







前言
这一篇博客是关于HTTP协议的上半部分,知识点很多,笔者尽力总结。有些知识点不是属于这一部分的,但是涉及到了,笔者就稍微提一下。
一丶关于HTTP协议前置知识
<1>网络划分
1>局域网LAN
局域网,即 Local Area Network,简称LAN。局域网之内的主机能进行网络通信,成为内网。局域网和局域网没有连接时候无法通信。
网络通信:通过网络,获取网络在某个主机上的某个资源
互相通信:也就是互相访问对方提供的资源,比如说:(1)HTML文件 (2)CSS
文件 (3)JS文件 (4)图片,视频,音乐 等等
如果说一个局域网没有连接到公网的时候,是不可以访问公网的资源的。
局域网组建网络的方式有很多种,主要有以下几种:
(1)基于网线直连
(2)基于集线器组建
(3)基于交换机组建
(4)基于交换机和路由器组建
2>广域网 WAN
广域网,即 Wide Area Network,简称WAN。也就是通过路由器把多个局域网连接起来,在物理上组成很大范围的网络,这就是广域网。广域网的子网就是其内部的局域网。
<2>IP地址
IP用来标识网络主机,也就是说IP地址用于定位主机的网络地址。它的格式是一个32 位的进制数,但是我们会把它分为四个部分,每个部分8个比特位,0~255
主 机 I P 地 址 是 : 127.0.0.1 \color{red}{主机IP地址是:127.0.0.1} 主机IP地址是:127.0.0.1
但是问题来了,我们通过IP地址定位到了主机的地址,定位了之后,主机要怎么接收呢?
<3>端口
端口就是为了解决上述的问题应运而生,端口就是用来标识网络通信当中,某个主机上的某个进程。也就是标识主机当中发送数据,接收数据的进程。
我们通过IP和Port就能知道我们要获取哪个主机,要获取这个主机上的哪个进程资源。
<4>协议
这里的协议就指的是网络通信(网络数据传输)经过的所有网络设备都必须遵从的一组约定,规则。主要有三个要素:
1. 语法:即数据与控制信息的结构或格式;
2. 语义:即需要发出何种控制信息,完成何种动作以及做出何种响应;
3. 时序,即事件实现顺序的详细说明。
协议最后就体现为在网络上传输的数据包的格式。
二丶HTTP协议
<1>HTTP协议是什么?
HTTP (全称为 “超文本传输协议”) 是一种应用非常广泛的 应用层协议,它是一个处于应用层的协议。
超文本传输协议:可以传输文本以及其他格式的数据资源,比如说音乐视频什么的
应用层:指的是服务端和客户端所在的网络分层。他们需要使用相同的协议。
协议:http自己的文本格式
对于在浏览器访问一个资源(网页,图片,js等)来说,就是基于HTTP数据包的形式,从主机A的某个进程传输到主机B的某个进程,当然这里的A和B可以是一个,也可以是不同的。
<2>理解HTTP协议工作过程
当我们在浏览器中输入一个 “网址”, 此时浏览器就会给对应的服务器发送一个 HTTP 请求. 对方服务器收到这个请求之后, 经过计算处理, 就会返回一个 HTTP 响应.
这里用Fiddler来进行演示
首先我们在浏览器输入www.sougou.com
然后在抓包工具Fiddler中就可以看到

我们的请求和返回的结果。
这里我们的抓包工具其实就是充当一个中间的过客,当浏览器访问一个网站时候,会先把这个请求发给抓包工具,然后抓包工具再转发给对应网站的服务器,接着对应网站服务器会返回数据给抓包工具,抓包工具再返回给服务器。
当然,请求和响应都是有着对应的格式的
HTTP请求格式:
首行: [方法] + [url] + [版本]
Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示
Header部分结束
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在
Header中会有一个Content-Length属性来标识Body的长度;
HTTP响应格式:
首行: [版本号] + [状态码] + [状态码解释]
Header: 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;遇到空行表示
Header部分结束
Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在
Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个
html页面, 那么html页面内容就是在body中.
这里的主要注意一个问题,为什么要一定会有空行?
因为 HTTP 协议并没有规定报头部分的键值对有多少个. 空行就相当于是 "报头的
结束标记", 或者是 "报头和正文之间的分隔符".
HTTP 在传输层依赖 TCP 协议, TCP 是面向字节流的. 如果没有这个空行, 就会出
现 "粘包问题".
三丶HTTP请求
<1>认识URL
1>基本格式
URL就是用来标识某个资源的路径(通过IP找主机,通过端口找进程)
这里直接实例讲解

