







构造函数和析构函数
在初始化列表的时候 需要严格按照定义顺序去定义,不然可能会报错
private:
char* _str;
size_t _size;
size_t _capaticy;我们第一个初始化的是_size,此时strlen(str)是有效的,_capacity为_size+1,_str开出的空间为_capaticy+1是因为多了结束字符\0
string(const char *str)
:_size(strlen(str)),
_capaticy(_size)
{
_str=new char[_capaticy+1];
strcpy(_str,str);
}构造函数重载
如果在定义变量的时候,我们没有赋值的情况下,则str是为空的,那么我们需要写一个重载函数。
str为空或者不设置变量的时候,在初始化的时候我们不能将指针指向空,指向空是一个大坑,因为即使是空的时候,我们识别字符串的时候需要指向\0结束,指向空就无法识别出什么时候结束。
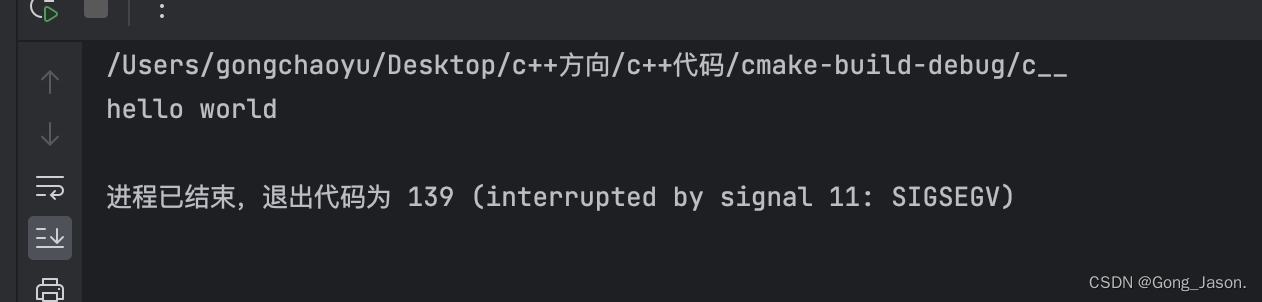
所以在构造函数重载的时候,我们可以直接在后面加上‘\0‘
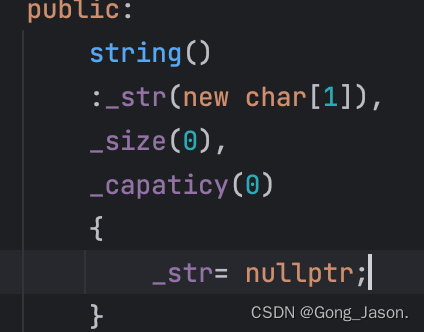
string()
:_str(new char[1]{'\0'}),
_size(0),
_capaticy(0)
{}当然,最便捷的方式是使用全缺省参数, 在初始化的时候另str指针直接指向“”,c语言规定常量字符串会默认生成“\0",如果此时加上\0,就会在多出一个\0,也不需要加空格,加上空格,size就会识别成1
string(const char *str="")
:_size(strlen(str)),
_capaticy(_size)
{
_str=new char[_capaticy+1];
strcpy(_str,str);
}拷贝构造
因为编译器的原因,有的编译器会对内置类型做输出化,有的不会,所以这里我们直接将参数进行初始化后,直接创建一个string类型的tmp 这个tmp取的是s.str的值,此时tmp完成了初始化,再用swap函数调用tmp,swap函数里面因为就近原则会直接调用当前的swap函数,所以要带上std去调用库里的函数
void swap(string& s){
std::swap(_str,s._str);
std::swap(_size,s._size);
std::swap(_capacity,s._capacity);
}
string(const string& s)
:_str(nullptr),
_size(0),
_capacity(0)
{
string tmp(s._str);//调用的是构造函数,char*类型的
swap(tmp);
}赋值=运算符
直接调用拷贝构造,调用完后自动析构函数
string& operator=(string tmp){
swap(tmp);
return *this;
}析构函数
~string() {
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}增删改查
size
size_t size() const {
return _size;
}capacity
size_t capacity() const {
return _capacity;
}_str
const char *c_str() const {
