






Input:
分子由原子和化学键描述。
蛋白质、RNA 和 DNA 具有规则化的一般结构(生物大分子骨架),这使得在原子级别上表示这些实体过于详细。因此,使用不同的token来表示不同的分子。
AlphaFold2是一个纯蛋白质结构预测工具,有23个标记:20个标记代表标准氨基酸中的每一个,一个标记代表未知氨基酸,一个代表间隙(gap)的标记,以及一个用于掩码多序列比对(MSA)的标记。
AlphaFold3还考虑了RNA、DNA 和一般分子。对于DNA 和 RNA,标记对应于整个核苷酸。对于所有其他一般分子,一个标记由一个单个重原子表示。
网络架构
BLOCK:
- **Input:**特征、循环次数和两个维度参数(cs,cz)。
- 步骤1:通过输入特征embedder处理输入特征。
- 步骤2-5:初始化single和pair的repr,并对其进行无偏置线性变换和相对位置编码。
- 步骤6:初始化single和pair repr的暂存变量。
- 步骤7-14:在指定的循环次数内,通过层归一化和无偏置线性变换更新single和pair repr,使用Template embedder和MSA进行进一步处理,然后通过Pairformer进行迭代优化。
- 步骤15:通过扩散采样过程生成预测的三维结构。
- 步骤16:使用置信度头计算预测结构的局部距离差异测试分数、预测对齐误差矩阵、预测距离误差矩阵和解析度。
- 步骤17:通过Distogram头计算距离直方图。
- 步骤18:返回预测结构、各种评分和距离直方图。
AF2:
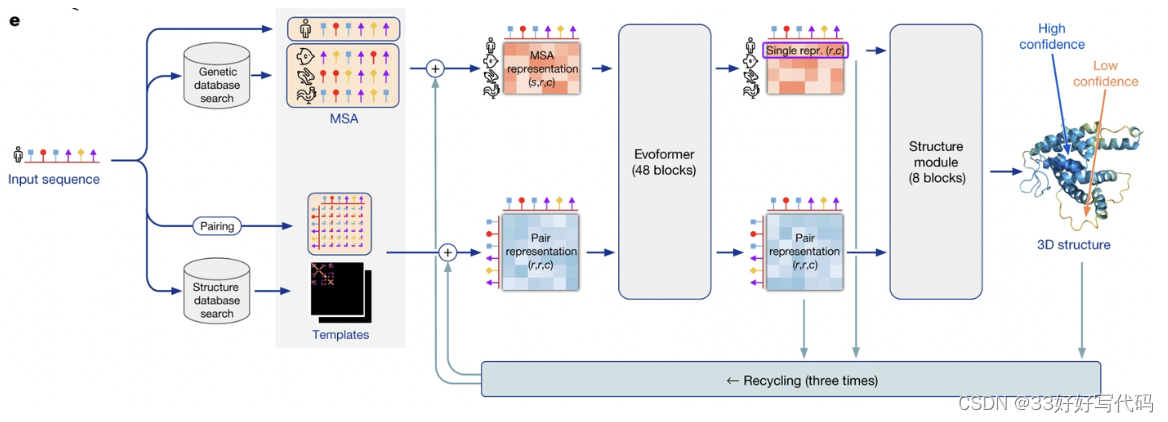
AF3:
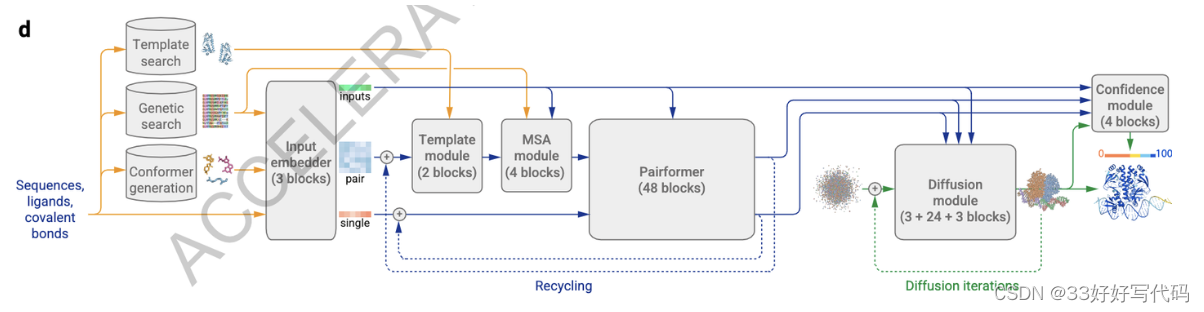
Input:
input(seq)、pair、single、结构(用来做加噪去噪)
不同:
- MSA表示的处理使用了一种廉价的成对加权平均方法,且仅使用pair repr进行后续处理步骤
- AlphaFold3中的MSA模块比AlphaFold2小得多(仅有四个块),并且已从新的Pairformer模块中删除。
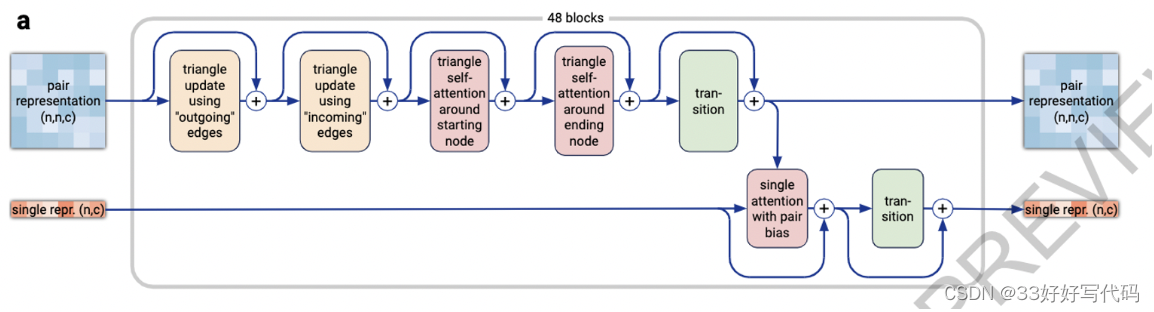
