







关注微信公众号“时序人”获取更好的阅读体验
时间序列知识整理系列
写在前面
聚类分析(cluster analysis)简称聚类(clustering),它是数据挖掘领域最重要的研究分支之一,也是最为常见和最有潜力的发展方向之一。聚类分析是根据事物自身的特性对被聚类对象进行类别划分的统计分析方法,它的目的是根据某种相似度度量对数据集进行划分,将没有类别的数据样本划分成若干个不同的子集,这样的一个子集称为簇(cluster),聚类使得同一个簇中的数据对象彼此相似,不同簇中的数据对象彼此不同,即通常所说的“物以类聚”。
时间序列的聚类在工业生产生活中非常常见,大到工业运维中面对海量KPI曲线的隐含关联关系的挖掘,小到股票收益曲线中的增长模式归类,都要用到时序聚类的方法帮助我们发现数据样本中一些隐含的、深层的信息。
本文为大家梳理时间序列聚类相关知识与方法,希望带各位走入时间序列分析的大门,为今后学习更高级的模型奠定一些基础。
相似性度量
要找到相似的时序曲线,并将其聚为一类,首先,我们需要有方法刻画时间序列的相似性。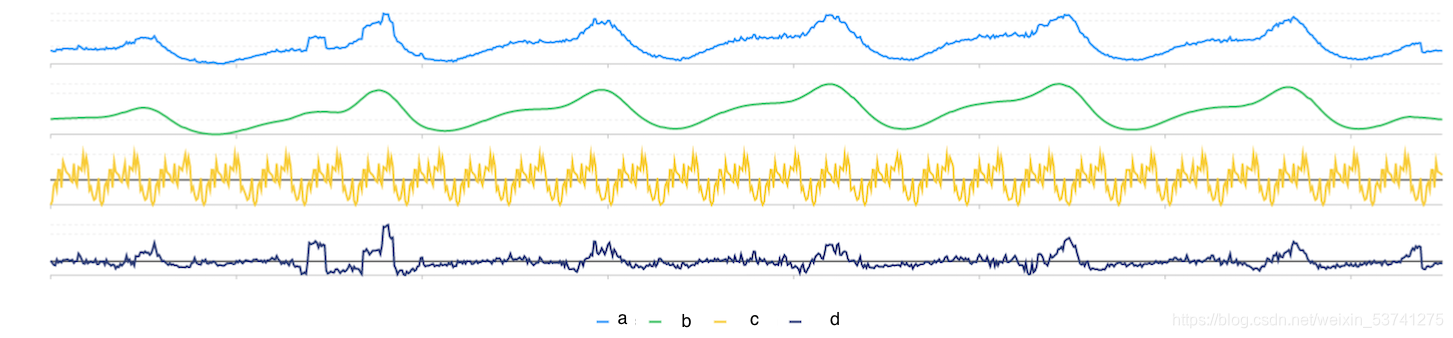
正常情况下,我们认为上图的四条曲线中,a,b,d是形状相似的。在这三条曲线中,我们认为a与b是最相似的两条曲线(因为a,b的距离最近)。
实际上相似的定义很简单:距离最近且形状相似。那么如何量化这些相似呢?直觉的,我们要对序列之间的距离进行量化。对于长度相同的序列,计算每两点之间的距离然后求和,距离越小相似度越高。

1. 闵可夫斯基距离
闵可夫斯基距离是常用的距离度量方法,如上图左边所示,在一一对应的位置上进行对比。给定两条时间序列:
P
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
P=(x_1,x_2,...,x_n)
P=(x1,x2,...,xn)和
Q
=
(
y
1
,
y
2
,
.
.
.
