




 本文探讨了语义分割任务中的数据增强方法,包括全监督、自监督和半监督学习。重点介绍了Mixup、Cutout和CutMix技术,以及针对半监督场景的ClassMix方法,它解决了CutMix的标签污染问题,并利用伪标签优化了模型训练。此外,ClassMix结合Mean-Teacher框架,提升了半监督学习的性能。
本文探讨了语义分割任务中的数据增强方法,包括全监督、自监督和半监督学习。重点介绍了Mixup、Cutout和CutMix技术,以及针对半监督场景的ClassMix方法,它解决了CutMix的标签污染问题,并利用伪标签优化了模型训练。此外,ClassMix结合Mean-Teacher框架,提升了半监督学习的性能。
半监督语义分割笔记(1)-数据增强方法
本文为笔者在半监督语义分割方面的数据增强方法笔记,若有错误,欢迎批评指正。
1. 语义分割
语义分割是计算机视觉领域的一项任务,旨在将图像中的每个像素标记为特定的语义类别。与普通的图像分类任务不同,语义分割不仅要识别整个图像的类别,还要对图像中的每个像素进行分类。
在语义分割中,图像被划分为许多像素级别的区域,每个区域被赋予一个特定的类别标签。常见的类别包括人、车、建筑物、道路等。语义分割的目标是为图像中的每个像素分配正确的类别标签,从而实现对图像的详细解析。
通俗地来讲,所谓的语义分割就是既要将整个图像就行分类,还要将图像中的内容进行分类识别。
2. 监督学习
详见参考链接:一文看懂半监督学习
2.1 全监督
全监督学习是指在训练过程中使用完全标记好的数据集。对于语义分割任务来说,全监督学习即使用像素级别的标签进行训练,每个像素都有准确的类别标签。全监督学习通常需要大量标记好的数据,且标注工作量较大。
2.2 自监督
自监督学习是一种从无标签数据中学习的方法,它通过设计任务来创建人工标签。对于语义分割任务,自监督学习可以通过将图像进行数据增强或图像变换,并设计自监督任务来生成伪标签。例如,将图像旋转一定角度后,利用旋转前后的图像来生成像素级别的伪标签。
2.3 半监督
半监督学习是介于全监督学习和无监督学习之间的一种方法。它利用部分标记的数据和未标记的数据进行训练。对于语义分割任务来说,半监督学习可以使用部分像素级别标记的数据和未标记的数据来训练模型。半监督学习的目标是通过利用未标记的数据来提高模型的性能。
3. 数据增强方法
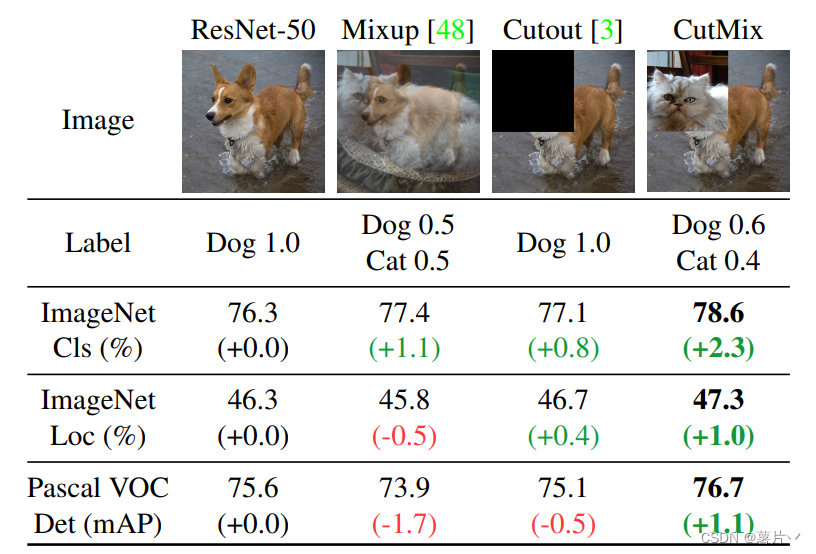
3.1 Mixup
