







参考大数据技术之Spark(三) SparkStreaming
sparkstreaming是什么
在讲sparkStreaming是什么之前首先讲一下为什么要有SparkStreaming。
Hadoop 的 MapReduce 及 Spark SQL 等只能进行离线计算,无法满足实时性要求较高的业务 需求,例如实时推荐、实时网站性能分析等,流式计算可以解决这些问题。目前有三种比较 常用的流式计算框架,它们分别是 Storm,Spark Streaming 和 fink。它们三个的区别如下:
1、SparkStreaming绝对谈不上比Storm、Flink优秀。这两个框架在实时计算领域中,都很优秀,只是擅长的细分场景并不相同。
2、Spark Streaming在吞吐量上要比Storm优秀。
3、Storm在实时延迟度上,比SparkStreaming就好多了,前者是纯实时,后者是准实时。而且,Storm的事务机制、健壮性/容错性、动态调整并行度等特性,都要比SparkStreaming更加优秀。
4、Spark Streaming,有一点是Storm绝对比不上的,就是:它位于Spark整个生态技术栈中,因此Spark Streaming可以和Spark Core、SparkSQL、Spark Graphx无缝整合,换句话说,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作。这个特点大大增强了SparkStreaming的优势和功能。流处理:
实时流处理:(Storm 、Flink)
每一条记录,都会提交一次计算作业。
每一条记录,一般都被称为一个事件
准实时流处理:(Spark Streaming)
介于批处理和实时流处理之间,是一个较小的时间间隔的数据处理
其底层原理还是基于SparkCore来处理
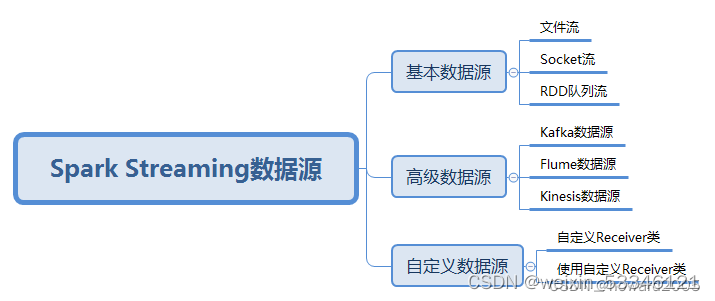
一、执行sparkstream的步骤:
1、通过创建输入DStream来定义输入源
2、通过对DStream应用转换操作和输出操作来定义流计算
3、用streamingContext.start()来开始接收数据和处理流程
4、用streamingContext.awaitTermination()方法来等待处理结束(手动结束或因为错误而结束)
5、可以通过streamingContext.stop()来手动结束流计算进程
二、创建文件夹
进入指定的目录下,创建一个文件夹
cd /usr/local/spark/mycode
mkdir streaming
cd streaming
mkdir logfile
cd logfile
三、Dstream
一、文件流数据统计
今日下午SparkStreaming上机案例要求:
1.指定目录下创建文件目录
2.spark监听该目录
3.在文件目录下创建文件,不断向该文件中输入内容,时间间隔定义1-10s之内
4.pyspark客户端编写代码
5.独立py文件编写代码
6.注意两种编写代码方式的差异
有两种方法:
1、pyspark客户端(xshell)中进行编写代码:
-
创建StreamingContext对象
如果要运行一个Spark Streaming程序,就需要首先生成一个StreamingContext对象,它是Spark Streaming程序的主入口。可以从一个SparkConf对象创建一个StreamingContext对象 登录Linux系统后,启动spark-shell。进入spark-shell以后,就已经获得了一个默认的SparkConext,也就是sc,就可以不用再创建。因此,可以采用如下方式来创建StreamingContext对象:
先进入pyspark中
cd /usr/local/spark-3.2.0/bin
./pyspark
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
ssc = StreamingContext(sc,10)
lines = ssc.textFileStream("file:///usr/local/spark_mycode/logfile")
words = lines.flatMap(lambda line:line.split(" "))
wordCounts = words.map(lambda x:(x,1)).reduceByKey(lambda a,b:a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
ssc = StreamingContext(sc,10)
这里不用定义sc = SparkContext(conf=conf)说明pyspark客户端可以自动识别。
echo “This is the content I want to append to the file” >> log.txt
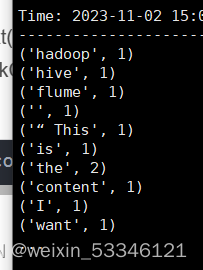
必须先启动ssc以后在把数据输入进才会有数据出现
2、在pycharm中进行编写
