









MySQL指令总结
基础指令
指令分类
DDL(Data Definition Language) :数据定义语言。用来操作数据库,表,列等。
DML(Data Manipulation Language) :数据操作语言。用来对数据库中表的记录(数据)进行增删改。
DQL(Data Query Language) :数据查询语言。用来查询数据库中表的记录(数据)。
相对来说,查询在工作中最常用;
DDL(操作库表列)
库相关
-- 操作库
SHOW DATABASES; -- 查询所有数据库
SHOW CREATE DATABASE mysql; -- 查询某个数据库的创建语句,可以查看字符集(码表)
CREATE DATABASE db1; -- 创建数据库
CREATE DATABASE IF NOT EXISTS db2; -- 创建数据库 这个更规范
CREATE DATABASE IF NOT EXISTS db4 CHARACTER SET gbk; -- 创建数据库并指定字符集,一般utf-8
ALTER DATABASE db4 CHARACTER SET utf8; -- 修改数据库字符集
SHOW CREATE DATABASE db4; -- 查看db4数据库的字符集
DROP DATABASE IF EXISTS 数据库名称; -- 删除数据库如果存在
USE db4; -- 使用数据库,切到这个数据库
SELECT DATABASE(); -- 查询当前使用的数据库
表相关
表信息相关查询:
SHOW TABLES; --查询使用的数据库下所有表
DESC USER; -- 查询表结构 结果是字段类型 字段是否为空等信息
SHOW TABLE STATUS FROM 数据库名称 [LIKE '表名']; -- 查询数据表的所有属性信息 该表的存储引擎,字符集,表大小,创建时间和更新时间等信息
SHOW CREATE TABLE user; -- 查询当前表的字符集;包含创建时的字段信息等;
创建表:重点:
/*
创建数据表
标准语法:
CREATE TABLE 表名(
列名 数据类型 [约束],
列名 数据类型 [约束],
...
列名 数据类型 [约束]
);
*/
-- 列的约束其实大多数是会考虑的,这个在实际生产中要注意;其实在使用工具的时候可以不用通过sql语句建表;
-- 建表全示例:
CREATE TABLE oneday(
user_id INT PRIMARY KEY AUTO_INCREMENT, -- 自增约束
user_num VARCHAR(30) UNIQUE, -- 唯一约束 该字段下数据不能重复
user_name VARCHAR(30) NOT NULL, -- 不为空约束
user_age INT
) ENGINE = MYISAM; -- 存储引擎设置,不写默认为InnoDB引擎;(最常用) ,一般都不写,使用默认的
-- 普通建表示例:
CREATE TABLE product(
id INT,
NAME VARCHAR(20),
price DOUBLE,
stock INT,
insert_time DATE
);
-- 不指定任何信息,建一个普通表
ALTER TABLE 原表名 RENAME TO 现表名; -- 修改表名
ALTER TABLE product RENAME TO product2;
/*
给表添加列(重点)
标准语法:
ALTER TABLE 表名 ADD 列名 数据类型;
新需求需要添加列的解决方案
1. 在需要的时候添加一个列 不建议
2. 在数据库设计之初,就预留多列冗余字段。建议
*/
ALTER TABLE oneday ADD color INT;
/*
修改表中列的数据类型
标准语法:
ALTER TABLE 表名 MODIFY 列名 数据类型;
*/
/*
修改表中列的名称和数据类型
标准语法:
ALTER TABLE 表名 CHANGE 旧列名 新列名 数据类型;
*/
/*
删除表中的列
标准语法:
ALTER TABLE 表名 DROP 列名;
*/
/*
删除表,判断、如果存在则删除
标准语法:
DROP TABLE IF EXISTS 表名;
*/
常见约束归类
约束名称 含义
PRIMARY KEY 主键约束(主键约束 = 唯一约束 + 非空约束,一张表只有一个主键)
PRIMARY KEY AUTO_INCREMENT 主键自增约束
UNIQUE 唯一约束,该字段下内容不能重复
NOT NULL 非空约束,该字段不能插入空值
创建表时添加约束如上:
创建表后添加约束和删除约束:
-- 建表后单独添加主键约束
ALTER TABLE 表名 MODIFY 字段名 字段类型 约束名;
-- 删除主键
ALTER TABLE 表名 DROP 约束名;
外键约束: 实际业务中不推荐,资源消耗比较大 多表关联时使用;
-- 创建orderlist订单表
CREATE TABLE orderlist(
id INT PRIMARY KEY AUTO_INCREMENT, -- id
number VARCHAR(20) NOT NULL, -- 订单编号
