







目录
系列文章目录
刷题笔记(一)–数组类型:二分法
刷题笔记(二)–数组类型:双指针法
刷题笔记(三)–数组类型:滑动窗口
刷题笔记(四)–数组类型:模拟
刷题笔记(五)–链表类型:基础题目以及操作
刷题笔记(六)–哈希表:基础题目和思想
刷题笔记(七)–字符串:经典题目
刷题笔记(八)–双指针:两数之和以及延伸
KMP算法详解
关于这个算法,笔者尽力表达清楚。
1.什么是KMP算法?
首先,什么是KMP算法?它是用来干啥什么的?我们会碰到一类题,就是给你一个主字符串比如说:aabaabaafa,然后让你查找在这个字符串当中,是否出现过一个模式字符串比如说:aabaaf。我们怎么办呢?(请注意并且牢记这里的主字符串和模式字符串!!!)
一般我们很容易想到BF算法,也就是暴力遍历(这里不对BF算法做解释)。但是这种算法有一个很大的缺陷就是时间复杂度很大,是O(m * n),因为有很多重复的遍历,那么能不能有一种算法减少这种重复的次数呢?由此,三位学者Knuth,Morris和Pratt发明了KMP算法。KMP算法的主要思想就是:
当字符串不匹配的时候,可以确定之前已经匹配过的一些字符串内容,然后利用已知内容或者说是信息去减少匹配次数。
2.关于前缀表
<1>什么是前缀表?
KMP算法里面储存已知的信息的数组叫做next数组,那么为什么我这里要提next数组呢?因为前缀表就是一个next数组,这个下面会详细讲一下。然后我们继续谈一下前缀表,我们这里说了,前缀表里面存着已知的信息,那么这个已知的信息是什么呢?
就是记录了当主字符串和模式字符串不匹配的时候,模式串应该从哪里开始匹配
是不是有点绕?因为上面这种说法偏向于思想,没有具体实例不好理解。没关系,那我们具体一点点,先从具体表现来说:
前缀表记录了下标i之前(包括i)的字符串中,最大长度的相同前缀和后缀
那 么 前 缀 和 后 缀 指 的 是 什 么 ? \color{red}{那么前缀和后缀指的是什么?} 那么前缀和后缀指的是什么?
我们用一个例子来举例,随便来一个字符串aabaaf,这个字符串的前缀是什么呢?
a,aa,aab,aaba,aabaa
注意这里不包含字符串整体,前缀和后缀都是。那么后缀是什么呢?
f,af,aaf,baaf,abaaf
所以我们可以发现,前缀和后缀没有相同的,所以如果说前缀表里i之前包括(i)出现了这个字符串,那么它对应的前缀表的值就是0。是不是有点没有讲清?那么我们继续具体,还是这个字符串aabaaf,它的前缀表是怎样的呢?我们从第一个字符串开始遍历这个字符串:
[0,1,0,1,2,0]
a:当i = 0的时候,也就是仅仅只有一个字符'a'的时候,它没有前缀,也没有后缀,所以就是0
aa:当i = 1的时候,也就是当前字符串为'aa'的时候,前缀是a,后缀也是a,所以前后缀最大相同长度就是1
aab:当i = 2的时候,当前字符串为'aab',这个时候没有相同的前缀和后缀,所以是0
aaba:当i = 3的时候,当前字符串为'aaba',这个时候最大相同前后缀是a和a,所以是1
aabaa:当i = 4的时候,当前字符串为'aabaa',这个时候最大相同前后缀是aa和aa,所以是2
aabaaf:当 i = 5的时候,当前字符串为'aabaaf',这个时候没有最大相同前后缀,所以是0
现在如果让你写一个字符串的前缀表是不是就能写出来了?那么继续往下走
<2>为什么要用前缀表?