,
y
n
)
Q=(y_1,y_2,...,y_n)
Q=(y1,y2,...,yn),距离度量的具体公式如下:
d
i
s
t
=
(
∑
i
=
1
n
∣
x
i
−
y
i
∣
p
)
1
p
dist = (\sum_{i=1}^{n}|x_i-y_i|^p)^{\frac{1}{p}}
dist=(i=1∑n∣xi−yi∣p)p1
当p=1时,表示曼哈顿距离;p=2时,表示欧几里得距离(又称为欧式距离);当p趋近于无穷大时,该距离转换为切比雪夫距离,具体如下式所式:
lim
p
−
>
∞
(
∑
i
=
1
n
∣
x
i
−
y
i
∣
p
)
1
p
=
m
a
x
i
=
1
n
∣
x
i
−
y
i
∣
\lim_{p->\infty}(\sum_{i=1}^{n}|x_i-y_i|^p)^{\frac{1}{p}} = max_{i=1}^{n}|x_i-y_i|
p−>∞lim(i=1∑n∣xi−yi∣p)p1=maxi=1n∣xi−yi∣
闵可夫斯基距离比较直观,但是它与数据的分布无关,具有一定的局限性,如果x方向的幅值远远大于y方向的幅值,这个距离公式就会过度被x维度的作用。因此在加算前,需要对数据进行变换(去均值,除以标准差)。这种方法在假设数据各个维度不相关的情况下,利用数据分布的特性计算出不同的距离。如果数据维度之间数据相关,这时该类距离就不合适了!
2. 马氏距离
若不同维度之间存在相关性和尺度变换等关系,需要使用一种变化规则,将当前空间中的向量变换到另一个可以简单度量的空间中去测量。假设样本之间的协方差矩阵是
Σ
\Sigma
Σ,利用矩阵分解(LU分解)可以转换为下三角矩阵和上三角矩阵的乘积:
Σ
=
L
L
T
\Sigma=LL^T
Σ=LLT。消除不同维度之间的相关性和尺度变换,需要对样本x做如下处理:
z
=
L
−
1
(
x
−
μ
)
z=L^{-1}(x-\mu)
z=L−1(x−μ)。经过处理的向量就可以利用欧式距离进行度量。
d
i
s
t
=
z
T
z
=
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
dist = z^Tz = (x-\mu)^T\Sigma^{-1}(x-\mu)
dist=zTz=(x−μ)TΣ−1(x−μ)
3. DTW距离
那么,当序列长度不相等的时候,如何比较两个序列的相似性呢?这里我们需要动态时间规整(Dynamic Time Warping;DTW)方法,该方法是一种将时间规整和距离测度相结合的一种非线性规整技术。主要思想是把未知量均匀地伸长或者缩短,直到与参考模式的长度一致,在这一过程中,未知量的时间轴要不均匀地扭曲或弯折,以使其特征与参考模式特征对正。DTW距离可以帮助我们找到更多序列之间的形状相似。
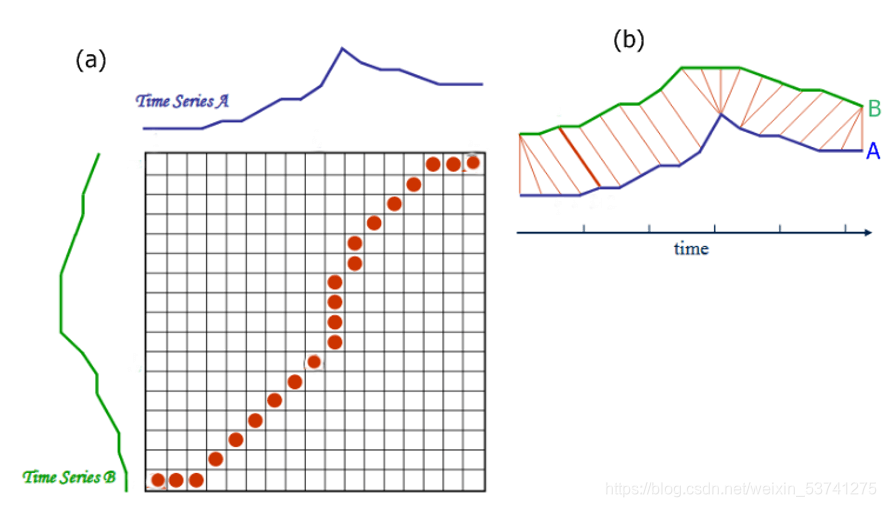
具体计算过程如下:
假设,两个时间序列A和B,
A
=
a
1
,
a
2
,
…
,
a
n
,
B
=
b
1
,
b
2
,
…
,
b
n
A={a_1,a_2,…,a_n}, B={b_1,b_2,…,b_n}
A=a1,a2,…,an,B=b1,b2,…,bn。构造一个(n, m)的矩阵,第(i, j)单元记录两个点
(
a
i
,
b
j
)
(a_i,b_j)
(ai,bj)之间的欧氏距离,
d
(
a
i
,
b
j
)
=
∣
a
i
−
b
j
∣
d(a_i,b_j )=|a_i-b_j |
d(ai,bj)=∣ai−bj∣。如上图所示,一条弯折的路径W,由若干个彼此相连的矩阵单元构成,这条路径描述了A和B之间的一种映射。设第k个单元定义为
w
k
=
(
i
,
j
)
k
w_k=(i,j)_k
wk=(i,j)k,则
w
=
w
1
,
w
2
,
w
3
,
.
