






论文信息: 论文标题Attention-based hierarchical denoised deep clustering network[1]。中译:《基于注意力的分层去噪深度聚类网络》。作者Yongfeng Dong, Ziqiu Wang, Jiapeng Du等。于2022年1月接受,发表于World Wide Web (2023)。
摘要: 聚类是数据分析和决策的一项基本任务。在对于图数据的聚类任务上,基于图卷积神经网络(graph convolution network, GCN)的深度聚类框架已经产生了最先进的性能。然而,传统的GCN并没有完全学习到邻居的结构信息。因此,作者提出了一种基于注意力的分层去噪深度聚类(AHDDC)算法来解决这一问题,该算法使GCN能够学习多层隐藏信息,并利用注意力机制对信息进行强化。此外,作者使用去噪自编码器(DAE)来减少数据噪声对聚类的影响。在AHDDC中,首先将原始数据的特征向量输入到去噪自编码器中学习隐藏表示;其次,将自编码器的表示信息和由KNN图构造的结构信息传递到一个分层注意图卷积网络中;最后,利用自监督模块对聚类结果进行优化。实验结果表明,此方法优于大多数先进的算法。此外,所提出的分层、基于注意力和去噪改进策略的有效性也得到了实验验证。
关键词: 深度聚类,大规模群,图卷积神经网络(GCN),数据表示
Abstract: Clustering is a fundamental task in data analysis and decision-making. For clustering tasks on graph data, deep clustering frameworks based on Graph Convolutional Networks (GCN) have achieved state-of-the-art performance. However, traditional GCN do not fully learn the structural information of neighbors. Therefore, the authors propose an Attention-based Hierarchical Denoising Deep Clustering (AHDDC) algorithm to address this issue. This algorithm enables GCN to learn multi-layer hidden information and enhances it using attention mechanisms. Additionally, the authors use Denoising Autoencoders (DAE) to reduce the impact of data noise on clustering. In AHDDC, the feature vectors of the original data are first input into the denoising autoencoder to learn hidden representations. Then, the representation information from the autoencoder and the structural information constructed by the KNN graph are passed to a hierarchical attention graph convolutional network. Finally, a self-supervised module is used to optimize the clustering results. Experimental results show that this method outperforms most advanced algorithms. Moreover, the effectiveness of the proposed hierarchical, attention-based, and denoising improvement strategies is also experimentally verified.
