






这里是一篇中文翻译。“Unsafe Python”是指可能导致安全风险或内存安全问题的技术。作者使用pygame 和 OpenCV 来处理图像缩放任务,发现性能差距很大,原因是由numpy 数组的内存布局(strides)引起的,最后通过优化内存访问模式来提升性能。
我们将使用“不安全”的Python将一些Numpy代码加速100倍。假设你在用pygame编写一个游戏,并且你需要经常调整图像大小。我们可以使用pygame或openCV调整图像大小:
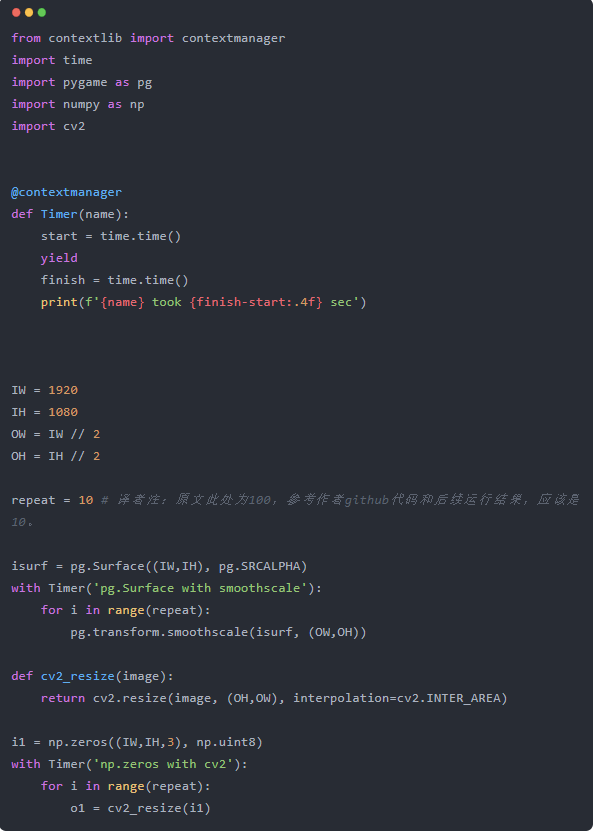
输出为:

使用openCV加速了10倍,所以我们回到游戏中,使用pygame.surfarray.pixels3d以零拷贝的方式访问像素作为Numpy数组,然后使用cv2.resize,然而,一切都变慢了!
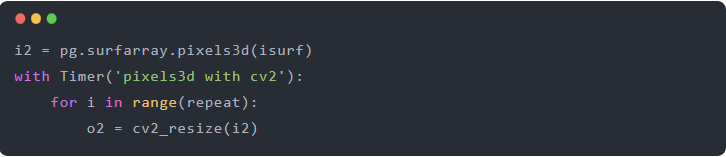
结果:

如果你去查看数组的.shape和.dtype,会发现他俩一样。但是,同一个函数(cv2_resize)在一个数组上运行比另一个数组慢 100 倍,为什么捏?SDL 应该不会在一些特别难以访问的 RAM 区域分配像素(即使它在理论上可以通过内核的一点帮助来做到这一点,比如创建一个不可缓存的内存区域之类的)。或者Surface存储在 GPU 中,通过 PCI 获取每个像素?!它不是这样工作的,是吗?-这些东西有一些可怕的内存一致性协议,我错过了什么吗?如果不是——如果它们是相同形状和大小的相同类型的内存——是什么不同导致我们减速 100 倍?
结果证明...我承认我是偶然发现的,在放弃这个并转向其他事情之后。完全偶然的是,那个其他事情涉及将 numpy 数据传递给 C 代码,所以我不得不学习这个数据在 C 中的样子。所以,事实证明,shape和datatype并不是 numpy 数组的全部:

结果,输出的步幅(stride)是不同的:

所以是步幅的差异导致了代码慢了100倍?我们可以修复这个问题吗?但首先我们要去解释为什么步幅不同。
numpy array内存布局
所以步幅(stride)是什么?步幅告诉您从一个像素到下一个像素需要跨越多少字节。例如,假设我们有一个三维数组,比如一个 RGB 图像。然后,给定数组的基指针和三个步幅, array[x,y,z]的地址将是 base+x∗xstride+y∗ystride+z∗zstride (对于图像,z 的值为 0、1 或 2,分别对应 RGB 图像的三个通道之一)。
换句话说,步幅定义了数组在内存中的布局。无论好坏,numpy 在数组形状和数据类型方面非常灵活,因为它支持许多不同的步幅值。
手头的两种布局 : numpy 的默认布局和 SDL 的布局 - 嗯,我甚至不知道哪个更冒犯我。从步幅值可以看出,numpy 默认用于 3D 数组的布局是 base+x∗3∗height+y∗3+z 。

这意味着一个像素的 RGB 值存储在 3 个相邻的字节中,一列的像素在内存中连续存储 - 以列为主序。我觉得这种方法很冒犯,因为图像传统上是以行为主序存储的,尤其是图像传感器以这种方式发送图像(并以这种方式捕捉图像,正如您可以从滚动快门看到的 - 每一行在稍微不同的时间点进行捕捉,而不是按列进行)
“为什么,我们确实也遵循这一受人尊敬的传统,”流行的基于numpy的图像库说道。“看看你自己——将一个形状为 (1920, 1080) 的数组保存为 PNG 文件,你会得到一张 1080x1920 的图像”。这是真的,当然这使情况变得更糟:如果你使用 arr[x,y] 进行索引,那么 x,也就是维度零,实际上对应于相应 PNG 文件中的垂直维度;而 y,也就是维度一,对应于水平维度。因此,numpy 数组的列对应于 PNG 图像的行。这在某种意义上使 numpy 图像布局成为"行优先",但代价是 x 和 y 的含义与通常相反。
...除非你从 pygame Surface 对象中获取 numpy 数组,否则 x 实际上是索引到水平维度的。因此,相对于 pygame.image.save(surface) 创建的 PNG 文件,使用 imageio 保存 pixels3d(surface) 将会产生一个转置的 PNG。而且,如果这种侮辱还不够,cv2.resize 使用 (width, height) 元组作为目标大小,将产生一个形状为 (height, width) 的输出数组。
在这些侮辱和伤害的背景下,SDL 拥有一个诱人的、文明的布局,其中 x 是 x,y 是 y,数据以诚实的行优先顺序存储,对于“行”的所有含义都是如此。但是仔细一看,这个布局只是践踏了我的感情: base+x∗4+y∗4∗width−z 。
