






大家好,我是南枫,在这篇Python技术文章中,我将介绍如何使用Python爬虫来爬取中国水效标识网4686页(一页数据为15条)数据,并将其保存在本地数据库中。

我们需要爬取的数据是点击“详细”按钮,才能看到的具体数据:
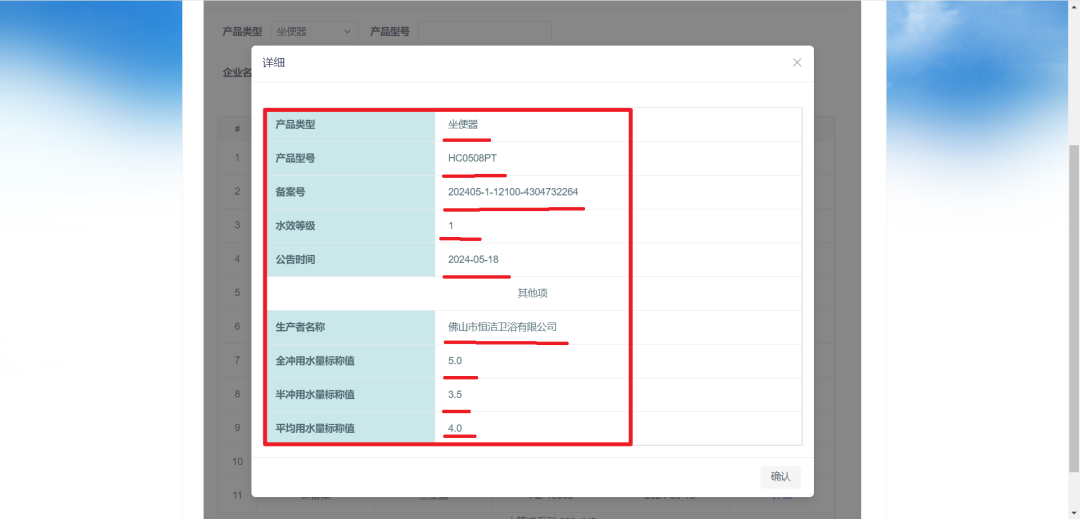
我以红线标出来的数据就是我们需要使用爬虫技术爬取下来,并保