






文章目录
一、LeNet-5网络
1.1 网络结构
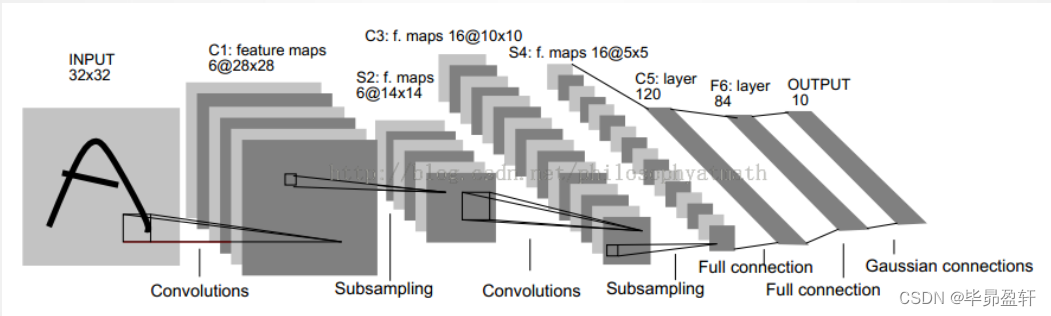
1.2 结构详解
C1层:
- 6个Feature Map构成。
- 每个神经元对输入进行5*5卷积。
- 每个神经元对应55+1个参数,共6个Feature Map,2828个神经元,因此共有122304个连接。
S2层:
Pooling层。
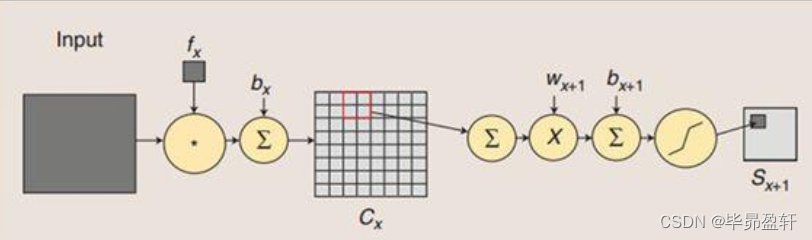
C3层:
卷积层。
S4层:
与S2层相同。
C5层:
- 120个神经元。
- 每个神经元对输入进行5*5卷积,与S4全连接。
- 总连接数48120。
F6层:
- 84个神经元。
- 与C5全连接。
- 总连接数10164。
输出层:
- 由欧式径向基函数单元构成。
- 每类一个单元。
- 输出RBF单元计算输入向量与参数向量之间的欧氏距离。
与现在网络的区别:
- 卷积时不进行填充。
- 池化层采用平均池化而非最大池化。
- 选用Sigmoid或tanh而非ReLU作为非线性环节激活函数。
- 层数较浅,参数数量较小(约6万)。
1.3 代码实现
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape: \t',X.shape)
#模型训练
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
二、基本卷积神经网络
2.1 AlexNet网络
网络结构:
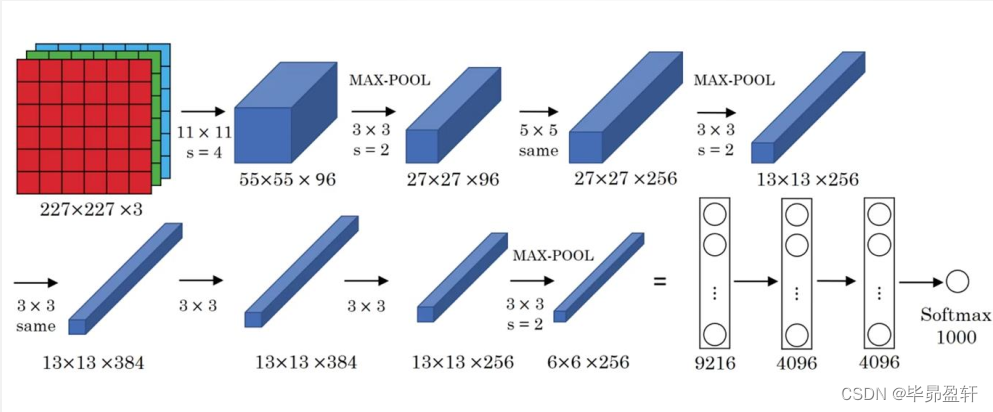
网络说明:
- 网络共有8层可学习层,包括5层卷积层和3层全连接层。
- 改进:
池化层采用最大池化;
选用ReLU作为非线性环节激活函数;
网络规模扩大,参数数量接近6000万;
