








车间调度系列文章:
-
17、柔性车间调度丨改进人工蜂群算法
引言
调度问题定义:在一定的约束条件下,把有限的资源在时间上分配给若干个任务,以满足或优化一个或多个性能指标。柔性车间问题的特点就是:每个工序有多机床可选。因此,要想在短时间内更好的分配资源,是很困难的,需要借助计算机来帮我们运算得出答案。
问题和模型
柔性车间调度问题和模型见参考论文截图:

代码实现过程
- 1、机器串生成规则 GS /LS /RS
以前复现过相关作者的论文,可以看前面的推文,代码在fjsp里,函数是creat_Machine,GS是工序优先选择全局负荷最小的机器,
LS是机器是优先选择局部负荷最小的机器,RS是工序随机选择加工机器
核心代码:
for j in range(self.machines[i]):
highs=self.tom[i][j]
lows=self.tom[i][j]-self.tdx[i][j]
n_machine=self.Tmachine[i,lows:highs].tolist()
n_time=self.Tmachinetime[i,lows:highs].tolist()
index_select=[]
if r<self.p1 or r>1-self.p2:
for k in range(len(n_machine)):
m=int(n_machine[k])-1
index_select.append(m)
t=n_time[k]
a_global[0,m]+=t #全局负荷计算
a_part[0,m]+=t #局部负荷计算
if r<self.p1: #全局选择
select=a_global[:,index_select]
idx_select=np.argmin(select[0])
else: #局部选择
select=a_part[:,index_select]
idx_select=np.argmin(select[0])
m_select=n_machine[idx_select]
t_index=n_machine.index(m_select)
machine.append(m_select)
machine_time.append(n_time[t_index])
time+=n_time[t_index]
else: #否则随机挑选机器
index=np.random.randint(0,len(n_time),1)
machine.append(n_machine[index[0]])
machine_time.append(n_time[index[0]])
time+=n_time[index[0]]
- 2、工序串的生成规则 MRL /SPT /RS
MRL把各个工件的剩余加工时间统计排序,优先加工剩余加工时间最长的工件; SPT优先处理剩余加工时间短的工件; RS把各个工序
进行随机排序选择。
核心是记录每个工件的剩余加工时间,每次机器安排工件的工序进行生产后,更新剩余时间。
核心代码:
for i in range(len(self.work)):
r=np.random.rand()
a=np.argwhere(time_last>0) #挑选剩余工件加工时间大于0的索引
if r<self.p3+self.p4: #剩余负荷最大规则和加工时间最短优先规则
b=time_last[a].reshape(a.shape[0],).tolist() #按照索引取出具体工件的加工时间
if r<self.p3: #剩余负荷最大规则
a_index=b.index(max(b))
jobb=int(a[a_index,0])