- AlphaFold3中的Pairformer模块取代了AlphaFold2中的Evoformer模块。虽然两个模块的结构相似,除了删除了MSA模块(见上一点),但Pairformer模块还有一些内部的变化。例如,信息从对表示到单表示的流动,但反之则不然。
- Pairformer"(图2a)取代了AlphaFold2的"Evoformer",成为主要的处理块——只操作single repr和pair repr;MSA repr不保留,所有信息都通过成对表示传递。
- single repr和pair repr连同输入表示一起传递给diffusion取代了AlphaFold2的结构模块
- 大多数的ReLU激活函数在AlphaFold3中被SwiGLU激活函数所替换,以提高性能。
MSA
在AlphaFold2中,MSA处理是通过复杂的Evoformer块进行的:特征提取和转换。而在AlphaFold3中,这部分被简化,替换为更小、更高效的模块,即Pairformer块,这些模块专注于对pair repr进行处理,而不是之前那样广泛地处理多个序列间的关系 。
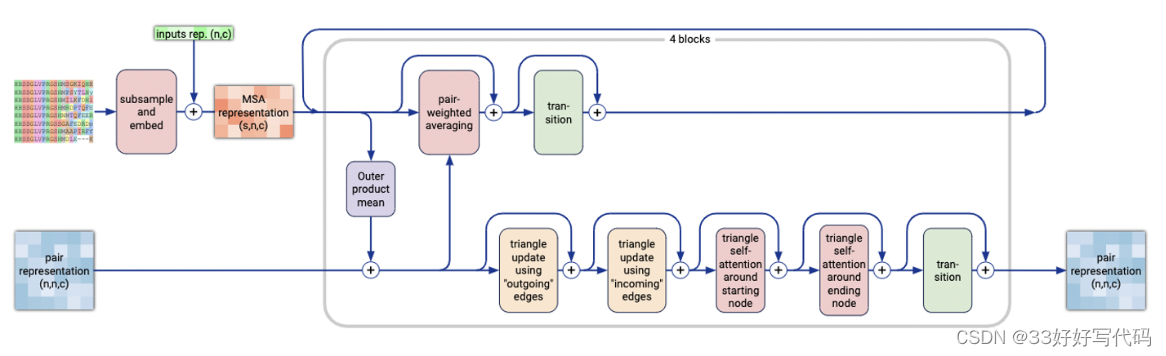
MSA 模块包含四个块,比 AlphaFold2 的 48 个块少得多
AlphaFold3 的 MSA 模块不使用逐行门控自注意力。
第一行是查询(输入)序列。接下来的行是通过将 MSA 复制 n 次以用于同源复合物(其中 n 为链重复的次数)或者通过将每个链的 MSA 从左到右堆叠在一起来构建的,然后配对异源复合物的序列。剩余未配对的 MSA 序列将添加在下方。
最终,MSA 矩阵的行中包含不同的 MSA 序列,而对齐的残基位于列中。在 AlphaFold2 中应用逐行门控自注意力会生成残基对的注意力权重,得到pair repr。在 AlphaFold3 中,注意力是针对每一行独立进行的。这也意味着注意力权重是从成对嵌入生成的。换句话说,这种变化更加关注成对表示,而不是残基对之间的 MSA。然而,这些成对表示包含来自 MSA 行中的残基对的一些信息,这些信息来自输入嵌入。
这种变化的影响是什么呢?嗯,MSA 行注意力关注同一序列的不同残基对。这由导致这些标记之间相互作用的特征表示。这些特征应该被编码到这些残基的成对表示中,因此让完整的信息通过成对表示是有意义的,可以理解为更准确的生成pair repr!
