






半监督分割的工作总结为两种:self-training和consistency learning。
参考:[CVPR 2021] CPS: 基于交叉伪监督的半监督语义分割
1. 自训练:self-training
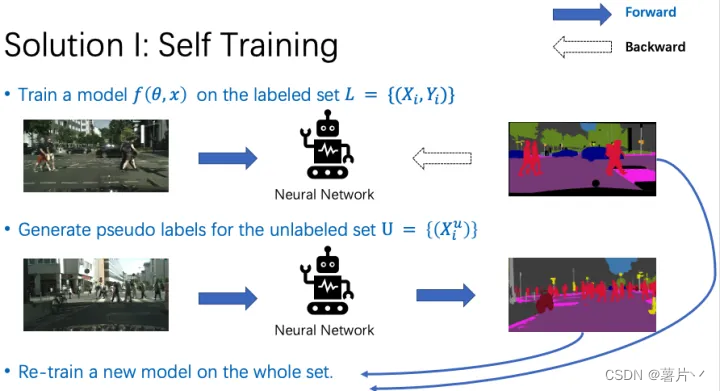
Self-training主要分为3步。
第一步,我们在有标签数据上训练一个模型。
第二步,我们用预训练好的模型,为无标签数据集生成伪标签。
第三步,使用有标注数据集的真值标签,和无标注数据集的伪标签,重新训练一个模型。
2. 一致性学习:consistency learning
一致性学习:鼓励模型对经过不同变换的同一样本有相似的输出。
前文已提到:Π模型,Temporal Ensembling,Mean-Teacher
2.1 PseudoSeg: Designing Pseudo Labels for Semantic Segmentation(ICLR2021)
文章提出了PseudoSeg,这是一个单阶段训练框架,通过利用带有图像级标签(弱标签数据)或没有任何标签的额外数据来改进图像语义分割。PseudoSeg提出了一种新的伪标签设计,用于推断附加数据的有效结构化伪标签。然后优化强增强数据的预测,以匹配相应的伪标签。PseudoSeg采用FixMatch方案,利用弱增强图像的伪分割来监督基于单一分割网络的强增强图像的分割。