出现“多个卷积层+一个池化层”的结构。 - 普遍规律:
随网络深入,宽、高衰减,通道数增加。
2.2 VGG-16网络
网络结构:
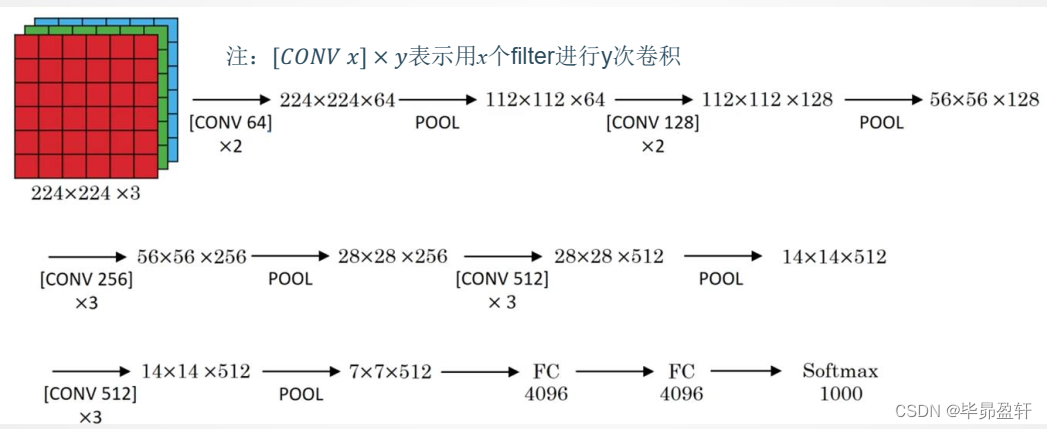
网络说明:
- 改进:
网络规模进一步增大,参数数量约为1.38亿;
由于各卷积层、池化层的超参数基本相同,整体结构呈现出规整的特点。 - 普遍规律:
随网络深入,高和宽衰减,通道数增多。
三、常用数据集
3.1 MNIST
MNIST数据集主要由一些手写数字的图片和相应的标签组成,图片一共有10类,由60000个训练样本和10000个测试样本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。
3.2 Fashion-MNIST
FashionMNIST是一个替代 MNIST手写数字集的图像数据集。FashionMNIST 的大小、 格式和训练集/测试集划分与原始的MNIST 完全一致。60000/10000 的训练测试数据划分,28x28的灰度图片。
3.3 CIFAR-10
CIFAR-10数据集由10个类的60000个32x32彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。数据集分为五个训练批次和一个测试批次,每个批次有10000个图像。测试批次包含来自每个类别的恰好1000个随机选择的图像。
3.4 PASCAL VOC
目标分类(识别)、检测、分割最常用的数据集之一。一共分成20类。
3.5 MS COCO
包含目标分类(识别)、检测、分割、语义标注等数据集。提供的标注类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
四、深度学习视觉应用
4.1 算法评价指标
混淆矩阵:

P(精确率):

R(召回率):

精度:

P-R曲线:表示了召回率和准确率之间的关系。
mAP:均值平均准确率

其中𝑁代表测试集中所有图片的个数, 𝑃(𝑘)表示在能识别出𝑘个图片的时候Precision的值, 而 Δ𝑟(𝑘)则表示识别图片个数从𝑘 − 1变化到𝑘时(通过调整阈值) Recall值的变化情况。
4.2 目标检测与YOLO
目标检测:
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,并且物体还可以是多个类别。
YOLO(一步法)基本思想:
分类问题扩展为回归+分类问题
YOLO网络结构:
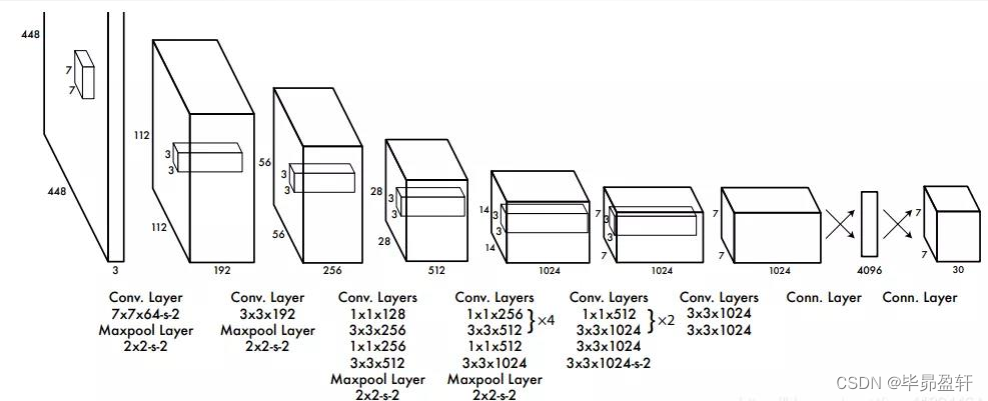
网络结构包含24个卷积层和2个全连接层;其中前20个卷积层用来做预训练,后面4个是随机初始化的卷积层,和2个全连接层。
YOLO模型处理:
将图片分割为 𝑆2个grid(𝑆 = 7),每个grid cell的大小都是相等的,每个格子都可以检测是否包含目标。
YOLO网络输出:
输出是一个7 × 7 × 30的张量。对应7 × 7个cell,每个cell对应2个包围框(boundingbox, bb),预测不同大小和宽高比,对应检测不同目标。每个bb有5个分量,分别是物体的中心位置(𝑥, 𝑦)和它的高(ℎ) 和宽 (𝑤) ,以及这次预测的置信度。
YOLO置信度:
置信度计算公式

Pr(𝑜𝑏𝑗)是一个grid有物体的概率,IOU是预测的bb和真实的物体位置的交并比。
YOLO损失函数:

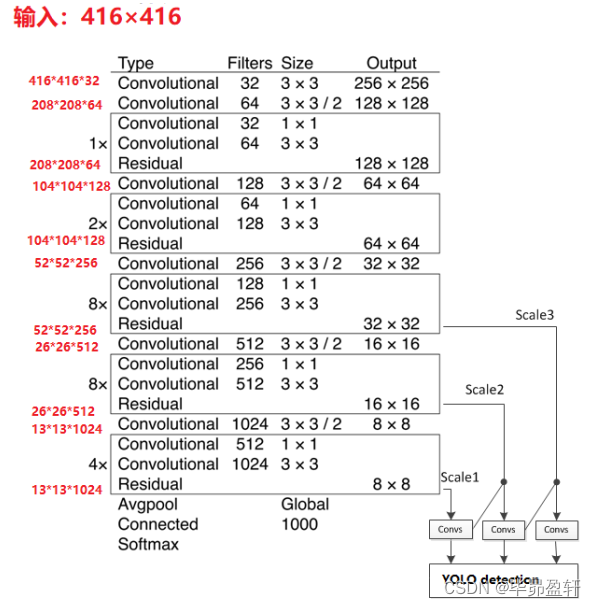
YOLOv3骨干网络结构:DarkNet-53
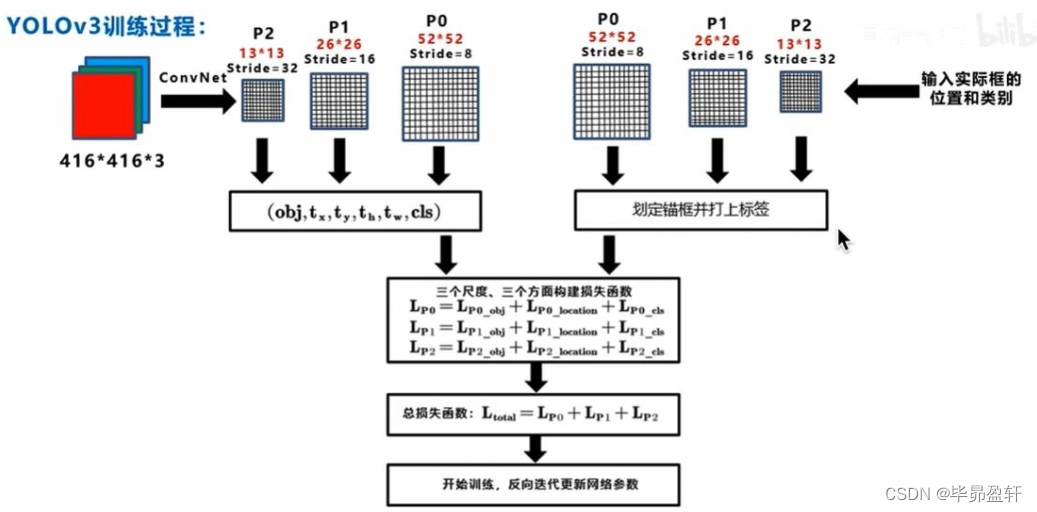
YOLOv3训练过程:
五、语义分割与FCN
5.1 语义分割问题
语义分割:找到同一画面中的不同类型目标区域。
发展:
目标:
对图中每一个像素进行分类,得到对应标签。
5.2 FCN网络
FCN网络结构:
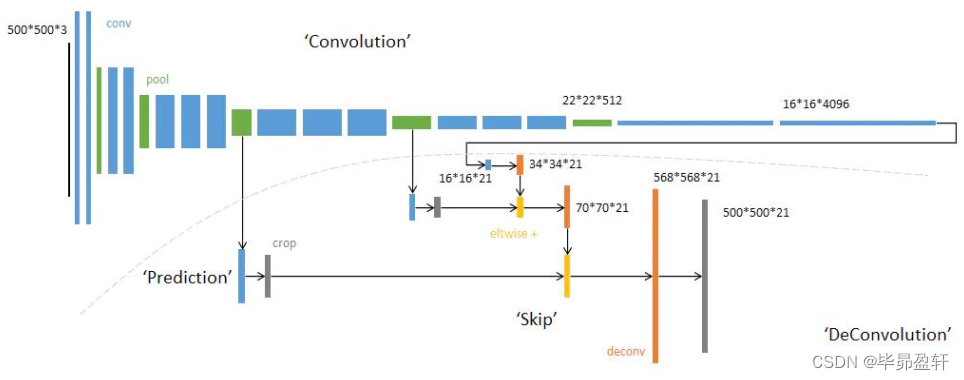
网络结构分为两个部分:全卷积部分和反卷积部分。全卷积部分借用了一些经典的CNN网络,并把最后的全连接层换成卷积,用于提取特征,形成热点图;反卷积部分则是将小尺寸的热点图上采样得到原尺寸的语义分割图像。
卷积部分:
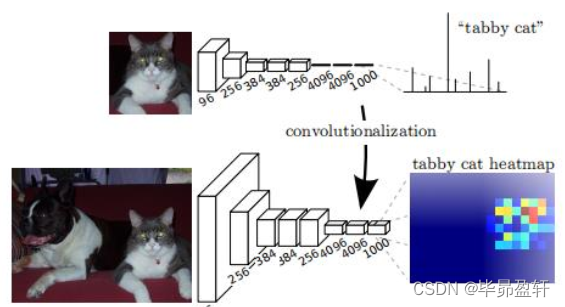
输出的特征图(称为heatmap) , 颜色越贴近红色表示对应数值越大。
反卷积部分:跳级结构
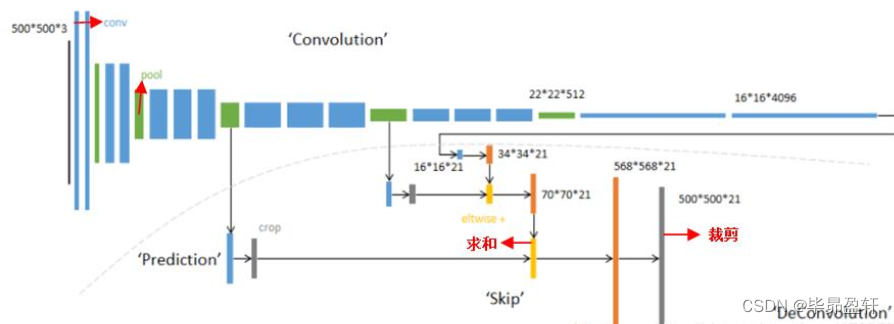
蓝色:卷积层;绿色: Max Pooling层;黄色: 求和运算;灰色: 裁剪。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