.
.
,
w
K
,
m
a
x
(
n
,
m
)
<
=
K
<
=
n
+
m
−
1
w={w_1, w_2, w_3, ..., w_K}, max(n,m) <= K <= n+m-1
w=w1,w2,w3,...,wK,max(n,m)<=K<=n+m−1
这条弯折的路径满足如下的条件:
- 边界条件: w 1 = ( 1 , 1 ) w_1=(1,1) w1=(1,1),且 w k = ( n , m ) w_k=(n,m) wk=(n,m)
- 连续性:设 w k = ( a , b ) w_k=(a, b) wk=(a,b), w k − 1 = ( a ′ , b ′ ) w_{k-1}=(a^{'}, b^{'}) wk−1=(a′,b′),那么 a − a ′ < = 1 , b − b ′ < = 1 a-a^{'}<= 1,b-b^{'}<=1 a−a′<=1,b−b′<=1
- 单调性:设 w k = ( a , b ) w_k=(a,b) wk=(a,b), w k − 1 = ( a ′ , b ′ ) w_{k-1}=(a^{'}, b^{'}) wk−1=(a′,b′),那么 a − a ′ > = 0 , b − b ′ > = 0 a-a^{'}>=0, b-b^{'} >=0 a−a′>=0,b−b′>=0
在满足上述条件的多条路径中,最短的,花费最少的一条路径是:
D
T
W
(
A
,
B
)
=
m
i
n
1
K
(
∑
k
=
1
K
w
k
)
DTW(A,B) = min{\frac{1}{K} \sqrt(\sum_{k=1}^{K}w_k)}
DTW(A,B)=minK1(k=1∑Kwk)
DTW距离的计算过程是一个动态规划过程,先用欧式距离初始化矩阵,然后使用如下递推公式进行求解:
r
(
i
,
j
)
=
d
(
i
,
j
)
+
m
i
n
r
(
i
−
1
,
j
−
1
)
,
r
(
i
−
1
,
j
)
,
r
(
i
,
j
−
1
)
r(i,j) = d(i,j) + min{r(i-1, j-1), r(i-1, j), r(i, j-1)}
r(i,j)=d(i,j)+minr(i−1,j−1),r(i−1,j),r(i,j−1)
4. 参数距离
除了直接的度量原始时间序列之间的距离,很多方法尝试对时间序列进行建模,并比较其模型参数的相似度。之前我们介绍了时间序列的统计分析方法,这里,可以用到的有:
基于相关性的相似度度量方法:
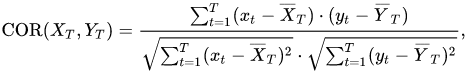
量化两条序列X与Y之间的相关系数:相关系数等于1,表示它们完全一致;如果等于-1,表示它们之间是负相关的。
基于自相关系数的相似度度量方法:
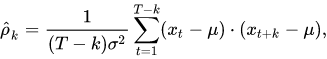
如上式分别抽取曲线X与Y的自相关系数,可以定义时间序列之间的距离如下:
d ( X T , Y T ) = ( ρ ^ X T − ρ ^ Y T ) T ( ρ ^ X T − ρ ^ Y T ) d(X_T,Y_T)=\sqrt{(\hat{\rho}{X_T}-\hat{\rho}{Y_T})^T(\hat{\rho}{X_T}-\hat{\rho}{Y_T})} d(XT,YT)=(ρ^XT−ρ^YT)T(ρ^XT−ρ^YT)