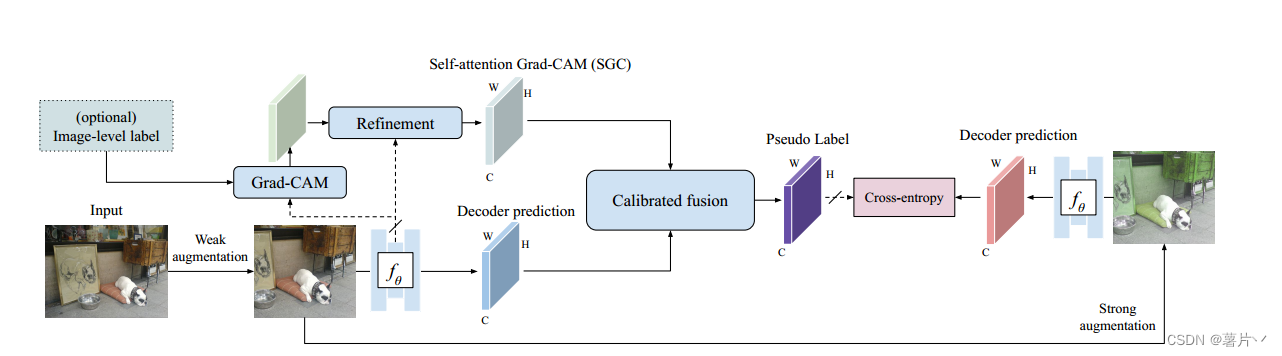
无标签数据训练分支概述。给定图像,将弱增强后的图像输入到网络中,得到解码器预测和自关注Grad-CAM (SGC)。
然后,通过校准的融合策略将两个源组合起来,形成伪标签。通过对网络进行训练,使其解码器从强增强图像中进行预测,并通过逐像素交叉熵损失来匹配伪标签。
2.1.1 CAM
参考:CAM可解释性分析-算法讲解
首先需要知道原始CAM干了什么。对于常规的图像分类,输入卷积神经网络后,对最后一层卷积层进行全局平均池化(GAP),得到一个表征向量,再经过一个全连接层,得到分类向量(如图上)。如果把这个全连接层对应神经元的权重对最后一层卷积层的各channel进行加权求和(如图2下),就能得到类别激活图。
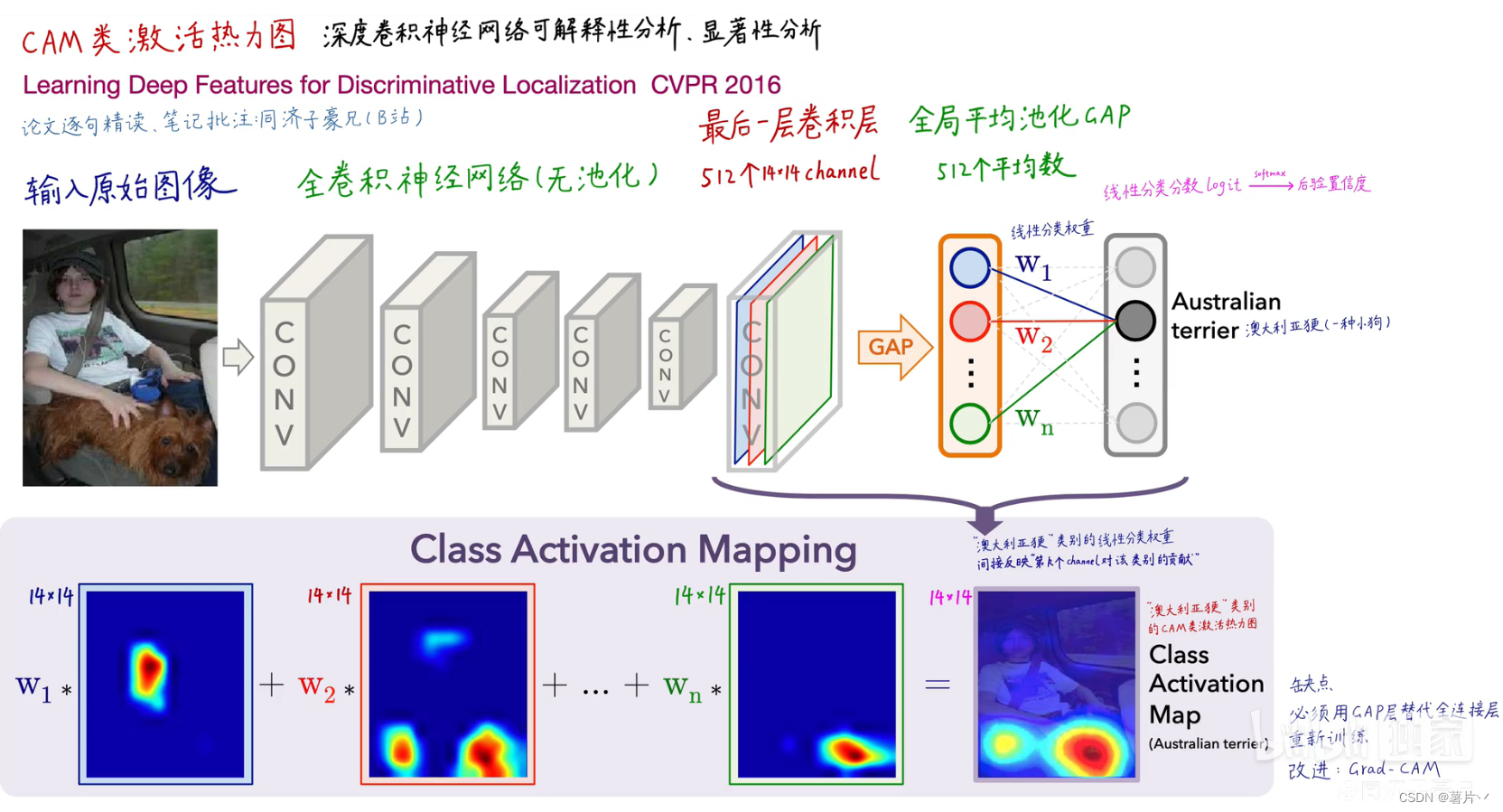

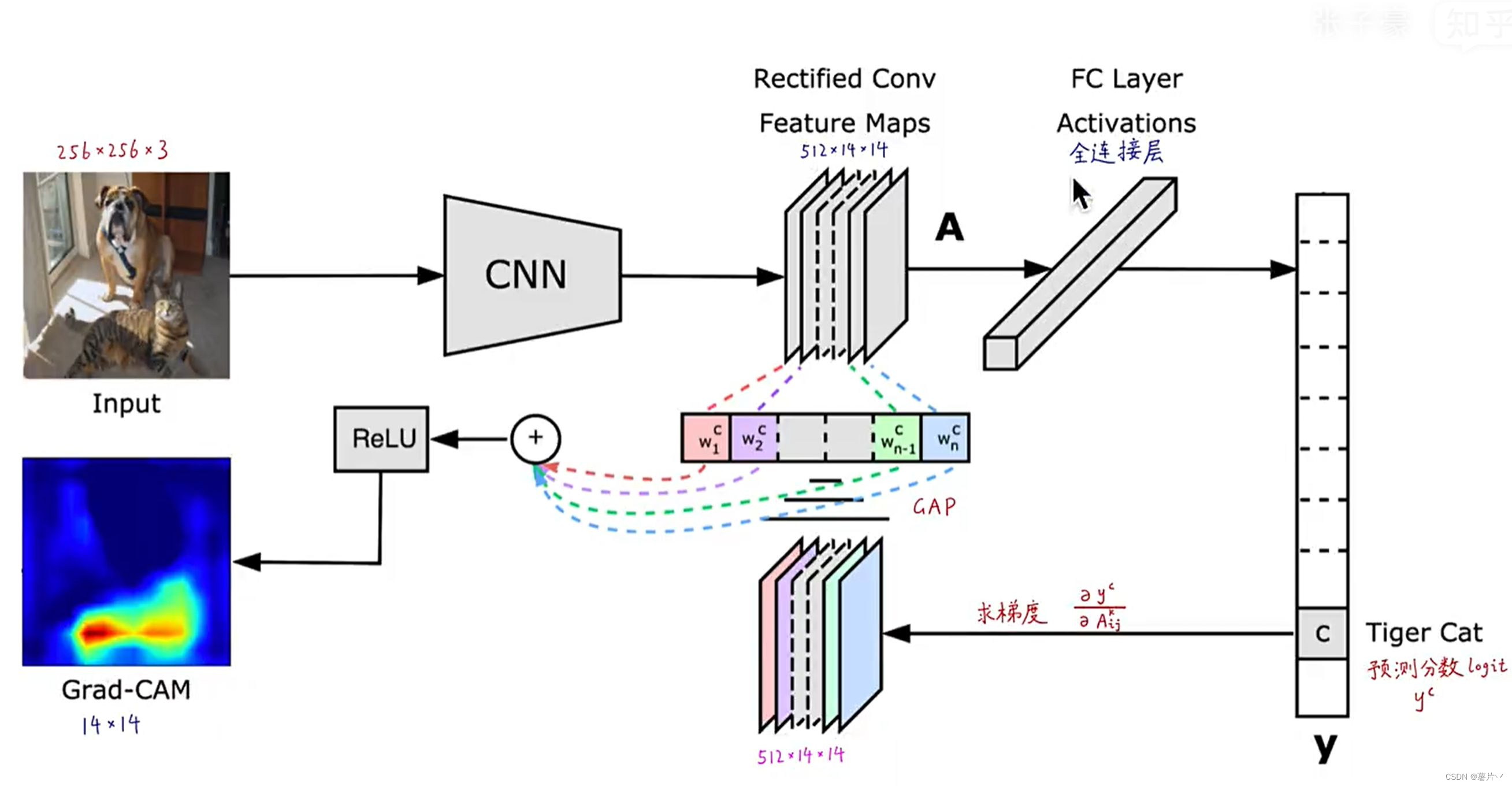