job.append(jobb)
else: #加工时间最短优先规则
a_index=b.index(min(b))
jobb=int(a[a_index,0])
job.append(jobb)
else: #随机选择规则
index=np.random.randint(0,a.shape[0],1)
jobb=int(a[index,0])
job.append(jobb)
loc=count[0,jobb]
loc1=rember[jobb]+loc
time=machine_time[loc1]
time_last[jobb]-=time #更新剩余工件加工时间
- 3、雇佣蜂IPOX交叉
主要是POX交叉,论文改进的方向:概率小于0.5时选择最优的个体进行交叉,概率大于0.5时随机选择不相同的个体进行交叉,子代优于父代时更新。具体的概念可以看参考论文,自行百度或者看前面推文。
IPOX交叉核心代码:
best_index=answer.index(min(answer)) #最优个体的索引
for i in range(len(answer)):
W1,M1,T1=work_job[i:i+1],work_M[i:i+1],work_T[i:i+1]
if np.random.rand()<0.5: #另一个工序串是全局最优
index=best_index
else: #另一个工序串是随机选择且与原工序串不同
a=np.arange(i)
b=np.arange(i+1,len(answer),1)
c=np.hstack((a,b))
index=np.random.choice(c,1)
W2,M2,T2=work_job[index:index+1],work_M[index:index+1],work_T[index:index+1]
W1,W2=self.job_IPOX(W1,W2) #工序交叉
C_finish,,_,_,_,_=self.to.caculate(W1,M1,T1)
if C_finish<answer[i]: #完工时间比父代短就替换
work_job[i]=W1
answer[i]=C_finish
ipox交叉代码:
def IPOX(self,chrom_L1,chrom_L2): #工序的ipox交叉
num=list(set(chrom_L1))
np.random.shuffle(num)
index=np.random.randint(0,len(num),1)[0]
jpb_set1=num[:index+1] #固定不变的工件
jpb_set2=num[index+1:] #按顺序读取的工件
C1,C2=np.zeros((1,chrom_L1.shape[0]))-1,np.zeros((1,chrom_L1.shape[0]))-1
sig,svg=[],[]
for i in range(chrom_L1.shape[0]):#固定位置的工序不变
ii,iii=0,0
for j in range(len(jpb_set1)):
if(chrom_L1[i]==jpb_set1[j]):
C1[0,i]=chrom_L1[i]
else:
ii+=1
if(chrom_L2[i]==jpb_set1[j]):
C2[0,i]=chrom_L2[i]
else:
iii+=1
if(ii==len(jpb_set1)):
sig.append(chrom_L1[i])
if(iii==len(jpb_set1)):
svg.append(chrom_L2[i])
signal1,signal2=0,0 #为-1的地方按顺序添加工序编码
