







前言
前段时间学习了一点爬虫知识,找到一些网站学习学习,巩固一下。
- python版本:python(3.11.4)
- 网站:豆瓣电影TOP250
- python包:requests(2.31.0),BeautifulSoup(4.12.2),csv,time
练习
思路
通过requests访问该网站,使用beautifulsoup解析网站,将相关内容保存到csv格式文件中。
框架
#爬取前250部电影的名称、评分、导演、链接
def getHTMLText(url):
return ‘’
def getMovieList(html):
return ‘’
def save_to_csv(movielist):
return ‘’
def main():
return ‘’
if __name__ == '__main__':
main()
主要框架就是这样,接下来按照自己的需求一点一点填充就好。
补充代码
getHTMLText(url)
def getHTMLText(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
r = requests.get(url, headers=headers,timeout=30)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常
# print(r.status_code)# 查看状态码
r.encoding = r.apparent_encoding
# print('success')
return r.text
except:
print('error')# 异常处理
return "产生异常"
headers
使用requests访问网站时需要指定相应的headers,告诉网站,现在是真人通过浏览器进行访问,不要拒绝我。

我们可以打开相应网站,按F12,打开开发者工具,点击“网络”查看当前的“User-Agent”
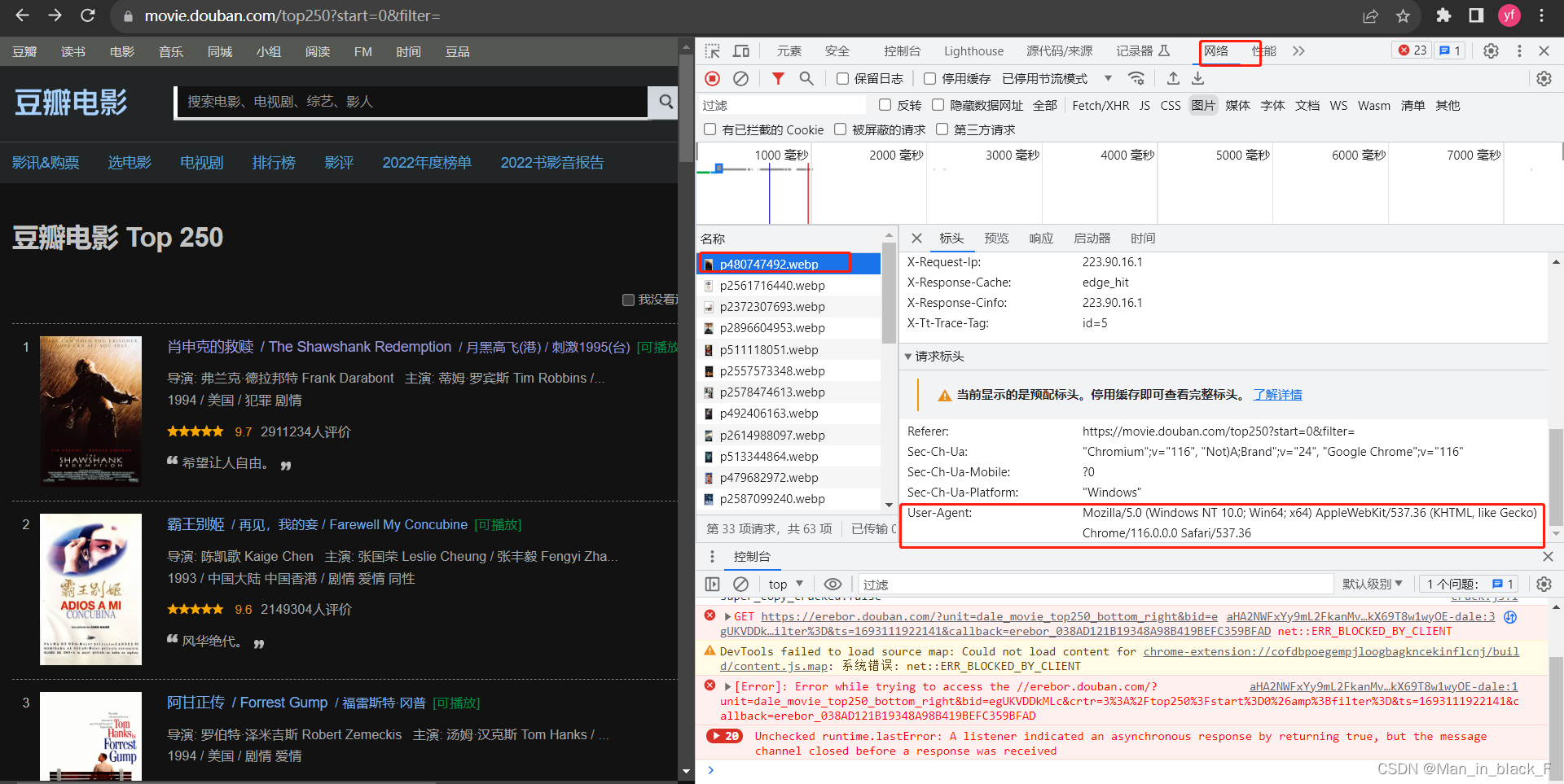
status
为了能够判断我们是否能够正常访问网站,通常使用raise_for_status(),查看状态,如果状态不是200,引发HTTPError异常,这一步可以使用try...except完成。
getMovieList(html)
def getMovieList(html):
soup=BeautifulSoup(html,'html.parser')
Movies=soup.find_all('div',class_='item')
movielist=[]
for movie in Movies:
key={}
#提取电影名称
key['movieName']=movie.find('span',class_='title').string
#提取电影评分
key['rating_num']=movie.find('span',class_='rating_num').string
#获取链接
key['link'] = movie.find('a')['href']
# ###有些信息不全,不够完美,因此在这就不提取了
movie_info = movie.find('div', class_='bd').find('p', class_='')