存到数据库里的,那么,我们首先先使用爬虫技术来把这些数据都爬下来(跟紧南枫步伐,不要掉队)
首先,我们需要找到数据所在位置,找到之后才能对他进行爬取:
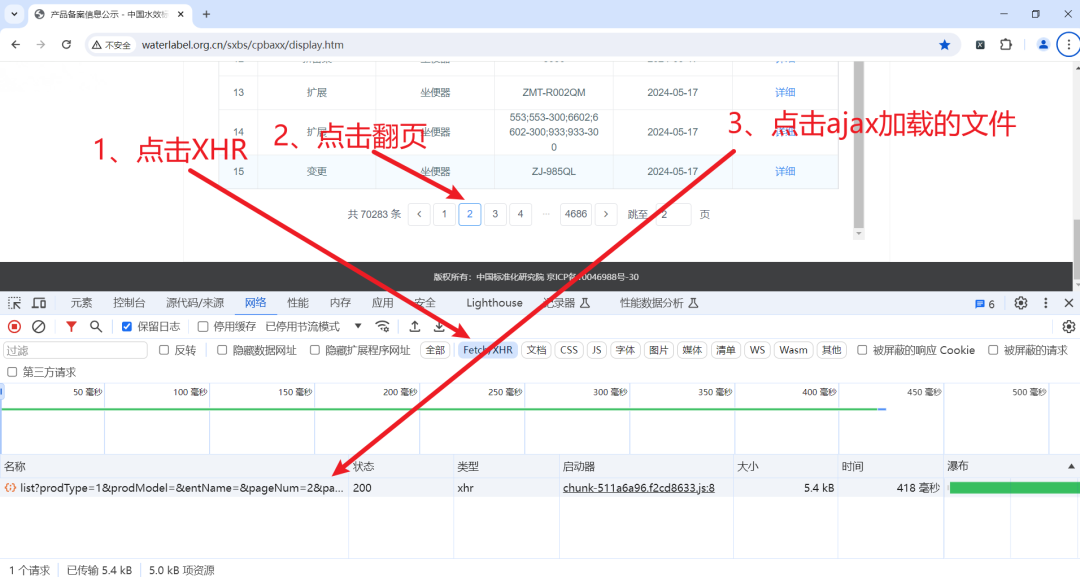
点击之后
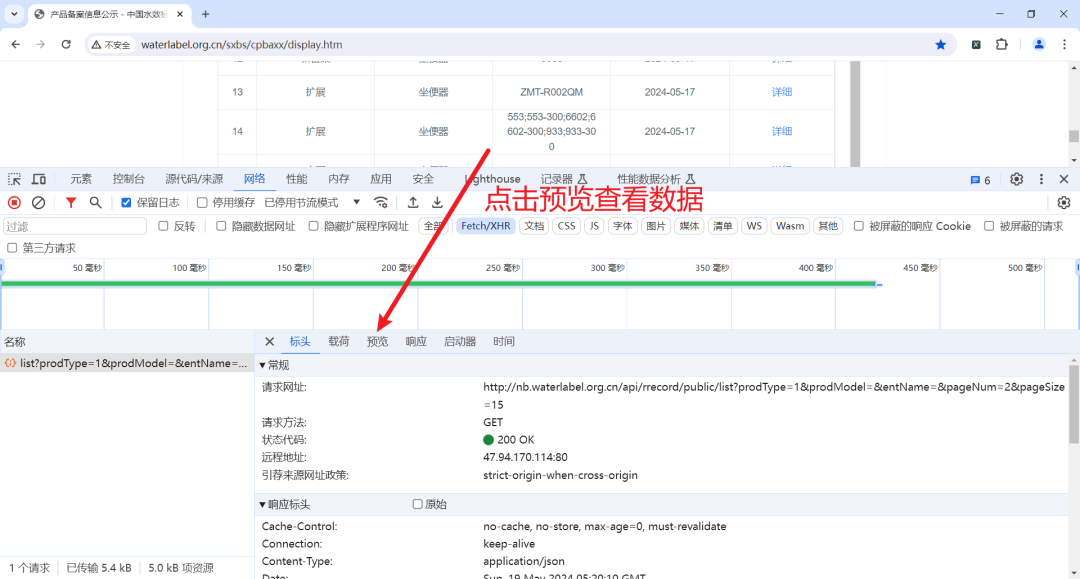
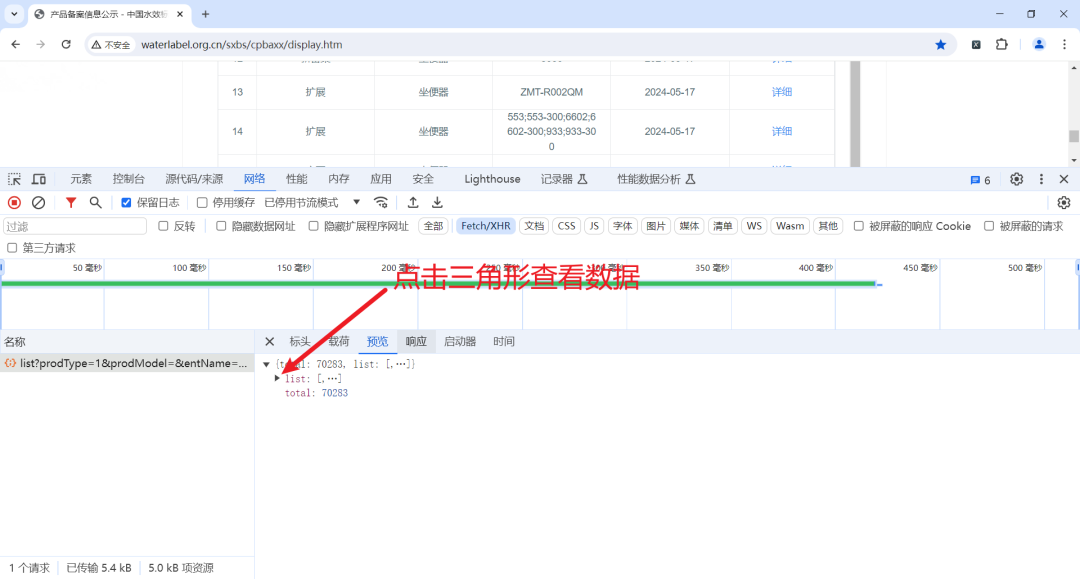
