打开MP3播放器。另外,为了与朋友聊天,在打开MSN软件。此时共创建了3个进程。从操作系统的角度看,进程是程序流的基本单位,若创建多个进程,则操作系统将同时运行。有时一个程序运行过程中也会产生多个进程。接下来要创建多进程服务器就是其中的代表。编写服务器端前,先了解一下通过程序创建进程的方法。
CPU核的个数与进程数
拥有2个运算设备的CPU称作双核(Daul)CPU,拥有4个运算器的CPU称作4核(Quad)CPU。也就是说,1个CPU中可能包含多个运算设备(核)。核的个数与可同时运行的进程数相同。相反,若进程数超过核数,进程将分时使用CPU资源。但因为CPU运转速度极快,我们会感到所有进程同时运行。当然,核数越多,这种感觉越明显。
进程ID
讲解创建进程方法前,先简要说明进程ID。无论进程是如何创建的,所有进程都会从操作系统分配到ID。此ID称为"进程ID",其值为大于2的整数。1要分配给操作系统启动后的(用于协助操作系统)首个进程,因此用户进程就无法得到ID值1.接下来观察Linux中正在运行的进程。
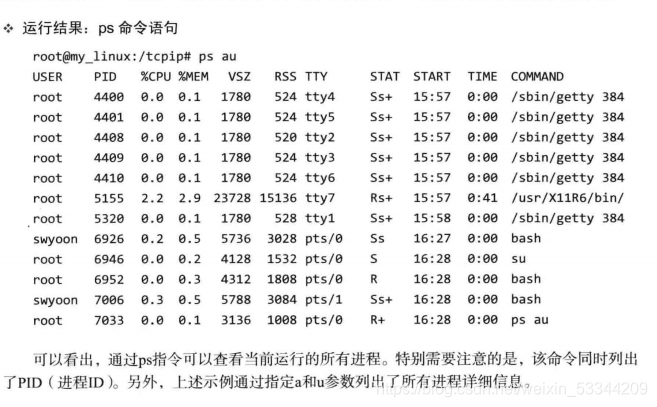
通过调用fork函数创建进程
创建进程的方法很多,此处只介绍用于创建多进程服务器端的fork函数。
#include <unistd.h>
pid_t fork(void);
/* 成功时返回进程ID,失败时返回-1 */
fork函数将创建调用的进程副本(概念上略难)。也就是说,并非根据完全不同的程序创建进程,而是复制正在运行的、调用fork函数的进程。另外,两个进程都将执行fork函数调用后的语句(准确地说是在fork函数返回后)。但因为通过同一个进程、赋值相同的内存空间,之后的程序流要根据fork函数的返回值加以区分。即利用fork函数的如下特点区分程序执行流程。
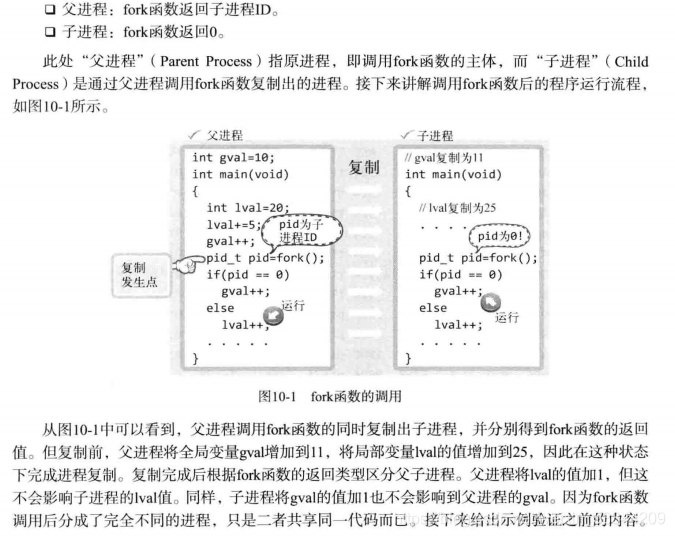
2 进程和僵尸进程
文件操作中,关闭文件和打开文件同等重要。同样,进程销毁也和进程创建同样重要。如果未认真对待进程销毁,它们将编程僵尸进程困扰各位。大家可能觉得这是在开玩笑,但事实的确如此。
僵尸(Zombie)进程
进程完成工作后(执行完main函数中的程序后)应被销毁,但有时这些进程将变成僵尸进程,占用系统中的重要资源。这种状态下的进程称作"僵尸进程",这也是给系统带来负担的原因之一。
产生僵尸进程的原因
为了防止僵尸进程的产生,先解释产生僵尸进程的原因。利用如下两个示例展示调用fork函数产生子进程的终止方式。
1️⃣ 传递参数并调用exit函数
2️⃣ main函数中执行return语句并返回值
向exit函数传递的参数值和mian函数的return语句返回的值都会传递给操作系统。而操作系统不会销毁子进程,直到把这些值传递给产生子进程的父进程。处在这种状态下的进程就是僵尸进程。也就是说,将子进程变成僵尸进程的正是操作系统。既然如此,此僵尸进程何时被销毁呢?其实已经给出提示。
