







一、概述
spark是一种基于内存的快速、通用、可扩展的大数据计算引擎。
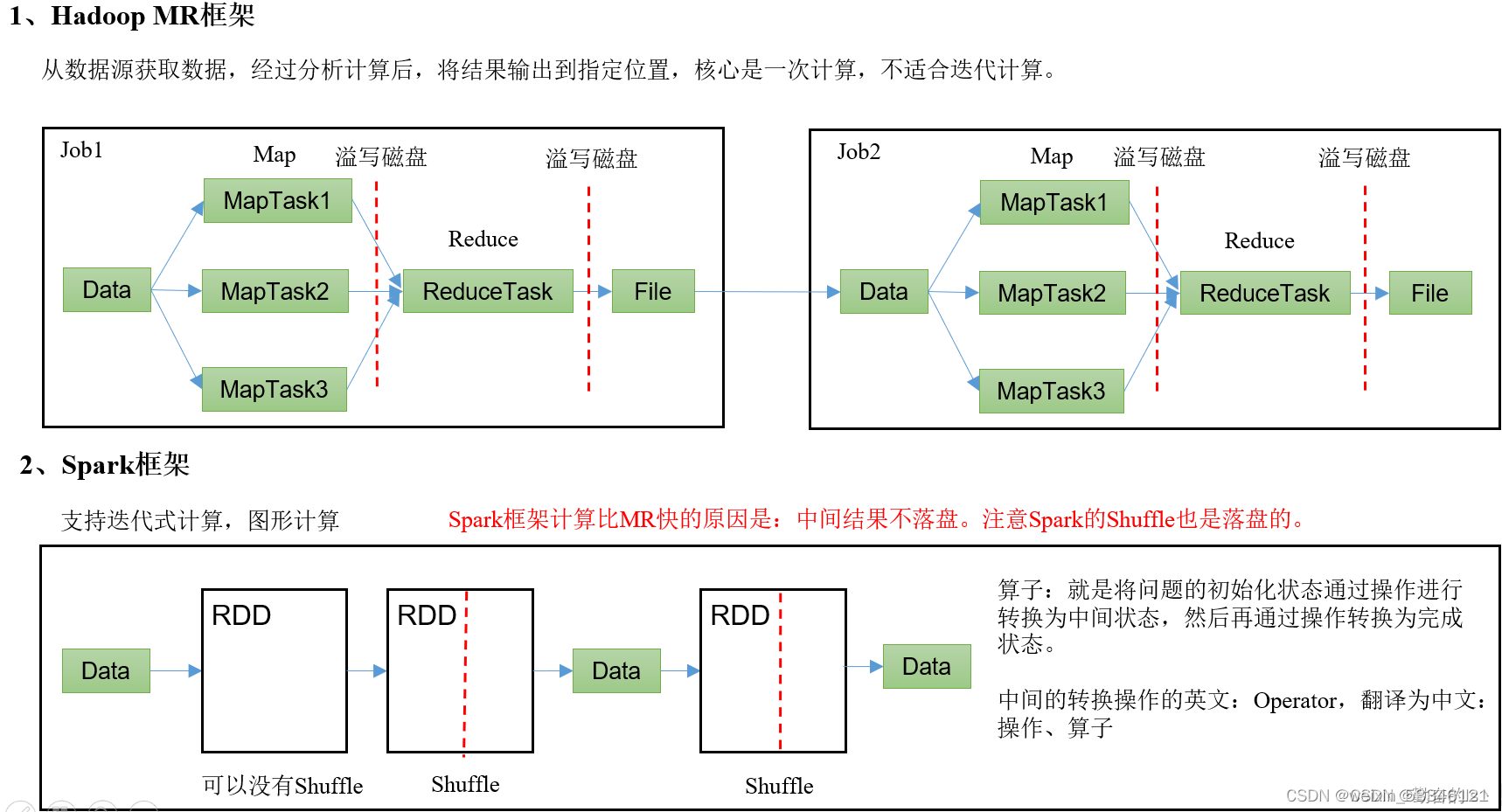
二、spark框架和hadoop框架
Hadoop中的计算框架是MapReduce。MapReduce是一种用于处理大规模数据集的编程模型和计算框架。它可以在分布式计算环境中执行并行处理任务,如处理大量的结构化和非结构化数据。MapReduce框架将计算任务分解成两个主要阶段:Map(映射)和Reduce(归约)。
在Map阶段,输入数据被切分成小块并由多个Mapper处理,每个Mapper独立地将其输入数据转化为键值对(Key-Value Pairs)。然后,这些键值对根据Key进行排序并传递给Reduce阶段。
在Reduce阶段,输入键值对根据Key进行分组,并由多个Reducer处理。每个Reducer将属于相同Key的所有值进行合并和处理,生成最终的输出结果。
MapReduce框架的设计目标是实现高容错性、高可伸缩性和高并发性,适用于大规模数据处理。它是Hadoop生态系统中非常重要的一部分,被广泛用于大数据处理和分布式计算任务。
三、WordCount案例
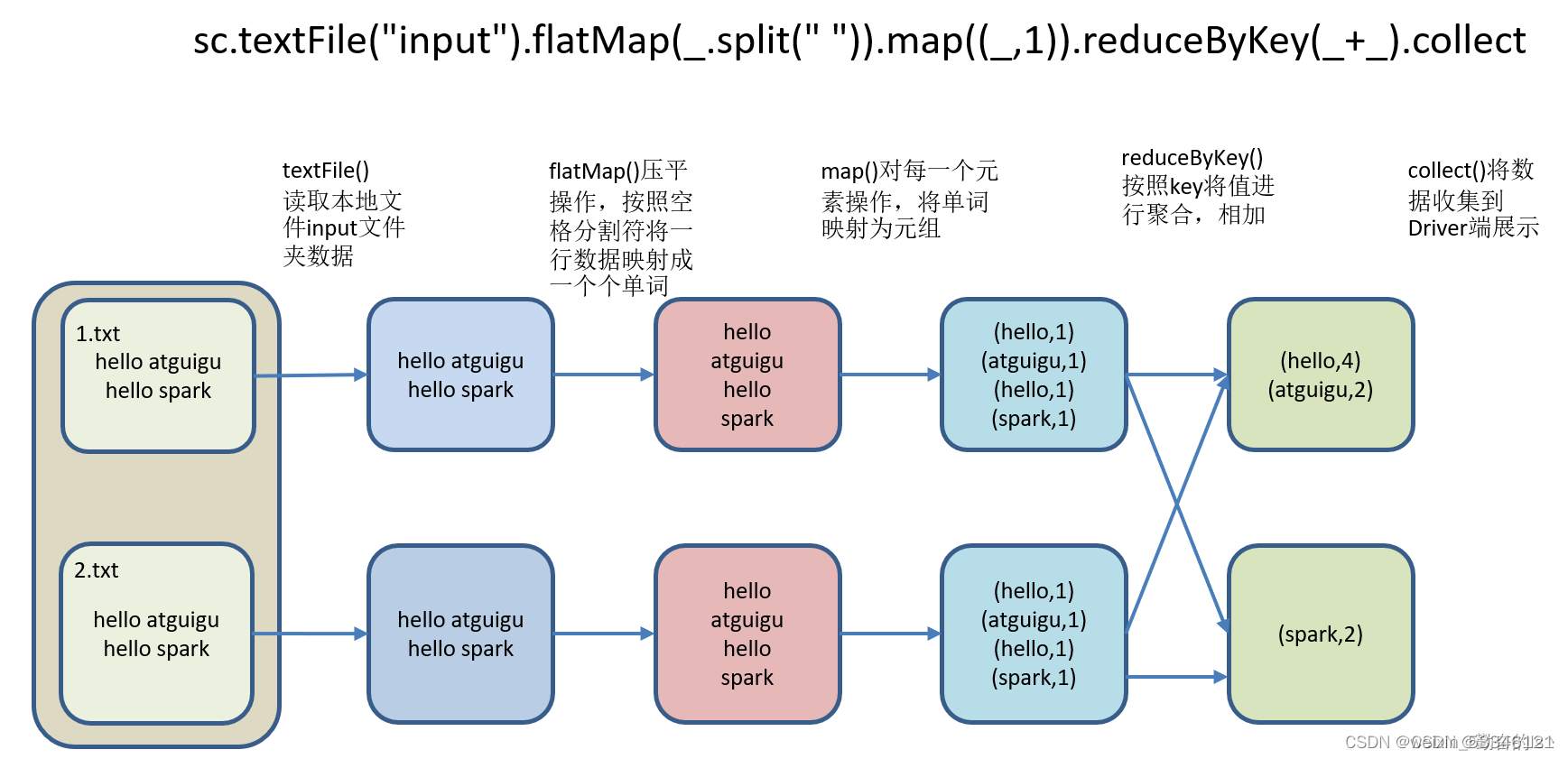
注意:sc是SparkCore程序的入口;spark是SparkSQL程序入口;master = local[*]表示本地模式运行。
# coding:utf8
from pyspark import SparkConf,SparkContext
if __name__ == '__main__':
#创建SparkConf配置对象
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
# 调整日志级别为WARN
sc.setLogLevel("WARN")
# 单词计数:wordcout:读取HDFS上的words.txt文件,对其内部的单词统计出现的数量
# 1.读取文件 本地文件
file_rdd = sc.textFile("../data/input/words.txt") #相对路径