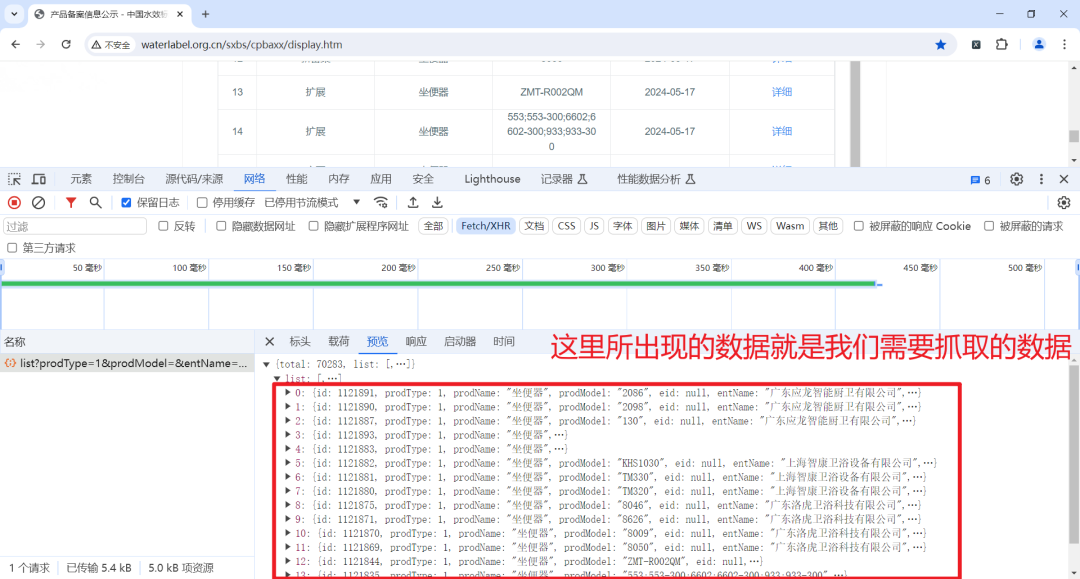
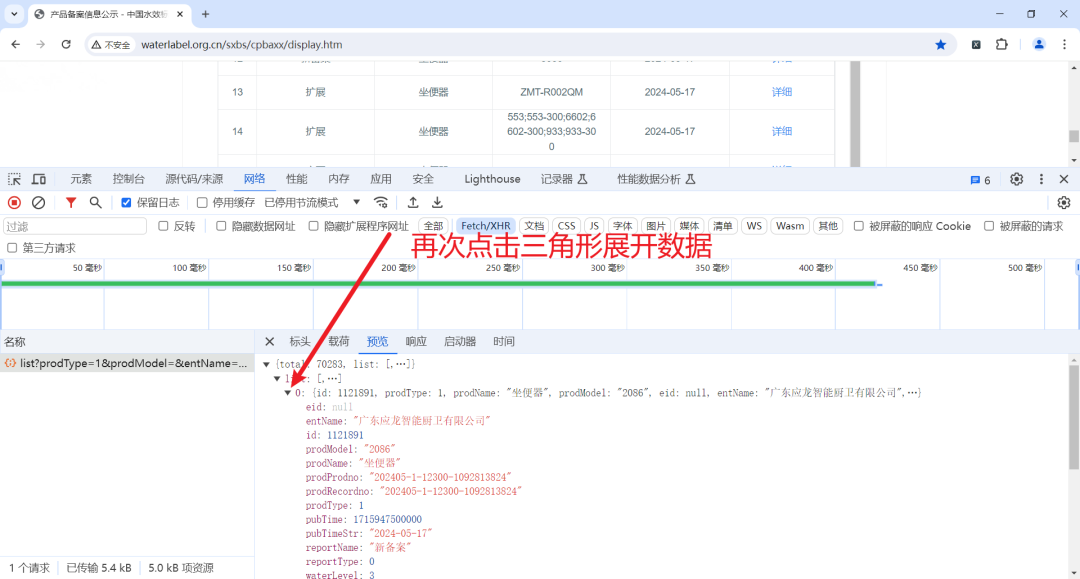
此时我们看到的所有内容皆为我们需要爬取的数据,那么接下来就是要把数据爬取下来。
导入对应模块,对找到的ajax加载文件进行发送请求,获取到对应的所有数据。