“应该向创建子进程的父进程传递子进程的exit参数值或return语句的返回值。”
如何向父进程传递这些值呢?操作系统不会主动把这些值传递给父进程。只有父进程会主动发起请求(函数调用)时,操作系统才会传递该值。换言之,如果父进程未主动要求获得子进程的结束状态值,操作系统将一直保存,并让子进程长时间处于僵尸进程状态。接下来的示例将创建僵尸进程。
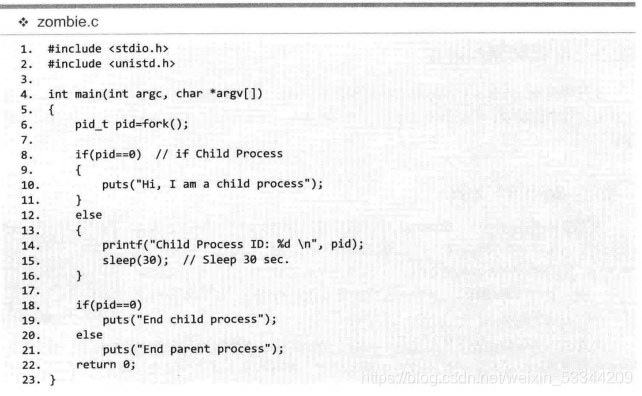

销毁僵尸进程1:利用wait函数
如前所述,为了销毁子进程,父进程应主动请求获取子进程的返回值。接下来讨论发起请求的具体方法(非常简单),共两种,其中之一就是调用如下函数。
#include <sys/wait.h>
pid_t wait(int *statloc);
/* 成功时返回终止的子进程ID,失败时返回-1 */
调用此函数时如果已有子进程终止,那么子进程终止时传递的返回值将保存到该函数的参数所指内存空间。但函数参数指向的单元中还包含其他信息,因此需要通过下列宏进行分离。
1️⃣ WIFEXITED 子进程正常终止时返回"真"(true)。
2️⃣ WEXITSTATUS 返回子进程的返回值。
也就是说,向wait函数传递变量status的地址时,调用wait函数后应编写如下代码。
if (WIFEXITED(status)) // 是正常终止的嘛?
{
puts("Normal termination!");
printf("Child pass num: %d", WEXITSTATUS(status)); // 那么返回值是多少?
}
根据上述内容编写示例,此示例中不会再让子进程编程僵尸进程。


销毁僵尸进程2:使用waitpid函数
wait函数会引起程序阻塞,还可以考虑调用waitpid函数。这是防止僵尸进程的第二种方法,也是放置阻塞的方法。
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *statloc, int options);
/*
* 成功时返回终止的子进程ID(或0),失败时返回-1
* pid 等待终止的目标子进程的ID,若传递-1,则与wait函数相同,可以等待任意子进程终止
* statloc 与wait函数的statloc参数具有相同含义
* options 传递头文件sys/wait.h中声明的常量WNOHANG,即使没有终止的子进程也不会进入阻塞状态,而是返回0并退出函数。
*/
下面介绍调用上述函数的示例。调用waitpid函数,程序不会阻塞。各位应重点观察这点。


3 信号处理
我们已经知道了进程创建及销毁方法,但还有一个问题没有解决。
“子进程究竟何时终止?调用waitpid函数后要无休止地等待嘛?”