也就是说我们的URL具体格式如下:
协议名://服务器地址:服务器端口号/带层次的资源路径?查询字符串
这里我们注意了,在我们访问Web资源的时候
1.如果我们通过浏览器直接访问,那么我们可以不输入协议名称
2.服务器路径可以写IP或者端口(本机IP:127.0.0.1 本机端口:localhost)
3.端口号:浏览器不输入端口号,HTTP协议默认使用80端口,HTTPS协议默认使用
443端口
4.带层次的资源路径:表示在某个服务器中,某个资源的具体路径,如果没有输入
路径资源,就是访问/(也称为某个Web应用的根路径)
5.查询字符串:就是查询某个资源下但是不同条件的数据
然后这里再总结一下我们可以省略的地方
(1)协议名: 可以省略, 省略后默认为 http://ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性). 省略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致.
(2)端口号: 可以省略. 省略后如果是 http 协议, 端口号自动设为 80; 如果是 https 协议, 端口号自动设为 443.
(3)带层次的文件路径: 可以省略. 省略后相当于 / . 有些服务器会在发现 / 路径的时候自动访问/index.html
(4)查询字符串: 可以省略
(5)片段标识: 可以省略
2> URL encode(了解)
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现。
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义。一个中文字符由 UTF-8 或者 GBK 这样的编码方式构成, 虽然在 URL 中没有特殊含义, 但是仍然需要进行转义. 否则浏览器可能把 UTF-8/GBK 编码中的某个字节当做 URL 中的特殊符号.。
转义的规则如下: 将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。
这就意味着,如果看到url当中出现了特殊字符,比如说中文空格等等,其实都会先转义,然后再放在http协议的数据包当中。
urlencode(url编码):将里边中文,空格等转换为16进制。
urldecode(url解码):将url中16进制转换为原始的中文,空格。
3>查询字符串queryString
query string 中的内容是键值对结构. 其中的 key 和 value 的取值和个数, 完全都是程序猿自己约定的。
键值对的格式:
键 = 值
多个键值对之间用 & 间隔
key1=value1&key2=value2
前端(js代码)发送的时候,携带约定的键。后端(服务端)接收的时候,解析约定的键。
4>抓包观察http协议格式(详解)
在这里我们登录一个网页来查看对应的http协议格式。

是不是感觉很大一堆完全看不懂。但是分起来也就是以下四种:

首先可以看到,第一行是首行。

格式如下:
请求方法 url http版本号
然后就是我们能看到的那一大堆的东西,虽然说很乱很杂,但是我们可以发现我们仔细看的话是能看的懂的,这一部分就是我们的header头(请求头)
header头作用:标识http协议的属性
多个键值对的内容,每个键值对为( 键:值),多个键值对之间用换行符间隔
接着就是空行,空行代表header头结束
最后就是body(请求正文或者响应正文),

没错,这就是我写的这篇博客发出的Post请求。
body中的数据可以是任意格式,所以在服务器接收到了之后,要如何解析呢?这里就要看Content-type和Content-length