基于周期性的相似度度量方法:
通过傅里叶变换得到一组参数,然后通过这组参数来反映原始的两个时间序列时间的距离。数学表达为:
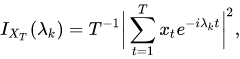
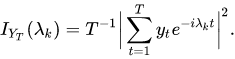
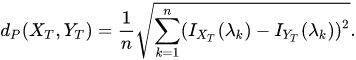
还有通过ARMA模型抽象时序的参数,进行举例度量,类似方法这里不作展开。
聚类算法
有了对时间序列的距离度量方法,我们便可以采用机器学习中很多聚类算法,帮助我们进行时间序列的聚类分析。这里简单为大家罗列一些经典算法。
基于距离的机器学习聚类算法
KMeans 算法是非常经典的距离度量聚类算法,其目的是把样本,基于它们之间的距离公式,把它们划分成K个类别,其中类别K的个数是需要在执行算法之前人为设定的。
从数学语言上来说,假设已知距离空间点集为
{
x
1
,
.
.
.
,
x
n
}
\{x_1, ...,x_n\}
{x1,...,xn},事先设定的类别个数是K ,当然
K
≤
n
K\leq n
K≤n 是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合
{
S
i
}
1
≤
i
≤
n
\{S_i\}_{1\leq i \leq n}
{Si}1≤i≤n 使得
arg
min
S
i
∑
x
∈
S
i
∣
∣
x
−
μ
i
∣
∣
2
\arg \min S_i \sum_{x \in S_i} {|| x - \mu_i||}^2
argminSi∑x∈Si∣∣x−μi∣∣2 达到最小,其中
μ
i
\mu_i
μi表示集合
S
i
S_i
Si中的所有点的均值。
基于相似性的机器学习聚类算法
层次聚类是一种很直观的方法,就是一层一层的对数据进行聚类操作,可以自低向上进行合并聚类、也可以自顶向下进行分裂聚类。
- 凝聚式:从点作为个体簇开始,每一个步合并两个最接近的簇
- 分裂式:从包含所有个体的簇开始,每一步分裂一个簇,直到仅剩下单点簇为止
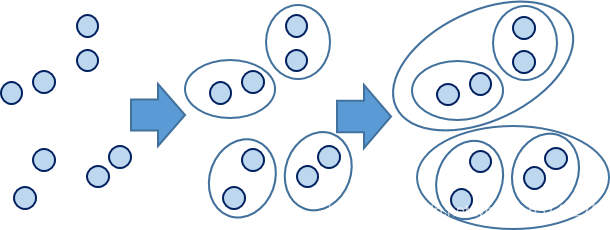
所谓凝聚,其大体思想就是在一开始的时候,把点集集合中的每个元素都当做一类,然后计算每两个类之前的相似度,也就是元素与元素之间的距离;然后计算集合与集合之前的距离,把相似的集合放在一起,不相似的集合就不需要合并;不停地重复以上操作,直到达到某个限制条件或者不能够继续合并集合为止。
所谓分裂,正好与聚合方法相反。其大体思想就是在刚开始的时候把所有元素都放在一类里面,然后计算两个元素之间的相似性,把不相似元素或者集合进行划分,直到达到某个限制条件或者不能够继续分裂集合为止。
在层次聚类里面,相似度的计算函数就是关键所在。在这种情况下,可以设置两个元素之间的距离公式,距离越小表示两者之间越相似,距离越大则表示两者之间越不相似。除此之外,还可以设置两个元素之间的相似度。
更多原创内容与系列分享,欢迎关注微信公众号“时序人”获取。


















 2173
2173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









