







前言
大家好我是jiantaoyab,这是我所总结作为学习的笔记第11篇,在这里分享给大家,这篇文章讲超标量与多发射和超长指令字设计,前面文章提到的书籍的pdf大家没有的话可以私信找我要!
《计算机组成与设计:硬件 / 软件接口》中4.10.1 和 4.10.2 的推测和静态多发射,是我们所说的超长指令字(VLIW)的知识点。4.10.2 的动态多发射,是我们所说的超标量(Superscalar)的知识点。
回顾一下
程序的 C P U 执行时间 = 指令数 × C P I × C l o c k C y c l e T i m e 程序的 CPU 执行时间 = 指令数 × CPI × Clock Cycle Time 程序的CPU执行时间=指令数×CPI×ClockCycleTime
这个公式里面的CPI指标,它的倒数叫IPC(Instruction Per Clock),也就是一个时钟周期里面能够执行的指令数,代表了 CPU 的吞吐率。
那么把它放到流水线中能达到多少呢?
最佳情况下,IPC 也只能到 1。因为无论做了哪些流水线层面的优化,即使做到了指令执行层面的乱序执行,CPU 仍然只能在一个时钟周期里面,取一条指令。
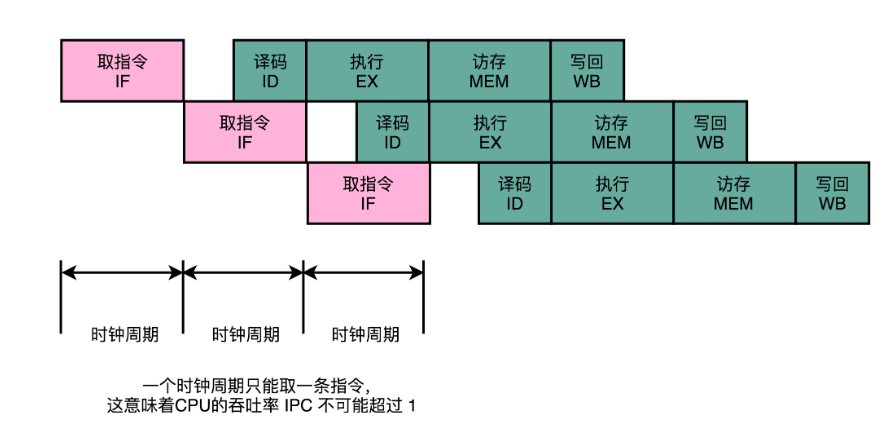
无论指令后续能优化得多好,一个时钟周期也只能执行完这样一条指令,CPI 只能是 1。但是,我们现在用的 Intel CPU 或者 ARM 的 CPU,一般的 CPI 都能做到 2 以上,这是怎么做到的呢?这就涉及到今天这个文章所讲的多发射与超标量。
多发射与超标量
早期的CPU 是没有专门的浮点数计算电路的,是用软件进行模拟或者配一块单独的芯片来专门用来进行浮点数的运算,即使到了现在浮点数计算变成CPU的一部分,但并不是所有计算功能都在一个 ALU 里面,真实的情况是,我们会有多个 ALU这也是为什么,乱序执行的时候,会看到,其实指令的执行阶段,是由很多个功能单元(FU)并行(Parallel)进行的。
不过,在指令乱序执行的过程中,取指令(IF)和指令译码(ID)部分并不是并行进行的。
既然指令的执行层面可以并行进行,为什么取指令和指令译码不行呢?如果想要实现并行,该怎么办呢?