uid INT, -- 外键列
CONSTRAINT ou_fk1 FOREIGN KEY (uid) REFERENCES USER(id) -- 建表时创建外键约束
);
-- CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主表主键列名)
-- 建表后添加外键约束
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名);
-- 删除外键约束
ALTER TABLE orderlist DROP FOREIGN KEY ou_fk1;
表数据增删改:超重点
/*
给指定列添加数据(工作中推荐写法)
标准语法:
该写法好处:
1. 可以直观的看出添加数据的列
2. 数据库添加新的字段之后,不会受到影响
INSERT INTO 表名(列名1,列名2,...) VALUES (值1,值2,...);
*/
-- eg
INSERT oneday (user_id,user_num,user_name,user_age) VALUES(NULL,'1322332','bbbbbbb',24);
-- 默认给所有列添加 可以不用表名后跟列名
/*
给全部列添加数据
标准语法:
INSERT INTO 表名 VALUES (值1,值2,值3,...);
*/
/*
批量添加所有列数据
标准语法:
INSERT INTO 表名 VALUES (值1,值2,值3,...),(值1,值2,值3,...),(值1,值2,值3,...);
*/
INSERT oneday (user_id,user_num,user_name,user_age) VALUES(NULL,'1322333','aaaaaa',24),(NULL,'1322334','ccccccc',24);
-- 注意一定要加where条件,不加会整个表修改;
/*
修改表数据
标准语法:
UPDATE 表名 SET 列名1 = 值1,列名2 = 值2,... [where 条件];
*/
UPDATE oneday SET user_age = 30,user_name = 'nihao' where user_num = '1322334';
-- 注意删除条件也要加where 否则全表删除
/*
删除表数据
标准语法:
DELETE FROM 表名 [WHERE 条件];
*/
DELETE FROM oneday WHERE user_num='1322334';
数据查询 重要
查询公式
sql查询是有一定规则的,按这个顺序进行查询
SELECT [DISTINCT]
字段列表 [[AS] 别名] /函数
FROM
表名列表
-- 下面的关键字不要求都出现。但是只要出现了,必须是下面的顺序,否则语法错误。
WHERE
条件列表
GROUP BY
分组字段
HAVING
分组后的过滤条件
ORDER BY
排序
LIMIT
分页
查询语法
/*
查询全部数据
标准语法:
SELECT * FROM 表名;
查询出来的结果称为结果集(ResultSet)。
不建议使用select *
1. 冗余字段会被查出来,后期添加的字段也会被查出来
2. select * 的性能低于 select 字段名列表
3. 实际生产环境不允许全部查询,因为每个表可能有万级或亿级数据,查询很浪费性能,一般如果全部查询我们会分页limit
*/
select * FROM oneday;
/*
查询指定列
标准语法:
SELECT 列名1,列名2,... FROM 表名;
*/
SELECT user_num,user_name FROM oneday; -- 查询名字和学号
/*
去除重复查询
标准语法:
SELECT DISTINCT 列名1,列名2,... FROM 表名;
*/
SELECT DISTINCT user_name from oneday;
/*
计算列的值,一般不用,如果需要运算,会在Java代码中运算,传值给SQL
标准语法:
SELECT 列名1 运算符(+ - * /) 列名2 FROM 表名;
如果某一列为null,可以进行替换
ifnull(表达式1,表达式2)
表达式1:想替换的列
表达式2:想替换的值
*/
查询是where后面跟的条件
符号 功能
大于
< 小于
= 大于等于
<= 小于等于
= 等于
<> 或 != 不等于
BETWEEN … AND … 在某个范围之内(都包含)
IN(…) 多选一
LIKE 占位符 模糊查询 _单个任意字符 %0到多个任意字符
IS NULL 是NULL
IS NOT NULL 不是NULL
AND 或 && 并且
OR 或 || 或者
NOT 或 ! 非,不是
排序查询:
升序 ASC 默认的顺序
降序 DESC
/*
排序查询
标准语法:
SELECT 列名 FROM 表名 [WHERE 条件] ORDER BY 列名1 排序方式1,列名2 排序方式2;
*/
select * FROM oneday ORDER BY user_id DESC;
-- 多个排序条件时,第一个优先
分组查询:
/*
分组查询
标准语法:
SELECT 列名 FROM 表名 [WHERE 条件] GROUP BY 分组列名 [HAVING 分组后条件过滤] [ORDER BY 排序列名 排序方式];
*/
分页查询:
/*
分页查询
标准语法:
SELECT 列名 FROM 表名
[WHERE 条件]
[GROUP BY 分组列名]
[HAVING 分组后条件过滤]
[ORDER BY 排序列名 排序方式]
LIMIT 当前页数,每页显示的条数;
LIMIT 当前页数,每页显示的条数;
公式:当前页数 = (当前页数-1) * 每页显示的条数
LIMIT 之前已经显示的记录数, 本页要显示的记录数
*/
函数
常见函数可参考菜鸟教程总结
https://www.runoob.com/mysql/mysql-functions.html
/*
聚合函数
标准语法:
SELECT 函数名(列名) FROM 表名 [WHERE 条件];
count(*) 表只有一列且没有主键,性能最好 不用
★count(id主键) 表有主键(这一列的值不能为空,且不能重复)的时候,性能最好
count(1) 表有多列,且没有主键的时候,性能最好 不用
*/
索引
mysql的索引是一大块内容,这里只是指令方面进行大概总结
/*
创建索引
CREATE [UNIQUE|FULLTEXT] INDEX 索引名称
[USING 索引类型] -- 默认是BTREE
ON 表名(列名...);
*/
/*
查询索引
SHOW INDEX FROM 表名;
*/
/*
ALTER添加索引
-- 普通索引
ALTER TABLE 表名 ADD INDEX 索引名称(列名);
-- 组合索引
ALTER TABLE 表名 ADD INDEX 索引名称(列名1,列名2,...);
-- 主键索引
ALTER TABLE 表名 ADD PRIMARY KEY(主键列名);
-- 外键索引(添加外键约束,就是外键索引)
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名);
-- 唯一索引
ALTER TABLE 表名 ADD UNIQUE 索引名称(列名);
-- 全文索引
ALTER TABLE 表名 ADD FULLTEXT 索引名称(列名);
*/
/*
删除索引
DROP INDEX 索引名称 ON 表名;
*/
索引主要是影响的我们运行一条sql指令时的效率,查询指令效率如下
EXPLAIN SELECT * FROM oneday WHERE user_num = '1322333';
EXPLAIN SELECT * FROM oneday;

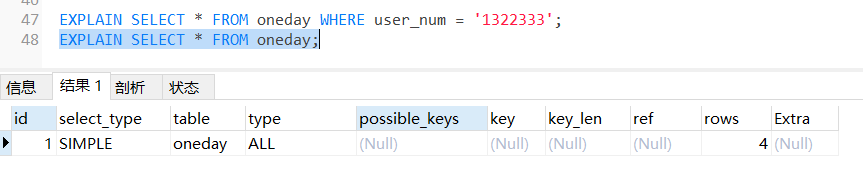
各个属性的解释:
1、**id:**这是SELECT的查询序列号 ,值越大优先级越高,id相同时自上而下的顺序;
2、select_type:select_type就是select的类型,可以有以下几种:
名称 含义
SIMPLE 简单SELECT(不使用UNION或子查询等)
PRIMARY 最外面的SELECT
UNION UNION中的第二个或后面的SELECT语句
DEPENDENT UNION UNION中的第二个或后面的SELECT语句,取决于外面的查询
UNION RESULT UNION的结果
SUBQUERY 子查询中的第一个SELECT
DEPENDENT SUBQUERY 子查询中的第一个SELECT,取决于外面的查询
DERIVED 导出表的SELECT(FROM子句的子查询)
3、table:显示这一行的数据是关于哪张表的
4、**type:**这列最重要,显示了连接使用了哪种类别,有无使用索引,是使用Explain命令分析性能瓶颈的关键项之一。
结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
可以简单记为:
eq_ref > ref >range > index > ALL
一般来说,得保证查询至少达到range级别,最好能达到ref,否则就可能会出现性能问题。
5、possible_keys:列指出MySQL能使用哪个索引在该表中找到行
6、**key:**显示MySQL实际决定使用的键(索引)。如果没有选择索引,键是NULL
7、key_len:显示MySQL决定使用的键长度。如果键是NULL,则长度为NULL。使用的索引的长度。在不损失精确性的情况下,长度越短越好
8、ref:显示使用哪个列或常数与key一起从表中选择行。
9、rows:显示MySQL认为它执行查询时必须检查的行数。 越小越好
10、Extra:包含MySQL解决查询的详细信息,也是关键参考项之一。
10.1:using filesort mysql使用了内部文件排序,比较耗费性能,因该避免;
10.2:using temporary mysql使用了内部表优化,必须避免;
10.3:using index 性能较好;















 1052
1052











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