# # print(movie_info.get_text())
# # 提取导演和主演
director_and_actors = movie_info.get_text().split('...')[0]
# # print(director_and_actors)
key['director'] = director_and_actors.split('导演: ')[1].split('主')[0].strip()#本来是根据“主演”来进行分割,但是有个别电影内容格式比较奇怪,只有一个“主”字,这里就使用‘主’来进行分割了,知道怎么用就好(挠头i)
# #删除key['director']中的空格
# key['director'] = re.sub('\s','',key['director'])
movielist.append(key)
return movielist
将第一步获取的网站内容使用beautifulsoup进行解析,使用find_all()找到指定内容。
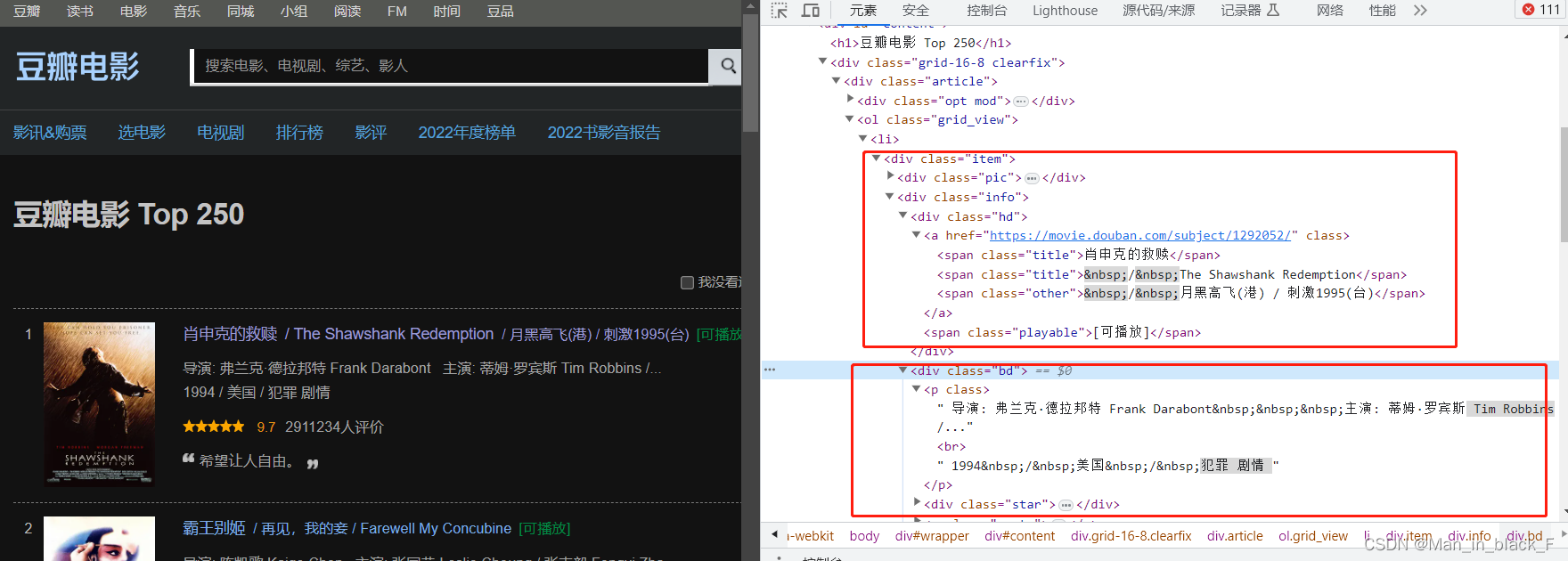
save_to_csv(movielist)
将上一步获取的信息爆粗电脑csv文件中
def save_to_csv(movielist):
with open('DouBanMovieT250.csv','a+',encoding='UTF-8',newline='') as fp:
writer = csv.writer(fp)
for key in movielist:
writer.writerow([key['movieName'],key['rating_num'],key['director'],key['link']])
def main()
def main():
for page in range(0,226,25):
time.sleep(2) #休眠两秒
#url不要写死,便于分页抓取数据
url =f'https://movie.douban.com/top250?start={page}&filter='
html=getHTMLText(url)
movielist=getMovieList(html)
save_to_csv(movielist)
# print(html)
# print(url)
翻页
有多页内容,可观察网址变化规律从而实现获取多页内容。


sleep
设置休眠时间。
在进行网络爬虫时,设置适当的休眠时间是很重要的。休眠时间可以帮助你避免给目标服务器过多的负担,同时也可以降低被服务器识别为恶意爬虫的风险。以下是一些关于设置爬虫休眠时间的建议和方法:
- 固定的固定休眠时间: 你可以在每次请求之后设置固定的休眠时间,以便在请求之间添加一些间隔。例如,每次请求后休眠 1 到 3 秒钟。
- 随机的休眠时间: 为了模拟更真实的用户行为,你可以使用随机的休眠时间。这可以减少被服务器检测到模式的风险。
全代码
#import libs
import requests
from bs4 import BeautifulSoup
import csv
import time
#爬取前250部电影的名称、评分、导演、链接
def getHTMLText(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'}
r = requests.get(url, headers=headers,timeout=30)
r.raise_for_status() # 如果状态不是200,引发HTTPError异常