其实只要我们把取指令和指令译码,也一样通过增加硬件的方式,并行进行就好了。我们可以一次性从内存里面取出多条指令,然后分发给多个并行的指令译码器,进行译码,然后对应交给不同的功能单元去处理。这样,我们在一个时钟周期里,能够完成的指令就不只一条了。IPC 也就能做到大于 1 了
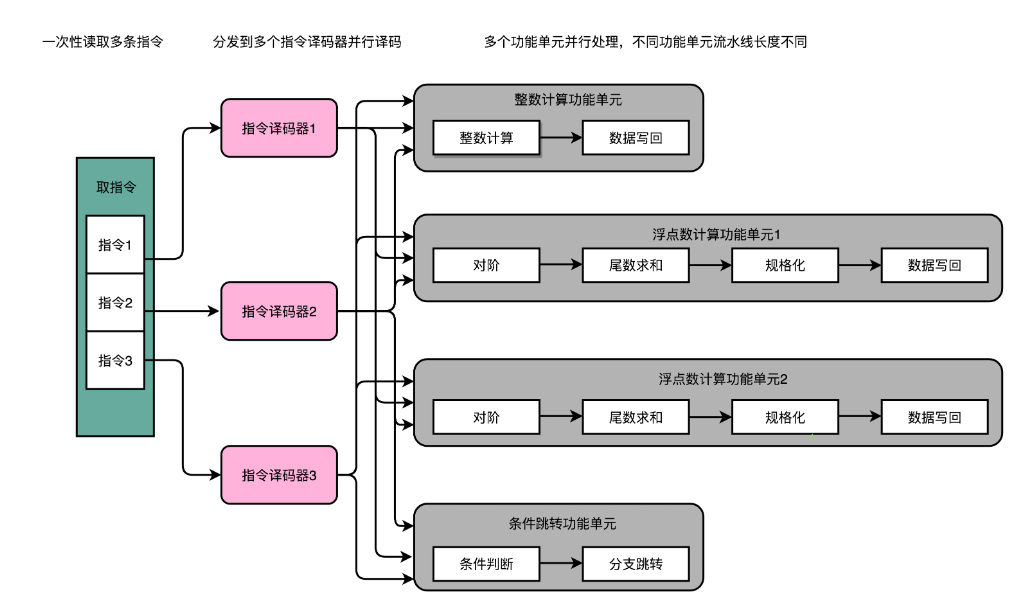
这就是CPU中的多发射与超标量设计。
什么是多发射呢?
同一个时间,可能会同时把多条指令发射(Issue)到不同的译码器或者后续处理的流水线中去
在超标量的 CPU 里面,有很多条并行的流水线,而不是只有一条流水线。“超标量“这个词是说,本来我们在一个时钟周期里面,只能执行一个标量(Scalar)的运算。在多发射的情况下,我们就能够超越这个限制,同时进行多次计算
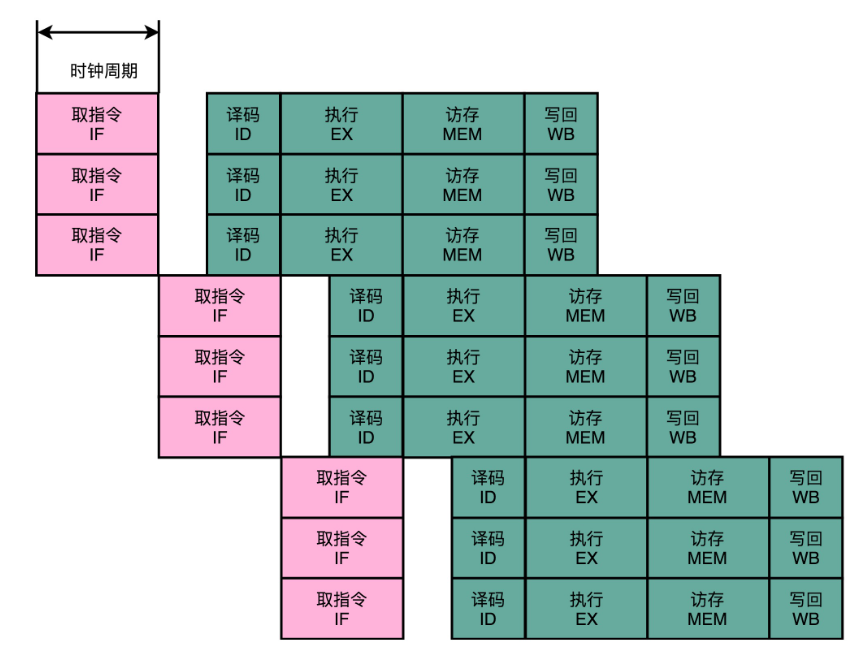
可以看出不同的功能单元的流水线长度是不一样的。我们平时所说的 14 级流水线,指的通常是进行整数计算指令的流水线长度。如果是浮点数运算,实际的流水线长度则会更长一些。
超长指令字设计
无论是乱序执行,还是超标量技术,在实际的硬件层面,其实实施起来都挺麻烦的。这是因为,在乱序执行和超标量的体系里面, CPU 要解决依赖冲突的问题(冒险问题)
