







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
本次主要是通过对原始的客户购买记录数据进行数据清洗与数据预处理,提取数据构建RFM模型,然后对客户进行聚类,最后模型应用,将客户分成不同的客户群。
实现目标有三:
1.借助客户数据,对客户进行分类
2.对不同的客户类别进行特征分析,比较不同类客户的客户价值
3.对不同价值的客户类别提供个性化服务,制定相应的销售策略
原始数据读者可通过点击该此处来获取。
一、知识准备
1.1.RFM模型
RFM模型是衡量客户价值和客户创造利益能力的重要工具和手段。在众多的客户关系管理(CRM)的分析模式中,RFM模型是被广泛提到的。该机械模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱3项指标来描述该客户的价值状况。
1.2.kmean聚类
1.最常见的划分方法是K均值聚类分析。算法如下:
- (1) 选择K个中心点(随机选择K行);
- (2) 把每个数据点分配到离它最近的中心点;
- (3) 重新计算每类中的点到该类中心点距离的平均值(也就说,得到长度为p的均值向量,这 里的p是变量的个数);
- (4) 分配每个数据到它最近的中心点;
- (5) 重复步骤(3)和步骤(4)直到所有的观测值不再被分配或是达到最大的迭代次数
2.聚类一般步骤
-
(1) 选择合适的变量。
-
(2) 缩放数据。变量标准化为均值为0和标准差为1的变量。或被其最大值相除或该变量减去它的平均值并除以变量的平均绝对偏差。
-
(3) 寻找异常点。
-
(4) 计算距离。两个观测值之间最常用的距离量度是欧几里得距离
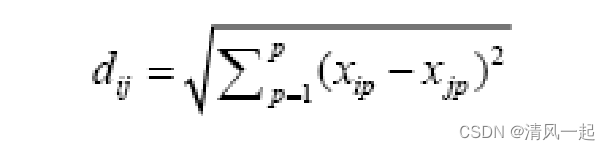
如以下例子:
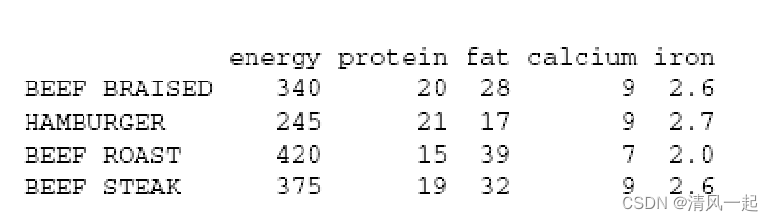
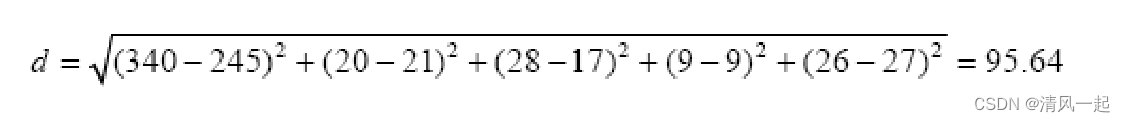
-
(5) 选择聚类算法。
层次聚类对于小样本来说很实用(如150个观测值或更少),这种情况下,嵌套聚类更实用。
划分的方法能处理更大的数据量,但是需要事先确定聚类的个数。 -
(6) 获得一种或多种聚类方法。
-
(7) 确定类的数目。
常用方法是尝试不同的类数(比如2~K)并比较解的质量。往往使用CH系数和手肘法来可视化观察
- (8) 获得最终的聚类解决方案。
- (9) 结果可视化。
层次聚类的结果通常表示为一个树状图。划分的结果通常利用可视化双变量聚类图来表示。
- (10) 解读类。
- (11) 验证结果。
二、Python实现过程
2.1.数据清洗
1.读入原始数据
#读入原始数据
import pandas as pd
data = pd.read_csv('实验2数据data.csv.csv',encoding = 'ISO-8859-1',header = 0)
#查看一下数据
display(data.head())
display(data.sample(5))
结果:
2.探索性分析
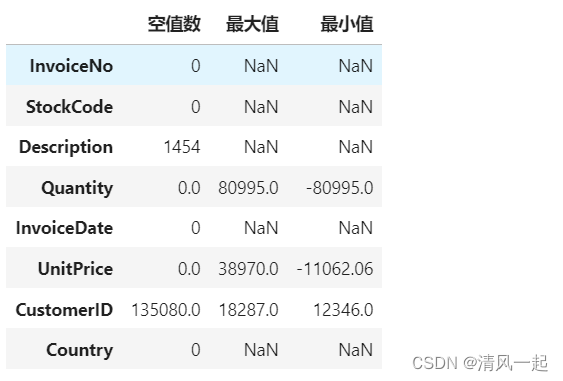
explore = data.describe(percentiles = [],include = 'all').T
explore['null'] = len(data)-explore['count']
explore = explore[['null','max','min']]
explore.columns = [u'空值数',u'最大值',u'最小值']
explore
下面结果方面显示
CustomerID 列存在135080个空值数据。理应删除,UnitPrice也类似
3.处理缺失值
# data = data[data['CustomerID'].notnull()*data['Description'].notnull()]
data = data[data['CustomerID'].notnull()]
data = data[data['UnitPrice'].notnull()]
data
4.将清洗后的数据存入Excel表