但是,CAM强依赖于GAP,对网络结构较为苛刻。于是提出了Grad-CAM(图),得到的预测分数对最后的feature map的每一个元素求导,组成新的导数feature map,对其进行GAP获得权重,然后再加权求和,经过激活函数,即可得到Grad-CAM. 优点是灵活轻便,即插即用,不需要改变原网络结构。
2.1.2 Grad-CAM
2.1.3 FixMatch
参考:http://t.csdn.cn/R3OC0
伪标记
伪标记(pseudo label)其实算最早的一类半监督算法,代表算法self-training。简单地说就是通过训练的模型对无标记样本打标签,这个标签有对有错,通过一些方法筛选标签后,选择一部分无标记样本和模型打的标签一起送入模型继续训练。伪标记的方法最大问题在于,如何保证伪标记的正确性。因为当模型打的标签提供了较多的错误信息时,会使模型的训练结果更劣。一般常见的筛选方式是将模型输出的预测结果(Softmax之后)进行阈值判断,其argmax的概率大于阈值,才认为是有效标记,否则将此无标记样本丢弃。
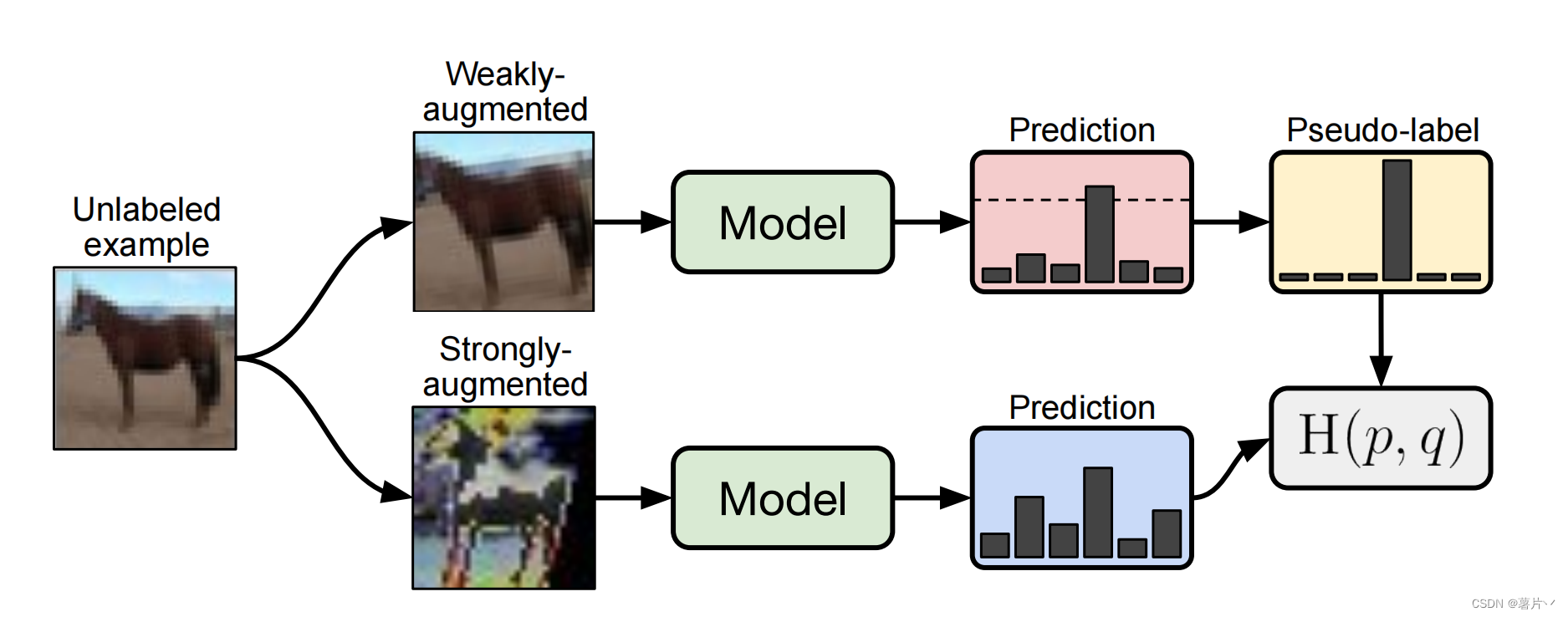
对于有标记样本,进行正常的监督学习,损失函数为CrossEntropyLoss,得到Ls
对于无标签样本:
第一步,先对无标记样本进行扩增(Augment),扩增分为强扩增和弱扩增,弱扩增使用标准的旋转和移位;强扩增使用RandAugment和CTAugment两种算法。