CPU 需要在指令执行之前,去判断指令之间是否有依赖关系。如果有对应的依赖关系,指令就不能分发到执行阶段。因为这样,上面我们所说的超标量 CPU 的多发射功能,又被称为动态多发射处理器。这些对于依赖关系的检测,都会使得我们的 CPU 电路变得更加复杂
能不能不把分析和解决依赖关系的事情,放在硬件里面,而是放到软件里面来干呢?
在乱序执行和超标量的 CPU 架构里,指令的前后依赖关系,是由 CPU 内部的硬件电路来检测的。而到了超长指令字的架构里面,这个工作交给了编译器这个软件。
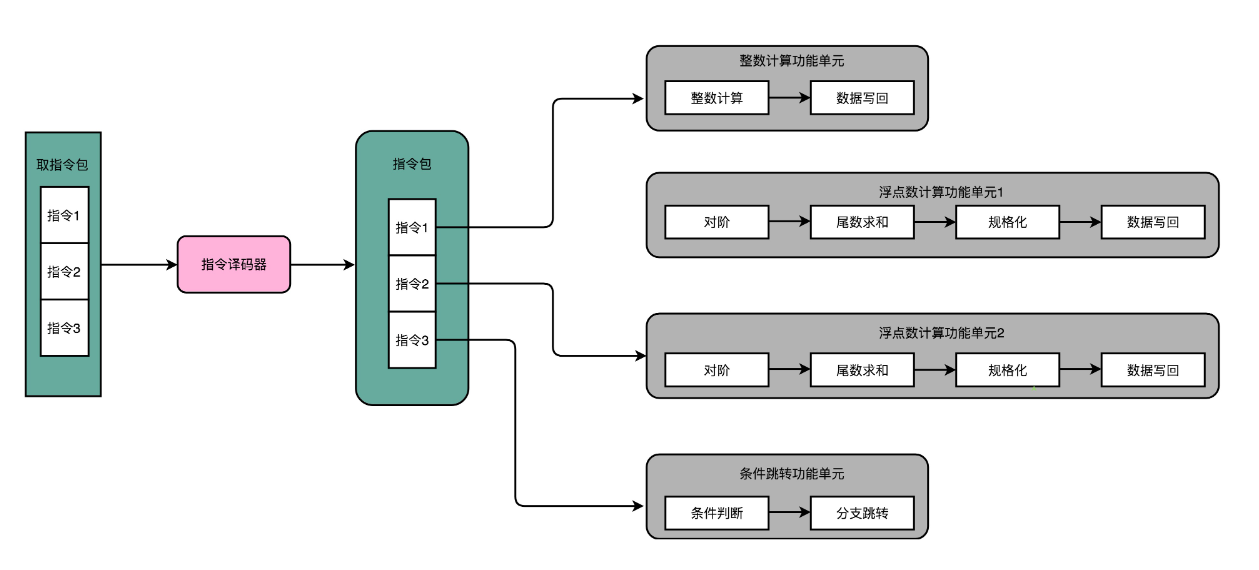
编译器在这个过程中,直接分析出指令的前后依赖关系。于是,硬件在代码编译之后,可以让编译器把没有依赖关系的代码位置进行交换。然后在这些指令中,可以并行执行的多条连续的指令打包在一起组成一个指令包。
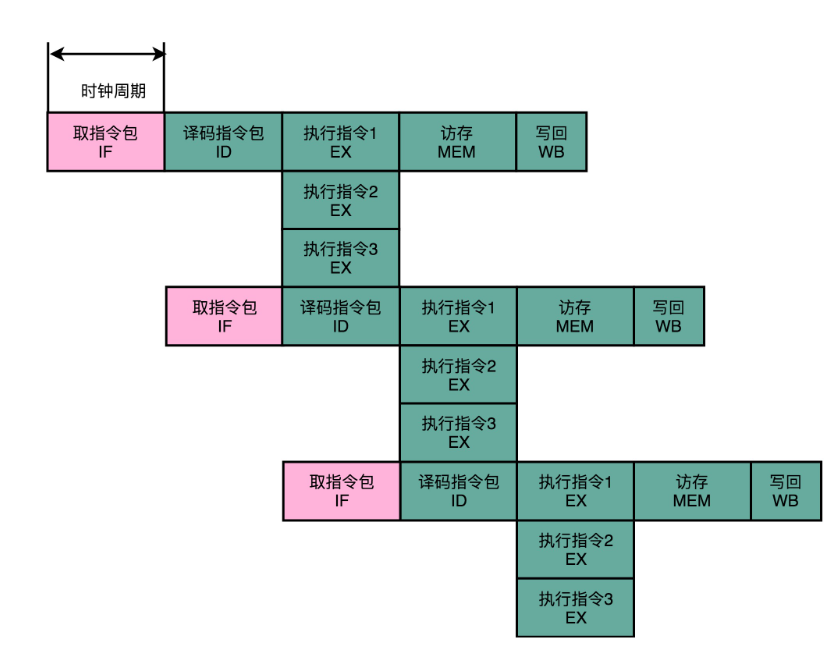
CPU 在运行的时候,不再是取一条指令,而是取出一个指令包。然后,译码解析整个指令包,解析出 3 条指令直接并行运行。可以看到,使用超长指令字架构的 CPU,同样是采用流水线架构的。
也就是说,一组(Group)指令,仍然要经历多个时钟周期。同样的,下一组指令并不是等上一组指令执行完成之后再执行,而是在上一组指令的指令译码阶段,就开始取指令了
流水线停顿这件事情在超长指令字里面,很多时候也是由编译器来做的。除了停下整个处理器流水线,超长指令字的 CPU 不能在某个时钟周期停顿一下,等待前面依赖的操作执行完成。
