






Transformer在NLP领域内十分常用,所以俺今天来学习一下相关内容,并进行简单地总结。
论文原链接:1706.03762.pdf (arxiv.org)
本篇博客只是个人学习总结,相关算法和流程推荐一篇知乎上详细解读的文章,可以帮助理解:Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)
本文提出了简单网络架构Transformer,基于注意力机制省去了递归和卷积
目录
3.2.1 Scaled Dot-Product Attention
6.3English Constituency Parsing
1.介绍
在各种任务中,注意力机制已成为引人注目的序列建模和转导模型的一个组成部分,允许在不考虑它们在输入或输出序列中的距离的情况下对依赖关系进行建模。
2.背景
自我注意力,有时称为内部注意力,是一种将单个序列的不同位置联系起来的注意力机制,以计算序列的表示。自我注意力已成功用于各种任务,包括阅读理解、抽象总结、文本蕴涵和学习与任务无关的句子表征。端到端记忆网络基于递归注意力机制,而不是序列对齐递归,并且已被证明在简单语言问答和语言建模任务中表现良好。
3.模型架构
大多数竞争性神经序列转导模型都具有编码器-解码器结构。在这里,编码器将符号表示的输入序列 (x1, ..., xn) 映射到连续表示序列 z = (z1, ..., zn)。给定 z,解码器然后生成一个输出序列 (y1, ..., ym) 一个元素的符号。在每个步骤中,模型都是自回归的,在生成下一个步骤时,会消耗先前生成的符号作为附加输入。
下图为transformer架构图:
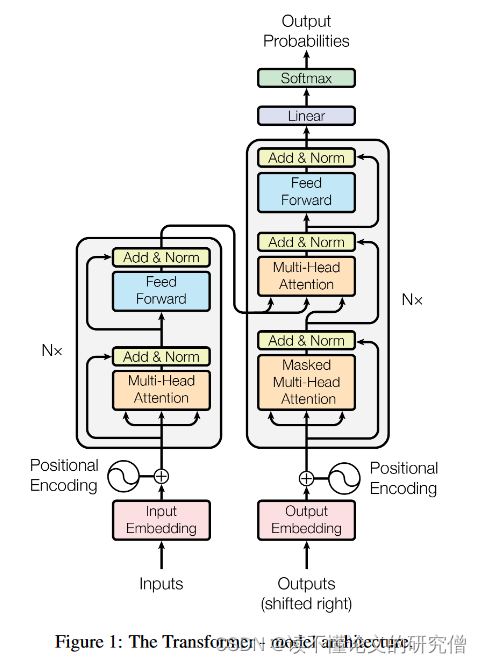
3.1编码器和解码器堆栈
编码器:编码器由 N = 6 个相同层的堆栈组成。每个图层有两个子图层。第一种是多头自注意力机制,第二种是简单的、位置上完全连接的前馈网络。我们在两个子层中的每一个都采用残差连接,然后进行层归一化。
解码器:解码器也由 N = 6 个相同层的堆栈组成。除了每个编码器层中的两个子层外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意。与编码器类似,我们在每个子层周围采用残差连接,然后进行层归一化。
3.2注意力机制
注意力函数可以描述为将一个查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。输出计算为加权总和,其中分配给每个值的权重由具有相应键的查询的兼容性函数计算。
注意力机制分为两种:Scaled Dot-Product Attention & Multi-Head Attention
3.2.1 Scaled Dot-Product Attention
Scaled Dot-Product Attention 。输入由维度dk的查询和键以及维度dv的值组成。用所有键计算查询的点积,除以√dk,并应用一个softmax函数来获得值的权重。
在实践中,同时计算一组查询的注意力函数,并将其打包成矩阵Q。键和值也打包成矩阵K和V。计算输出的矩阵为:

3.2.2 Multi-Head Attention
与使用dmodel维的键、值和查询执行单个注意力函数不同,发现将查询、键和值分别以不同的、学习过的线性投影h次线性投影到dk、dk和dv维是有益的。在这些查询、键和值的每个投影版本上,并行地执行注意力函数,产生dv维输出值。将这些进行拼接并再次投影,得到最终的值。
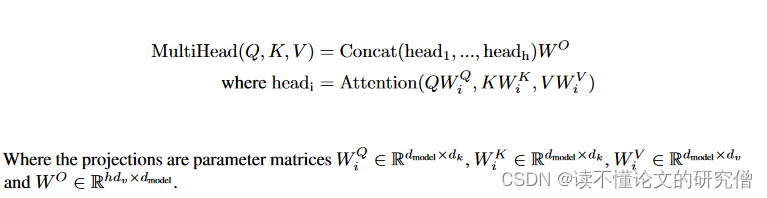
3.2.3模型中注意力机制的应用
Transformer以三种不同的方式使用多头注意力:
1.在"编码器-解码器注意力"层中,查询来自前面的解码器层,而内存键和值来自编码器的输出。这使得解码器中的每个位置都可以参与输入序列中的所有位置。这模仿了序列到序列模型中典型的编码器-解码器注意机制。
2.编码器包含自注意力层。在一个自注意力层中,所有的键、值和查询来自同一个地方,在这种情况下,编码器中前一层的输出。编码器中的每个位置可以参与到编码器前一层的所有位置。
3.同样,解码器中的自注意力层允许解码器中的每个位置关注解码器中的所有位置,直到并包括该位置。需要在解码器中阻止向左的信息流动以保持自回归特性。通过屏蔽softmax输入中与非法连接相对应的所有(设置为-∞)值来实现缩放点积注意力的内部。
3.3位置智能型前馈网络
除了注意力子层之外,编码器和解码器中的每一层都包含一个全连接的前馈网络,该网络分别且相同地应用于每个位置。这包括两个线性变换,ReLU激活介于两者之间。
![]()
3.4嵌入和Softmax
与其他序列转导模型类似,利用学习的嵌入将输入和输出的标记转换为d维向量。还使用通常学习的线性变换和softmax函数将解码器输出转换为预测的下一个令牌概率。在两个嵌入层和pre - softmax线性变换之间共享相同的权重矩阵。在嵌入层中,将这些权重乘以√dmodel。
3.5位置编码
由于模型不包含递归和不包含卷积,为了使模型能够利用序列的顺序,必须在序列中注入一些关于令牌相对或绝对位置的信息。为此,在编码器和解码器堆栈底部的输入嵌入中加入"位置编码"。位置编码与嵌入具有相同的维度dmodel,因此两者可以求和。
位置编码的选择方式:
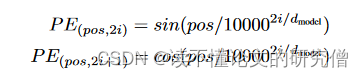
其中pos为位置,i为维度。
4.为什么选择自注意力机制
这里把自注意力层的各个方面与通常用于将一个可变长度的符号表示序列( x1 , ... , xn)映射到另一个等长的序列( z1 , ... , zn) ( xi,zi∈Rd )的循环层和卷积层进行比较,例如典型的序列转导编码器或解码器中的隐藏层。为了激发对自我注意的使用,有以下三个必备。
(1)每层的总计算复杂度。
(2)可以并行化的计算量,用所需的最小顺序操作数来衡量。
(3)第三是网络中长程依赖之间的路径长度。
作为副效益,自我关注可以产生更多可解释的模型。
5.训练
5.1 训练数据和批处理
在标准的 WMT 2014 英德数据集上进行了训练。
5.2优化器
使用了Adam优化器,β1 = 0.9,β2 = 0.98,ε = 10-9。在训练过程中,根据公式改变学习率:
![]()
5.3正则化
采用了几种正则化方法:
(1)残差滤波 :对每个子层的输出进行滤波,然后将其添加到子层输入中并进行归一化处理。此外,还对编码器和解码器堆栈中的嵌入和位置编码之和进行了滤除。在基础模型中,我们使用 Pdrop = 0.1 的比率。
(2)标签平滑:在训练过程中,使用了标签平滑值 εls = 0.1。这样做会增加模型的不确定性,从而降低复杂度,但却提高了准确度和 BLEU 得分。
6.结果
6.1机器翻译
在 WMT 2014 英译德翻译任务中,大转换器模型(表 2 中的转换器(big))的 BLEU 值比之前报道的最佳模型(包括集合)高出 2.0 以上,达到了 28.4 的新的最先进 BLEU 值。在 8 个 P100 GPU 上的训练耗时 3.5 天。
6.2Model Variations
一个结果说明表:
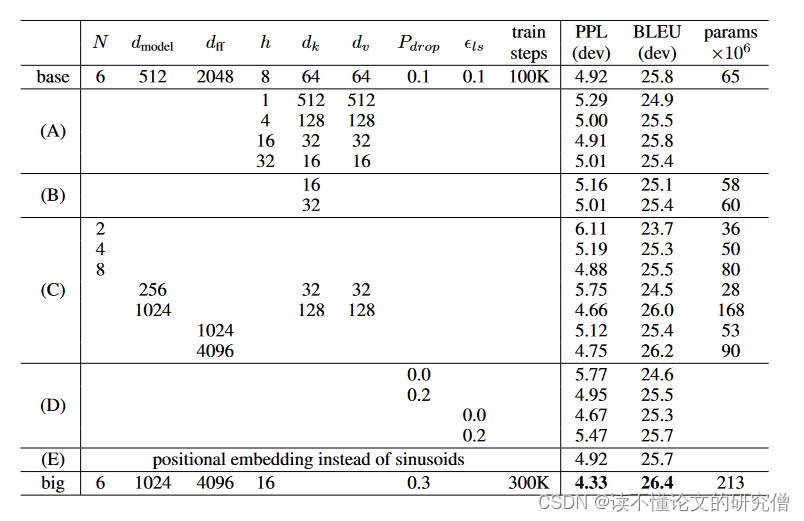
在表行(B)中,发现减小关注键大小 dk 会降低模型质量。这表明,确定兼容性并不容易,比点积更复杂的兼容性函数可能更有益处。在第(C)行和第(D)行中,进一步观察到,正如所预期的那样,模型越大越好,而 dropout 对避免过度拟合很有帮助。在第(E)行中,用学习到的位置嵌入[9]替换了正弦位置编码,观察到的结果与基础模型几乎完全相同。
6.3English Constituency Parsing
与 RNN 序列到序列模型相比,即使只在由 40K 个句子组成的 WSJ 训练集上进行训练,Transformer 的表现也优于 BerkeleyParser。
下表中的结果表明,尽管缺乏针对特定任务的调整,但模型表现出人意料的好,其结果优于除递归神经网络语法以外的所有以前报道过的模型。

7.结论
提出了Transformer,这是第一个完全基于注意力的序列转换模型,用多头自我注意力取代了编码器-解码器架构中最常用的递归层。
写在最后
经过学习Transformer,增加了自己对于NLP的进一步理解,帮助自己在NLP领域进一步学习探索!!!!!!















 261
261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