# encoding:utf8
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
conf = SparkConf()
conf.setAppName("TestDStream")
conf.setMaster("local[*]")
sc = SparkContext(conf=conf)
#ssc:StreamingContext 对象的变量名。
#sc:SparkContext 对象,用于执行 Spark Streaming 程序。
#10:批处理间隔,表示每隔 10 秒钟会有一个批处理任务。
ssc = StreamingContext(sc,10)
lines = ssc.textFileStream('file:///usr/local/spark_mycode/logfile')
words = lines.flatMap(lambda line:line.split(" "))
wordCounts = words.map(lambda x:(x,1)).reduceByKey(lambda a,b:a+b)
wordCounts.pprint()
ssc.start()
ssc.awaitTermination() #等待下一次
#ssc.stop() #手动停止
lines = ssc.textFileStream(‘file:///usr/local/spark_mycode/logfile’)
这里的路径是虚拟机上的路径
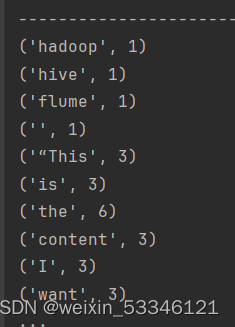
也可以上传该py文件到指定目录下
运行代码
# 进入到 py文件所在的目录下,执行以下命令:
/usr/local/spark-3.2.0/bin/spark-submit FileStreaming.py
# 不断向文件中输入单词
echo “This is the content I want to append to the file” >> log.txt
二、嵌套字流数据统计
是无状态转换操作,只统计当前数据,不会叠加
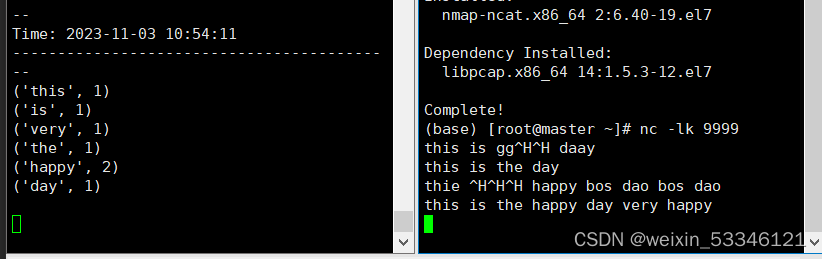
2.1使用套接字流作为数据源:使用nc启动9999端口
上机实操案例:
socket套接字流sparkstreaming统计分析
1.监听端口 9999(或者其他端口,只要保证端口没被占用即可)
2.编写代码,获取上述端口中输入的内容并进行wordcounts统计
重点:
1.内置方法 nc程序启动 一个端口,如 9999,如果nc启动报错,则要如何处理(yum install nc -y 即可)
nc -lk 9999
2.编写py文件代码,注意运行模式(loacl[2])
# encoding:utf8
from __future__ import print_function
import sys
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
if __name__ == '__main__':
if len(sys.argv) !=3:
print("Usage:NetworkWordCount.py <hostname> <port>",file=sys.stderr)
exit(-1)
conf = SparkConf()
conf.setAppName("PythonStreamingNetworkWordCount")
conf.setMaster("local[2]") #local[*]只有一个线程,local[3]有三个线程
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc,1)
lines = ssc.socketTextStream(sys.argv[1],int(sys.argv[2]))
counts = lines.flatMap(lambda line:line.split(" ")).\
map(lambda word:(word,1)).\
reduceByKey(lambda a,b:a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
3.运行py文件的提交命令(spark-submit),注意提交的参数(使用 sys进行处理参数即可)
/usr/local/spark-3.2.0/bin/spark-submit NetWorkWordCount.py localhost 9999
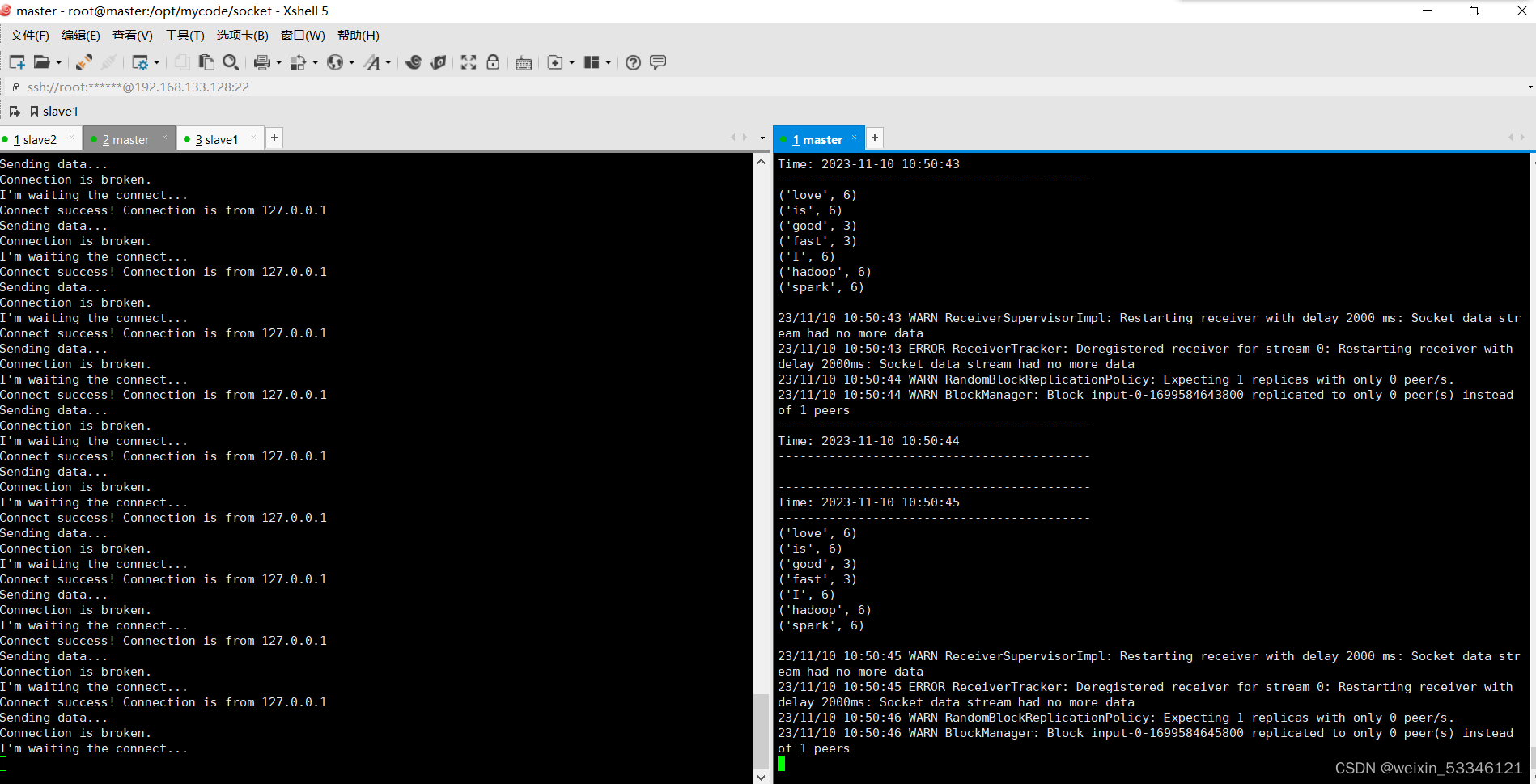
2.2 使用Socket编程实现自定义数据源
datasourcesocket.py
# encoding:utf8
# 导入包
import socket
'''
自定义产生数据流
'''
# 生成socket对象
server = socket.socket()
# 绑定ip和端口
server.bind(('localhost', 9999))