在这里我们可以打印json_data来查看一下数据是说明类型的
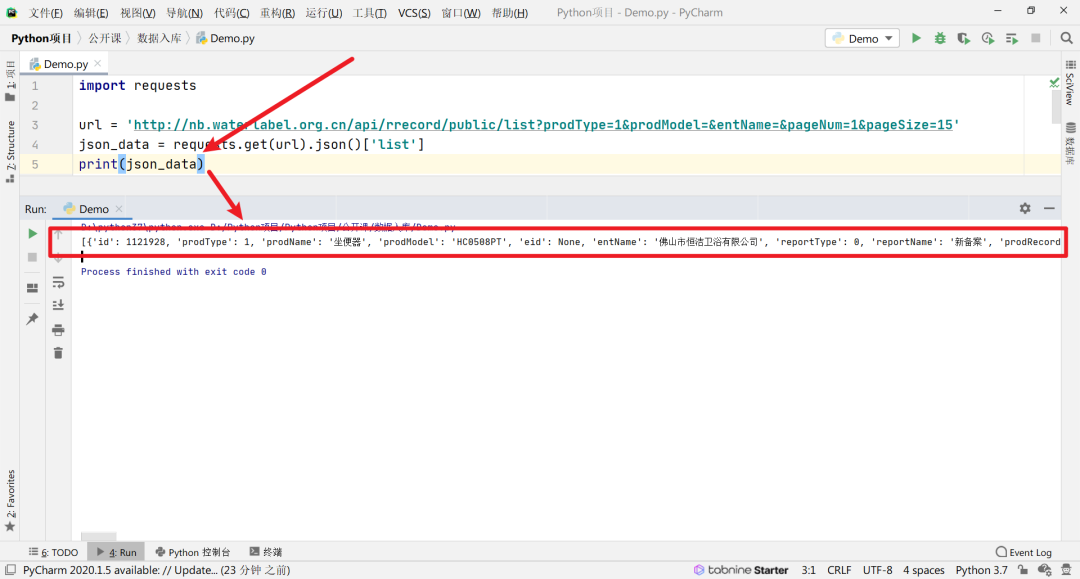
可以看到我们现在的数据,是在列表中,那么我们就需要把数据从列表中通过循环拿出来。
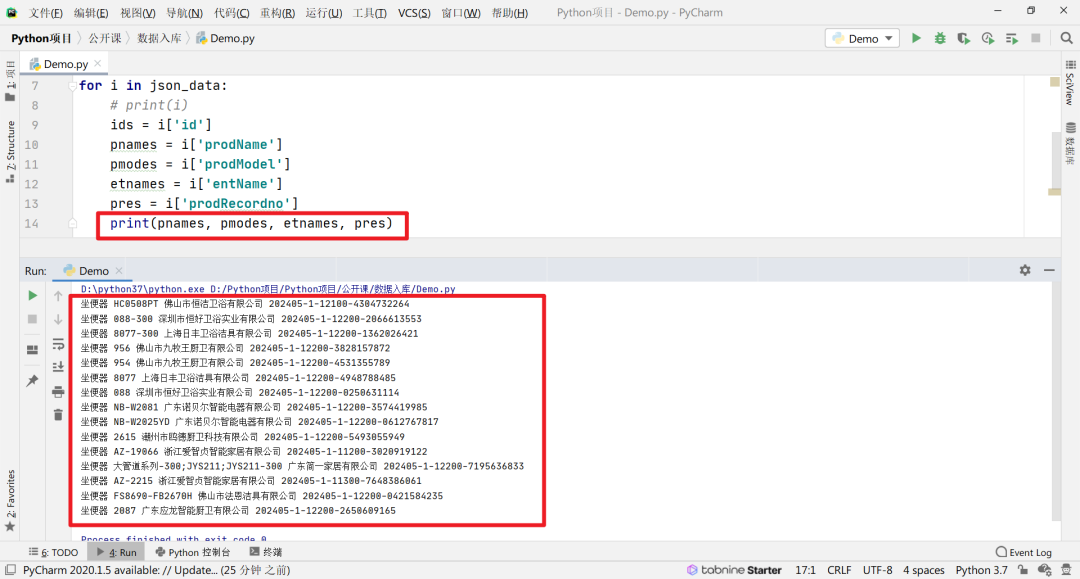
这便是我们通过循环所获取到的数据。
那现在数据已经获取下来了,我们又该如何保存到数据库中去呢?