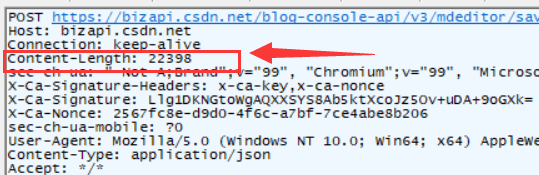
Content-Type:标识body的数据格式,作用是告诉对方要如何解析body
Content-Length:标识body的字节长度
C o n t e n t − T y p e 中 的 常 见 格 式 \color{red}{Content-Type中的常见格式} Content−Type中的常见格式
1.application/x-www-form-urlencoded为表单提交的格式:键 = 值,多个键值对
之间使用 & 间隔
2.image/jpeg:图片
3.text/javaScript text/html text/css
一般来说,请求正文的格式,我们常用的就是表单格式(上传数据到服务端),图片和视频(上传文件到服务端)等文件格式
响应正文的格式,常用的是text/javascript,text/css,text/html。
4.application/json。请求和响应都常用的和js对象的格式差
不多(只是键需要加双引号)
对于这种,请求就是输入一些内容后,提交数据到服务端。
响应就是服务端返回一些数据,客户端js代码获取响应,然后填充到html当中*。
<2>认识“方法”(method)
方法就是语义上操作资源的类型,但是很多情况下具体的实现还是由我们自己来实现的。
1>GET方法
get方法是最常用的http方法,常用于获取服务器上的某一个资源。
其特点如下:
1.GET方法一般用来获取资源(不是非要遵守,具体功能我们自己看)
2.在浏览器输入url,默认是GET方法
3.携带的数据使用queryString存放(所以可以为空)
4.body一般为空(要遵守)
在GET请求的URL长度取决于浏览器的实现和HTTP服务器端的实现,一般我们的浏览器支持长度都很长,但是在服务器端,这个长度我们可以自己配置。
2>POST方法
post也是一种常见的方法,多用于提交用户输入的数据给服务器。我们可以通过HTML中的form标签构造POST请求,也可以使用JS中的ajax来构造一个POST请求。
其特点如下:
1.POST方法是提交资源的
2.URL的queryString一般为空(也可以不为空)
3.header部分有若干个键值对结构
4.body部分一般不为空,body内的数据格式通过header中的Content-type决定,body长度由header中的Content-Length决定。
3>其他方法
1.PUT 与 POST 相似,只是具有幂等特性,一般用于更新
2.DELETE 删除服务器指定资源
3.OPTIONS 返回服务器所支持的请求方法
4.HEAD 类似于GET,只不过响应体不返回,只返回响应头
5.TRACE 回显服务器端收到的请求,测试的时候会用到这个
6.CONNECT 预留,暂无使用
4>问:GET和POST的区别?
<1>语义上:get是获取资源/数据,post是提交资源/数据(当然这里我们决定)
<2>存放数据的位置:get存放在queryString的位置,post存放在body的位置
<3>幂等性:get具有幂等性,post不具有幂等性
<4>缓存:get可以缓存,post不能缓存(这里不能打破,因为get有幂等性,浏览
器为了提高性能,就把get获取的资源提前保存在本地,下次请求直接从本地获取
就好了)
补充:这里的幂等性指的是,相同的http数据包多次发送,不会影响服务端的结果(和第一次发送结果一样)。
5>内容补充
关 于 安 全 \color{red}{关于安全} 关于安全
网络安全指的是网络被攻击而造成的信息泄露等等其他问题,http是一种明文协议
,http数据包的内容,不会进行任何加密,就直接以最原始明文的方式来传输,所
以在一定程度上,只要是http协议,就是不安全的
传 输 量 / u r l 长 度 \color{red}{传输量/url长度} 传输量/url长度
url长度在上面也说了,这里再次提一下,长度是由浏览器和web服务器决定的,
在http中是没有规范url长度的
传 输 的 数 据 类 型 \color{red}{传输的数据类型} 传输的数据类型
POST和GET都是可以传输文本和二进制数据的,就比如一张图片,作为二进制数据
使用base64就可以编码为字符串了。但是如果把这个字符串放在queryString当中
就可以直接使用get发送图片了
<3>认识请求“报头”(header)
header的作用是标识http数据包属性。它是由键值对构成,每一个键值对都会占据一行,键和值 冒号 间隔。
1>Host
Host用来标识服务器的地址(域名/ip + port)
2>Content-Length
标识body的长度,然后根据它来解析。
3>Content-Type
虽然前面也稍微提了一下,但是不妨碍我们在来一次不是,当然这次会更加详细。
1>multipart/form-data:简称form-data格式,一般用于请求,不用于响应。它
可以发送多个信息(字段),其中每个字段可以是简单的数据类型(数值型,字