#file_rdd = sc.textFile("/tmp/pycharm_project_962/data/words.txt") #绝对路径
# 2.将单词进行切割,得到一个存储全部单词的集合对象
words_rdd = file_rdd.flatMap(lambda line: line.split(" "))
# 3.将单词转换为元组对象,key是单词,value是数据1
words_with_one_rdd = words_rdd.map(lambda x:(x,1))
# 4.将元组的value按照key来分组,对所有的value执行聚合操作(相加)
result_rdd = words_with_one_rdd.reduceByKey(lambda a,b:a+b)
# 5.通过collect方法收集RDD的数据打印输出结果
print(result_rdd.collect())
# 关闭SparkContext对象
sc.stop()
实际上,并不是所有时候都需要显式地创建SparkConf对象来配置Spark应用程序。在一些简单的应用场景下,可以直接使用SparkConf的默认构造函数,避免显式设置应用程序的配置选项。例如,使用如下语句创建SparkContext:
val sc = new SparkContext()
在上面的代码中,默认的SparkConf对象将会被创建,这些缺省选项通常是足够的,但是各个版本的默认参数可能不同。需要注意的是,它们可能与您的应用程序需求不匹配,因此,建议根据实际需求适当地设置SparkConf参数。
另外,在一些高级用例中,开发人员可以使用更高级的API或者特定的框架来创建SparkContext,而不必显式地创建SparkConf对象。
综上,是否需要显式设置SparkConf根据具体情况而定,通常情况下,建议根据实际需求适当地设置SparkConf参数。需要注意的是,如果不显式设置SparkConf对象,可能会导致使用默认配置和参数,而这些参数可能无法满足应用程序的性能和需求。















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