父进程往往与子进程一样繁忙,因此不能只调用waitpid函数以等待子进程终止。接下来讨论解决方案。
向操作系统协助
子进程终止的识别主体是操作系统,因此,若操作系统能把如下信息告诉正在忙于工作的父进程,将有助于构建高效的程序。
“嘿,父进程!你创建的子进程终止了!”
此时父进程将暂时放下工作,处理子进程终止相关事宜。这是不是既合理又很酷的想法呢?为了实现该想法,我们引入信号处理(Signal Handing)机制。此处的"信号"是在特定事件发生时由操作系统向进程发送的消息。另外,为了响应该消息,执行与消息相关的自定义操作的过程称为"处理"或"信号处理"。关于这两点稍后将再次说明,各位现在不用完全理解这节概念。
信号与signal函数
下列进程和操作系统间的对话是帮助大家理解信号处理而编写的,其中包含了所有信号处理相关内容。
1️⃣ 进程:“嘿,操作系统!如果我之前创建的子进程终止,就帮我调用zombie_handler函数。”
2️⃣ 操作系统:“好的!如果你的子进程终止,我就帮你调用zombie_handler函数,你先把该函数要执行的语句编好!”
上述对话中进程所讲的相当于"注册信号"过程,即进程发现自己的子进程结束时,请求操作系统调用特定函数。该请求通过如下函数调用完成(因此称此函数为信号注册函数)。
#include <signal.h>
void (*signal(int signo, void (*func)(int)))(int);
/* 为了在产生信号时调用,返回之前注册的函数指针 */
上述函数的返回值类型为函数指针。因此函数声明有些繁琐。现在为了便于讲解,我将上述函数声明整理如下。
1️⃣ 函数名:signal
2️⃣ 参数:int signo, void (*func)(int)
3️⃣ 返回类型:参数为int型。返回void型函数指针
调用上述函数时,第一个参数为特殊情况信息,第二个参数为特殊情况下将要调用的函数的地址值(指针)。发生第一个参数代表的情况时,调用第二个参数所指的函数。下面给出可以在signal函数中注册的部分特殊情况和对应的常数。
1️⃣ SIGALRM:已到通过调用alarm函数注册的时间。
2️⃣ SIGINT:输入CTRL+C。
3️⃣ SIGCHLD:子进程终止。
接下来编写调用signal函数的语句完成如下请求:
“子进程终止则调用mychild函数。”
此时mychild函数的参数应为int,返回类型应为void。只有这样才能称为signal函数的第二个参数。另外,常数SIGCHLD定义了子进程终止的情况,应称为signal函数的第一个参数。也就是说,signal函数调用语句如下。
signal(SIGCHLD, mychild)
接下来编写signal函数的调用语句,分别完成如下2个请求。
“已到通过alarm函数注册的时间,请调用timeout函数”
“输入CTRL+C时调用keycontrol函数。”
代表这2中情况的常数分别为SIGALRM和SIGINT,因此按如下方式调用signal函数。
signal(SIGALRM, timeout);
signal(SIGINT, keycontrol);
以上就是信号注册过程。注册好信号后,发生注册信号时(注册的情况发生时),操作系统将调用该信号对应的函数。下面通过示例验证,先介绍alarm函数。
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
/* 返回或以秒为单位的距SIGALRM信号发生所剩时间 */
如果调用该函数的同时向它传递一个正整型参数,相应时间后(以秒为单位)将产生SIGALRM信号。若向该函数传递0,则之前对SIGALRM信号的预约将取消。如果通过该函数预约信号后未指定该信号对应的处理函数,则(通过调用signal函数)终止进程,不做任何处理。希望引起注意。