接下来我们要好好理一理这句话
前缀表记录了当模式串和主串不匹配的时候,模式串从哪里开始匹配。
还是这个模式字符串aabaaf,还是这个主字符串aabaabaafa,如果说按照暴力遍历算法(绿色竖线代表匹配,红色竖线代表不匹配),就是下面的情况:
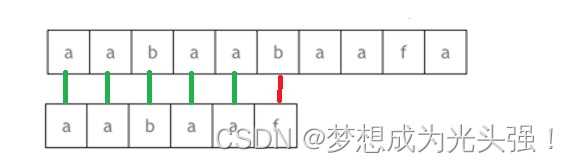
模式串最后一个字符串f和当前主串的下标字符b是不是不匹配,那么接下来就要一步步往后移动
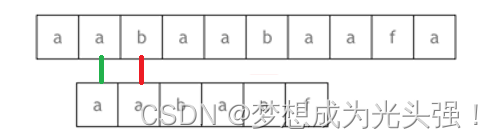
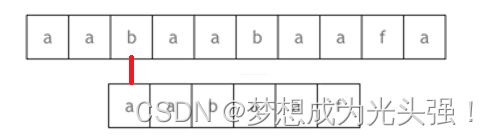
最后才会匹配成功,这是BF算法。但是如果说是按照KMP算法的思想,按照前缀表来进行操作
如果模式串和主串不匹配,那么按照前缀表记录的,从当前匹配失败的字符的前一个字符对应的next数组值开始遍历模式串(这里不固定嗷,具体要根据实际情况来说,但是这里按照我这种先理解)
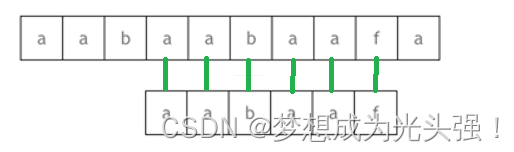
是不是又感觉有点绕?那么还是这个模式字符串aabaaf,还是这个主字符串aabaabaafa,我们前面不是说了这个模式字符串的前缀表是[0,1,0,1,2,0]。当最后一个字符匹配失败的时候
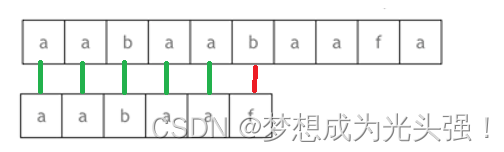
也就是上面这种情况的时候,接下来不是一步一步的后移了。接下来是查询next数组,看到对应的前一个字符对应的next数组值是2
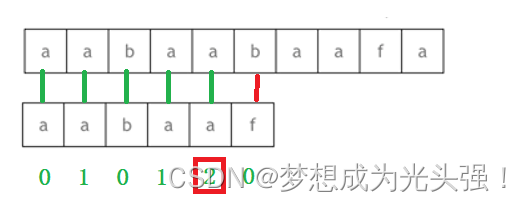
然后从模式串的下标为2的地方开始匹配,也就是
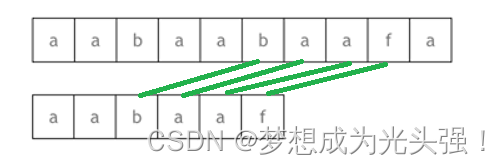
所以明白了吗?虽然模式串和主串的最后一个匹配的字符失败了,但是匹配失败的地方是模式串的后面,他们前面是一样的,所以就直接找到相同前缀的地方开始匹配就好了。
所以如果当前匹配失败,那么就让前缀表来告诉我们应该跳到那个匹配成功的地方再次开始匹配
3.前缀表和next数组
我们前面说了,前缀表其实就是next数组,那么为什么我们不这样叫呢?而是要把他们分开?
前缀表:记录了最大相同前后缀的长度
next数组:是前缀表具体的应用
什么意思?这样说,前缀表就是next数组,但是next数组有时候会对前缀表做一点小小的改变。我们可以直接用前缀表作为next数组,也可以把前缀表所有的数字往右移一位,然后首位补成-1,作为next数组

也可以把前缀表所有下标的值 -1作为next数组

所以如果你在网上看关于KMP算法的文章,你就会发现有时候会很迷,这篇文章是这样的一种说法,其他文章又是另外一种说法,但其实思想的方向都是一样的,不同的是具体的实现方式。这里的话,我们主要讲一下前缀表值-1的这种next数组。
4.关于具体实现
关于具体的实现,这里一共是分为三步进行。
<1>初始化
首先就是定义两个指针i和j,j指向前缀末尾位置,i指向后缀末尾位置。
int j = -1;
next[0] = j;
那这里可能就有小伙伴要问了,j为什么初始化为-1?两个理由:
<1>j要赋值给next的数组对应的下标的值,而前缀表第一个一定是0,减了1之后就是-1
<2>我们这里采取的是前缀表的下标值 -1的next数组。所以之后我们j的下标具体表示其实是j + 1
所以我们这里j初始化为-1。这里的next[i]表示i(包括i)之前的前后缀的长度(其实也就是j)
<2>前后缀不相同的时候
刚开始j初始化为-1,那么我们比较怎么比较呢?