首先我们要下载Navicat,一个数据库可视化软件,再去下载mongodb或者mysql数据库,下载完成之后才能进行接下来的操作。
在这里我已经以光速下载好了,准备好之后,我们接下来就可以去把数据保存进我们数据库中啦,接着跟紧南枫来操作吧~
为什么要写这些代码?写这些代码有什么作用?我都在Pycharm里面写好注释了,大家自行观看、文明观看、禁止投喂,谢谢~(感觉有点像动物园宣传语)
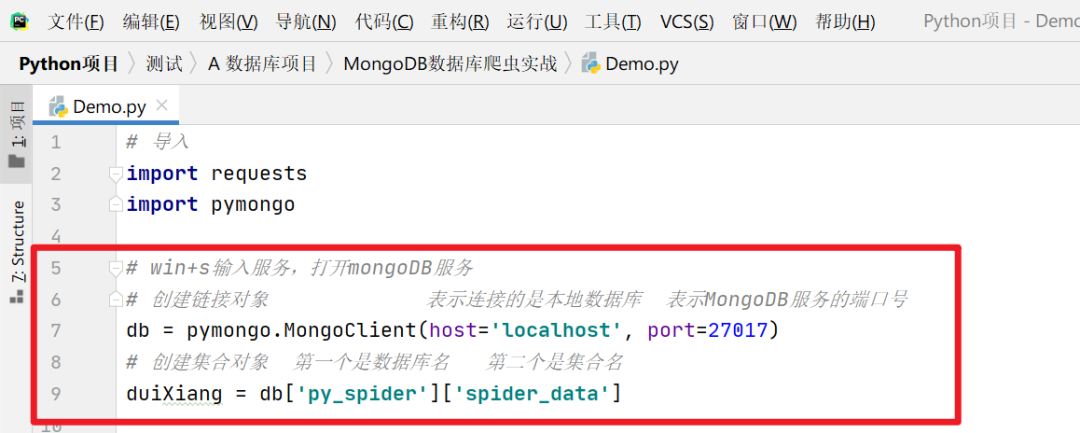