PairFormer
Input:
输入参数 {si} 和 {zij},以及块的数量 Nblock。
2. pair的处理
每次循环包括以下几个步骤,针对成对特征 {zij} 的处理:
- 行向Dropout和三角乘法:
- DropoutRowwise0.25(TriangleMultiplicationOutgoing({zij})):对
{zij}应用行向 Dropout 和向外的三角乘法,增加模型的泛化能力,并处理信息的传递。 - DropoutRowwise0.25(TriangleMultiplicationIncoming({zij})):应用行向 Dropout 和向内的三角乘法,处理信息的聚集。
- DropoutRowwise0.25(TriangleAttentionStartingNode({zij})):处理从起始节点发出的注意力,通过三角形结构增强局部上下文的理解。
- DropoutColumnwise0.25(TriangleAttentionEndingNode({zij})):列向 Dropout 和结束节点的注意力处理,加强对结尾信息的注意。
- DropoutRowwise0.25(TriangleMultiplicationOutgoing({zij})):对
- Transition({zij}):成对特征的状态转换,更新成对表示。
3. 单一堆栈的处理
对单一token特征 {si} 的处理包括:
- 带偏置的注意力对:
- AttentionPairBias({si}, ∅, {zij}, βij = 0, Nhead = 16):在没有额外单独特征的情况下,对
{si}应用带成对偏置的注意力,这有助于根据{zij}中的成对信息调整{si}。
- AttentionPairBias({si}, ∅, {zij}, βij = 0, Nhead = 16):在没有额外单独特征的情况下,对
- Transition({si}):单一特征的状态转换,进一步更新token表示。
4. 循环和输出
- 经过指定次数的循环后,函数返回更新后的单一特征
{si}和成对特征{zij}。
Diffusion Module
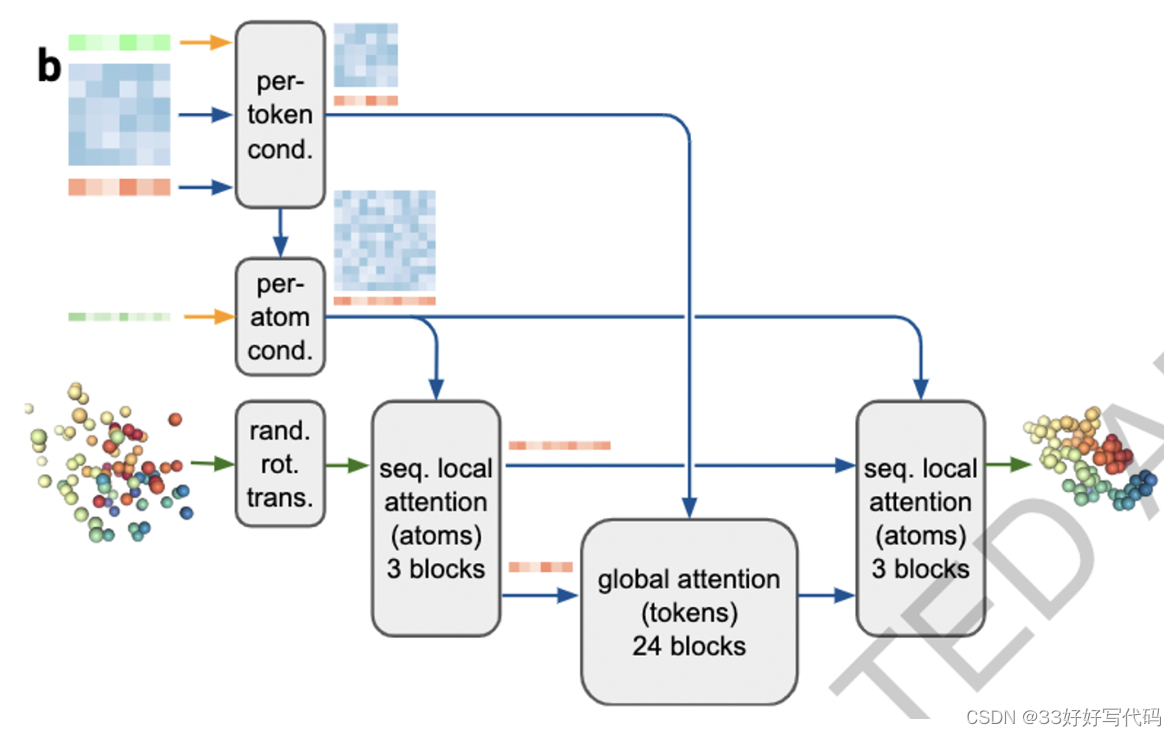