Keywords: Deep clustering; Large-scale group; Graph convolution network (GCN); Data representation
1 研究背景
-
- 深度聚类
传统的聚类方法在求解低维数据时是有效的,但在数据维数较高时很少产生令人满意的性能。最近,基于深度学习的解决方案在各种任务中得到了广泛的关注。到目前为止,基于深度学习的方法已经产生了有效的聚类性能,特别是在解决高维和大规模数据时。
常见的深度表示方式包括深度子空间聚类、深度谱聚类和基于自编码器(AE)的方法。AE可以为输入数据建立语义上有意义且分离良好的表示,是最常用的方法。对于生成的深度特征,分配各种附加约束,例如,高斯混合分布,分布保持假设,互信息最大化和局部结构保持。此外,构建深度聚类特征的最有效的AE框架也是研究者关注的焦点。
-
- GCN
新兴的图卷积网络(Graph Convolutional Networks, GCN)对图结构和节点属性进行编码,用于节点表示,这被认为是表示数据结构信息最有效的方法。GCN模型由Kopf等人于2016年提出[2]。
GCN将图的拓扑结构与节点特征结合起来,通过图卷积操作来提取节点之间的关系和特征信息。相比传统的卷积神经网络(Convolutional Neural Network, CNN),GCN能够直接在不规则的图结构上运行,而无需将其转换为规则的网格数据。
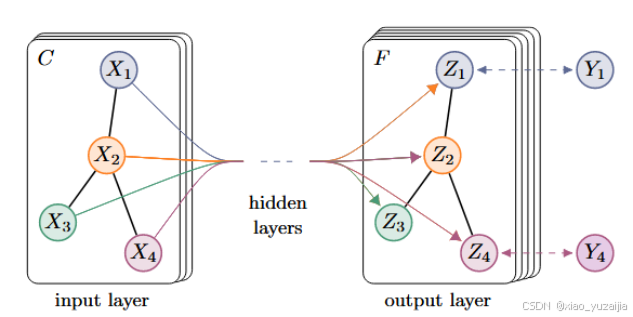
图1 GCN结构
图结构上的卷积只需要找到当前节点的邻居进行聚合然后更新自身节点信息就可以。即通过邻居信息更新自身节点信息,从而使得不同节点的表示融合了局部信息这一行为。首先聚合局部信息,然后进行更新自身信息循环往复。
-
- SDCN
2020年,Bo等人首次将基于GCN的结构信息集成到深度聚类框架中,提出了结构性深度聚类网络SDCN模型[3]。提取原始图数据的KNN图,并将其用于SDCN模型中,以捕获数据的结构信息。然后,SDCN模型通过DNN模块学习数据特征的表示,GCN模块学习结构信息的表示。它通过双自监督目标对整体聚类进行优化。
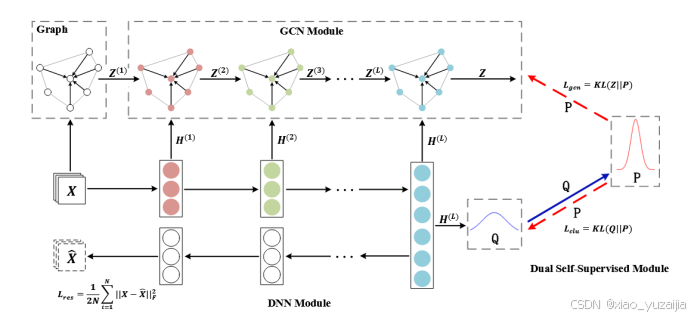
图2 SDCN结构
SDCN整个模型大概包括三部分:自编码器模块(图中DNN),图卷积模块(GCN)和双重自监督模块。自编码器模块的不同之处在于编码器中每层的输出,都提供给各层的GCN进行处理。GCN部分,基于原始数据X计算出一个K最近邻图(KNN图),个图会被作为GCN模块的初始输入。GCN的每一层在获取Z,即输入数据后,还需要接收来自编码器的每层输出。这里通过每层特征的融合,让GCN学习到的表示同时包含原始特征信息和图结构信息。
SDCN将GCN用于对图数据的无监督(自监督)聚类任务上,这种方式注重了图数据的结构信息,获得了更好的效果。
-
- 现存问题和改进方法
然而,传统的GCN并没有完全学习到邻居的结构信息。GCN直接在SDCN中建模的结构信息,实际上是邻域关系信息,仍然可以得到改进。在SDCN中,不同样本的相似度是通过基于欧几里得距离的KNN估计来计算的,当数据维数较高时,这可能不是最优的方法。
该文章探索了基于GCN框架的改进方法,从而提出了一种基于注意力的分层去噪深度聚类(AHDDC)模型。首先,在AHDDC中采用层次GCN,可以更好地捕获图数据中隐藏的高阶信息;然后,在层次结构中,作者仍然发现不同样本之间使用注意力机制可以进一步提高网络的表示能力。此外,很明显,数据中总会存在一些噪声,这些噪声会影响聚类性能。为此,在表示输入数据时,作者采用去噪AE (DAE)模型,并建立r平方损失来去除噪声,产生纯粹的特征信息。最终,像SDCN那样做的,分层的GCN和DAE仍然结合在一个统一的框架中。
2 研究方法
2.1 任务概述
考虑这样一个任务,给定原始数据X,给定聚类簇数c。每个数据样本X_i都是一个高维的数据点(向量),任务要求为每个数据点X_i分配一个聚类中心c_j。
为了完成这个任务,文章提出了基于注意力的分层去噪深度聚类模型(Attention-based hierarchical denoised deep clustering model, AHDDC)。整体框架如图3所示。