return _str;
}[]操作符
[]操作符分为两个版本,一个是可写的版本,一个是可读的版本,在一开始需要断言出pos位置是否是合法位置,然后返回该值
char& operator[](size_t pos){
assert(pos<_size);
return _str[pos];
}
const char& operator[](size_t pos)const{
assert(pos<_size);
return _str[pos];
}void str_test2(){
string s1="hello world!";
for(size_t i=0;i<s1.size();i++){
cout<<s1[i]<<" ";
}
cout<<endl;
for(size_t i=0;i<s1.size();i++){
s1[i]='a';
cout<<s1[i]<<" ";
}
迭代器
首先先定义一个char*的数据类型iterator,代表迭代器的意思
typedef char* iterator;分别定义成员函数begin和end,其中begin指向str的头地址,str+size正好就是该字符串\0的位置
分别返回地址
iterator begin(){
return _str;
}
iterator end(){
return _str+_size;
}
定义一个指针变量,it指向s1.begin(),就是返回的s1的首地址
string::iterator it=s1.begin();
for(;it<s1.end();it++){
cout<<*it<<" ";
}
cout << endl;
for(auto ch:s1){
cout<<ch<<" ";
}还有一种只读的迭代器,适用于范围for
typedef const char* const_iterator;
const_iterator begin()const{
return _str;
}
const_iterator end()const{
return _str+_size;
}reserve
当n>容量的时候,才会去扩容,否则不会
void reserve(size_t n){
if(n>_capacity){
char* tmp=new char[n+1];
strcpy(tmp,_str);
delete[] _str;
_str=tmp;
_capacity=n;
}
}push_back
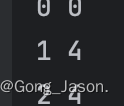
假如size==capacity,那么才会扩容,需要注意的是,如果原本变量指向空,那么capacity等于0,就无法扩容了,所以在一开始便要判断一下变量是否为空,如果为空则在一开始就开四个空间。
void reserve(size_t n){
if(n>_capacity){
char* tmp=new char[n+1];
strcpy(tmp,_str);
delete[] _str;
_str=tmp;
_capacity=n;
}
}
void push_back(char ch){
if(_size==_capacity){
reserve(_capacity==0?4:_capacity*2);
}
_str[_size++]=ch;
_str[_size]='\0';
}
append
