






对自然语言处理领域相关文献进行梳理和总结,对学习的文献进行梳理和学习记录。希望和感兴趣的小伙伴们一起学习。欢迎大家在评论区进行学习交流!
论文:《VisualTextRank: Unsupervised Graph-based Content Extraction for Automating Ad Text to Image Search》
1.解决了对广告文本自动获取相关广告图像(Advertising Text Automatically Gets Relevant Advertising images ,ATGAI)问题中查询数据有限问题。
2.提出了一种基于无监督图的内容提取方法(VisualTextRank)。
3.针对ATGAI提出了基于图排序的三种算法:
第一个算法是PageRank算法。PageRank算法基于图的链接结构,将互联网抽象为一个有向图,其中节点表示网页,边表示网页之间的链接关系。PageRank通过计算每个网页的权重来衡量网页的重要性,重要性高的网页往往具有更多的入链指向它。PageRank算法通过迭代计算网页的权重值,直到收敛为止。在每次迭代中,每个网页的权重值由指向该网页的其他网页的权重值以及这些网页的出链数量来确定。
优点:PageRank算法广泛应用于网页排序等搜索引擎领域。
缺点:PageRank算法对于文本摘要、关键词提取等自然语言处理任务并不直接适用。
为了解决第一个算法的问题,提出了第二个算法TextRank。TextRank是一种基于图的算法,用于从文本中提取关键词或生成摘要。它将文本中的单词或短语表示为图中的节点,通过单词之间的共现关系构建边,然后使用PageRank算法对节点进行排序,最终选取排名靠前的节点作为关键词或摘要的表示。
优点:TextRank算法解决了文本摘要、关键词提取等任务中的排序问题,扩展了PageRank算法的应用范围。
缺点:TextRank算法在关键词提取和文本摘要过程中没有考虑用户的需求和偏好,可能会提取出与用户需求不相关的内容。
为了解决第二个算法的问题,提出了第三个算法Biased TextRank。Biased TextRank的基本原理与TextRank类似,在TextRank的基础上引入了偏置项(bias term),使得算法能够根据用户提供的关键词或主题信息,有针对性地提取与用户需求相关的内容。具体来说,偏置项可以加权考虑用户提供的关键词或主题信息,使得算法更加倾向于提取与关键词或主题相关的内容。
优点:Biased TextRank算法能够根据用户提供的关键词或主题信息,有针对性地提取与关键词或主题相关的内容,提高了文本摘要和关键词提取的准确性。
缺点:用户提供的查询数据(关键词或主题)有限或不够准确,算法的效果可能会受到限制,无法充分体现用户的真实需求和意图,即查询数据有限问题。
为了解决第三个算法的问题,提出了VisualTextRank算法。该算法是建立在Biased TextRank算法的基础上。VisualTextRank专注于广告文本和广告图像查询中,改进了Biased TextRank。采用检索相似的现有广告来增强输入广告文本。增强是使用类似广告的文本以及类似广告图像中的图像标签以无监督的方式完成的,同时使用sentence-bert(SBERT)嵌入的方式引入广告类别特定的偏见。通过引入类别偏见(category biasing),并使用相似的广告的文本和图像来增强输入的广告文本,解决了查询数据有限问题。
4.运用了VisualTextRank算法和sentence-bert(SBERT)模型;数据来源:收集了来自约300个广告主的样本的数据,对于每个广告主,数据包括:(i)广告文本,(ii)原始广告图像,(iii)广告图像的图像查询。将此数据集称为onboard -sample。
5.训练模型:
我们假设一个现有广告池(集),用P表示。P中的广告具有以下属性:(i)广告文本,(ii)广告图像的图像标签以及每个标签的置信度得分。对于广告池P中的每个广告,我们计算广告相对于输入广告a𝑖𝑛的语义相似度(相关性)。

其中a是P中的广告,𝑟𝑒𝑙𝑒𝑣𝑎𝑛𝑐𝑒(a,a𝑖𝑛)表示其相对于输入广告a𝑖𝑛的相关性。可以使用SBERT(针对语义文本相似性进行训练)这样的句子嵌入方法来获得𝜙(a)和𝜙(a𝑖𝑛)。我们使用上述相关性评分从给定输入广告a𝑖𝑛的池P中获得top-𝑚相似广告。
增强相似的广告图像标签。我们通过选择语义上与相似广告的广告文本中的单词接近的图像标签,用相似广告的图像标签来增强令牌图G。我们假设一个边界:
(i)我们可以添加的图像标签的最大数量(= 𝑚𝑎𝑥_𝑡𝑎𝑔𝑠)。
(ii)图像标签与其父文本中的单词之间的最小余弦相似度来选择图像标签进行增强(=𝑚𝑖𝑛_𝑡𝑎𝑔_𝑠𝑖𝑚)。如算法1中所述,我们从一个相似广告{a𝑖, . . . , a𝑚} 列表开始,按照与输入广告文本a𝑖𝑛的相关性降序排序。对于每个相似广告a𝑖𝑛, T (a𝑖)表示与相应广告图像相关的图像标签列表;该标签列表根据来自对象检测器的置信度分数按降序排序。给定a𝑖和T(a𝑖),我们选择一个标签𝑡 ∈ T(a𝑖),该标签至少与a𝑖(i.e., < 𝜙(𝑡),𝜙(𝑤) >) ≥ 𝑚𝑖𝑛_𝑡𝑎𝑔_𝑠𝑖𝑚)中的一个单词𝑤接近。我们按照算法1的方法不断迭代,直到我们收集到T∗中的𝑚𝑎𝑥_𝑡𝑎𝑔𝑠个图像标签。

增强相似的广告文本。除了图像标签,我们还使用类似广告中的单词来增强令牌图G。我们提出的单词增强方法在算法2中描述。它在本质上类似于图像标签增强方法。按照出现的顺序对广告文本a𝑖中的单词进行迭代,并选择高于𝑚𝑖𝑛_𝑤𝑜𝑟𝑑_𝑠𝑖𝑚相似度阈值(使用SBERT嵌入,输入广告文本a𝑖与候选单词𝑤之间的余弦相似度)的单词。选定的单词W∗ 用于扩充G。

类别偏见(category biasing)。考虑一个类别短语c的集合,这样的集合可以通过使用标准和类别分类法中的短语来创建。用下面的方法找到最接近的ˆ 𝑐类。
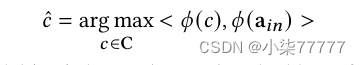
其中𝜙(𝑐)和𝜙(a𝑖𝑛)表示类别短语和输入广告文本的(SBERT)嵌入。假设在设置中不存在给定广告文本的类别标签,并且上面的方法是推断给定广告文本最接近的类别的代理。对于给定的输入广告文本推断出ˆ 𝑐后,增强令牌图G∗上,我们计算中每个顶点 𝑖 的类别偏差𝑏𝑖𝑎𝑠 (𝑐𝑎𝑡) 𝑖。
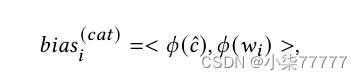
其中𝑤𝑖 表示与顶点𝑖相关的单词。直观地说,类别偏倚试图增加更接近推断类别的单词的权重。
通过上面叙述的内容进行模型训练。















 448
448

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