将两张图片和其标签,按权重进行叠加,生成新的数据集和其所对应的标签。
参考资料:http://t.csdn.cn/Yk7kP
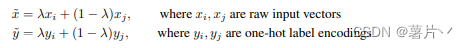
Mixup的步骤如下:
- 从训练数据中随机选择两个样本,记作样本A和样本B。
- 随机选择一个介于0和1之间的权重值λ。
- 将样本A和样本B的特征按照权重值λ进行线性组合:mixed_feature = λ * feature_A + (1 - λ) * feature_B。
- 将样本A和样本B的标签按照权重值λ进行线性组合:mixed_label = λ * label_A + (1 - λ) * label_B。
- 使用mixed_feature作为新的训练样本,使用mixed_label作为对应的标签。
3.1.1 λ的选择:使用beta分布
beta分布有两个参数α和β,通过调正α和β的值,可以调整λ的分布概率,当α = β = 1时,等于(0,1)均匀分布;当α = β < 1时,表现为两头的概率大,中间的概率小,当α = β → 0时,相当于{0,1}二项分布,要么取0,要么取1,等于原始数据没有增强,也就是论文中所说的经验风险最小化ERM;当α = β > 1时,表现为两头概率小,中间概率大,类似正态分布,当α = β → ∞时,概率恒等于0.5,相当于两个样本各取一半。所以使用Beta分布相当灵活,只需要调整参数α , β的值,就可以得到多样化的[0,1]区间内的概率分布,使用非常方便。
3.1.2 λ的选择:使用凸组合
凸组合是指线性组合中各项系数之和为1,也可以对Mixup中的λ进行分配。
3.2 Cutout
随机的将样本中的部分区域cut掉,并且填充0像素值,分类的结果不变
Cutout的步骤如下:
- 选择一个固定大小的遮挡框或者随机生成一个遮挡框的大小。
- 在图像中随机选择一个位置,并将遮挡框放置在该位置。
- 在遮挡框中将像素值设置为固定的值,例如零或者随机噪声。
- 得到带有遮挡的图像作为新的训练样本。
3.3 CutMix
相当于综合了Mixup和Cutout的想法,把一张图片上的某个随机矩形区域剪裁到另一张图片上生成新图片。
标签的处理和mixUp是一样的,都是按照新样本中两个原样本的比例确定新的混合标签的比例。
参考资料:http://t.csdn.cn/kggQs

步骤:
- 设定lamda的值,服从beta分布
- 找到两个随机样本
- 生成剪裁区域B
- 将原有的样本A中的B区域,替换成样本B中的B区域