扩散模型经过训练“加噪”原子坐标然后预测真实坐标。这项任务要求网络在多种长度尺度上学习蛋白质结构,其中小噪声任务强调了非常局部的立体化学理解,而大噪声任务强调系统的大尺度结构。在推理时,随机噪声被采样,然后反复去噪以产生最终结构。重要的是,这是一个生成性训练过程,产生一系列答案。这意味着,对于每个答案,局部结构将被清晰定义(例如,侧链键的几何形状),即使网络对位置不确定。因此,我们能够避免对残基的扭转参数化和对结构的violation loss,同时处理一般配体的全部复杂性。
生成模型容易出现幻象现象
我们采用了一种新颖的交叉蒸馏方法token broadcasting activations(将小数据集扩展或复制到更大的数据结构)。我们使用AlphaFold-Multimer v2预测的结构丰富训练数据。这些结构中,无结构的区域通常由长的延展循环表示,而不是紧凑的结构。训练这些表示可以帮助AlphaFold3模仿这种行为,从而显著减少AF3的幻觉行为。
算法步骤
- 条件设置:
- DiffusionConditioning:从输入特征中提取条件信息,这些信息将用于后续的去噪过程。
- 标准化位置数据:
- 将带噪声的位置**
⃗xnoisyl**除以标准化因子(基于时间步长ˆt和数据标准差σdata),以使得位置向量具有单位方差。
- 将带噪声的位置**
- 原子级注意力编码:
- AtomAttentionEncoder:使用原子级别的注意力机制处理标准化的位置数据,然后聚合到更粗粒度的token级别。
- 这一步涉及将原子信息转换成token级别的特征**
ai**,同时保留跳过连接的各种状态,以便后续步骤使用。
- token-level self-attention:
- 对token特征**
ai**进行自注意力处理,这一处理涉及多个block和头。 - 使用层归一化和无偏置线性变换增强token的表示。
- 对token特征**
- 将token broadcasting activations(将小数据集扩展或复制到更大的数据结构)到原子并运行原子级注意力解码:
- AtomAttentionDecoder:将token激活转换回原子级,通过注意力机制更新原子位置。
- 重新缩放位置更新并与输入位置结合(sample diffusion):