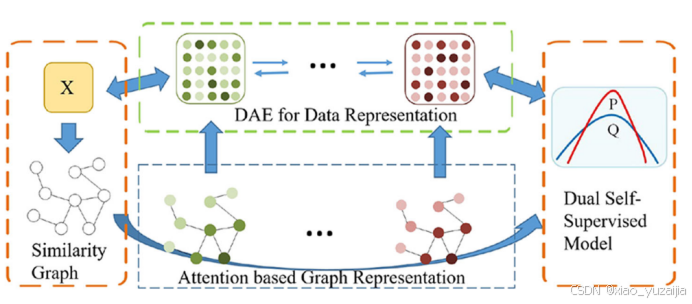
图3 AHDDC的框架
整体框架是通过使用数据表示和相似图表示的组合来建立的,这种方法在SDCN中被证明是有效的。数据表示由DAE模块完成,并受到r平方损失的惩罚;数据的相似图由基于注意的分层GCN表示,该算法在保留数据相似关系的同时,探索最具区别性的数据特征。最终,两种表示方式的分布被一种自监督方式[4]统一。
2.2 双向自监督模块
对于数据X∈R (N*d)中的每个样本X_i,我们可以根据欧几里得相似度挑选出它的邻居。然后,通过设置一个阈值,例如,top K个相似的邻居,我们最终建立一个相似矩阵S∈R (N*N),它对应于X的相似图。图中的每个顶点都与一个样本相关联,一条边表示其连接的顶点是相似的。
然后,对于X,安排去噪自编码器(DAE)以提取特征H,同时,对于S,基于基于注意力的分层GCN训练新的分布Z。这两个过程的细节将在下面的两小节中给出。
之后,采用双向自监督模块来保证上述两种方式产生的数据分布是一致的。
2.2.1 第一自监督
在双向自监督模块中,首先,根据t-分布(学生)获得聚类结果,也就是真实分布Q。对于H中的第i个样本H_i和任意聚类质心c_j,他们的相似度(分配概率)定义为
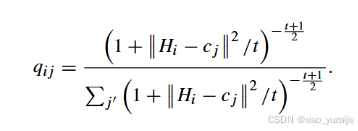
而目标分布P则通过下式计算
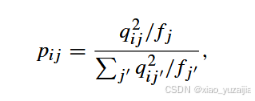
其中
![]()
那么由DAE获得的第一个自监督目标(损失)就是
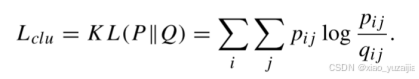
KL散度(Kullback-Leibler)用于量化目标分布P和真实分布Q两种类型之间的差异,目标是最小化P和Q之间的差异。
2.2.2 第二自监督
从GCN模块获得了分布Z之后,使用同样的方式获得第二个自监督目标,其中目标分布P和第一个自监督目标一致。
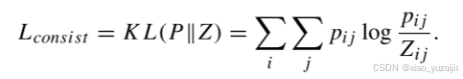
KL散度用于量化目标分布P和真实分布Z两种类型之间的差异,目标是最小化P和Z之间的差异。
2.3 基于注意力的分层GCN
在相似图中,每个节点和每条边都有自己的特征。分层GCN的学习目标是获取每个节点图的感知隐藏状态。这意味着对于每个节点来说,它的隐藏状态来自于邻居信息。分层GCN是通过迭代更新所有节点的隐藏状态来实现的。
GCN通过考虑所有相邻节点贡献相同来更新数据表示。然而,对于大多数数据,作者认为不同的相邻节点可能扮演不同的角色。因此,根据不同相邻节点的重性设计合适的权重,文章作者给出了一种改进的方法。以任意表示Z(i)层中的任意节点r为例。它的特征值用Z_r表示,也就是Z(i)的第r行向量值。从相似图中,我们可以找到r的相邻节点,并将其记录为r_1,r_2,…,r_k。
然后,表示节点r与任意一个邻居(以r_k为例)的权值由softmax对注意力值归一化得来
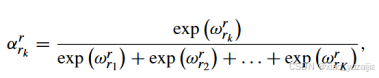
其中,来自每个领居节点r_k的注意力值定义为
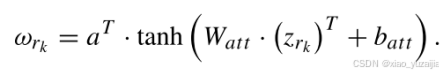
其中,a为共享注意力向量,W_att为注意力权重矩阵,b_att为偏置。使用tanh先进行非线性变换,再进行线性变换。
在获得所有领居的权重后,就可以更新节点r的表示。即完成一步图卷积操作。
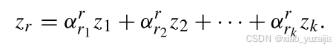
通过重复这个过程,我们可以更新Z(i)层中的所有节点数据表示。即完成一层图卷积操作。
2.4 DAE模块
将原始数据X输入降噪自编码器(DAE)以学习其特征。编码器将原始数据X压缩为特征H,解码器通过几个全连接层重构输入数据。
为了去除影响聚类的噪声,作者在自编码器前面加了一个dropout层,随机杀死神经元,达到降噪的效果。将任意神经元被杀死的概率设置为固定常数g。与未损坏数据的训练相比,损坏数据的训练噪声更小,因为在擦除时输入噪声会被意外擦除。而且,从特征提取的流形学习的角度来看,受损数据相当于对特征
进行简单的降维提取。
编码器和解码器的前向传播定义为
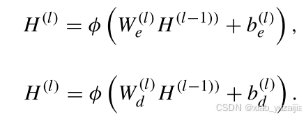