重点是我用红色框标注的内容
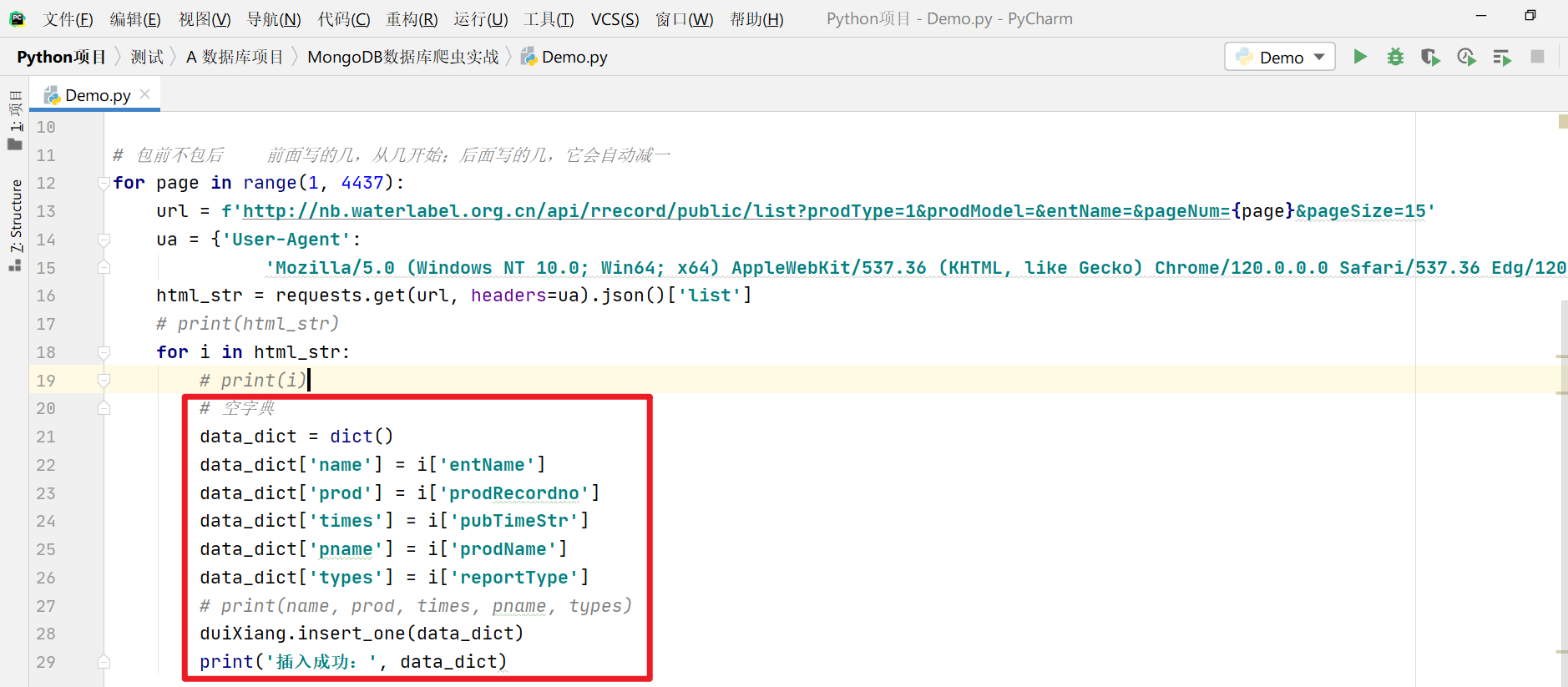
这里就有人会在评论区问了:“哎呀,你12行写的for是什么呀?”没错,我预判了你们的预判,这里所写的就是range,为了就是起到翻页的效果,我在文章开头就已经说了,我们要爬取4686页的数据,那我们每爬一页,是不是就得翻一页呢?这样数据才会出来呀,对吧,据我观察,翻页只需要去改变他的page值就行