- 使用一个缩放因子,该因子基于时间步长和数据标准差,调整位置更新的规模。
- 将缩放后的更新与原始带噪声的位置结合,得到最终的输出位置
⃗xoutl。
- 返回更新后的位置:
- 返回经过扩散过程处理后的位置数据
{⃗xoutl},这些位置预期接近原子在无噪声条件下的真实位置。
- 返回经过扩散过程处理后的位置数据
Sample Diffusion
扩散过程循环:
- 循环遍历噪声调度表
[c1, ..., cT]中的每一个噪声级别cτ。
调整噪声系数:
- 根据当前的噪声级别
cτ和预设的最小噪声阈值γmin决定使用的噪声系数γ。如果cτ大于γmin,使用γ0;否则,使用0。 - 生成噪声向量
⃗ξl,该向量由当前噪声级别cτ的平方与正态分布噪声结合生成,然后乘以噪声规模λ。
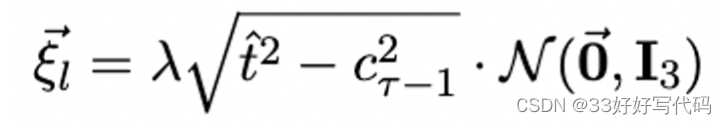
变量:时间步长、噪声调度
Diffusion Conditioning:条件引导生成
- pair condition:
- Step 1:将来自主干的pair embedding**
{ztrunkij}与相对位置编码结合。相对位置编码基于输入特征{f*}**生成,用于增强位置信息。 - Step 2:对合并后的pair embedding应用线性无偏置变换和层归一化,标准化数据,以便进一步处理。
- Step 3-5:通过一个循环,其中包含两次Transition操作(状态转换),进一步处理和精细调整pair embedding。
- Step 1:将来自主干的pair embedding**
- single condition:
- Step 6:将来自主干的single embedding**
{strunki}与单个输入input{sinputsi}**合并。 - Step 7:对合并后的single embedding应用线性无偏置变换和层归一化,进行标准化处理。
- Step 8:计算傅里叶嵌入**
n**,这是基于时间步的对数和数据标准差的函数,用于捕捉时间相关的变化。 - Step 9:将傅里叶嵌入经过层归一化和线性无偏置变换后,加入到单个嵌入中。
- Step 10-12:与成对条件设置类似,单个条件也通过两次Transition操作进行进一步处理和优化。