此外,就像SDCN做的那样,将AE中的编码器与GCN层层交流。作者认为DAE模块(H (l))和分层GCN模块(Z(l))中第l个数据表示的分布应该相似。因此,我们将Z(l)进一步更新为
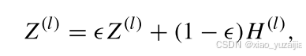
使用这样的Z(l)更新方式,让GCN层也学习到编码器的特征。文章中权重设置为0.5。
作者采用R-square误差作为AE去噪模块的损失函数,解决了聚类中不同震级的问题。因为在聚类分析中,要求数据有统一的幅度。
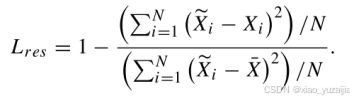
2.5 训练
AHDDC的全部损失为
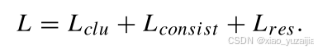
文章的目标函数采用联合优化方法,如[5], [6]。L_res为DAE重构损失;L_consist是自适应分层GCN的损失函数,它使Z更接近P;L_clu为聚类优化损失,使聚类结果Q更接近P。自适应分层GCN和DAE模块统一在同一个优化目标上,使其结果趋于一致。这是因为DAE模块和自适应分层GCN模块的目标都是近似目标分布P。
首先,初始化DAE模块和分层GCN模块中的参数。
然后,从KNN图中获取结构信息,并通过DAE模块获取特征信息都输入到GCN模块。表示学习的结果是在迭代隐层和注意机制的运算后得到的。
最后,在损失函数收敛之前不断产生聚类结果。由于表示方式不仅包含特征信息,还包含结构信息,因此AHDDC使用表示学习的聚类结果作为最终输出。
3 实验
3.1 数据集和评价标准
作者的AHDDC模型实验在五个标准的深度聚类数据集上进行,分别是ACM[7]、DBLP[7]、HHAR[8]、USPS[9]和Reuters[10]。这些数据集的统计结果如表2所示。
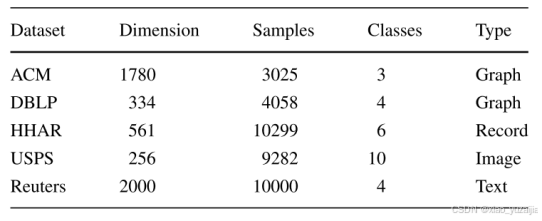
表2 数据集统计
文章使用4个指标来评估聚类算法的性能。准确率(ACC)、归一化互信息(NMI)、平均兰德指数(ARI)和F1得分(F1)。对于每一个指标,数值越大意味着聚类结果越好。
3.2 实验结果
文章将AHDDC模型与10个基线聚类模型进行了比较。表3显示了5个数据集上的聚类结果。文章记录了ACC、NMI、ARI、F1在ACM、DBLP、HHAR、USPS和Reuters数据集上的聚类结果。
对比的基线算法包括三类:第一类是传统的聚类算法(K-means);第二种是基于AE的聚类算法(AE、DAE、DEC、IDEC),第三种是基于GCN的聚类算法(VGAE、
AGC、DAEGC、SDCN、DGSCN)。对比这八种近年来的聚类方法,AHDDC模型在每个指标上都能得到更好的聚类结果。
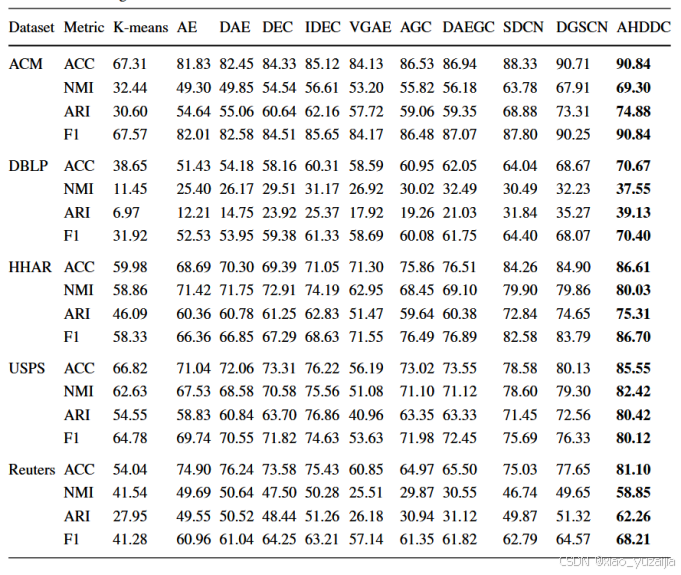
表3 在五个数据集上的聚类结果
4 总结
本文的作者提出了基于注意力的分层去噪深度聚类(AHDDC)模型,在总结了前人的研究之后,作者认为传统的GCN并没有完全学习到邻居的结构信息,在卷积过程中节点不应该平均的吸收来自领居节点的信息,因此作者提出了基于注意力的GCN卷积过程。此外,在编码器层面,作者使用去噪自编码器(DAE)来减少数据噪声对聚类的影响,增强编码器的特征表达能力,并且DAE的损失不使用一般的均方根误差,而是使用R-square计算误差。最后同样在双向自监督目标对整体聚类。最后取得了比SDCN等过去的算法更好的效果。
参考文献
[1] Y. Dong, Z. Wang, J. Du, W. Fang, and L. Li, “Attention-based hierarchical denoised deep clustering network,” World Wide Web, vol. 26, no. 1, pp. 441–459, Jan. 2023, doi: 10.1007/s11280-022-01007-4.
[2] T. N. Kipf and M. Welling, “Semi-Supervised Classification with Graph Convolutional Networks,” ICLR 2017, Feb. 2017, doi: 10.48550/arXiv.1609.02907.