data.to_excel('实验2清洗后数据_1.xlsx',header = True)
data1 = pd.read_excel('实验2清洗后数据_1.xlsx')
data1.head()
5.处理缺失值
利用箱线图查看一下数据
#画一下Quantity列的箱线图
import matplotlib.pyplot as plt
#2.画箱线图
import numpy as np
list_fen = []
plt.grid(True) # 显示网格
for i in data1['Quantity']:
list_fen.append(i)
# print(list_fen)
plt.boxplot(list_fen,
medianprops={'color': 'red', 'linewidth': '1.5'},
meanline=True,
showmeans=True,
meanprops={'color': 'blue', 'ls': '--', 'linewidth': '1.5'},
flierprops={"marker": "o", "markerfacecolor": "red", "markersize": 10},
labels=['Quantity'])
# plt.yticks(np.arange(0, 12, 0.2))
删除异常值
# 箱型图判断异常点
def box_outlier(data):
df = data[['Quantity','UnitPrice']].copy(deep=True)
out_index = []
for col in df.columns: # 对每一列分别用箱型图进行判断
Q1 = df[col].quantile(q=0.25) # 下四分位
Q3 = df[col].quantile(q=0.75) # 上四分位
low_whisker = Q1 - 1.5 * (Q3 - Q1) # 下边缘
up_whisker = Q3 + 1.5 * (Q3 - Q1) # 上边缘
# 寻找异常点,获得异常点索引值,删除索引值所在行数据
rule = (df[col] > up_whisker) | (df[col] < low_whisker)
out = df[col].index[rule]
out_index += out.tolist()
data.drop(out_index, inplace=True)
return data
box_outlier(data1)
2.2.下面开始构建RFM模型
1.构建R
from datetime import datetime
from datetime import timedelta
# R:购买行为,最近消费 假设当前时间为2011-12-2 8:00
# time_object = '12/2/2010 8:00'
# data1['InvoiceDate'][3]
# data3 = time_object-data1['InvoiceDate'][3]
data1['nowtime'] = '12/24/2011 8:00'
data1['nowtime']= pd.to_datetime(data1['nowtime'])
data1['InvoiceDate'] = pd.to_datetime(data1['InvoiceDate'])
data1['nowtime'] = pd.to_datetime(data1['nowtime'])
data1['R'] = data1['nowtime'] - data1['InvoiceDate']
data1['R'] = pd.to_timedelta(data1['R'])
data1['R'] = data1['R'].dt.total_seconds()
##R
data1_R = data1.groupby('CustomerID')['R'].min()
display(data1_R)
#R就被我们存到data1_R里面
data1_R = data1_R.reset_index()
data1_R.sort_values(by='CustomerID', inplace=True)