接下来给出信号处理相关示例,希望各位通过该示例彻底掌握之前的内容。





4 基于多任务的并发服务器
我们已做好了利用fork函数编写并发服务器的准备,现在可以开始编写像样的服务器端了。
基于进程的并发服务器模型
之前的回声服务器端每次只能向1个客户端提供服务。因此,我们将扩展回声服务器端,使其可以同时向多个客户端提供服务。图10-2给出了基于多进程的并发回声服务器端的实现模型。
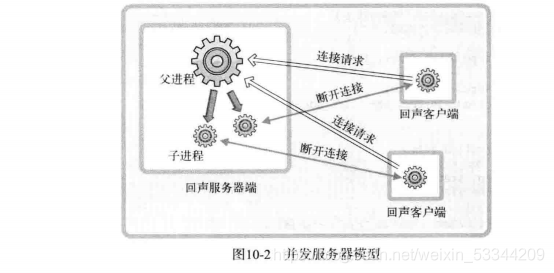
从图10-2可以看出,每当有客户端请求服务(连接请求)时,回声服务器端都创建子进程以提供服务。请求服务的客户端若有5个,则将创建5个子进程提供服务。为了完成这些任务,需要经过如下过程,这是与之前的回声服务器端的区别所在。
1️⃣ 第一阶段:回声服务器端(父进程)通过调用accept函数受理连接请求。
2️⃣ 第二阶段:此时获取的套接字文件描述符创建并传递给子进程。
3️⃣ 第三阶段:子进程利用传递来的文件描述符提供服务。
此处容易引起困惑的是向子进程传递套接字文件描述符的方法。但各位读完代码后会发现,这其实没什么大不了的,因为子进程会复制父进程拥有的所有资源。实际上根本不用另外经过传递文件描述符的过程。
实现并发服务器
虽然我已经给出了所有理论说明,但大家业余还没相处具体的实现方法,这就有必要理解具体代码。下面给出并发回声服务器端的实现代码。当然,程序是基于多进程实现的,可以结合第4章的回声客户端运行。




5 分隔TCP的I/O程序
各位应该已经理解fork函数相关的所有有用内容。下面以此为基础,在讨论客户端中分隔I/O程序(Routine)的方法。内容非常简单,大家不必有负担。
分隔I/O程序的优点
我们已实现的回声客户端的数据回声方式如下:
“向服务器端传输数据,并等待服务器端回复。无条件等待,直到接收完服务器端的回声数据后,才能传输下一批数据。”
传输数据后需要等待服务器端返回的数据,因为程序代码中重复调用了read函数和write函数。只能这么写的原因之一是,程序在1个程序中运行。但现在可以创建多个进程,因此可以分隔数据收发过程。默认的分隔模型如图10-5所示。
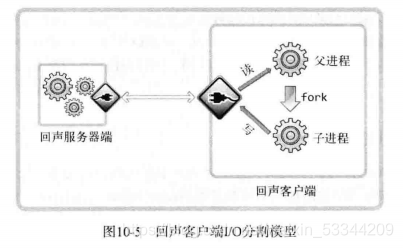
从图可以看出,客户端的父进程负责接收数据,额外创建的子进程负责发送数据。分割后,不同进程分别负责输入和输出,这样,无论客户端是否从服务器端接收完数据都可以进行传输。
选择这种实现方式的原因有很多,但最重要的一点是,程序的实现更加简单。也许有人质疑:既然多产生1个进程,怎么能简化程序实现呢?起始,按照这种实现方式,父进程中只需编写接收数据的代码,子进程只需编写发送数据的代码,所以会简化。实际上,在1个进程内同时实现数据收发逻辑需要考虑更多细节。程序越符炸,这种区别越明显,它也是公认的优点。
分隔I/O程序的另一个好处是,可以提高频繁交换数据的程序性能,如图10-6所示。
图10-6
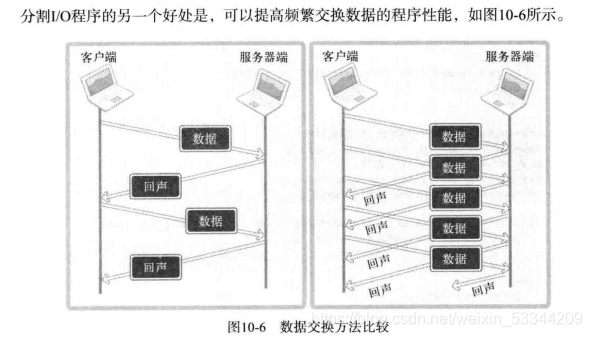
上图左侧演示的是之前的回声客户端数据交换方式,右侧演示的是分隔I/O后的客户端数据传输方式。服务器端相同,不同的是客户端区域。分隔I/O后的客户端发送数据时不必考虑接收数据的情况,因此可以连续发送数据,由此提高同一时间内传输的数据量。这种差异在网络较慢时尤为明显。
这一节内容可谓是干货满满,相信大家如果认真看完,会对多进程如何实现有更深的了解。














 278
278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









