







 文章探讨了Mamba模型,一种结合了Transformer的并行化能力和RNN的记忆控制,通过StateSpaceModel处理长序列。Mamba通过选择性扫描和硬件感知算法优化计算,解决了SSM在处理远程依赖和内容感知上的局限性。
文章探讨了Mamba模型,一种结合了Transformer的并行化能力和RNN的记忆控制,通过StateSpaceModel处理长序列。Mamba通过选择性扫描和硬件感知算法优化计算,解决了SSM在处理远程依赖和内容感知上的局限性。
Mamba
Transformer到Mamba
- Tranformer缺陷:
- 一次性矩阵每个token进行比较(支持并行化)
- 推理缺陷:生成下一个token任务中,要算所有token的注意力(L^2)
- RNN解决:
- RNN只考虑之前隐藏状态和当前输入,防止重新计算所有先前状态
- 但RNN会遗忘信息(不然就不会有Transformer出现了)
- RNN是顺序循环——>训练不能并行
其实这也不能说是谁解决谁缺陷吧,毕竟lstm和transformer的出现就是为了解决RNN的遗忘的总之,RNN推理速度快,但不能并行,Transformer反之。
❓能否以某种方式找到一种像 Transformer 这样并行训练的架构,同时仍然执行随序列长度线性扩展的推理?
SSM(State Space Model)