- 根据剪裁区域坐标框的值调整lam的值
- 将生成的新的训练样本丢到模型中进行训练
- 按lamda值分配权重
CutMix 有两个优点
- 充分利用了训练数据,而不是像 Cutout 那样丢弃部分区域
- 在图片上采用硬融合,避免了 Mixup 模型定位能力差的问题
Cutmix Semiseg:(Cutmix半监督语义分割)
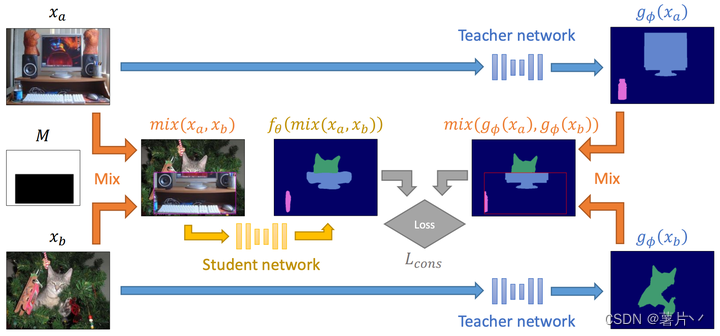
3.3.1 CutMix存在的问题——标签污染和小目标检测
一、标签污染

如图所示,
左图:True标签;红色是1级,蓝色是2级。
中间:网络预测;网络在类1和类2之间不确定的区域有红色和蓝色的混合。决策边界用白线标记。
右图:红色类被粘贴在新图像的顶部,新图像完全由第三个类组成。
注意,粘贴的类仍然给新图像带来了类2(蓝色)的一些不确定性。
这将导致训练中的人工标签出现问题,因为所粘贴对象周围的上下文现在更改为类3。
二、小目标检测
CutMix算法将两张图片混合的方式是随机的,如果是针对小目标检测对于网络本身可能没有好处。
对于小目标检测任务,可能存在以下问题:
- 目标遮挡:当一个小目标被裁剪并粘贴到另一个图像中时,由于目标的尺寸较小,可能会被其他区域遮挡,导致目标信息的缺失或混淆。
- 目标定位:小目标的位置信息对于检测任务尤为关键。随机裁剪和粘贴可能会导致目标的位置发生变化,使网络难以准确地定位小目标。
这些问题可能会对小目标检测任务的性能产生负面影响。因此,对于小目标检测任务,使用随机混合方式(如CutMix)可能没有明显的好处,甚至可能降低网络的性能。
3.4 ClassMix
介绍了上面三种数据增强方法后,这里介绍一个Classmix数据增强方法。
ClassMix主要是集合了伪标签和一致性正则化。思想来源于CutMix那条研究路线,但是优化了CutMix中的标签污染的情况。另外,Classmix继续在半监督分割的设定下,优化了 CutMix Semi-Seg 中的蒙版 M,从矩形框抠图升级至像素级抠图
参考:ClassMix: Segmentation-Based Data Augmentation for Semi-Supervised Learning学习笔记
参考:ClassMix:基于分割的数据增强的半监督学习
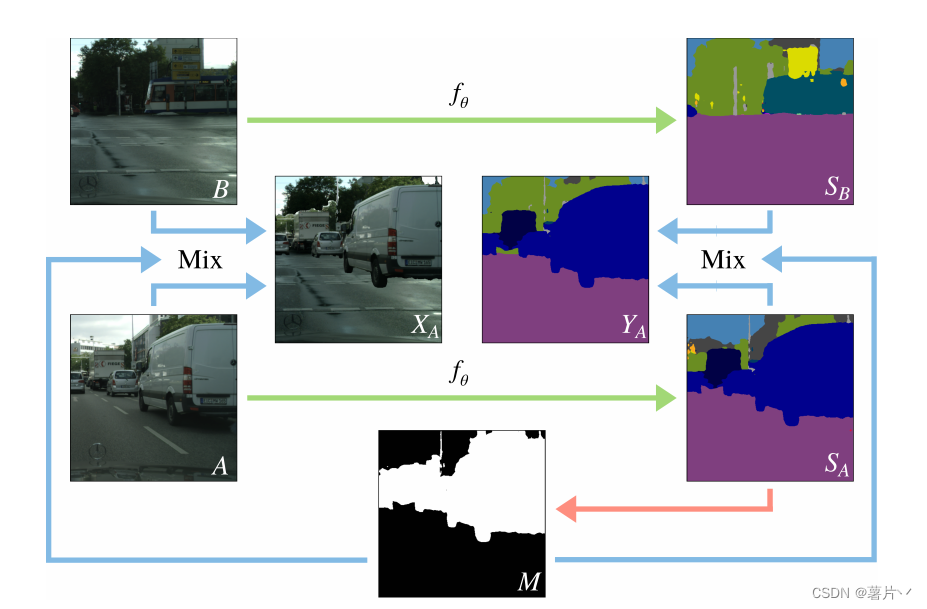
伪代码:

由于Classmix的原始论文中,使用到了Mean-Teacher,需要理解Mean-Teacher的概念。