s[i] 和 s[j+1]
因为j的值-1了,所以这里就是上面的比较。i的下标没啥好说的,肯定是从1开始的
for (int i = 1; i<s.length(); i++){}
如果说遇到s[i]和s[j+1]不相同,那么我们就要向前回退。什么意思呢?next[j]记录着j(包括j)之前的子串的相同前后缀的长度。那么当s[i] 和 s[j + 1]不同的时候,我们需要去找j + 1的前一个元素在next数组里面的值,也就是找到next[j]
while(j>=0 && s.charAt(i) != s.charAt(j+1)){
j=next[j];
}
这里要特别注意这个回退的思想,在求前缀表里这是一个需要我们细细咀嚼的知识点。
<3>前后缀相同的情况
如果说s[i]和s[j+1]相同,这个时候就要往后移动i和j了,说明相同的前后缀已经找到了,同时将j(前缀长度)赋值给next[i],因为next[i]要记录相同前后缀的长度。
if(s.charAt(i)==s.charAt(j+1)){
j++;
}
next[i] = j;
所以整体构建next数组代码如下;
public void getNext(int[] next, String s){
int j = -1;
next[0] = j;
for (int i = 1; i<s.length(); i++){
while(j>=0 && s.charAt(i) != s.charAt(j+1)){
j=next[j];
}
if(s.charAt(i)==s.charAt(j+1)){
j++;
}
next[i] = j;
}
}
5.关于next数组具体应用
这个具体应用就和我们前面说的一样,如果相同就往后移动,不相同就读取next数组对应的前一个值。当然这里有一个点是需要我们注意的,我们定义遍历模式串的指针j的时候下标要初始化为-1,因为next数组里面记录的初始位置为-1,那么一步一步来,遍历主串
for (int i = 0; i < s.size(); i++)
如果说s[i]和s[j+1]不相同,那么j就要从next数组里面寻找下一个匹配的位置
while(j >= 0 && s[i] != t[j + 1]) {
j = next[j];
}
如果相同,那么i和j就同时往后移动
if (s[i] == t[j + 1]) {
j++; // i的增加在for循环里
}
那么怎样判断主串中是否出现了模式串呢?就是当j遍历完的时候,就代表主串中包含了模式串,这个时候如果说让你求文本串在主串中出现的第一个位置,就把i的位置减去字符串的长度然后+1就好。
if (j == (t.size() - 1) ) {
return (i - t.size() + 1);
}
所以匹配的整体代码如下:
int j = -1; // 因为next数组里记录的起始位置为-1
for (int i = 0; i < s.size(); i++) { // 注意i就从0开始
while(j >= 0 && s[i] != t[j + 1]) { // 不匹配
j = next[j]; // j 寻找之前匹配的位置
}
if (s[i] == t[j + 1]) { // 匹配,j和i同时向后移动
j++; // i的增加在for循环里
}
if (j == (t.size() - 1) ) { // 文本串s里出现了模式串t
return (i - t.size() + 1);
}
}
整体思路就有了,接下来我们用一些题来实践一下。
题目
28. 实现 strStr()
题目链接如下:
题目截图如下:
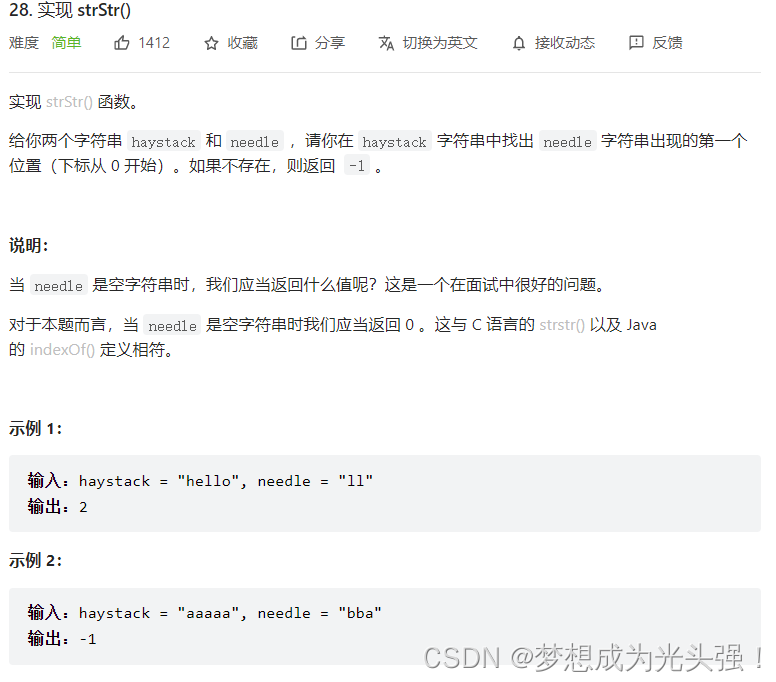
那么这题也是有两种解法
BF算法
也就是时间复杂度为O(m*n)暴力算法,这里我们把haystack = “hello”, needle = “ll” 中前者为主串,后者为模式串