编译器需要在适当的位置插入 NOP 操作,直接在编译出来的机器码里面,就把流水线停顿处理。
这种设计有一个著名的实现是 IA-64 架构的安腾处理器,但是失败了。
为什么呢?
一方面,安腾处理器的指令集和 x86 是不同的。这就意味着,原来 x86 上的所有程序是没有办法在安腾上运行的,而需要通过编译器重新编译才行
另一方面,安腾处理器的 VLIW 架构决定了,如果安腾需要提升并行度,就需要增加一个指令包里包含的指令数量,比方说从 3 个变成 6 个。一旦这么做了,虽然同样是 VLIW 架构,同样指令集的安腾 CPU,程序也需要重新编译。因为原来编译器判断的依赖关系是在 3 个指令以及由 3 个指令组成的指令包之间,现在要变成 6 个指令和 6 个指令组成的指令包。编译器需要重新编译,交换指令顺序以及 NOP 操作,才能满足条件。甚至,我们需要重新来写编译器,才能让程序在新的 CPU 上跑起来
,现在要变成 6 个指令和 6 个指令组成的指令包。编译器需要重新编译,交换指令顺序以及 NOP 操作,才能满足条件。甚至,我们需要重新来写编译器,才能让程序在新的 CPU 上跑起来















 7674
7674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