# print(r.status_code)# 查看状态码
r.encoding = r.apparent_encoding
# print('success')
return r.text
except:
print('error')# 异常处理
return "产生异常"
def getMovieList(html):
soup=BeautifulSoup(html,'html.parser')
Movies=soup.find_all('div',class_='item')
movielist=[]
for movie in Movies:
key={}
#提取电影名称
key['movieName']=movie.find('span',class_='title').string
#提取电影评分
key['rating_num']=movie.find('span',class_='rating_num').string
#获取链接
key['link'] = movie.find('a')['href']
# ###有些信息不全,不够完美,因此在这就不提取了
movie_info = movie.find('div', class_='bd').find('p', class_='')
# # print(movie_info.get_text())
# # 提取导演和主演
director_and_actors = movie_info.get_text().split('...')[0]
# # print(director_and_actors)
key['director'] = director_and_actors.split('导演: ')[1].split('主')[0].strip()
# #删除key['director']中的空格
# key['director'] = re.sub('\s','',key['director'])
movielist.append(key)
return movielist
def save_to_csv(movielist):
with open('DouBanMovieT250.csv','a+',encoding='UTF-8',newline='') as fp:
writer = csv.writer(fp)
for key in movielist:
writer.writerow([key['movieName'],key['rating_num'],key['director'],key['link']])
def main():
movielist=[]
for page in range(0,226,25):
time.sleep(2)#根据需要进行设置
#url不要写死,便于分页抓取数据
url =f'https://movie.douban.com/top250?start={page}&filter='
html=getHTMLText(url)
movielist=getMovieList(html)
save_to_csv(movielist)
# print(html)
# print(url)
if __name__ == '__main__':
main()
新手练习,还请大佬多多指教

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