public class 实现strStr_BF {
public int strStr(String haystack, String needle) {
//如果说主串或者模式串任意一个为空,那就返回0
if(haystack == null || needle == null){
return 0;
}
int hay_len = haystack.length();
int nee_len = needle.length();
//进行BF算法的具体实现
for (int i = 0; i < hay_len; i++) {
//定义一个临时指针key,这里不能直接对i操作
int key = i;
for (int j = 0; j < nee_len; j++) {
//如果说检测到key越界或者说两个对应字符不相等那就直接break
if(key > hay_len-1 || haystack.charAt(key) != needle.charAt(j)){
break;
}
//能来到这一步可以确定当前两个字符相等,那么就判断一下,如果j已经是模式串末尾位置,那就直接返回主串当前的下标
if(j == nee_len - 1){
return i;
}
//如果说j不是末尾位置,那就让key和j继续往后走,一直比较
key++;
}
}
//如果最后检测到主串没有包含模式串,那么就直接返回-1
return -1;
}
}
当然这里为了减少重复内容的匹配,我们也可以使用KMP算法。
KMP算法
public class 实现strStr_KMP {
public int strStr(String haystack, String needle) {
//先进行检测,如果模式串或者说是主串有一个为Null,那么就直接返回0
if(haystack.length() == 0 || needle.length() == 0){
return 0;
}
//定义一个长度和needle也就是模式串长度相同的int数组来进行next数组的存储
int[] next = new int[needle.length()];
//调用next()来进行next数组的获取
next(needle,next);
//定义指针j来遍历模式串
int j = -1;
for (int i = 0; i < haystack.length(); i++) {
//如果说模式串和主串不相同,那么就根据next数组的指示来进行回退
while(j >= 0 && haystack.charAt(i) != needle.charAt(j+1)){
j = next[j];
}
//如果模式串和主串相同那么就同时移动i指针和j指针
if(haystack.charAt(i) == needle.charAt(j+1)){
j++;
}
//如果说遍历模式串的j指针当前下标已经来到了模式串的末尾,那么就证明模式串被子串包含,返回主串对应的下标即可
if(j == needle.length() - 1){
return (i - needle.length() + 1);
}
}
//如果最后没找到就返回-1
return -1;
}
public void next(String needle,int[] next){
int j = -1;//首先初始化j为-1
next[0] = j;//next[0]初始化为j
for (int i = 1; i < needle.length(); i++) {
//如果说此时不相等就回退
while(j >= 0 && needle.charAt(i) != needle.charAt(j+1)){
j = next[j];
}
//相等的话前缀和后缀指针就同时往后走
if(needle.charAt(i) == needle.charAt(j+1)){
j++;
}