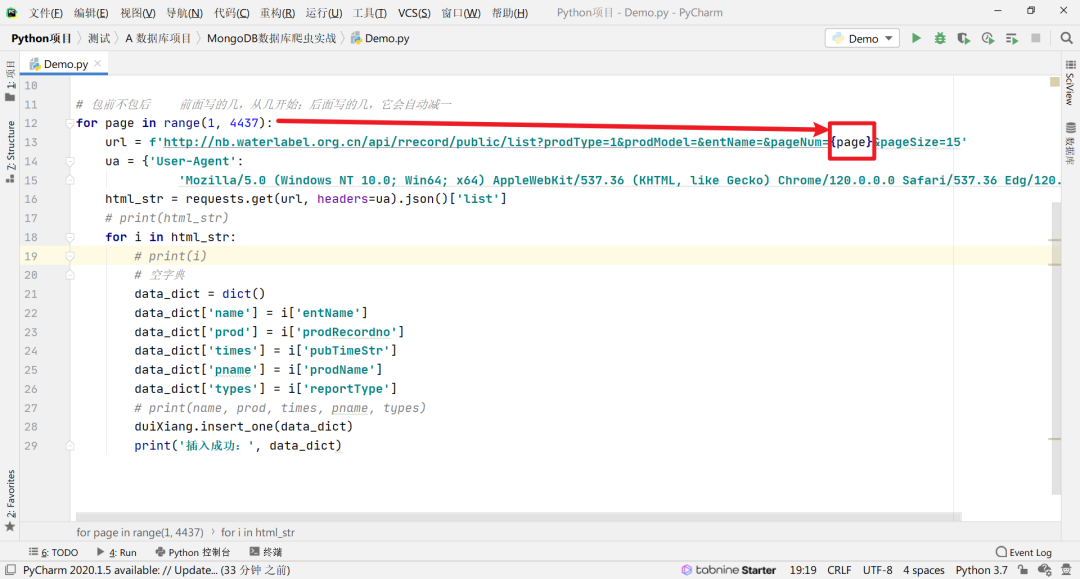
如果有实践党,那么可以去看看官网,是不是这样滴。
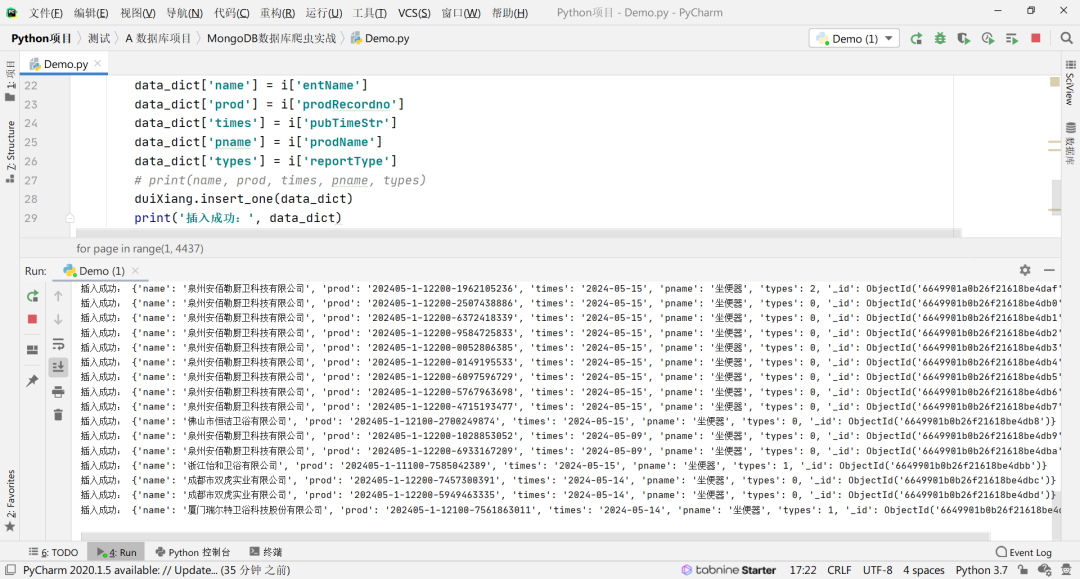
这个就是我把数据“插入”到数据库的截图,当然这里是会动得,但是我不知道咋录动图,所以不知道搞(理直气壮),我们看看数据库里是否已经有数据保存进来:
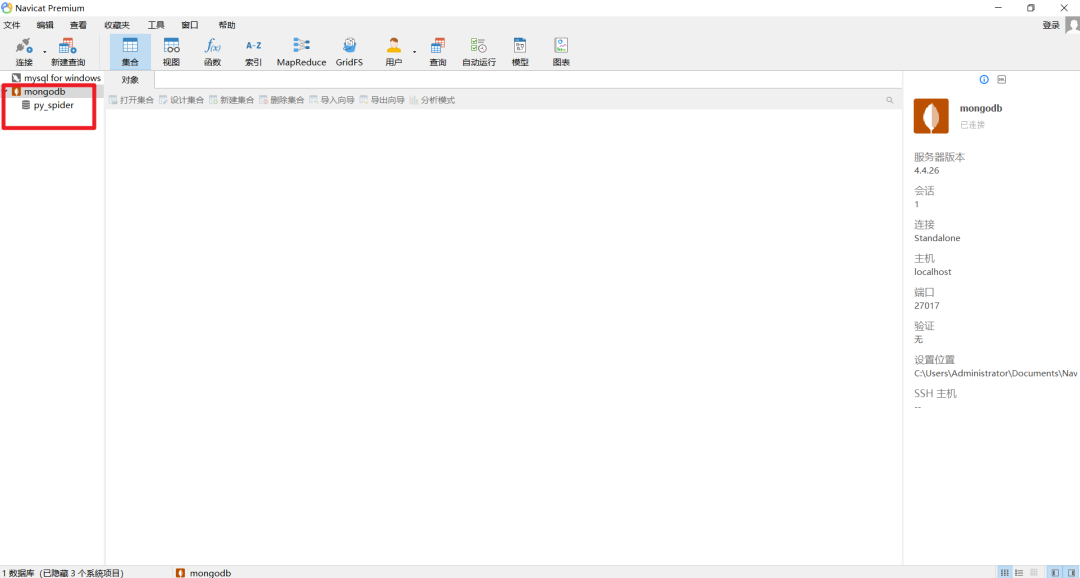