- Step 6:将来自主干的single embedding**
感觉对single进行傅里叶嵌入是为了更好的处理区分时间步?不知道🤷♀️
Diffusion Transformer = Transformer+Attention
- 注意力偏置的计算:通过算法24,计算带有偏置**
{βij}**的注意力。这一偏置可以根据模型的需要被设计来强调或减少特定token对之间的交互强度。 - 门控机制:使用门控信号**
{gh_i}**(通过sigmoid函数和线性变换得到)来调节token间的信息流。这种门控机制使得模型可以更加灵活地控制信息的聚焦和传播。 - 自注意力的计算:自注意力通过计算token之间的点积加上注意力偏置,并应用softmax进行归一化,从而确定每个token对其他token的关注程度。
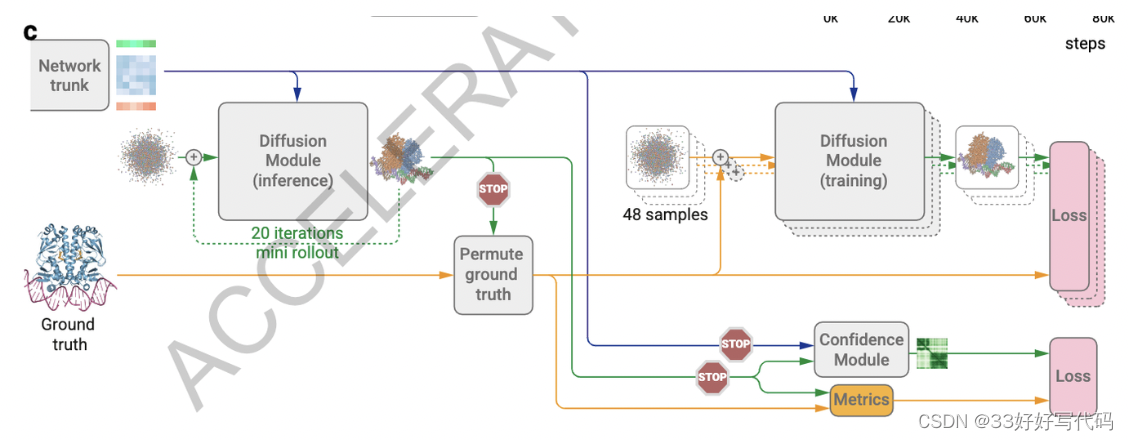
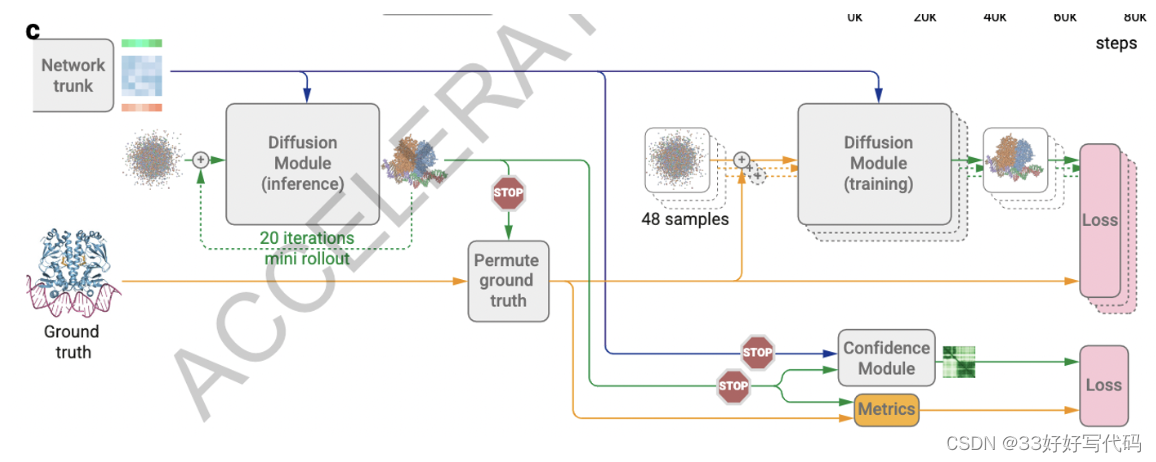
预测最终结构中原子级别和成对误差的置信度措施。
在AlphaFold2中,这是通过在训练期间直接回归结构模块输出的误差来完成的。然而,这种程序不适用于扩散训练,因为扩散训练只涉及单步预测,而不是完整的结构生成。
为了弥补这一点,我们开发了一个完整结构预测生成的扩散“rollout”程序,它在训练期间使用比正常更大的步长。这个预测的结构然后用于排列对称的基准链和配体,并计算性能指标,以训练置信度指标。置信度头使用pair repr来预测局部距离差异测试(LDDT)分数和预测对齐误差(PAE)矩阵,以及与真实结构相比预测结构的距离矩阵的误差。
开源消息:
GitHub - kyegomez/AlphaFold3: Implementation of Alpha Fold 3 from the paper: "Accurate structure prediction of biomolecular interactions with AlphaFold3" in PyTorch(这个是用openfold复现的,非官方,没有试过,欢迎大家试了来讨论)
欢迎大家来讨论!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









