







目录
一、传统回归方法的困境
在目标检测中,边界框回归通常通过L1/L2损失直接预测坐标值(如中心点偏移、宽高)。这种方法存在两大瓶颈:
-
对标注噪声敏感:标注误差或边界模糊时,模型被迫拟合不准确的标签,导致回归不稳定。
-
缺乏不确定性建模:无法区分“确定性高”和“不确定性高”的预测(如遮挡目标),泛化能力受限。
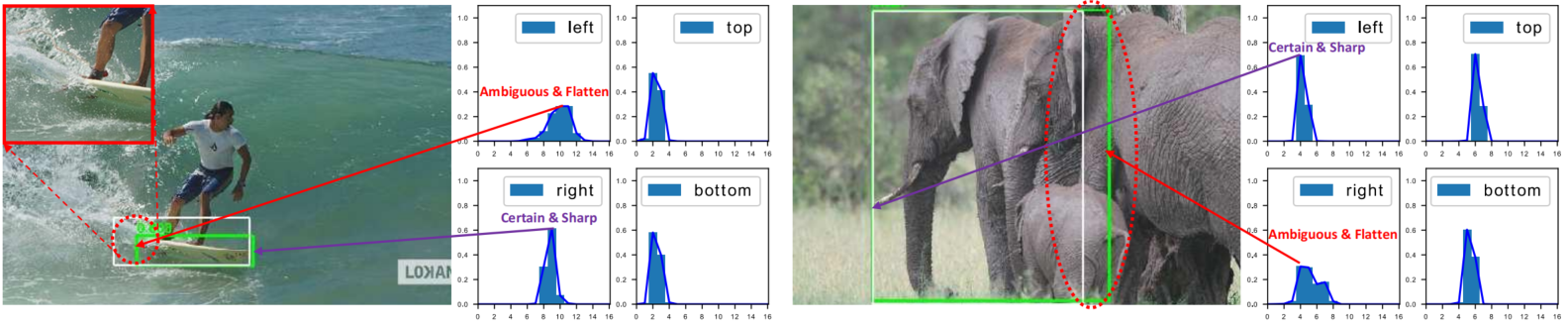
如图所示:由于遮挡、阴影、模糊等原因,许多目标的边界并不清晰,因此真实标签(白色框)有时并不可靠,仅用狄拉克δ分布难以表示这些情况(狄拉克δ分布是一种理想的、只在单一点概率为1,其他地方概率为0的数学分布,表示完全确定的情况)。相反,提出的边界框泛化分布学习方法能够通过分布形状体现边界信息,其中较为平坦的分布表示边界不清晰或模糊的情况(见红色圆圈标记),而尖锐的分布表示边界明确的情况。图中由我们模型预测的边界框标记为绿色。
二、DFL的核心思想:从离散分布到连续坐标
1. 离散概率分布建模
DFL将连续坐标值建模为离散区间上的概率分布。假设坐标真实值为 y,将其离散化为 n 个点 {y0,y1,...,yn−1},模型预测每个点的概率 P(yi)。
2. 积分计算连续值
通过加权求和(积分)得到最终预测坐标:
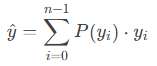
示例:

3. 为何更鲁棒?
-
噪声容忍:标注误差可能导致真实值在相邻区间偏移,DFL允许模型在相邻点分配概率,而非强行拟合噪声点。
-
不确定性建模:遮挡或模糊边界时,模型可自然在多个相邻位置分配概率,输出更稳定的预测。
三、DFL损失函数的设计原理
1. 损失公式
![]()
其中Si理解为概率。

当Si这个概率比较大时,说明y距离yi更近,y距离yi+1更远一点;希望Si对应的权重也大,就选择yi+1-y作为权重。
2. 为何仅优化两个相邻点?
-
稀疏性约束:强制模型聚焦真实值附近区域,避免无关区间的噪声干扰。
-
计算高效:仅计算两个点的损失,显著减少计算量。
3. 为何设置预测离散区间的数量为16