append在逻辑上是和push_back相同的,一个是打印的字符,一个是打印的字符串,首先要给出str的长度,这里的if判断中的reserve不能是扩二倍的关系,因为len的长度有可能远远的大于2*capacity,假如len的长度是10,而capacity的长度是3,capacity即使扩了二倍也无法满足所需要的。
void append(const char* str){
size_t len=strlen(str);
if(len+_size>_capacity){
reserve((_size+len));
}
strcpy(_str+_size,str);
_size+=len;
} 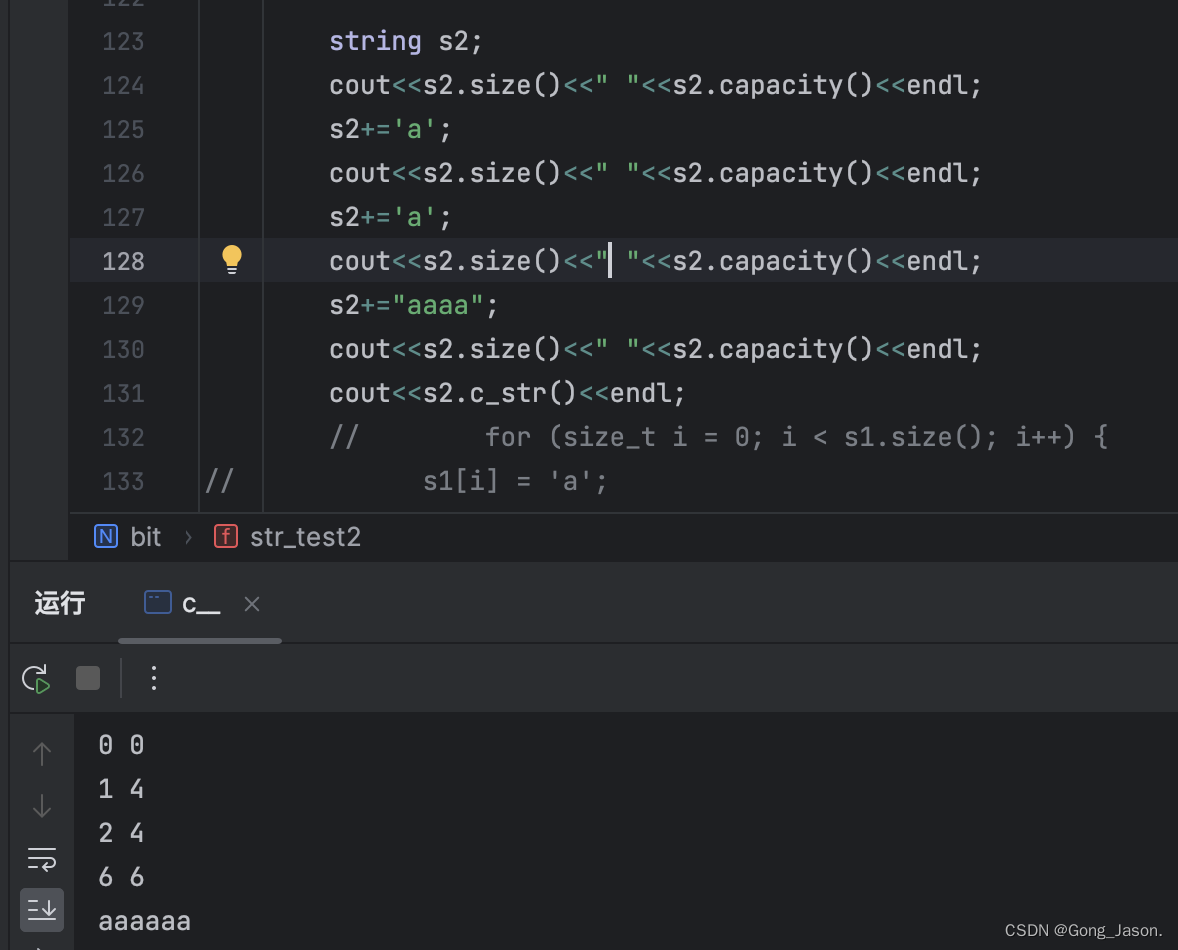
+=运算符
+=运算符在原理上是和push_back和append是一样的,只是返回的是this指针
string& operator+=(char ch){
push_back(ch);
return *this;
}
string& operator+=(const char* str){
append(str);
return *this;
}insert
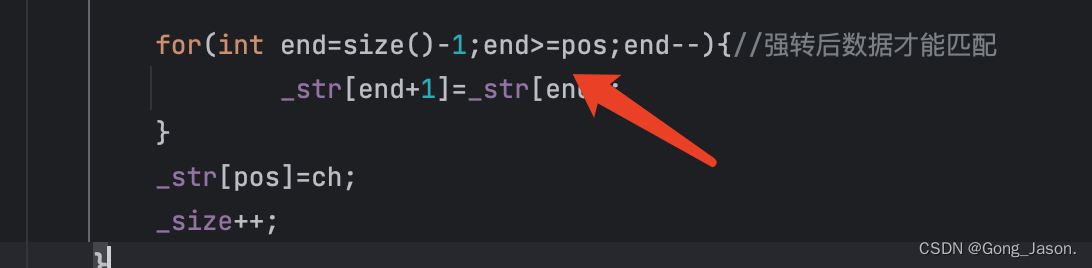
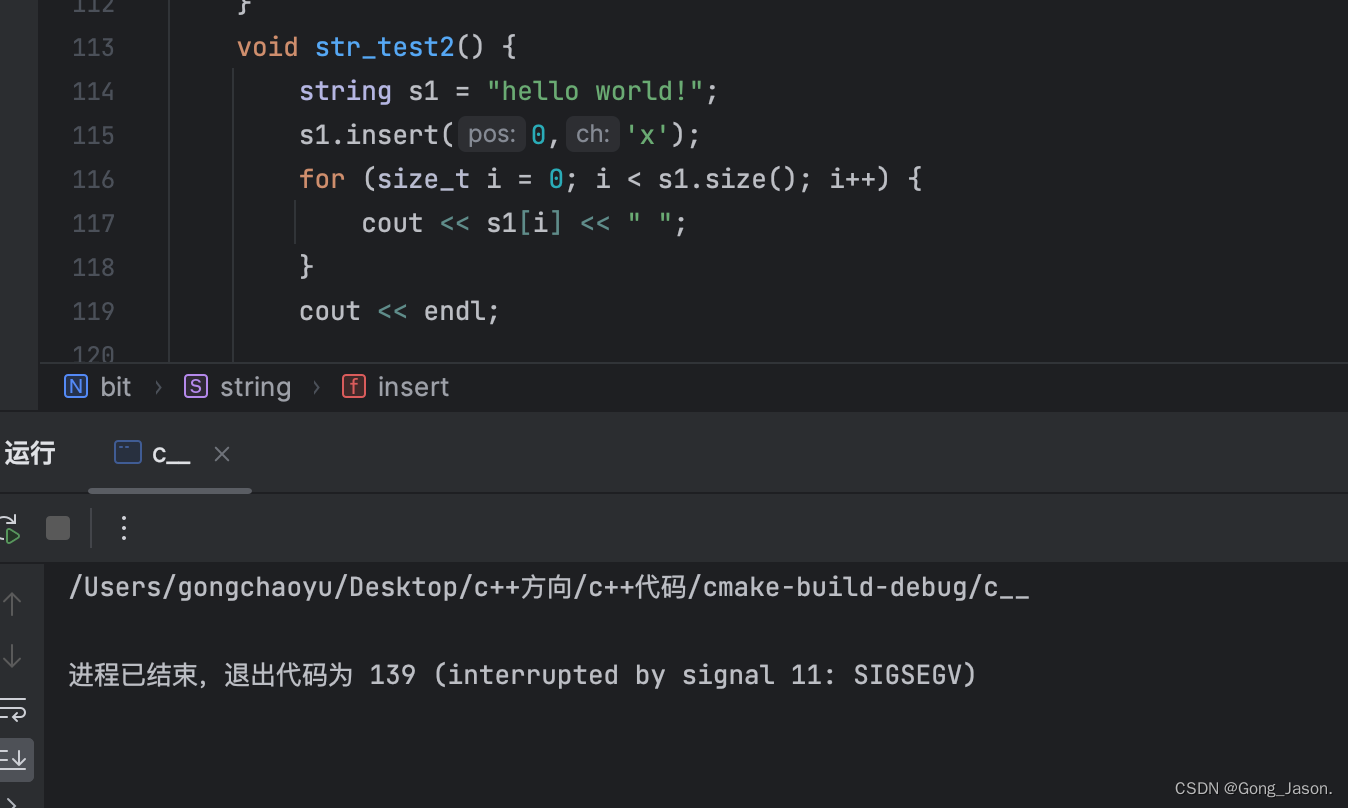
inserts是插入一个字符,在这里我们需要注意的是pos在stl库中是size_t类型的,假设我们插入的位置是第一个位置,所以在for循环中,当end等于-1的时候是无法和pos进行比较的,就会出现程序的报错,所以在for循环中给pos强转成和end一样的数据类型
错误示范:
正确示范:
void insert(size_t pos,char ch){
assert(pos<=_size);
if(_size==_capacity){
reserve(_size==0?4:2*_capacity);
}
for(int end=size();end>=(int)pos;end--){//强转后数据才能匹配
_str[end+1]=_str[end];
}
_str[pos]=ch;
_size++;
} 
在插入一段字符串的时候一样需要强转
void insert(size_t pos,const char* str){
assert(pos<=_size);
int len=strlen(str);
if(_size+len>_capacity){
reserve(_size+len);
}
for(int end=size();end>=(int)pos;end--){
_str[end+len]=_str[end];
}
int a=0;
for(int i=pos;i<pos+len;i++){
_str[i]=str[a++];
}
// strncpy(_str+len,str,len);
_size+=len;//更新size的记录
}erase
从pos位置开始删除len个数据,这边len填了个缺省参数,如果len等于npos的话就一直从pos删到结尾
void erase(size_t pos,size_t len=npos){
assert(pos<_size);
if(len+pos>=_size||len==npos){
_str[pos]='\0';
_size=pos;
}else{
for(int begin=pos+len;begin<=_size;begin++){
