







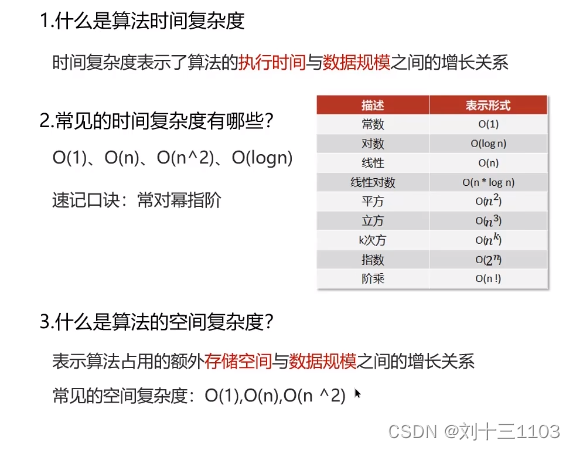
算法复杂度分析:
时间复杂度分析:

常见的复杂度表现形式:
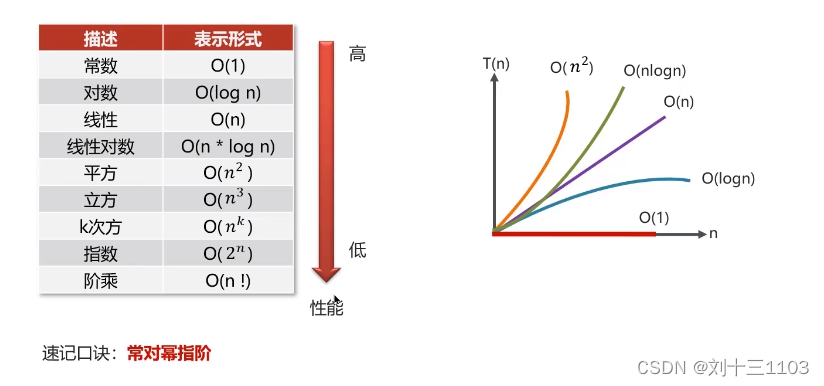
空间复杂度:

总结:
ArrayList----数组 :
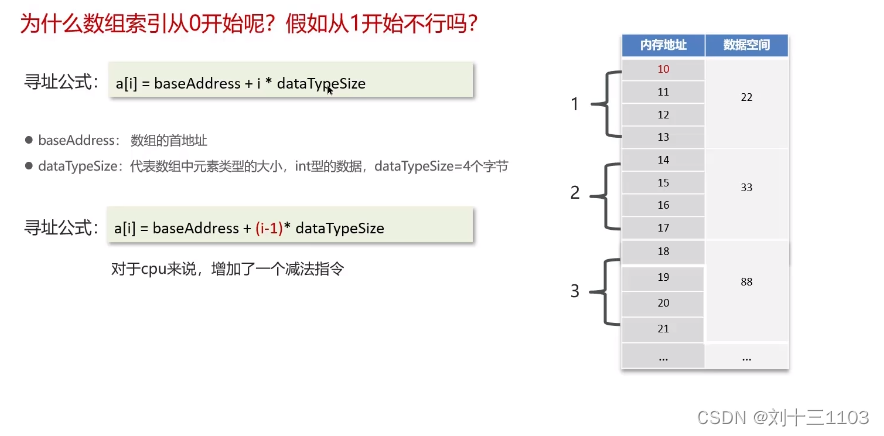
1.在根据数据索引获取元素的时候,会用索引和寻址公式来计算内存所对应的元素数据,寻址公式是:数组的首地址+索引乘以存储数据的类型大小
2.如果数组的索引从1开始,寻址公式中,就需要增加一次减法操作,对于CPU来说就多了一次指令,性能不高。
总结:
1.数组(Array)是一种用连续的内存空间存储相同数据类型数据的线性数据结构。
2.数组下标为什么从0开始:
寻址公式是:baseAddress+i*dataTypeSize,计算下标的内存地址效率较高
3.查找的事假复杂度:
随机查询的时间复杂度是O(1)
查找元素(未知下标)的时间复杂度是O(n)
查找元素(未知下标但排序)通过二分查找的时间复杂度是O(logn)
4.插入和删除时间复杂度
插入和删除的时候,为了保证数据的内存连续性,需要挪动数组元素,平均时间复杂度为O(n)
ArrayList底层的实现原理是什么:

如何实现数组和List之间的转换:

LinkList:

ArrayList和LinkList的区别:

HashMap:
二叉树分类:
满二叉树
完全二叉树
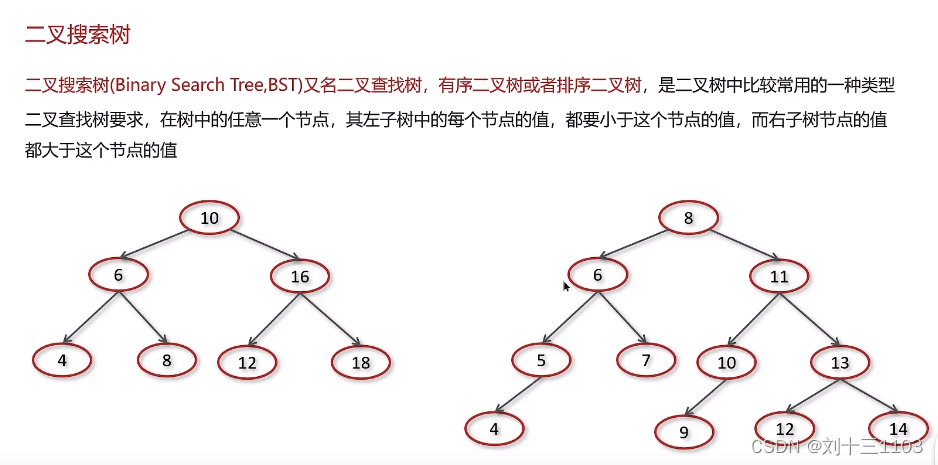
二叉搜索树
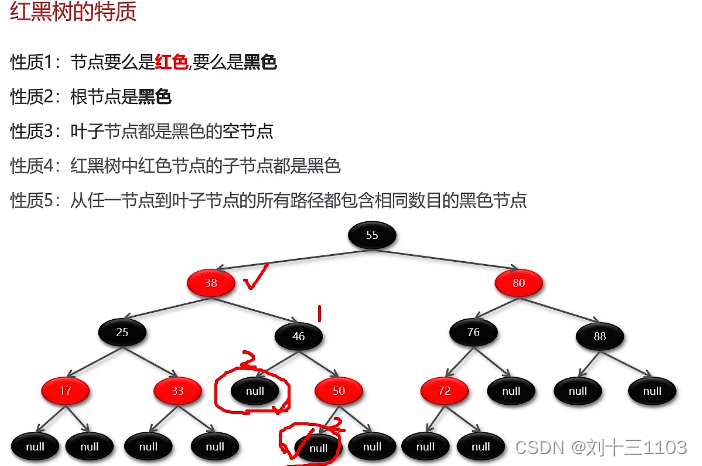
红黑树
二叉搜索树:
红黑树:
总结:
红黑树是一种自平衡的二叉搜索树
所有的红黑规则都是希望红黑树能够保证平衡
红黑树的时间复杂度:查找、添加、删除都是O(logn)
数据结构---散列表(哈希表):
散列表又名哈希表/Hash表,是根据键(Key)直接访问在内存存储位置值(Value)的数据结构,它是由数组演化而来的,利用了数组支持按照下标进行随机访问数据的特性
散列冲突
散列冲突---链表法(拉链)
总结:
1.什么是散列表
散列表又名哈希表/Hash表
根据键(Key)直接访问在内存存储位置值(Value)的数据结构
由数组演化而来的,利用了数组支持按照下标进行随机访问数据
2.散列冲突:
又称哈希冲突、哈希碰撞
多个key映射到同一个数组下标位置
3.散列冲突--链表法
数组的每个下标位置称之为桶或者槽
每个桶会对应一条链表
hash冲突后的元素都放到相同槽位对应的链表总或红黑树中
HashMap的实现原理:
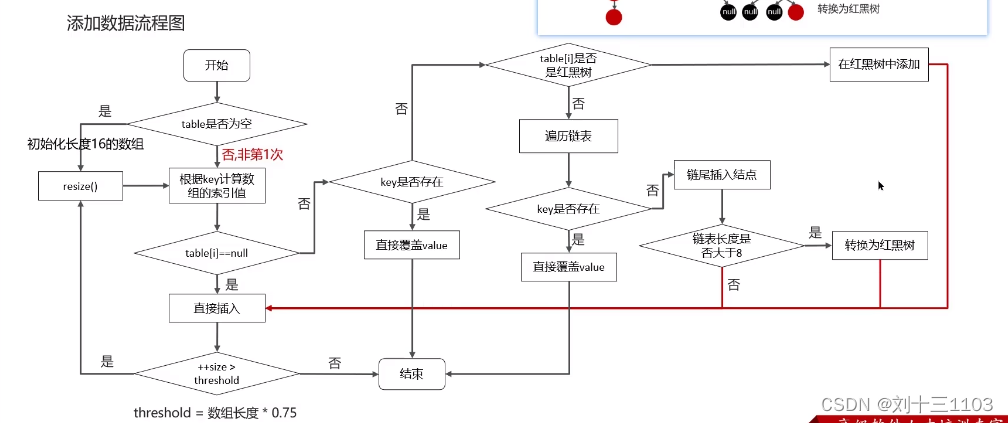
1.底层使用hash表数据结构,即数组+(链表|红黑树)
添加数据时,计算key的值确定元素在数组中的下标
-->key相同则替换
-->不同则存入链表或红黑树中
获取数据通过key的hash计算数组下标获取元素
2.HashMap的jkd1.7和jdk1.8有什么区别
JDK1.8之前采用的拉链法,数组+链表
JDK1.8之后采用数组+链表+红黑树,链表长度大于8且数组长度大于64则会从链表转化为红黑树
HashMap的put方法的具体流程:
添加数据流程图:

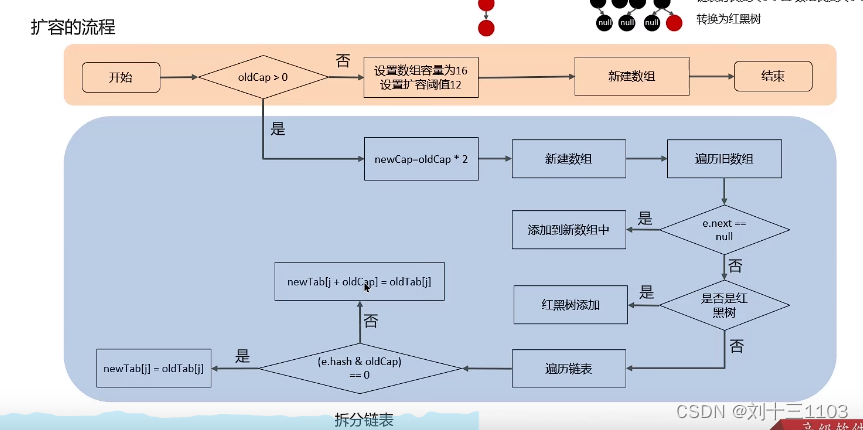
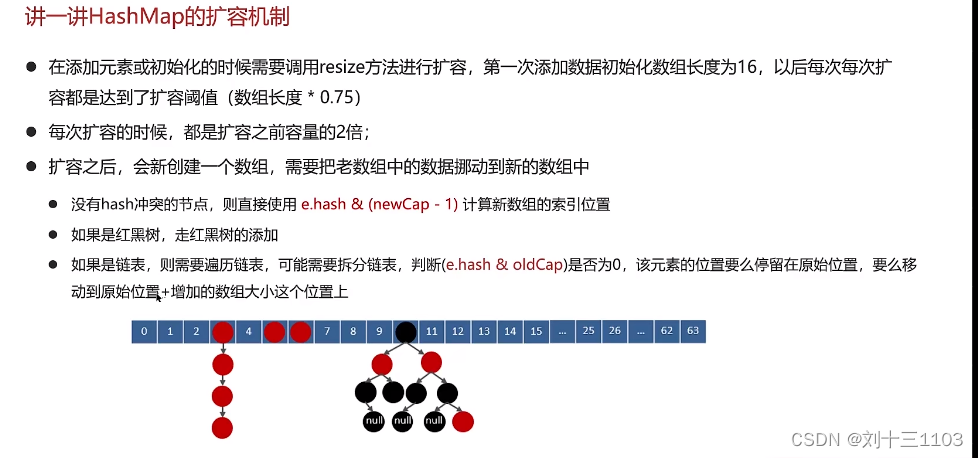
HashMap的扩容机制:
HashMap寻址算法:

HashMap在jdk1.7的多线程死循环问题 :
















 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