也就是说在20*20的特征图上,最极端的情况下,由中间的anchor负责预测,那么预测框边界到中心点的距离最大为10,所以16足够了。
四、YOLOv8中的DFL工程实现
1. 输入与输出
-
输入:形状为
(B, 16, H, W)的特征图,16表示离散区间数(C1=16)。 -
输出:形状为
(B, 1, H, W)的积分结果,每个位置对应一个坐标预测值。
2. 代码实现(核心逻辑)
class DFL(nn.Module):
"""
Distribution Focal Loss (DFL) 的积分模块
论文: 《Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection》
链接: https://ieeexplore.ieee.org/document/9792391
功能: 将离散概率分布转换为连续坐标值的积分操作,用于目标检测的边界框回归
"""
def __init__(self, c1=16):
"""
初始化DFL模块
:param c1: 离散区间的数量,默认16。表示将每个坐标(ltrb)离散化为16个区间
"""
super().__init__()
# 定义1x1卷积层: 输入通道c1,输出通道1,无偏置
# 该卷积的权重将被固定为离散位置值[0,1,...,c1-1],用于实现积分计算
self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False)
# 生成离散位置编码: [0.0, 1.0, ..., c1-1.0]
x = torch.arange(c1, dtype=torch.float)
# 将位置编码设置为卷积核权重,形状调整为(1, c1, 1, 1)
# 权重固定不更新,表示对离散位置值的固定积分操作
self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1))
self.c1 = c1 # 保存离散区间数
def forward(self, x):
"""
前向传播过程
:param x: 输入张量,形状为 (batch_size, 4*c1, num_anchors)
其中 4 表示边界框的四个坐标(ltrb),每个坐标对应c1个离散概率值
:return: 输出张量,形状为 (batch_size, 4, num_anchors),表示四个坐标的连续预测值
"""
b, _, a = x.shape # 解包维度: batch_size, 4*c1, num_anchors
# 关键步骤分解:
# 1. reshape: (b, 4*c1, a) -> (b, 4, c1, a)
# 将4个坐标的离散概率分离到第二维度
# 2. transpose: (b, 4, c1, a) -> (b, c1, 4, a)
# 调整维度顺序以适配卷积操作
# 3. softmax(1): 在c1维度(离散区间维度)进行概率归一化
# 确保每个坐标的离散概率和为1
# 4. conv操作: 使用固定权重的1x1卷积进行加权求和(积分)
# 卷积核权重为[0,1,...,c1-1],输出形状为 (b, 1, 4, a)
# 5. view: 调整形状为最终输出 (b, 4, a)
return self.conv(
x.view(b, 4, self.c1, a) # 按坐标分离通道
.transpose(2, 1) # 调整维度顺序 [b, c1, 4, a]
.softmax(1) # 离散概率归一化(区间维度)
).view(b, 4, a) # 输出形状调整
"""
示例说明:
假设输入形状为 (2, 64, 3),其中:
- c1=16, 4*c1=64 (4个坐标,每个坐标16个离散概率)
- num_anchors=3
处理流程:
1. reshape -> (2, 4, 16, 3) : 分离4个坐标
2. transpose -> (2, 16, 4, 3): 适配卷积输入形状 [通道数在前]
3. softmax(1) -> (2, 16, 4, 3): 每个坐标的16个概率值和为1
4. conv操作 -> (2, 1, 4, 3): 积分计算得到连续值
5. view -> (2, 4, 3): 最终输出每个锚点的4个坐标预测值
数学本质:
对每个坐标的离散概率分布执行加权求和:
ẏ = Σ (softmax(p_i) * i), i ∈ [0, 15]
其中卷积操作等价于 Σ (概率 * 位置编码)
"""之所以不更新卷积权重的参数,是因为要做积分操作,理解注释中的数学本质。

















 1863
1863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