# 监听绑定的端口
server.listen(1)
while 1:
# 为了方便识别,打印一个“I'm waiting...”
print("I'm waiting the connect...")
# 这里用两个值接受,因为连接上之后使用的是客户端发来请求的这个实例
# 所以下面的传输要使用conn实例操作
conn,addr = server.accept()
# 打印连接成功
print("Connect success! Connection is from %s" % addr[0])
# 打印正在发送数据
print('Sending data...')
conn.send('I love hadoop I love spark hadoop is good spark is fast'.encode())
conn.close()
print('Connection is broken.')
socketwordsnet.py
# encoding:utf8
from __future__ import print_function
import sys
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
'''
套接字自定义数据流:统计分析
'''
if __name__ == '__main__':
if len(sys.argv) !=3:
print("Usage:02.套接字流_1.py <hostname> <port>",file=sys.stderr)
exit(-1)
conf = SparkConf()
conf.setAppName("PythonStreamingNetworkWordCount")
conf.setMaster("local[3]")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc,1)
lines = ssc.socketTextStream(sys.argv[1],int(sys.argv[2]))
counts = lines.flatMap(lambda line:line.split(" ")).\
map(lambda word:(word,3)).\
reduceByKey(lambda a,b:a+b)
counts.pprint()
ssc.start()
ssc.awaitTermination()
在/opt/mycode/socket/目录下,创建以上两个文件,必须在此目录下输入以下命令
/usr/local/spark-3.2.0/bin/spark-submit datasourcesocket.py
/usr/local/spark-3.2.0/bin/spark-submit socketwordsnet.py localhost 9999
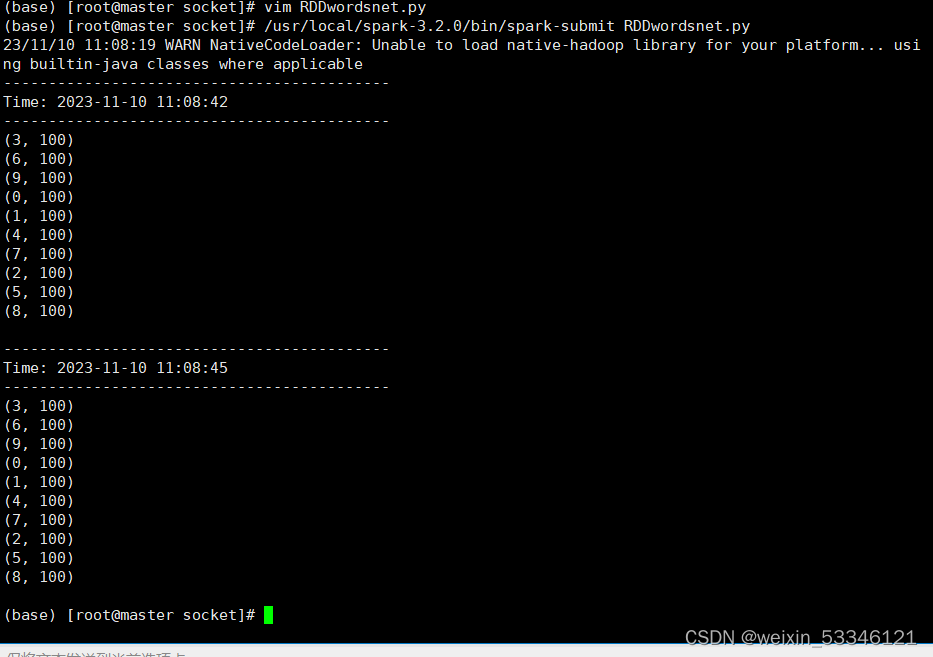
三、RDD队列流数据统计
RDDwordsnet.py
# encoding:utf8
from __future__ import print_function
import time
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
'''
RDD队列流:统计分析
'''
if __name__ == '__main__':
conf = SparkConf()
conf.setAppName("PythonStreamingQueueStream")
conf.setMaster("local[3]")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc,3)
#创建一个队列,通过改队列可以把RDD推给一个RDD队列流
rddQueue = []
for i in range(5):
rddQueue += [ssc.sparkContext.parallelize([j for j in range(1,1001)],10)]
time.sleep(1)
#创建一个RDD队列流
inputStream = ssc.queueStream(rddQueue)
# 不许要分割,本身就是从队列中读取的一个一个的值
mappedStream = inputStream.map(lambda x:(x%10,1))
reducedStream = mappedStream.reduceByKey(lambda a,b:a+b)
reducedStream.pprint()
ssc.start()
# 等待数据完全统计完了以后就会停止
ssc.stop(stopSparkContext=True,stopGraceFully=True)
vim RDDwordsnet.py
/usr/local/spark-3.2.0/bin/spark-submit RDDwordsnet.py
四、kafka数据流统计分析
# 创建一个topic
cd /usr/local/kafka_2.11
./bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic wordsendertest
# 查看话题是否创建成
cd /usr/local/kafka_2.11
./bin/kafka-topics.sh --list --zookeeper master:2181
# 查看话题创建成功之后,可以往话题中产生数据
cd /usr/local/kafka_2.11
./bin/kafka-console-producer.sh --broker-list master:9092 --topic wordsendertest
# 创建消费者,用consumer查看producer产生的数据
cd /usr/local/kafka_2.11
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic wordsendertest --from-beginning
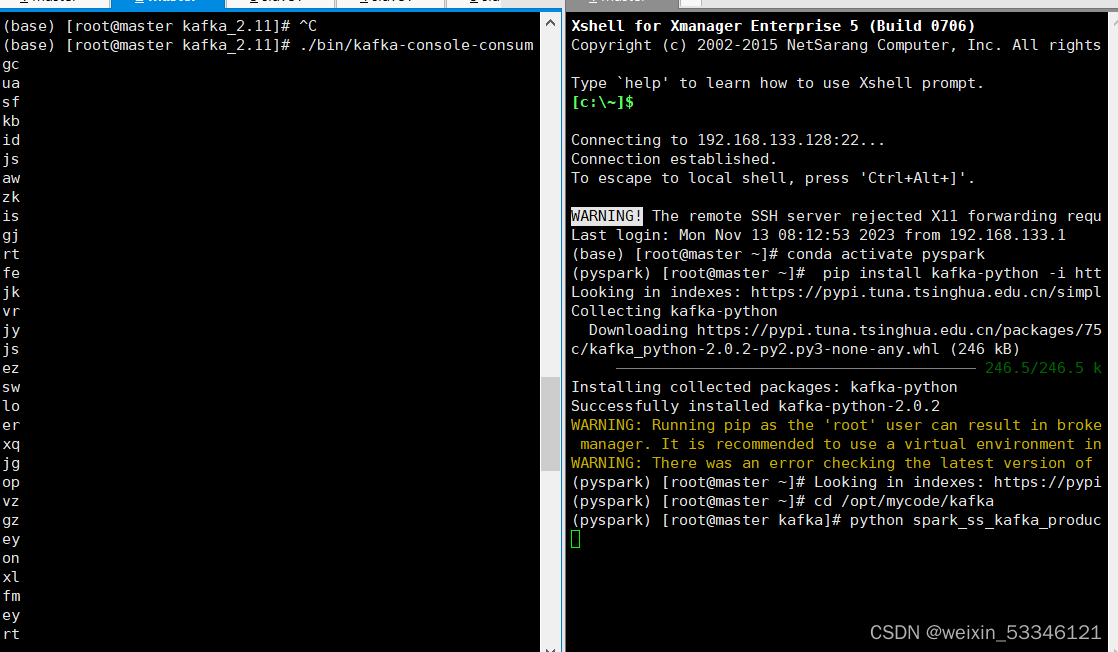
安装虚拟环境中kafka-python库,每个节点都要安装
conda activate pyspark #如果要运行的py文件中导入了第三方库就要启动,如果都是内置库就不用
pip install kafka-python -i https://pypi.tuna.tsinghua.edu.cn/simple Looking in indexes: https://pypi.tuna.tsinghua.edu.cn/simple
# encoding:utf8
import string
import random
import time
from kafka import KafkaProducer # pip install kafka-python
if __name__ == "__main__":
producer = KafkaProducer(bootstrap_servers=['master:9092'])
#随机取两个字符连接在一起
while True:
s2 = (random.choice(string.ascii_lowercase) for _ in range(2))
word = ''.join(s2)
value=bytearray(word,'utf-8')
producer.send('wordcount-topic',value=value).\
get(timeout=10)
time.sleep(0.1)
#创建输入数据的端口
./bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic wordcount-topic
#创建产生数据的查看端口
./bin/kafka-topics.sh --create --zookeeper master:2181 --replication-factor 1 --partitions 1 --topic wordcount-result-topic
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic wordcount-topic
(pyspark) [root@master kafka]# python spark_ss_kafka_producer.py
# encoding:utf8
from pyspark.sql import SparkSession
if __name__ == "__main__":
# SparkSession包括SparkContext
spark = SparkSession.builder.appName("StructuredKafkaCount").\
getOrCreate()
spark.sparkContext.setLogLevel("WARN")
# option("kafka.bootstrap.servers","master:9092"):设置Kafka服务器的地址,这里的地址是"master:9092"。
lines = spark.readStream.format('kafka').\
option("kafka.bootstrap.servers","master:9092").\
option("subscribe","wordcount-topic").\
load().\
selectExpr("CAST(value AS STRING)")
wordCounts = lines.groupBy("value").count()
#format("kafka")通过kafka的形式输出
#trigger(processingTime="8 seconds")每隔8秒统计一次
query = wordCounts.\
selectExpr("CAST(value AS STRING) as key","CONCAT(CAST(value AS STRING),':',CAST(count AS STRING)) AS value").\
writeStream.outputMode("complete").\