for i in range(chrom_L1.shape[0]):
if(C1[0,i]==-1):
C1[0,i]=svg[signal1]
signal1+=1
if(C2[0,i]==-1):
C2[0,i]=sig[signal2]
signal2+=1
return C1[0],C2[0]
- 4、雇佣蜂多点交叉
和遗传算法的均匀交叉一个意思,具体的概念可以看参考论文,自行百度或者看前面推文。
选择两个相邻的个体交叉:
for i in range(0,self.popsize,2): #种群规模下每次选2个个体
W1,M1,T1=work_job[i:i+1],work_M[i:i+1],work_T[i:i+1]
W2,M2,T2=work_job[i+1:i+2],work_M[li+1:i+2],work_T[li+1:i+2]
M1,T1,M2,T2=self.ma_cross(M1,T1,M2,T2) #机器交叉
C_finish,_,_,_,_=self.to.caculate(W1,M1,T1)
if C_finish<answer[i]: #完工时间比父代短就替换
work_M[i]=M1
work_T[i]=T1
answer[i]=C_finish
C_finish,_,_,_,_=self.to.caculate(W2,M2,T2)
if C_finish<answer[i]: #完工时间比父代短就替换
work_M[i+1]=M1
work_T[i+1]=T1
answer[i+1]=C_finish
多点交叉:
def ma_cross(self,m1,t1,m2,t2): #机器多点交叉
MC1,MC2,TC1,TC2=[],[],[],[]
for i in range(m1.shape[0]):
index=np.random.randint(0,2,1)[0]
if(index==0): #为0时继承父代的机器选择
MC1.append(m1[i]),MC2.append(m2[i]),TC1.append(t1[i]),TC2.append(t2[i]);
else: #为1时继承另一个父代的加工机器选择
MC2.append(m1[i]),MC1.append(m2[i]),TC2.append(t1[i]),TC1.append(t2[i]);
return MC1,TC1,MC2,TC2
5、观察蜂轮盘赌选择
按照论文的适应度值计算方式,用python的np.random.choice进行轮盘赌选择
代码:
def select(self,work_job,work_M,work_T,answer): #轮盘赌选择
fit=1/(1+np.array(answer)) #适应度值计算
idx=np.random.choice(np.arange(len(answer)),size=len(answer),replace=True,
p=fit/fit.sum()) #replace=True表示可以选择重复的值
return work_job[idx],work_M[idx],popp[idx]
论文每次子代优于父代就更新,种群数量不变,轮盘赌选择在原种群相同数量的种群出来,有可能会把最优个体丢失,暂时先不用,
代码是屏蔽了,也可以不屏蔽。
- 6、观察蜂变换步长策略
大步长是交换可行解中多对工序的顺序,可以用遗传算法的逆序变异,其是选择编码的一部分颠倒顺序,其余不变。
而小步长交换可行解中一对工序的顺序,和论文的工序串进行插入变异差不多一样,核心是交换两个位置的编码,小步长和插入变异就
算一个。