_str[begin-len]=_str[begin];
}
_size-=len;
}
}resize
resize就是保留size的尺寸,当n<size的时候,n的位置放上\0就代表了最后结束
反之大于则扩容,从size位置一直+到n位置的\0,判断的时候只需要遇到第一个\0就结束
void resize(size_t n,char ch='\0'){
if(n<=_size){
_str[n]='\0';
_size=n;
}else{
reserve(n);
for(int begin=_size;begin<n;begin++){
_str[begin]=ch;
}
_str[n]='\0';
_size=n;
}
}find
在这里我们pos位置填个缺省参数,判断从哪个位置开始找,存在从非第一个字符开始寻找目标ch的可能
size_t find(char ch,size_t pos=0){//
for(size_t i=pos;i<_size;i++){
if(_str[pos]==ch)return i;
}
return npos;
}使用一个strstr接口去找字串,相同则返回给p,如果p存在则返回p的首地址到str的首地址的长度,没有则npos
size_t find(const char* sub,size_t pos=0){
const char* p=strstr(_str+pos,sub);
if(p){
return p-_str;
}
else return npos;
}substr
const static size_t npos=-1; string substr(size_t pos,size_t len=npos){
string s;
size_t end=pos+len;
if(len==npos||pos+len>=_size){
len=_size-len;
end=_size;
}
s.reserve(len);
for(size_t i=pos;i<end;i++){
s+=_str[i];
}
return s;
}比较运算符
只需要比较<和==其他的都能套用
bool operator<(const string& s)const{
return strcmp(_str,s._str)<0;
}
bool operator==(const string& s)const{
return strcmp(_str,s._str)==0;
}
bool operator<=(const string& s)const{
return (*this<s)||(*this==s);
}
bool operator>(const string& s)const{
return !(*this<=s);
}
bool operator>=(const string& s)const{
return !(*this<s);
}
bool operator!=(const string& s)const{
return !(*this==s);
}clear
在重新写入的时候一般需要清除一下所有的元素
void clear(){
_str[0]='\0';
_size=0;
}














 1652
1652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