format("kafka").\
option("kafka.bootstrap.servers","master:9092").\
option("topic","wordcount-result-topic").\
option("checkpointLocation","file:///tmp/kafka-sink-cp").\
trigger(processingTime="8 seconds").\
start()
query.awaitTermination()
#第一个监控端口:监控话题输入的文本
cd /usr/local/kafka_2.11
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic wordcount-topic
#第二个监控端口:监控执行输出的结果
cd /usr/local/kafka_2.11
./bin/kafka-console-consumer.sh --bootstrap-server master:9092 --topic wordcount-result-topic
#第三个监控端口:执行生产者产生文本代码(先激活环境再执行)
cd /opt/mycode/kafka/
conda activate pyspark
python spark_ss_kafka_producer.py
#第四个监控端口:执行消费者统计代码
cd /opt/mycode/kafka/
/usr/local/spark-3.2.0/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.2.0 spark_ss_kafka_consumer.py
第一个监控端口输出

第二个监控端口输出

四、DStream转换
-
DStream有状态转换:有状态转换指的是在处理连续数据流时,使用之前时间窗口的状态来计算当前时间窗口的结果。在有状态转换中,Spark Streaming 会维护状态并在连续的时间窗口之间共享。这样,可以实现状态的累加、更新和持久化,能够处理更复杂的实时数据分析和处理需求。
-
DStream无状态转换:无状态转换指的是每个时间窗口的结果仅基于当前时间窗口内的数据,而不依赖于之前时间窗口的状态。在无状态转换中,每个时间窗口都是相互独立的,并且没有记忆或状态的维护。 因此,无状态转换适用于那些相互之间独立的计算任务,不需要考虑历史数据的影响。
DStream无状态转换操作
DStream有状态转换操作
socket产生数据,监听localhost 9999端口
1、updateStateByKey操作
#!/usr/bin/env python3
from __future__ import print_function
import sys
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: State_transition_operation_updateStateByKey.py <hostname> <port>", file=sys.stderr)
exit(-1)
conf = SparkConf()
conf.setAppName("PythonStreamingStatefulNetworkWordCount")
conf.setMaster("local[3]")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///opt/mycode/streamsocket/stateful/") #监听的目录
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
running_counts.pprint()
ssc.start()
ssc.awaitTermination()
#第一个监控端口
nc -lk 9999
#第二个监控端口
/usr/local/spark-3.2.0/bin/spark-submit State_transition_operation_updateStateByKey.py localhost 9999
监控9999端口的输入数据并会累加输入的数据。
2、滑动窗口转换操作
State_transition_operation_windows.py
#!/usr/bin/env python3
from __future__ import print_function
import sys
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: state_transition_operation_windows.py <hostname> <port>", file=sys.stderr)
exit(-1)
conf = SparkConf()
conf.setAppName("PythonStreamingWindowedNetworkWordCount")