State Space:
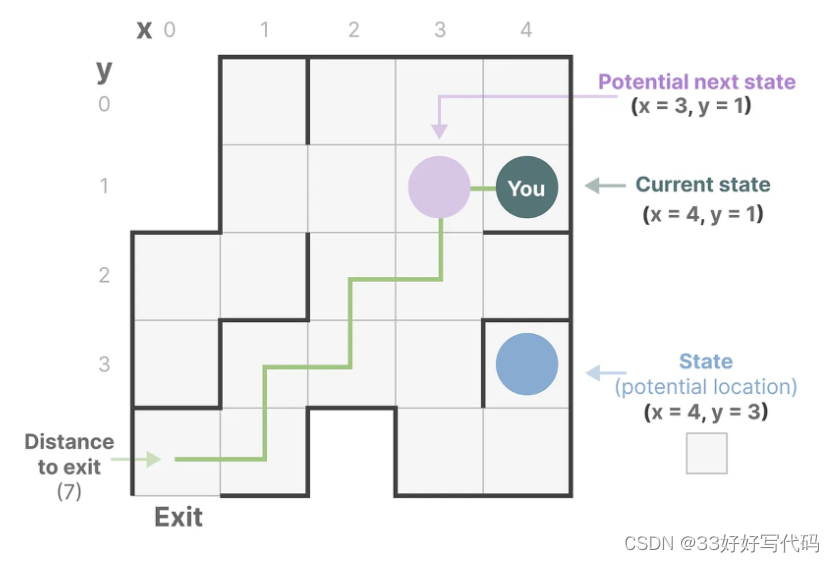
SSM:预测下一个状态
- 输入序列x(t) —(在迷宫中向左和向下移动)
- 潜在状态h(t) —(距离和 x/y 坐标)
- 预测输出序列y(t) —(再次移动以更快到达出口)
然而,它不使用离散序列(如向左移动一次),而是将连续序列作为输入并预测输出序列。
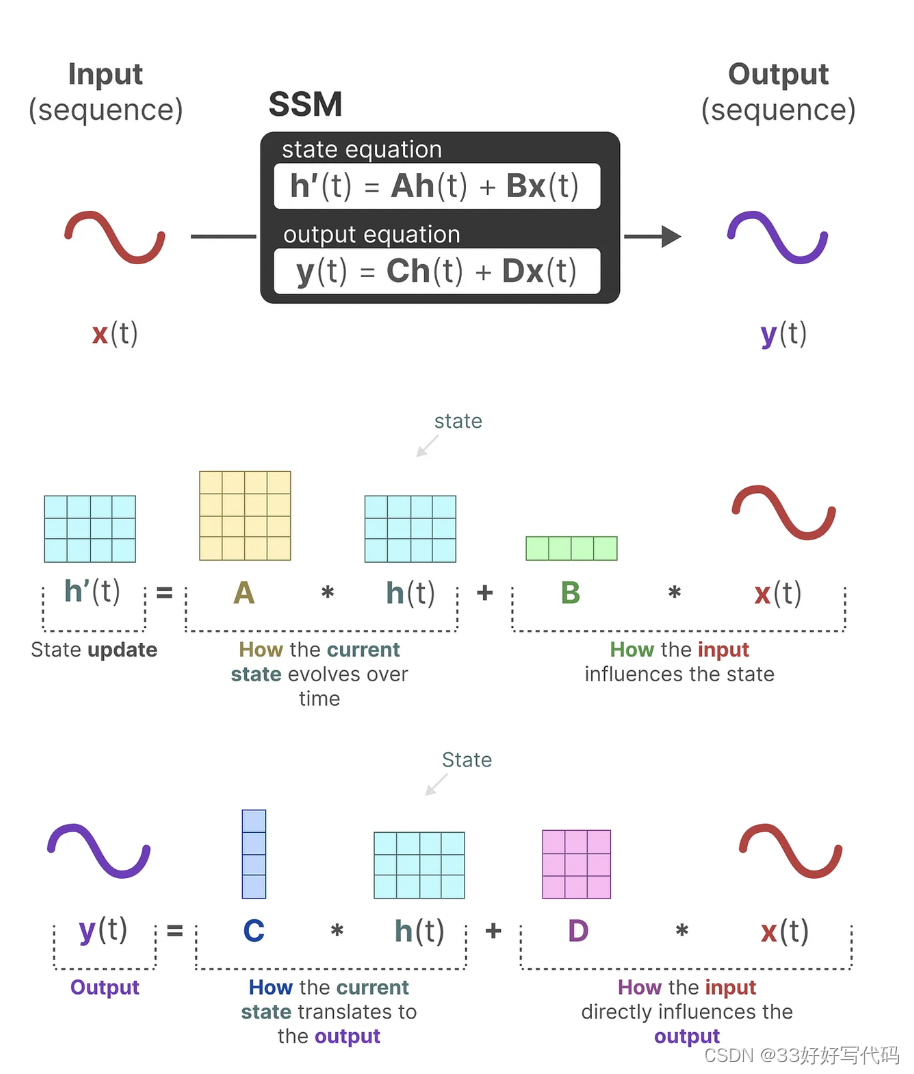
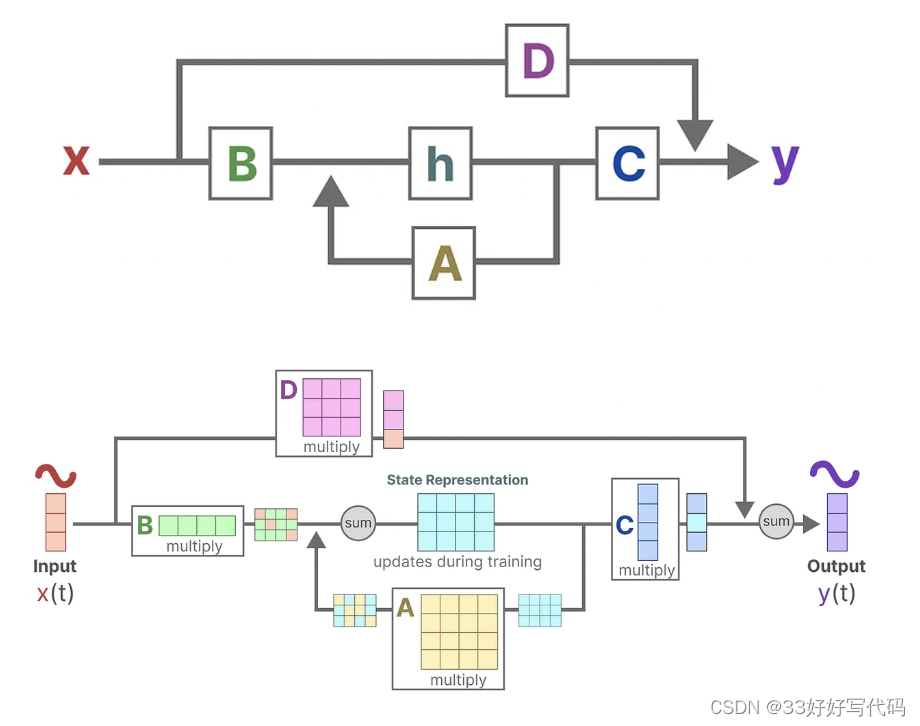 A,B,C——>SSM
A,B,C——>SSM
D——>skip connection(提供从输入到输出的直接信号)
SSM——>连续
连续信号到离散信号
Zero-order hold technique:
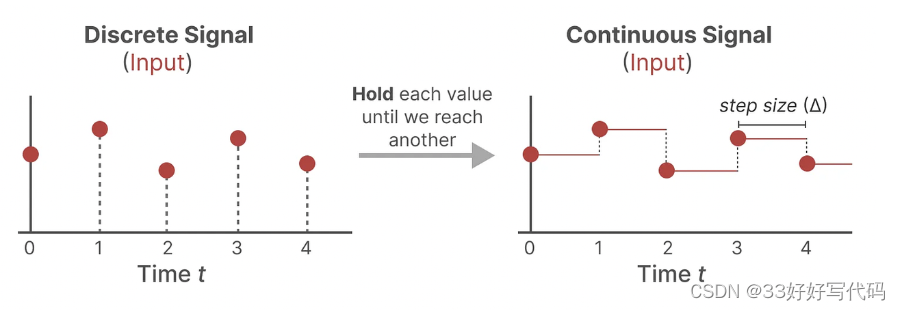
有了连续的输入信号,我们可以生成连续的输出,并且仅根据输入的时间步长对值进行采样,采样值就是我们的离散输出。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2050
2050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