[3] D. Bo, X. Wang, C. Shi, M. Zhu, E. Lu, and P. Cui, “Structural Deep Clustering Network,” in Proceedings of The Web Conference 2020, in WWW ’20. New York, NY, USA: Association for Computing Machinery, Apr. 2020, pp. 1400–1410. doi: 10.1145/3366423.3380214.
[4] S. Kou, W. Xia, X. Zhang, Q. Gao, and X. Gao, “Self-supervised graph convolutional clustering by preserving latent distribution,” Neurocomputing, vol. 437, pp. 218–226, May 2021, doi: 10.1016/j.neucom.2021.01.082.
[5] X. Li, Y. Hu, Y. Sun, J. Hu, J. Zhang, and M. Qu, “A Deep Graph Structured Clustering Network,” IEEE Access, vol. 8, pp. 161727–161738, 2020, doi: 10.1109/ACCESS.2020.3020192.
[6] C. Wang, S. Pan, R. Hu, G. Long, J. Jiang, and C. Zhang, “Attributed Graph Clustering: A Deep Attentional Embedding Approach,” Jun. 15, 2019, arXiv: arXiv:1906.06532. doi: 10.48550/arXiv.1906.06532.
[7] X. Wang et al., “Heterogeneous Graph Attention Network,” in The World Wide Web Conference, in WWW ’19. New York, NY, USA: Association for Computing Machinery, May 2019, pp. 2022–2032. doi: 10.1145/3308558.3313562.
[8] A. Stisen et al., “Smart Devices are Different: Assessing and MitigatingMobile Sensing Heterogeneities for Activity Recognition,” in Proceedings of the 13th ACM Conference on Embedded Networked Sensor Systems, in SenSys ’15. New York, NY, USA: Association for Computing Machinery, Nov. 2015, pp. 127–140. doi: 10.1145/2809695.2809718.
[9] Y. Le Cun et al., “Handwritten zip code recognition with multilayer networks,” in 10th International Conference on Pattern Recognition [1990] Proceedings, Jun. 1990, pp. 35–40 vol.2. doi: 10.1109/ICPR.1990.119325.
[10] D. D. Lewis, Y. Yang, T. G. Rose, and F. Li, “RCV1: A New Benchmark Collection for Text Categorization Research,” Journal of Machine Learning Research, vol. 5, no. Apr, pp. 361–397, 2004.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