next[i] = j;
}
}
}
459. 重复的子字符串
题目链接如下:
题目截图如下:
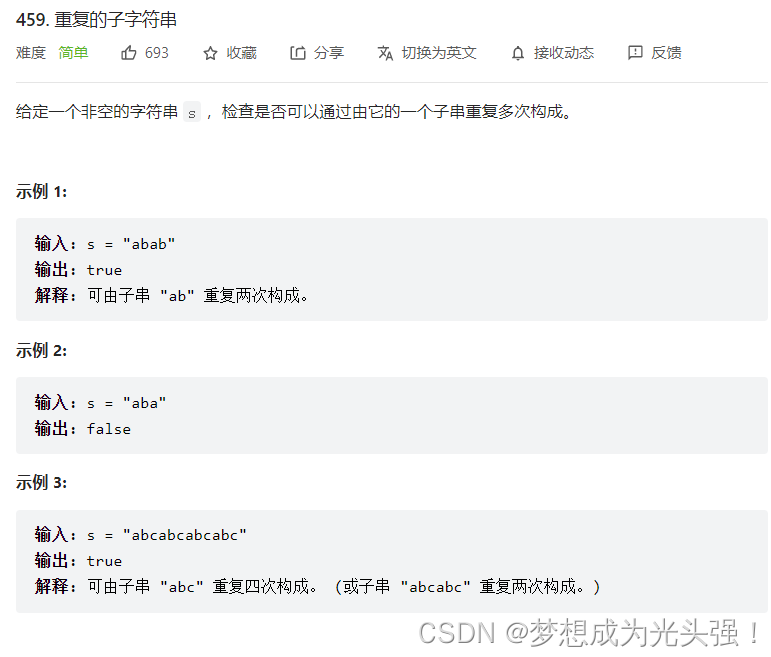
其实看到这道题的笔者愣了好久,因为上手的思路有点奇怪,最后还是看了好多题解才明白这道题有多精彩。
一行代码版本
这道题一行代码其实就可以搞定。
我们假设一个字符串S由n个子串s构成,即就是S = sn。那么我们构造一个字符串T把两个S拼接起来,所以就会有T = S + S = 2sn。我们这个时候去掉开头的字符和尾部的字符,也就是把这两处的子串给破坏了,那么这个时候T里面就会有2n - 2个子串。由于T里面有2n-2个子串,S里面有n个子串,如果说T包含了S,那么2n - 2 >= n,即就是n >= 2,也就是说一个字符串S最少由两个子串s构成,这个时候就可以判定为true。如果2n-2 < n,即就是 n < 2,这个时候就是false,也就是这个时候n只能为1,最后判定也就是false。
所以代码如下:
public class 重复的子字符串_一行代码版 {
public boolean repeatedSubstringPattern(String s) {
return (s+s).substring(1,s.length()*2-1).indexOf(s) != -1;
}
}
KMP解法
其实仔细想一想,这就是一道很典型的KMP的题。next数组记录了什么?是不是最大相同前后缀的长度?如果说next[len-1] != -1,那么就说明字符串有最长相同的前后缀(也就是字符串里面最长相同前后缀的长度)。此时最长相同前后缀的长度为next[len - 1] + 1。此时如果说有len%(len-(next[len - 1] + 1)) == 0。那么就可以说明(数组长度-最长相等前后缀的长度)正好可以被数组长度整除,说明字符串有重复的子字符串。
这里说明一下为什么证明就可以被整除。这里(数组长度-最长相等前后缀)其实就是一个周期的长度,如果说这个周期的长度可以被整除,那么就说明整个数组就是一个循环的周期。
public class 重复的子字符串_KMP算法版 {
public boolean repeatedSubstringPattern(String s) {
if (s.equals("")) return false;
int len = s.length();
// 原串加个空格(哨兵),使下标从1开始,这样j从0开始,也不用初始化了
s = " " + s;
char[] chars = s.toCharArray();
int[] next = new int[len + 1];
// 构造 next 数组过程,j从0开始(空格),i从2开始
for (int i = 2, j = 0; i <= len; i++) {
// 匹配不成功,j回到前一位置 next 数组所对应的值
while (j > 0 && chars[i] != chars[j + 1]) j = next[j];
// 匹配成功,j往后移
if (chars[i] == chars[j + 1]) j++;
// 更新 next 数组的值
next[i] = j;
}
// 最后判断是否是重复的子字符串,这里 next[len] 即代表next数组末尾的值
if (next[len] > 0 && len % (len - next[len]) == 0) {
return true;
}
return false;
}
}
总结
其实有一说一,还是要多多复习,温故而知新,笔者虽然文章写了下来,但是好多地方其实还是一知半解,唉,加油吧。















 1337
1337











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