conf.setMaster("local[3]")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 10)
ssc.checkpoint("file:///opt/mycode/streamsocket/windows")
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKeyAndWindow(lambda x, y: x + y, lambda x, y: x - y, 30, 10)
counts.pprint()
ssc.start()
ssc.awaitTermination()
#第一个监控端口
nc -lk 9999
#第二个监控端口
/usr/local/spark-3.2.0/bin/spark-submit State_transition_operation_windows.py localhost 9999
相当于一个有临时的存储空间,我们监控里面的数据,但是这个存储空间中的数据有时间限制,超过了存放时间,数据就会被移出去。如果连续的输入数据的操作都没有超过时间,数据将会累加输出。
五、DStream输出
统计结果数据输出操作:
1.保存到本地(linux)文件中;
#!/usr/bin/env python3
from __future__ import print_function
import sys
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: State_transition_operation_updateStateByKey.py <hostname> <port>", file=sys.stderr)
exit(-1)
conf = SparkConf()
conf.setAppName("PythonStreamingStatefulNetworkWordCount")
conf.setMaster("local[3]")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///opt/mycode/streaming/socket/stateful/")
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
running_counts.saveAsTextFiles("file:///opt/mycode/streaming/socket/output/result")
running_counts.pprint()
ssc.start()
ssc.awaitTermination()
2.保存到mysql中
#!/usr/bin/env python3
from __future__ import print_function
import sys
import pymysql
from pyspark import SparkContext,SparkConf
from pyspark.streaming import StreamingContext
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: State_transition_operation_updateStateByKey.py <hostname> <port>", file=sys.stderr)
exit(-1)
conf = SparkConf()
conf.setAppName("PythonStreamingStatefulNetworkWordCount")
conf.setMaster("local[3]")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 1)
ssc.checkpoint("file:///opt/mycode/streaming/socket/stateful/")
initialStateRDD = sc.parallelize([(u'hello', 1), (u'world', 1)])
def updateFunc(new_values, last_sum):
return sum(new_values) + (last_sum or 0)
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
running_counts = lines.flatMap(lambda line: line.split(" "))\
.map(lambda word: (word, 1))\
.updateStateByKey(updateFunc, initialRDD=initialStateRDD)
running_counts.pprint()
# 写入到数据库中
def dbfunc(records):
db = pymysql.connect(host="localhost",user="root",password="123456",database="spark")