第二步,对扩增后的样本进行预测。对于弱扩增的样本,输出的预测结果(Softmax之后的)最高预测概率(即argmax的结果)大于阈值(图中的虚线),则认为是有效的样本,将其预测结果作为标签(这就是pseudo label)。
第三步:对强扩增的样本,输出的预测结果和对应弱标记样本得到的标签做CrossEntropyLoss,得到损失函数Lu
第四步,计算损失LOSS=Ls+αLu,其中α为超参数。
最终,反向传播完成参数更新。
2.2CPC
参考:论文阅读《Representation learning with contrastive predictive coding 》(CPC)对比预测编码
2.3 CPS
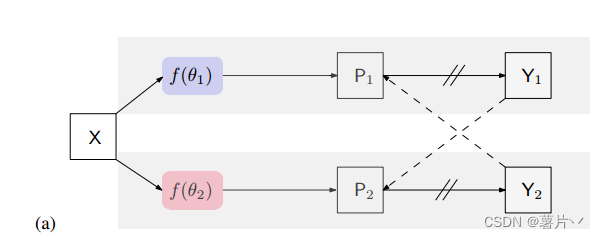
交叉伪监督。该方法由两个并行分割网络组成:
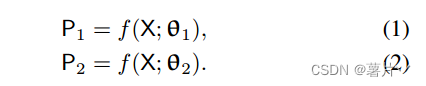
这两个网络具有相同的结构,其权重θ1和θ2初始化方式不同。输入X增广相同,P1 (P2)为分割置信图,即softmax归一化后的网络输出。建议的方法逻辑说明如下1:
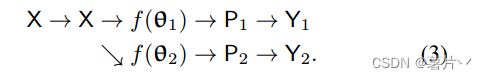
其中Y1 (Y2)为预测的单热标签映射,称为伪分割映射。
对于损失函数:
在两个并行分割网络上,使用标记图像上的标准逐像素交叉熵损失来表示监督损失Ls:(Y *1i、Y * 2i是真值。)
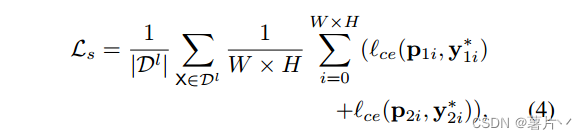
交叉伪监督损失是双向的:一个是从f(θ1)到f(θ2)。我们使用从一个网络f(θ1)输出的逐像素单热标签映射Y1来监督另一个网络f(θ2)的逐像素置信度映射P2,另一个是从f(θ2)到f(θ1)。对未标记数据的交叉伪监督损失写为
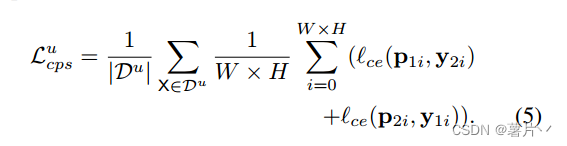
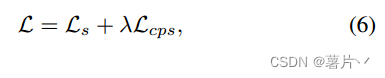
方法中应用了CutMix增强。
将CutMixed图像输入到两个网络f(θ1)和f(θ2)中。使用类似的方式从两个网络中生成伪分割图:将两个源图像(用于生成CutMix图像)输入到每个分割网络中,并将两个伪分割图混合作为另一个分割网络的监督。















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