像是我们在步幅中有 4 而不是 3 的部分,对于 RGB 图像我可以理解。当我们将 SRCALPHA 传递给 Surface 构造函数时,我们确实要求一个带有 alpha 通道的 RGBA 图像。所以我猜它将 alpha 通道与 RGB 像素一起保留,并且步幅中的 4 需要跳过 RBGA 中的 A。但是,我想问,为什么有单独的 pixels3d 和 pixels_alpha 函数?在使用 numpy 和 pygame Surface时,分别处理 RGB 和 alpha 总是很麻烦。为什么不是一个单一的 pixels4d 函数呢?
...好吧,4 而不是 3 我可以接受。但是 zstride 为-1?负一?你从红色像素的地址开始,要到绿色,你要往回走一个字节?!现在你只是在拿我开玩笑。
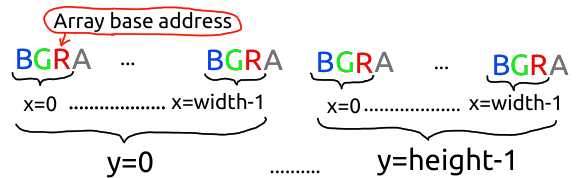
原来 SDL 支持 RGB 和 BGR 布局(特别是,显然从文件加载的surface是 RGB,而在内存中创建的surface是 BGR?..或者比这更复杂?..)如果您使用 pygame 的 API,则无需担心 RGB 与 BGR,API 会透明地处理它。如果您使用 pixels3d 进行 numpy 互操作,您也无需担心 RGB 与 BGR,因为 numpy 的步幅灵活性使 pygame 可以为您提供一个看起来像 RGB 的数组,尽管它在内存中是 BGR。为此,z 步幅设置为-1,并且数组的基指针指向第一个像素的红色值-比数组内存开始的位置提前两个像素,即第一个像素的蓝色值所在的位置。
等一下......现在我明白为什么我们有 pixels3d 和 pixels_alpha,但没有 pixels4d 了!!因为 SDL 有 RGBA 和 BGRA 图像——BGRA,而不是 ABGR——你无法使 BGRA 数据看起来像一个 RGBA numpy 数组,无论你使用怎样奇怪的步幅值。布局灵活性是有限的......或者更确切地说,实际上没有任何限制超过可计算限制,但幸运的是 numpy 止步于可配置步幅,并不允许您为完全可编程的布局 指定一个通用回调函数 addr(base, x, y, z) 。
为了透明地支持 RGBA 和 BGRA,pygame 被迫给我们提供 2 个 numpy 数组 - 一个用于 RGB(或 BGR,取决于surface),另一个用于 alpha 通道。这些 numpy 数组具有正确的形状,并让我们访问正确的数据,但它们的布局与其形状的普通数组非常不同。
不同的内存布局肯定可以解释性能上的主要差异。我们可以试图弄清楚为什么性能差异几乎是 100 倍。但是如果可能的话,我更愿意摆脱垃圾,而不是详细研究它。所以,我们不会深入理解这个问题,而是简单地展示布局差异确实解释了 100 倍的差异,然后在不改变布局的情况下摆脱减速,这就是“不安全的 Python”最终发挥作用的地方。
如何证明仅仅是布局,而不是 pygame Surface 数据的其他属性(比如分配的内存)导致了减速?我们可以对一个我们自己创建的具有与 pixels3d 相同布局的 numpy 数组进行 cv2.resize 的基准测试。
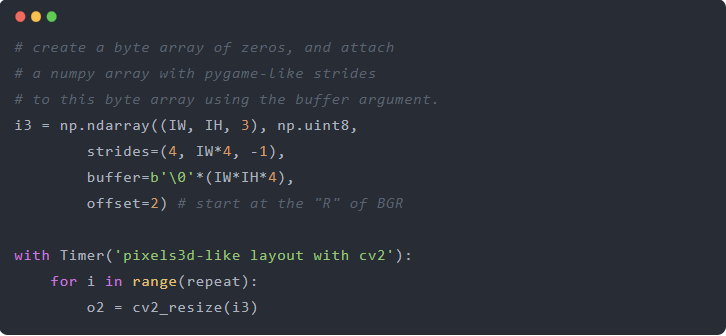
确实,这几乎和我们在 pygame Surface 数据上测量的一样慢:

出于好奇,我们可以检查如果仅仅在这些布局之间复制数据会发生什么:
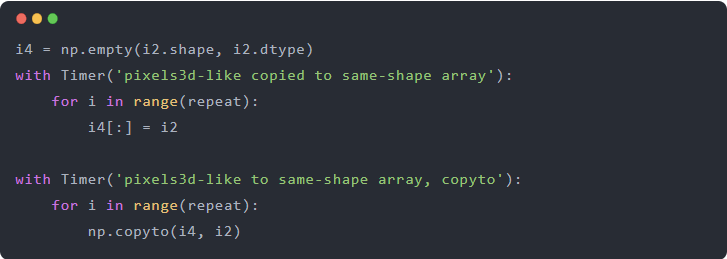
赋值运算符和 copyto 都非常慢,几乎和 cv2.resize 一样慢。

愚弄代码以使其运行更快
我们能做什么?我们无法改变 pygame Surface 数据的布局。我们也绝对不想复制 cv2.resize 的 C++代码,因为它具有各种平台特定的优化,看看我们是否能够适应 Surface 布局而不会丢失性能。我们可以做的是使用带有 numpy 默认布局的数组将 Surface 数据馈送给 cv2.resize(而不是直接传递由 pixel3d 返回的数组对象)。
请注意,这实际上并不适用于任何给定的函数。但它将特别适用于调整大小,因为它实际上并不关心数据的某些方面,我们实际上会公然歪曲:
-
• 调整大小的代码不在乎特定通道代表红色还是蓝色。(与将 RGB 转换为灰度不同,后者会在意。)如果您给出 BGR 数据并谎称它是 RGB,则代码将产生与给出实际 RGB 数据时相同的结果。
-
• 同样,调整大小时,数组维度代表宽度和高度的顺序并不重要。
现在,让我们再次来看看 pygame 的 BGRA 数组的内存表示,其形状是 (width, height) 。
这个表示实际上与一个形状为 (height, width) 的 RGBA 数组具有 numpy 的默认步幅是一样的!我的意思是,不完全一样 - 如果我们将这个数据重新解释为 RGBA 数组,我们将红色通道(R)的值视为蓝色(B),反之亦然。同样地,如果我们将这个数据重新解释为一个具有 numpy 的默认步幅的 (height, width) 数组,我们将隐式地对图像进行转置。但是调整大小并不在乎!
而且,作为额外的好处,我们将得到一个单独的 RGBA 数组,并且只需要一次调用 cv2.resize 来调整大小,而不是分别调整 pixels3d 和 pixels_alpha。耶!
下面的一段代码接收一个 Pygame surface并返回底层 RGBA 或 BGRA 数组的基础指针,以及一个指示它是 BGR 还是 RGB 的标志
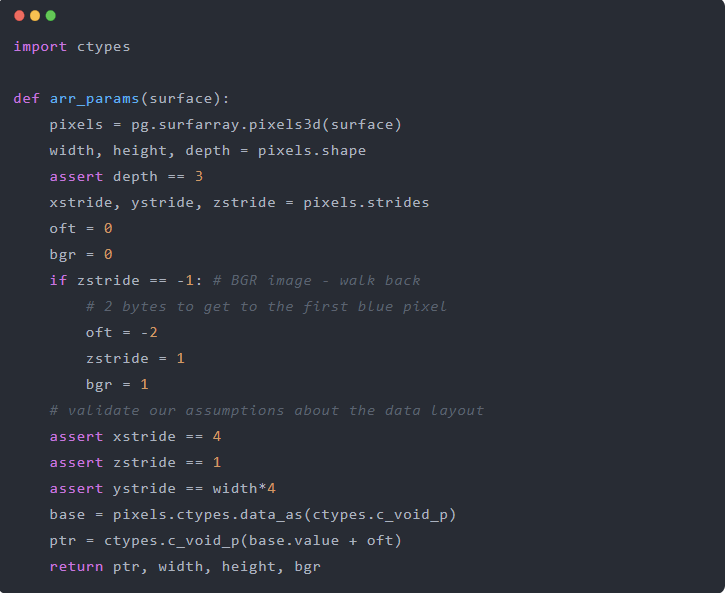
既然我们获得了像素数据的基础 C 指针,我们可以使用默认步长将其包装在一个 numpy 数组中,隐式转置图像并交换 R&B 通道。一旦我们将带有默认步长的 numpy 数组“附加”到输入和输出数据上,我们对 cv2.resize 的调用将快 100 倍!

果然,我们最终从使用 cv2.resize 对 Surface 数据进行调整中获得了加速而不是减速,我们的速度与调整 RGBA numpy.zeros 数组相同(最初我们对 RGB 数组进行基准测试,而不是 RGBA)
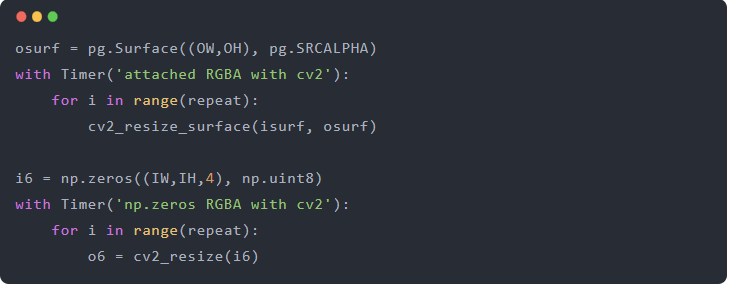
基准测试显示我们获得了 100 倍的回报:

上面所有丑陋的代码都在 GitHub[2] 上。由于这些代码很丑陋,你不能确定它是否正确地调整了图像大小,因此还有一些代码在那里测试非零图像的调整大小。如果你运行它,你将得到以下华丽的输出图像:

我们真的获得了 100 倍的加速吗?这取决于你如何计算。相对于直接使用 pixel3d 数组调用它,我们使 cv2.resize 的运行速度提高了 100 倍。但是特别是对于调整大小,pygame 有 smoothscale,相对于它,我们的加速比是 13-15 倍。在 GitHub 上还有一些其他函数的基准测试,其中一些没有相应的 pygame API。
-
• copying with dis[:] = src : 28x
-
• Inverting with dst[:] 255-src: 24x
-
• cv2.warpAffine: 12x
-
• cv2.mediaBlur: 15x
-
• cv2.GaussianBlur: 200x
无论如何,我会感到惊讶,如果有很多人使用 Python 从 SDL 来处理这个特定问题,以便使这个问题得到广泛的关注。但我猜测,具有奇怪布局的 numpy 数组也可能在其他地方出现,因此这种技巧可能在其他地方也是相关的。
Unsafe Python
上面的代码使用“C 风格的知识”来加快速度(Python 通常会隐藏数据布局,而 C 则会自豪地暴露它。)不幸的是,它具有 C 的内存(不)安全性 - 我们获得了像素数据的 C 基指针,从那一点开始,如果我们搞砸了指针算术,或者在数据被释放后继续使用数据,我们就会崩溃或损坏数据。然而我们没有编写任何 C 代码 - 这全部都是 Python。
Rust 有一个"unsafe"关键字,编译器强制你意识到你正在调用一个会破坏正常安全性保证的 API。但是 Rust 编译器并不会让你把包含 unsafe 代码块的函数标记为"unsafe"。相反,它相信你可以决定你的函数本身是否安全。
在我们的示例中, cv2_resize_surface 是一个安全的 API,假设我没有 Bug,因为没有恐怖逃逸到外部世界 - 在外部,我们只看到输出表面被输出数据填充。但 arr_params 是一个完全不安全的 API,因为它返回一个 C 指针,你可以对其做任何操作。 rgba_buffer 也是不安全的——尽管我们返回一个 numpy 数组,一个“安全”的对象,但在数据被释放后,你仍然可以使用它,例如。在一般情况下,没有静态分析可以告诉你是否从不安全的构建模块构建了安全的东西。
Python 没有 unsafe 关键字 - 这在动态语言和稀疏静态注释方面是符合特点的。但除此之外,Python + ctypes + C 库在精神上有点类似于带有 unsafe 的 Rust。该语言默认是安全的,但在需要时可以使用逃生通道。
《不安全的 Python》是一个通用原则的例证:Python 中大量使用了 C 语言。C 语言是 Python 的邪恶孪生兄弟,或者按时间顺序来说,Python 是 C 语言的友好孪生兄弟。C 语言提供了性能,不关心可用性或安全性;如果其中任何一个导致问题,告诉你的医疗保健提供者,C 语言不感兴趣。另一方面,Python 提供了安全性,并且基于十年来对初学者可用性的研究。不过,Python 不关心性能。它们都针对两种相反的目标进行了激烈的优化,忽视了对方的目标代价。
但更重要的是,Python 从一开始就考虑到了与 C 扩展的兼容性。今天,从我的角度来看,Python 作为一个流行的 C/C++ 库的打包系统。我很少有下载和构建 OpenCV 以在 C++ 中使用它的兴趣,相较于使用 Python 中的 OpenCV 二进制文件,因为 C++ 没有标准的包管理系统,而 Python 有。在 Python 中调用这些高性能库(例如在科学计算和深度学习中)的代码比在 C/C++ 中更多。另一方面,如果想要严格优化的 Python 代码和较小的部署文件大小/低启动时间,你可以使用 Cython 来生成一个“仿写成 C 所写”的扩展,以节省类似 numba 这样“更 Pythonic”的基于 JIT 的系统的开销。
Python 中不仅有很多 C 代码,而且它们是某种意义上的对立物,它们相互补充得相当好。使 Python 代码快速的好方法是以正确的方式使用 C 库。相反,安全使用 C 的好方法是用 C 编写核心,然后在 Python 中编写大量逻辑。Python 和 C/C++/Rust 混合——无论是具有大量 Python 扩展 API 的 C 程序,还是在 C 中完成所有繁重工作的 Python 程序——似乎在高性能、数值、桌面/服务器领域占据主导地位。虽然我不确定这个事实是否非常鼓舞人心,但我认为这是一个事实 ,而且这种情况将会持续很长时间。















 2432
2432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