详见:半监督方法:Π模型,Temporal Ensembling,Mean-Teacher
Classmix:通过在考虑对象边界的同时利用网络预测,通过混合未标记样本来扩充训练样本
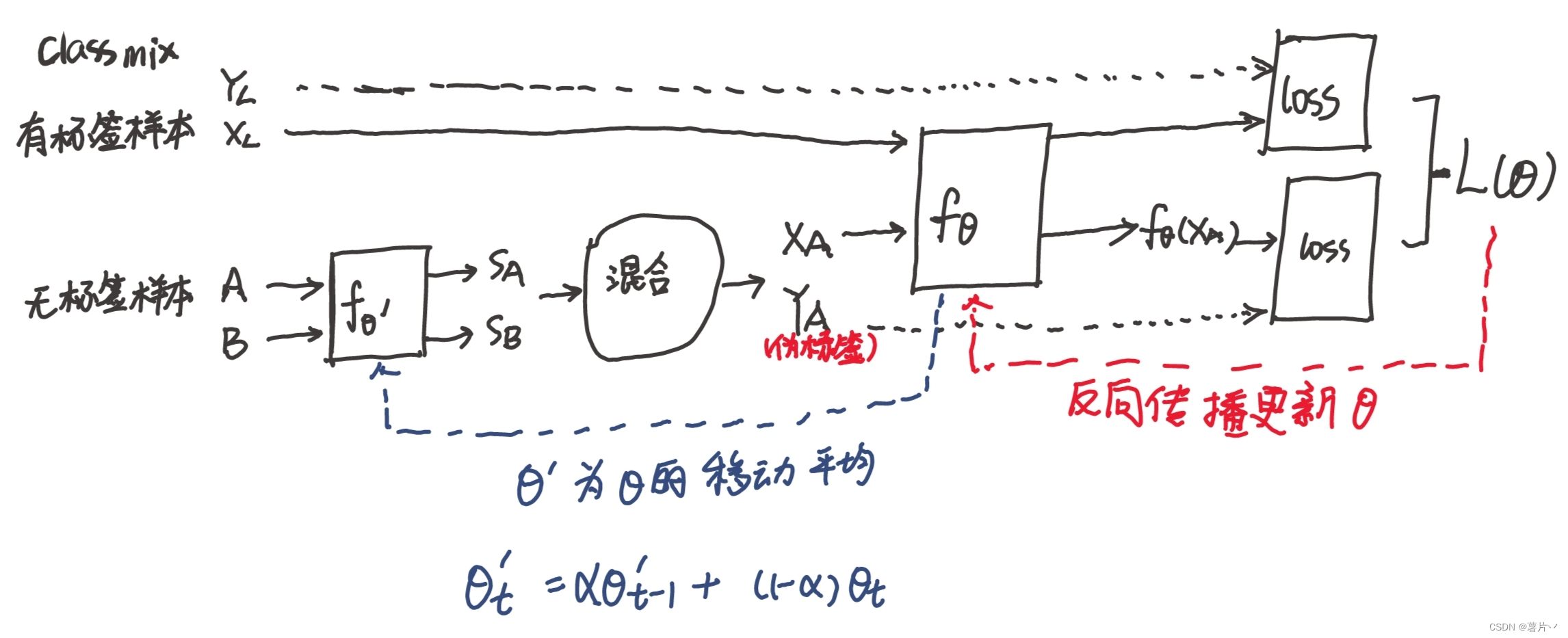
两个未标记的图像 A 和 B,从数据集中采样。
通过分割网络 f (θ), 而输出预测 SA 和 SB, 二进制 Mask M 是随机选择 SA 一半的类别的 argmax 预测,将这些类中的像素设置为值 1,而其他的值都是 0。
然后使用这个 Mask 将图像 A 和 B 混合为增强图像 XA 中,对 SA,SB 的预测也进行了同样的混合,生成人造标签 YA。
但是,在原论文中,为了使得Classmix更加稳定,引入了Mean-tearch的架构
论文使用 f(θ’) 预测A和B,(其中θ‘ 是θ的移动平均指数值)得到SA和SB,然后用f(θ)预测XA,随后使用梯度下降更新参数θ。
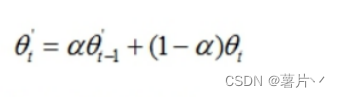

Classmix+Mean-Teacher的framework大致流程:(欢迎指出错误)
3.4.1伪标签
对于没有标签的数据,选取预测概率最大的类别作为其伪标签,它的主要动机来自熵正则化,鼓励网络对未标记的图像进行自信的预测。
半监督学习的目标是利用无标签数据来提高泛化性能。
关于ClassMix的另一个重要细节是,在为增强图像生成标签时,人工标签YA是“argmaxed”的。也就是说,每个像素在类上的概率质量函数被改变为一个单热向量,在被分配最高概率的类中为1,在其他地方为零。这形成了一个用于训练的伪标签,它是半监督学习中常用的技术,目的是鼓励网络进行自信的预测。
对于ClassMix,伪标签还有一个额外的目的,即消除边界上的不确定性。由于掩码M是由A的输出预测生成的,因此掩码的边缘将与语义图的决策边界对齐。这带来了一个问题,即在混合边界附近预测尤其不确定,因为在类边界附近分割任务最难。这导致了一个问题,我们称之为标签污染,如图所示。当M选择的类被粘贴到图像B上时,它们相邻的上下文经常会发生变化,导致人工标签效果不佳。
伪标记有效地缓解了这个问题,因为每个像素的概率质量函数被更改为最可能类别的一个向量,因此“锐化”了人工标签,导致没有污染。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