大步长策略代码:
def Job_vara(self,W1,W2): #工序的逆序变异(大步长)
index1=random.sample(W1.shape[0],2)
index1.sort()
L1=W1[:,index1[0]:index1[1]+1]
W_all=np.zeros((1,W1.shape[1]))
W_all[0]=W1[0]
for i in range(L1.shape[1]):
W_all[0,index1[0]+i]=L1[0,L1.shape[1]-1-i] #反向读取工序编码
return W_all[0]]
小步长策略代码:
def mutation_(self,W): #两点交叉(小步长)
location=random.sample(range(W.shape[0]),2)
W[i,location[0]],W[i,location[1]]=W[i,location[1]],W[i,location[0]]
return W
- 7、观察蜂机器串进行变异操作
插入变异和小步长算一个,机器串的变异操作是一道工序随机选择加工机器。
代码:
def ma_mul(self,W,M,T):
index=np.random.randint(W.shape[0])[0]
for i in range(len(self.machines)):
for j in range(self.machines[i]):
if sig == mul[signal] : #读取工序的可加工机器和工序
highs=self.tom[sig][count[0,sig]]
lows=self.tom[sig][count[0,sig]]-self.tdx[sig][count[0,sig]]
n_machine=self.Tmachine[sig,lows:highs].tolist()
n_time=self.Tmachinetime[sig,lows:highs].tolist()
ndex=np.random.randint(0,len(n_time),1) #随机选择加工机器
machine.append()
machine_time.append(n_time[index[0]])
M[sig]=n_machine[index[0]] #更新编码
Tt[sig]=n_time[index[0]]
break
sig+=1
return M,T
- 8、侦查蜂操作
文章是在一定搜索次数后,如果蜜源的适应度值没有改进,雇佣蜂转换为侦查蜂,随机产生一个新的。和变换步长策略策略一起考虑,文章变换步长的搜索阈值是5,搜索次数是20。
考虑计算量大,改进搜索限制:不管搜索了多少次,如果完工时间得到改进,结束搜索并更新,也可以不改进,代码改正较容易。
代码:
def search(self,W,M,T): #侦查蜂操作
answer,_,_,_,_=self.to.caculate(W,M,T)
for i in range(self.limit): #搜索次数
if i <self.threshold: #阈值
W=self.Job_vara(W)
else:
W=self.mutation_W(W)
M,T=self.ma_mul(W,M,T)
C_finish,_,_,_,_=self.to.caculate(W,M,T)
if C_finish<answer:
break
if i==self.limit-1: #如果大于20次,按上面的方法生成一个新的
W,M,T=self.to.creat_job()
C_finish,_,_,_,_=self.to.caculate(W,M,T)
