






参考的B站视频:https://www.bilibili.com/video/BV1HK4y1M7jm/
注:B站视频在Mean-teacher这部分的讲解有小错误,本笔记已修改。
伪代码可见:http://t.csdn.cn/GdBnv
此笔记用于理解原理。
1.简单的理解
简单的讲,对于半监督模型,数据中有无标签数据和有标签数据,对于所有的数据,我们可以先将数据进行聚类,然后每一类中,既有无标签数据,又有有标签数据,因此,该聚类中的无标签数据的标签就赋予为有标签数据的标签。
以上是一个简单的思想,先不考虑复杂情况,基本思想就是:相似的样本有相似的标签。
2. Π模型


3.Temporal Ensembling
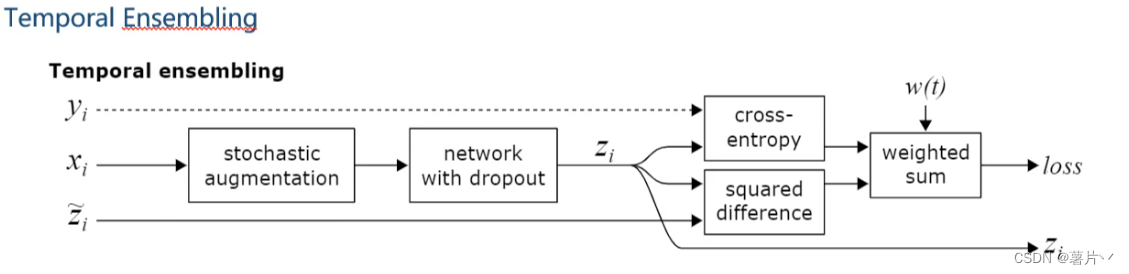
相较于Π模型,Temporal Ensembling 对无标签数据减少了一次计算,因此速度快了一倍。

EMA:

具体的公式:

得到:
然后讲1个epoch的所有加起来,得到loss。
注:第一次只使用labeled data,不用计算均方损失。
4 Mean-Teacher
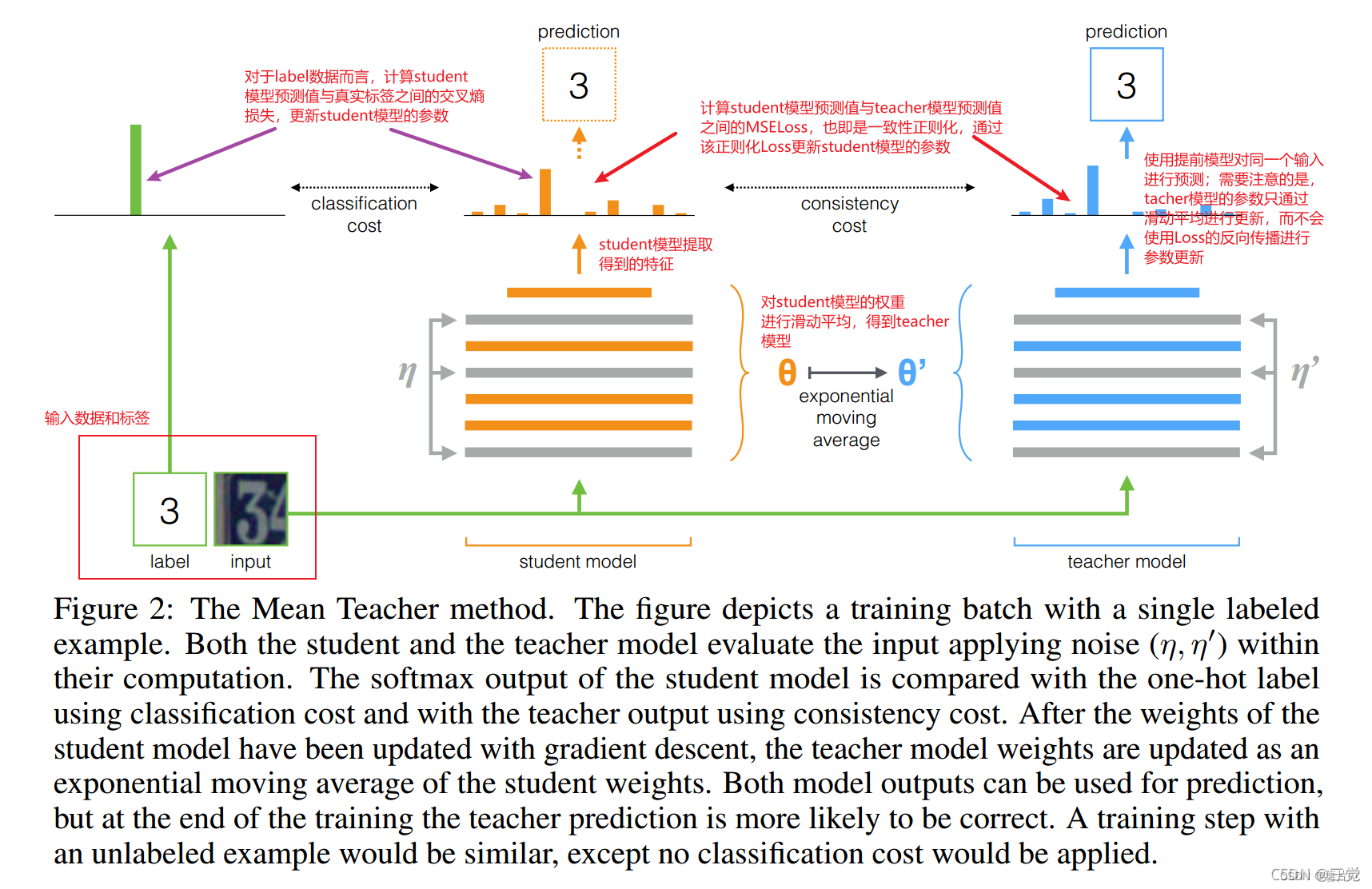
以上图片来源:http://t.csdn.cn/xArk4
算法流程:
参考:http://t.csdn.cn/IYNOt


上图中的L2为:
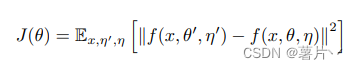 (教师模型的预测—学生模型的预测)²x:样本特征值;θ:神经网络的参数;η:教室/学生模型的噪声
(教师模型的预测—学生模型的预测)²x:样本特征值;θ:神经网络的参数;η:教室/学生模型的噪声
-
教师模型不反向传播更新参数,当student反向传播更新参数后,通过EMA更新参数。 也就是:
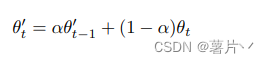
-
所有的损失为:有标签数据集在学生模型下和真实label的loss(L1)+有标签和无标签数据通过学生模型和教师模型后,两模型结果之间的loss(L2)















 4803
4803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