cursor = db.cursor()
def doinsert(p):
# sql1 = "delete from wordcount"
# cursor.execute(sql1)
sql = "insert into wordcount(word,count) values ('%s', '%s')" % (str(p[0]), str(p[1]))
try:
cursor.execute(sql)
db.commit()
except:
db.rollback()
for item in records:
doinsert(item)
def func(rdd):
repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(dbfunc)
# 开始保存数据到mysql中
running_counts.foreachRDD(func)
ssc.start()
ssc.awaitTermination()
六、Structured Streaming
6.1、Structured Streaming 编写代码方法
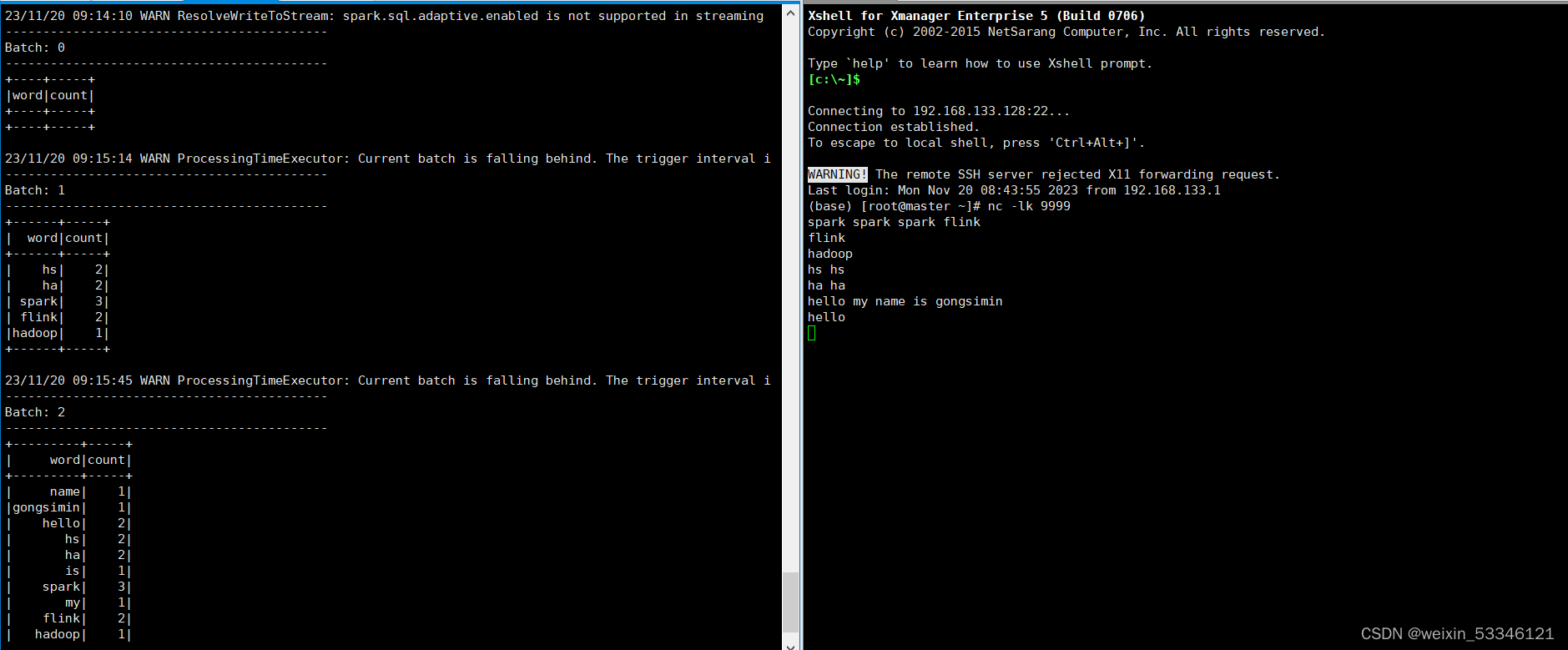
实例任务:一个包含很多行英文语句的数据流源源不断到达,Structured Streaming 程序对每行英文语句进行拆分,并统计每个单词出现的频率
07_structured_streaming_01.py
#!/usr/bin/env python3
from pyspark.sql import SparkSession
from pyspark.sql.functions import split
from pyspark.sql.functions import explode
if __name__ == "__main__":
spark = SparkSession.builder\
.appName("StructuredNetworkWordCount").\
getOrCreate()
spark.sparkContext.setLogLevel("WARN") #设置等级
lines = spark.readStream.\
format("socket").\
option("host","localhost").\
option("port",9999).\
load()
#alias("word")给这列加上名字word
words = lines.select(
explode(
split(lines.value, " ")
).alias("word")
)
wordCounts = words.groupBy("word").count()
# 启动流计算并输出结果
query = wordCounts.\
writeStream.\
outputMode("complete").\
format("console").\
trigger(processingTime="8 seconds").\
start()
query.awaitTermination()
将上述文件上传到/opt/mycode/structuredstreaming目录中
#启动一个master端口,执行 9999端口
nc -lk 9999
#启动第二个端口,执行上述 py文件
/usr/local/spark-3.2.0/bin/spark-submit 07_structured_streaming_01.py
6.2、Structured Streaming 读取json文件源
一般网站产生的数据都是json格式的数据
这里以一个json格式文件的处理来演示file源的使用方法,主要包括以下两个步骤:
- 创建程序生成json格式的file源测试数据
- 创建程序对数据进行统计
1、编写生成json数据代码文件 07_structured_streaming_json_02.py
#!/usr/bin/env python3
# 导入需要用到的模块
import os
import shutil
import random
import time
TEST_DATA_TEMP_DIR = '/opt/'
TEST_DATA_DIR = '/opt/testdata/'
ACTION_DEF = ['login', 'logout', 'purchase']
DISTRICT_DEF = ['fujian', 'beijing', 'shanghai', 'guangzhou']
JSON_LINE_PATTERN = '{{"eventTime": {}, "action": "{}", "district": "{}"}}\n' #结构
# 测试的环境搭建,判断文件夹是否存在,如果存在则删除旧数据,并建立文件夹
def test_setUp():
if os.path.exists(TEST_DATA_DIR):
shutil.rmtree(TEST_DATA_DIR, ignore_errors=True) #按照树形结构删除
os.mkdir(TEST_DATA_DIR)