符串,boolean等),也可以是复杂的数据类型(如图片,视频等等)。这就意味
着form-data可以上传任意多的数据,也可以是多个文件
2>applcation/x-www-form-urlencoded:表单格式,每个字段 键 = 值 ,多个
字段之间&间隔,和queryString格式一样,这里的字段值,只能是简单的数据类型
。
3>image/jpeg:指定具体的一个文件类型。如果用于客户端发送请求,也就只能上
传一个文件。如果用于服务端响应,也就只能返回一个图片。
4>applcation/json:json格式,请求和响应都常用。
4>User Agent(简称UA)
表示浏览器/操作系统的属性
5>Referer
标识当前这次http请求,是从哪个页面点击或跳转进来的。
6>Cookie
是一种客户端保存数据的技术。
1.保存的方式:是在由服务端响应的http数据包中,设置Set-Cookie头(一个或
多个)Cookie是和网站关联,不同的网站有不同的Cookie(保存的信息如账号等
不同网站保存为本地不同的Cookie)。
2.使用的方式:浏览器每次请求的时候,自动携带在请求Cookie头中
3.保存的数据格式:多组键值对(键 = 值,多个键值对之间分号分隔)。
7>Session
Session是一种服务端保存数据的技术,由于HTTP协议是一种无状态的协议(就是说每次服务端接收到客户端的请求时,都是一个全新的请求,服务端不知道客户端的历史请求记录),Session和Cookie的就是目的就是弥补HTTP的无状态特性。
在客户端请求服务端时候,服务端会为这次请求开辟一块内存空间,这个对象就
是Session对象,存储结构为ConcurrentHashMap,也就是Map<String,Session>这
样子的,这里的String就是CookieID的值。而一个Session对象就是一个用户会话
,里边可以存放一个用户需要的很多信息。
Map<String,Session>这里的Session是一个Map(String,Object),当然里边存放
什么键值对的数据,是由后端程序员实现的。
8>关于再次登录的问题
问题:服务端怎样知道当客户端访问的时候,是哪个用户呢?
一 丶 解 决 方 法 一 \color{red}{一丶解决方法一} 一丶解决方法一
登录后的访问页面,让他每次都携带用户账号密码信息,当然这样不安全,就像我们去超市买东西,如果我们是会员,那么每次都要携带身份证和银行卡才能有优惠,这样很不安全。
二 丶 解 决 方 法 二 \color{red}{二丶解决方法二} 二丶解决方法二
就是用我们的Cookie和Session,具体操作如下:
1.登录操作:服务端校验账号密码,效验成功。生成一个随机字符串(sessionID)
和一个Session对象,然后把这个SessionID的值作为键,保存在一个Map结构当中
Map<SessionID,Session>,然后把用户信息保存在Session对象当中,即就是
Map<String,Session>。
2.登录响应:登录操作,服务端返回给客户端的HTTP响应数据包当中,Set-Cookie
响应头当中,包含sessionID = 值。这里的SessionID服务端和客户端决定就好,
里的值就相当于会员卡卡号了。
3.客户端保存Cookie信息:将响应的Set-Cookie内容保存在客户端本地,和本服务
器绑定。
4.客户端每次发送请求时,都携带sessionID = xxx随机字符串。
5.以后服务端获取请求的时候,先获取Cookie请求头的内容,查看里边(内容是多
个键值对的数据),键叫sessionID的,获取到sessionID的值,然后从保存的Map
结果中查询,Session session = Map.get(sessionID)。如果存在,就是VIP用户
,如果为Null,就是新用户
9>内容补充
<1>服务端保存的session信息,有默认的过期时间。在服务器当中,有session的过期效验机制:通过单独的一个线程扫描,发现当前时间和session最后一次使用时间超时,就删掉。而服务器存放Session的地方,web服务器默认是放在内存,所以重启服务器的时候,session也没了。
<2>如果用户注销登录,就是把服务器当中Map<SessionID,session>删掉了,所以:注销之后,超时之后,重启之后,服务端保存的Session也就没了,此时客户端访问一些需要登录才能查看的页面,就需要登录–跳转到登录页面
<3>Cookie也有过期时间,当然这个过期时间和上面的session过期时间都是可以通过程序设置的。如果Cookie过期,浏览器就不会携带这些信息(没有携带会员卡),服务端又会验证sessionID值绑定的Session对象,如果找不到,此时就肯定找不到,对应也就是没有登录。
<4>认识请求正文“body”
同上Content-type类型。















 387
387











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