return W,M,T,C_finish
考虑到如果一个较优秀的解可能经过20次搜索,无法优化,而采用上面的方法可能生成一个新的解取代他,所以设计每次不搜索最优的个体。
核心代码:
best_index=answer.index(min(answer)) #最优个体的索引
for i in range(len(answer)):
if i !=best_index:
W1,M1,T1=work_job[i],work_M[i],work_T[i]
W1,M1,T1,C_finish=self.search(W1,M1,T1) #变换步长策略搜索
work_job[i]=W1
work_M[i]=M1
work_T[i]=T1
answer[i]=C_finish
注意:2,3在fjsp.py里,4,5,6,7,8在GABC.py里。
- 9、结果
主函数main.py:
import numpy as np
from data_solve import data_deal
from fjsp import FJSP
from GABC import abc
da=data_deal(10,6) #工件数,机器数
Tmachine,Tmachinetime,tdx,work,tom,machines=da.cacu() #mko1数据
parm_data=[Tmachine,Tmachinetime,tdx,work,tom,machines]
P_GLR=[0.3,0.3] #机器串生成规则 GS /LS /RS,依次是0.3,0.3,最后是1-0.3-0.3
P_MSR=[0.3,0.3] #工序串的生成规则 MRL /SPT /RS,依次是0.3,0.3,最后是1-0.3-0.3
fj=FJSP(10,6,P_GLR,parm_data,P_MSR) #前面两个数是工件数,机器数
parm_mo=[100,200,20,5] #依次是迭代次数,种群规模,搜索次数,阈值
ho=abc(10,fj,parm_mo,parm_data)
w,m,t,result=ho.gabc()
C_finish,_,_,_,_=fj.caculate(w,m,t)
fj.draw(w,m,t) #画甘特图
fj.draw_change(result) #画完工时间图
结果见图1:

甘特图见图2:
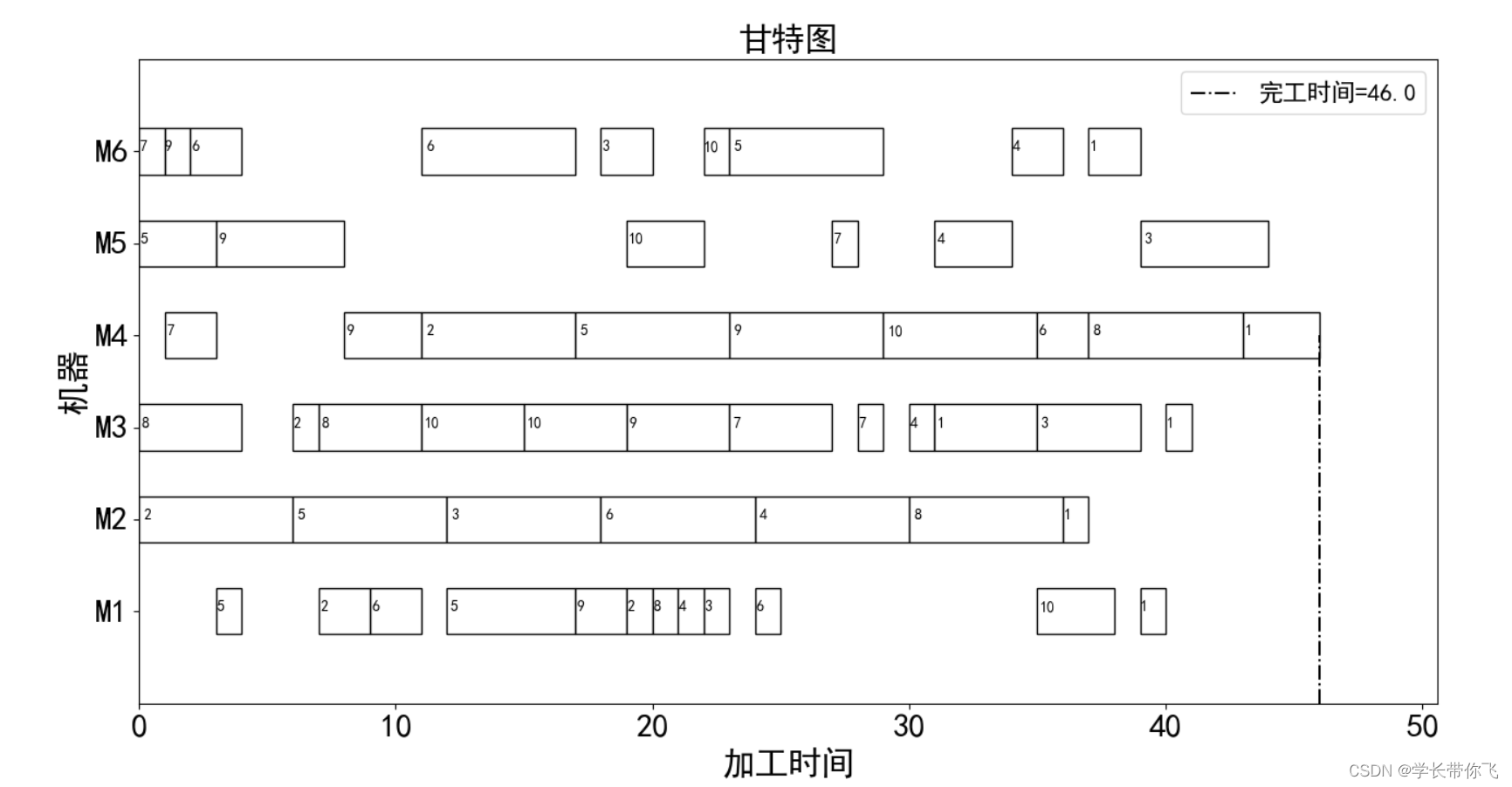
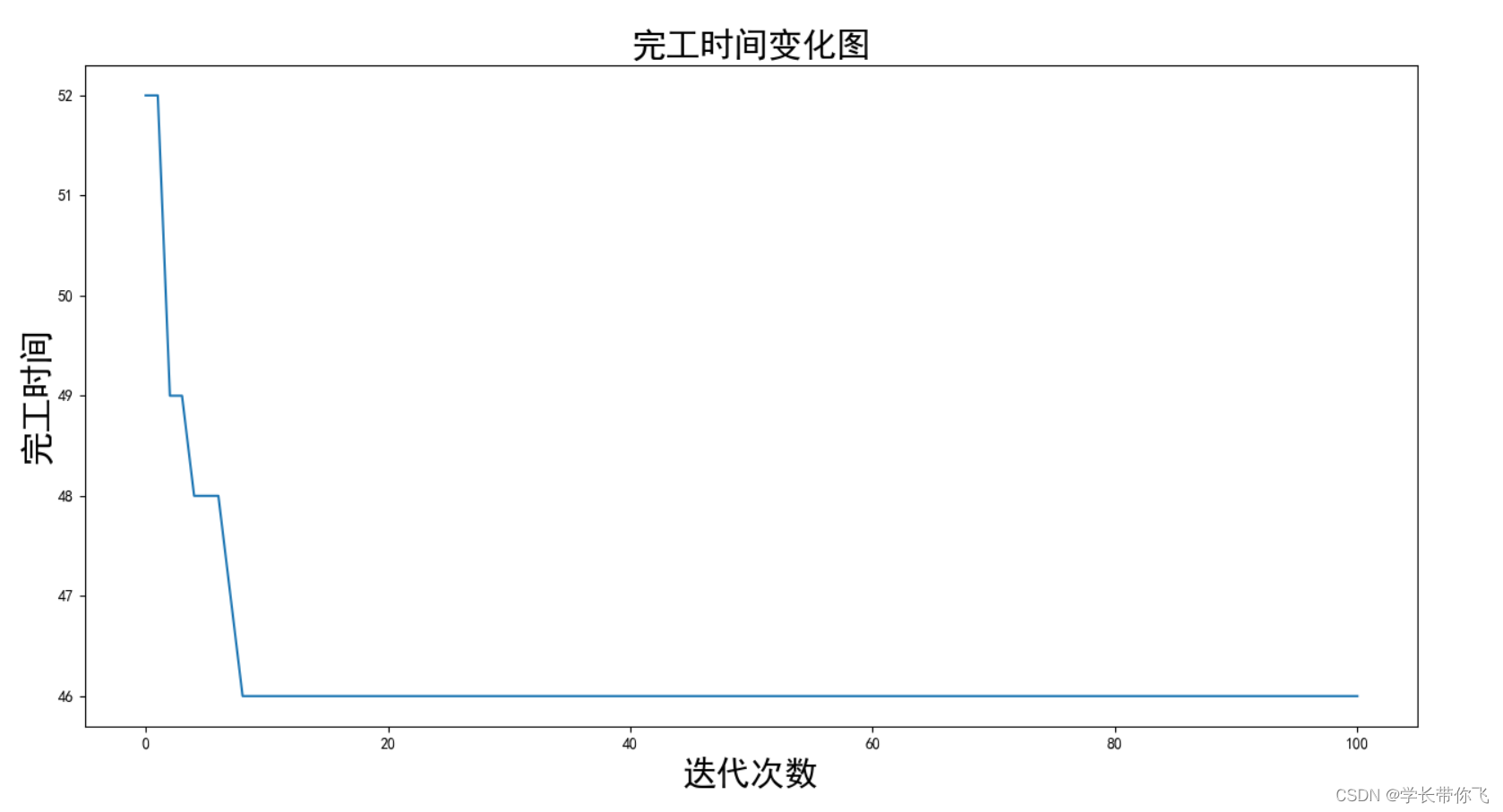
完工时间图见图3:
小结
- 代码运行时间不短,可能是计算量大,因为每次迭代都对种群个体进行多次搜索。
- 但基本复现了论文,用的是mk01数据,优化效果还行,感兴趣可以用其他数据试试,excel直接修改就行。
参考文献
- [1]王玉芳,马铭阳,葛嘉荣,缪昇.基于改进人工蜂群算法的柔性作业车间调度[J].组合机床与自动化加工技术,
2021(03):159-163+168.DOI:10.13462/j.cnki.mmtamt.2021.03.038.
演示:
论文复现丨基于改进人工蜂群算法的柔性作业车间调度
完整算法源码+数据:见下方微信公众号:关注后回复:车间调度
# 微信公众号:学长带你飞
# 主要更新方向:1、车辆路径和柔性车间调度问题求解算法
# 2、学术写作技巧
# 3、读书感悟
# @Author : Jack Hao
公众号二维码:
















 3047
3047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