# 测试环境的恢复,对文件夹进行清理
def test_tearDown():
if os.path.exists(TEST_DATA_DIR):
shutil.rmtree(TEST_DATA_DIR, ignore_errors=True)
# 生成测试文件
def write_and_move(filename, data):
with open(TEST_DATA_TEMP_DIR + filename,
"wt", encoding="utf-8") as f:
f.write(data)
shutil.move(TEST_DATA_TEMP_DIR + filename,
TEST_DATA_DIR + filename)
if __name__ == "__main__":
test_setUp()
for i in range(1000):
filename = 'e-mall-{}.json'.format(i)
content = ''
rndcount = list(range(100))
random.shuffle(rndcount)
for _ in rndcount:
content += JSON_LINE_PATTERN.format(
str(int(time.time())),
random.choice(ACTION_DEF),
random.choice(DISTRICT_DEF))
write_and_move(filename, content)
time.sleep(1)
test_tearDown()
2、编写统计分析代码 07_structured_streaming_json_03.py
#!/usr/bin/env python3
from pyspark.sql import SparkSession
from pyspark.sql.functions import window
from pyspark.sql.types import StructType,StructField
from pyspark.sql.types import TimestampType,StringType
# 定义JSON文件的路径常量
TEST_DATA_DIR_SPARK = 'file:///opt/testdata/'
if __name__ == "__main__":
# 数据结构,写死
# 定义模式,为时间戳类型的eventTime、字符串类型的操作和省份组成
schema = StructType([
StructField("eventTime", TimestampType(), True),
StructField("action", StringType(), True),
StructField("district", StringType(), True)])
spark = SparkSession \
.builder \
.appName("StructuredEMallPurchaseCount")\
.getOrCreate()
spark.sparkContext.setLogLevel('WARN')
lines = spark \
.readStream \
.format("json") \
.schema(schema) \
.option("maxFilesPerTrigger", 100) \
.load(TEST_DATA_DIR_SPARK)
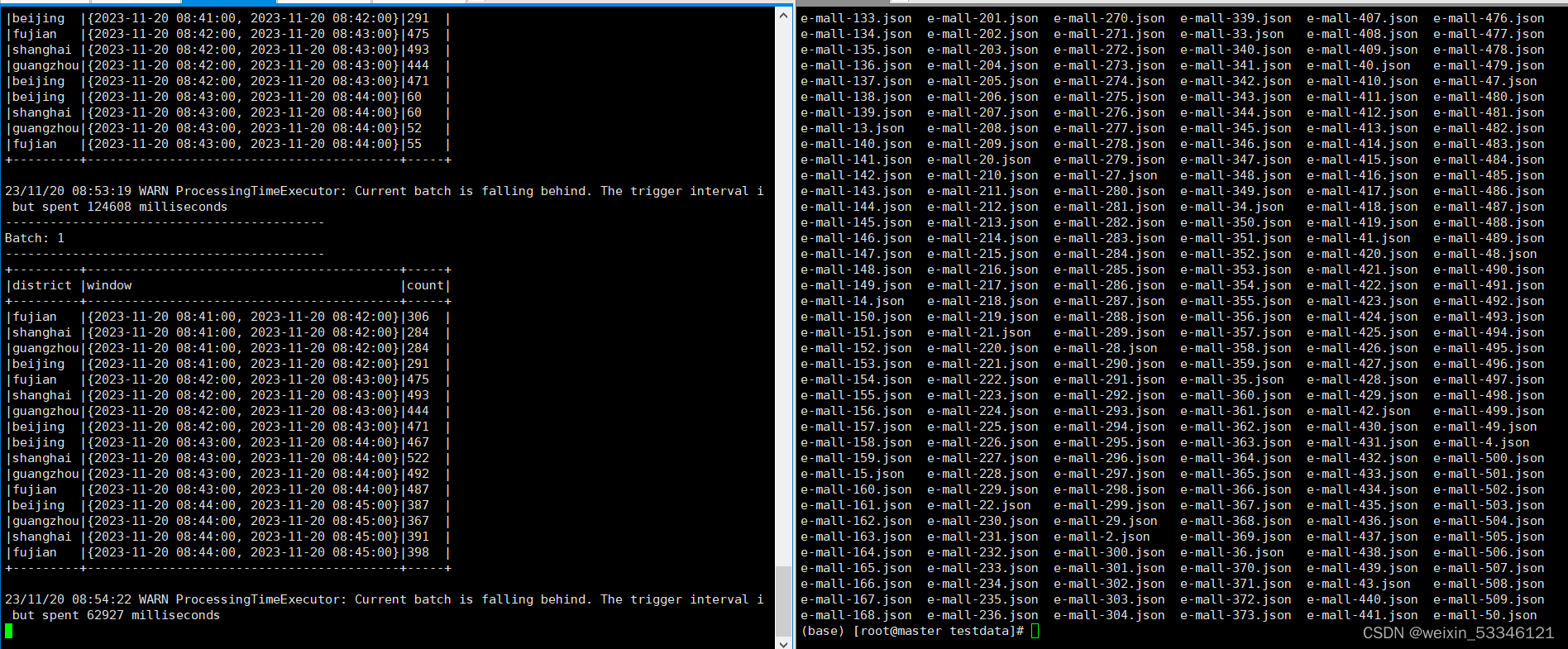
# 定义窗口
windowDuration = '1 minutes'
windowedCounts = lines \
.filter("action = 'purchase'") \
.groupBy('district', window('eventTime', windowDuration)) \
.count() \
.sort('window')
# 怎么输出
query = windowedCounts \
.writeStream \
.outputMode("complete") \
.format("console") \
.option('truncate', 'false') \
.trigger(processingTime="8 seconds")\
.start()
query.awaitTermination()
3、上传文件到/opt/mycode/structuredstreaming上
4、执行 产生json数据文件代码,进入到 pyspark虚拟环境中
#执行产生json数据文件
conda activate pyspark
python 07_structured_streaming_json_02.py
#执行统计分析代码文件
/usr/local/spark-3.2.0/bin/spark-submit 07_structured_streaming_json_03.py

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









