






用官方的话来说scrapy框架到目前为止依然是最受欢迎的爬虫框架之一,学习爬虫肯定绕不开scrapy框架的学习。在这里记录一下学习scrapy的过程。
下载scrapy:pip install scrapy
使用:
一、构建项目:
1.创建项目:
scrapy startproject 项目名 这样就创建了一个爬虫项目了在这个项目里面除了有项目外还有一个scrapy.cfg,这是项目的配置文件。不要动
而在项目中会有一个spider文件夹和几个python文件,我们的爬虫逻辑代码一般都在spider中写,但是那几个python文件也是有大用处的
_init_.py: 这是爬虫初始化的文件
items.py:这是在进行数据封装的时候用到的文件
middlewares.py: 中间件,可以用来添加代理,useragent等。
pipelines.py : 管道,主要进行数据保存。
setting.py : 设置,限制日志信息,启动管道等都要在里面设置

2.创建爬虫文件
首先我们要先进入爬虫项目中 :cd 项目名,然后创建爬虫
scrapy genspider my_scrapy(爬虫名) baidu.com(域名)
这时我的spiders文件夹中就多了一个爬虫文件了

在这个爬虫文件中 alowed_domains是爬虫能够爬取的域名,start_urls是爬虫的起始url,可以是多个。在parse中就是我们写爬虫代码的地方了。
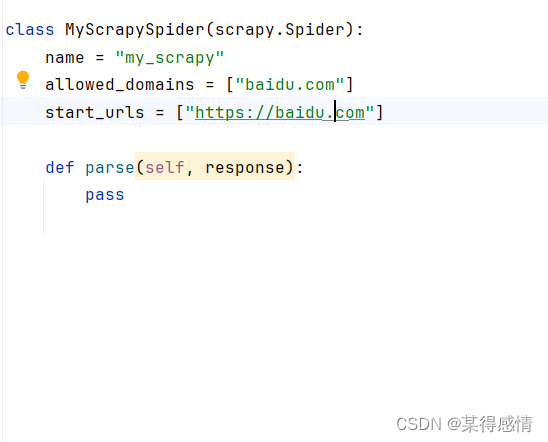
简单的写一个运行一下:
import scrapy
class MyScrapySpider(scrapy.Spider):
name = "my_scrapy"
allowed_domains = ["4399.com"] # 允许访问的域名,可多个
start_urls = ["https://www.4399.com/flash/gamehw.htm"] # 起始url地址,可多个
def parse(self, response):
text = response.text
print(text)
3.运行爬虫文件:
scrapy crawl my_spider(爬虫名)
这时结果会出现很多无关紧要的日志信息,
可以进入setting.py中添加限制日志信息
LOG_LEVEL = "WARNING" 这样日志信息只有"WARNING"以上级别的才会显示了。
日志信息的级别是debug < info < warning < error < critical
二、初识管道
管道的主要作用是进行数据的存储,可以存成文件,也可以存到数据库中。
简单些一个和管道有关的爬虫。
def parse(self, response):#parse是用来处理、解析的
li_list = response.xpath('//ul[@class="tm_list"]/li')
#print(li_list)
id = 0
for li in li_list:
id = id+1
name = li.xpath('./a/b/text()').extract_first()
#默认xpath返回的是selector对象,需要加上extract()空则报错或者extract_first()空返回null
#extract()可以得到多个,extract_first()只能得到第一个
time = li.xpath('./em/text()').extract_first()
category = li.xpath('./em/a/text()').extract_first()
#print(name, category, time)
dic = {
"id":id,
"name":name,
"category":category,
"time":time
}
#print(dic)
#break
yield dic在管道中的代码如下:
class GamePipeline:#定义一个类
#名字不能
def process_item(self, item, spider):#item中是数据,spider是爬虫
print(item)
return item#传送到下一个管道这个爬虫在parse中对数据进行提取,并以字典的形式通过yield传给管道,item就是管道接收的数据,管道接收到数据后输入数据,然后return数据,而且是必须return,因为下一个管道要用。
这里有一个小坑,管道写完后需要去setting中打开管道
ITEM_PIPELINES = {
"new.pipelines.NewPipeline": 300,
}
前面是管道地址,后面是优先级,数越小,优先级越高。
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