打开之后可以看到,mongodb里面已经有一个数据库表出来了
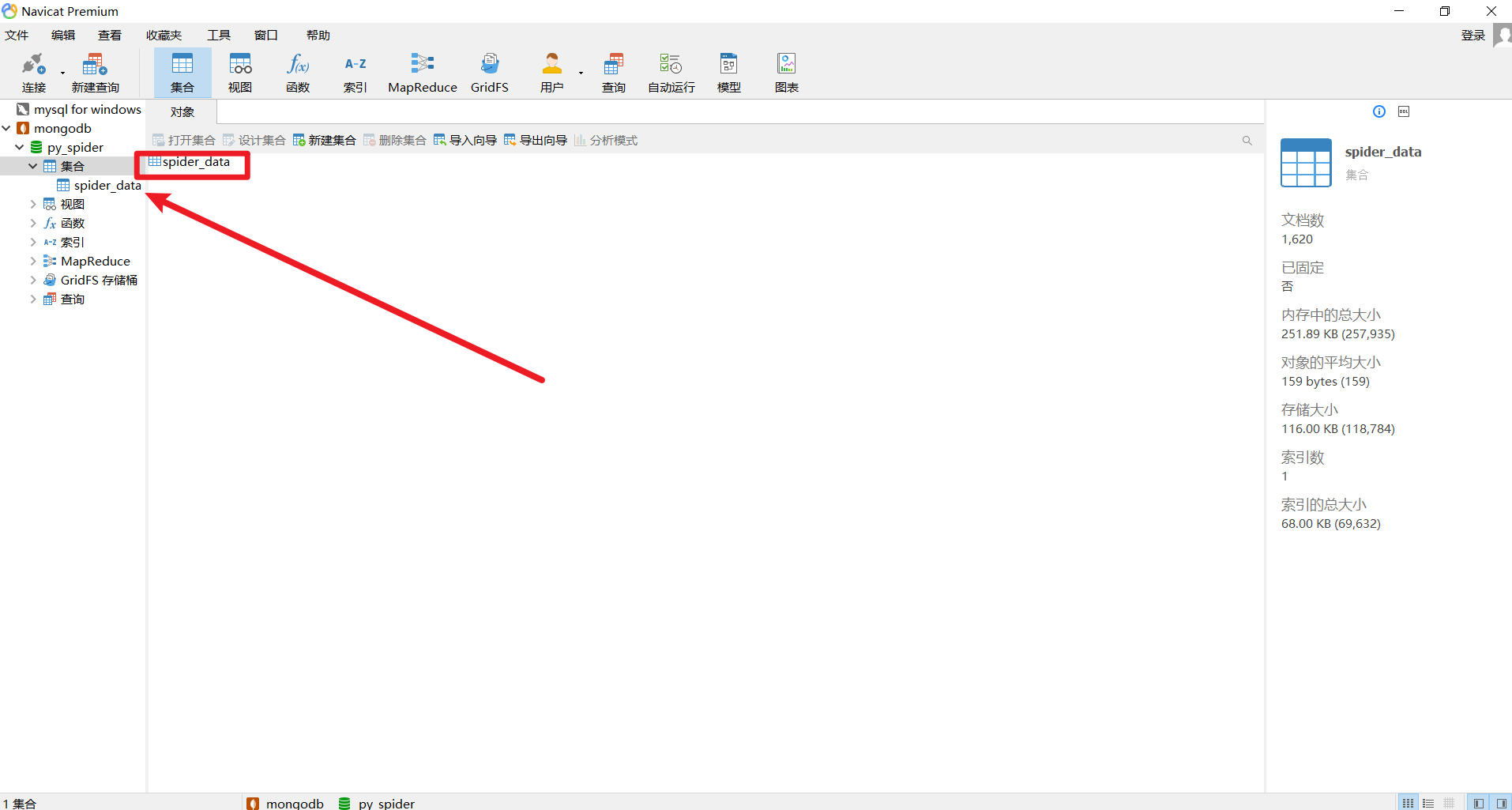
表里面也有一个集合,那么数据是否在集合里面呢?不要眨眼,看下图:
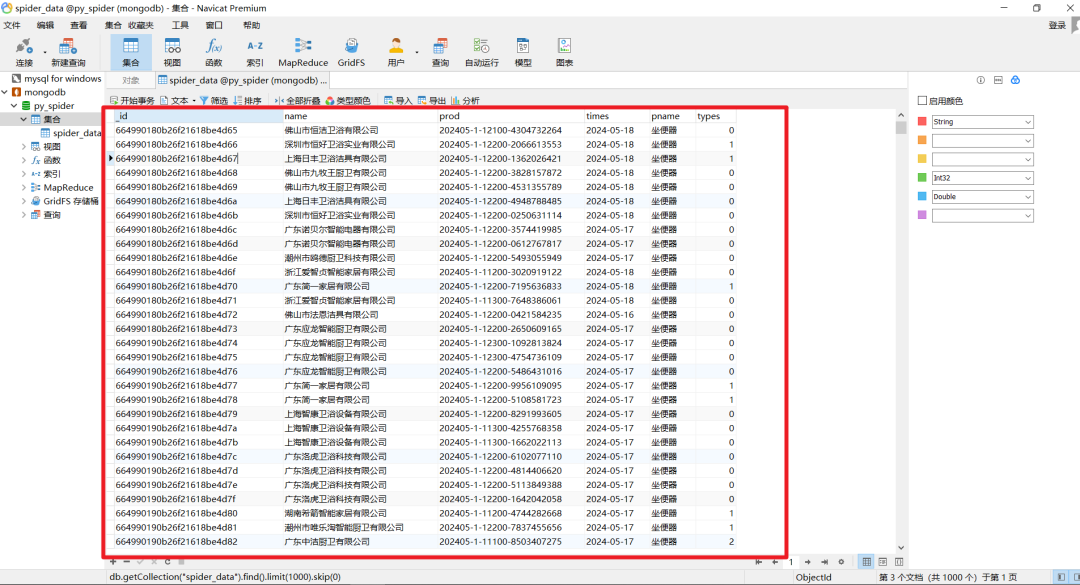
(掌声在哪里!?)
Ok,这个数据入库项目,你学会没有?
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