data1_R.to_excel('R_1.xlsx',header = True)
将处理后的R数据存入Excel表,利于我们下一次数据的合并,构建成完整的RFM模型数据。读者也可以不存入Excel表,只要最后将3个DataFrame进行合并(用df,merge()函数)
2.构建F
# 求F
result = data1.groupby(['InvoiceNo', 'CustomerID']).size()
print(result)
result = pd.DataFrame(result)
# result.columns
# display(result.index)
#重新设置索引
result = result.reset_index()
#display(result['CustomerID'])
result1 = result['CustomerID'].value_counts()
data1_F = result1
data1_F = data1_F.reset_index()
display(data1_F)
data1_F.columns = ['CustomerID','F']
display(data1_F)
data1_F.sort_values(by='CustomerID', inplace=True)
data1_F.to_excel('F_1.xlsx',header = True)
3.构建M
data1['金额'] = data1['Quantity']*data1['UnitPrice']
display(data1['金额'])
data1_M = data1.groupby('CustomerID')['金额'].sum()
display(data1_M)
data1_M = data1.groupby('CustomerID')['金额'].sum()
display(data1_M)
data1_M = pd.DataFrame(data1_M)
data1_M = data1_M.reset_index()
display(data1_M)
# data1_F = data1_F.reset_index()
data1_M.sort_values(by='CustomerID', inplace=True)
data1_M.to_excel('M_1.xlsx',header = True)
2.3.K-means聚类
1.读入RFM模型数据
#读入RMF模型
df = pd.read_excel('RFM_1.xlsx')
df.head()
data = df[['R','F','M']]
data.describe()
2.探索性分析(可视化看一下数据的分布)
# 绘制一下购买行为(R)的直方图
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
plt.rcParams['font.family'] = ['SimHei']
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
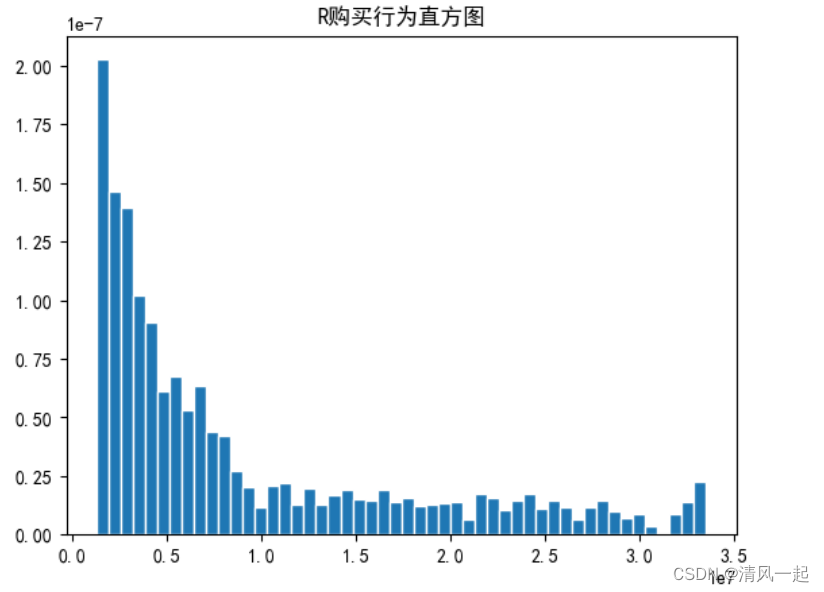
#plt.hist()也就是这个作用。将一个大区间划分为等间隔的小区间,并统计每个区间上样本出现的频数之和。
plt.hist(data['R'],bins = 50,edgecolor = 'white',density = True) # 每一份正好3
plt.title('R购买行为直方图')
plt.show()
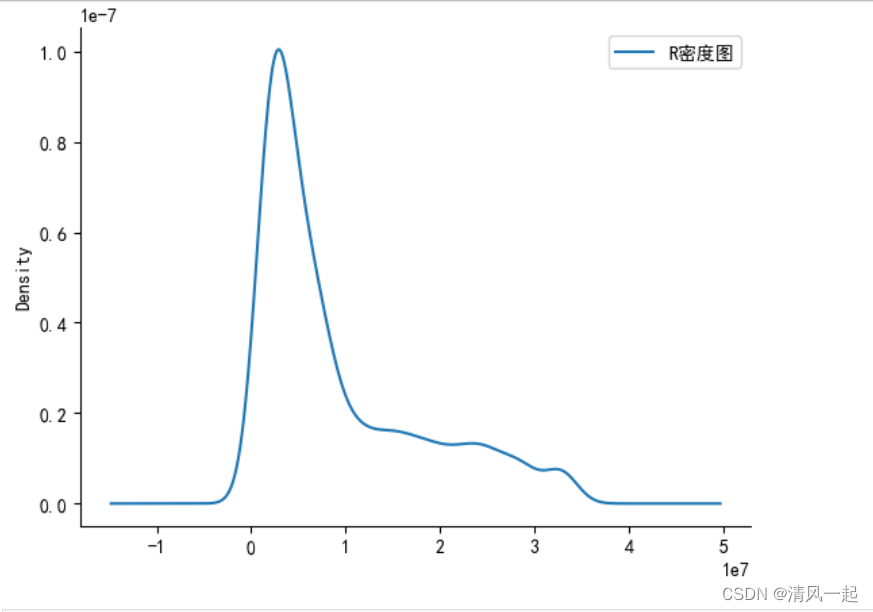
ax = plt.gca()
data['R'].plot(kind = 'kde',label = 'R密度图') # 获取当前子图
ax.spines['right'].set_color('none') # 右边框设置无色
ax.spines['top'].set_color('none') # 上边框设置无色
# 显示图例
plt.legend()
# 显示图形
plt.show()
其他M,F列数据可视化类型,读者参加对R列数据的可视化,不再加以赘述
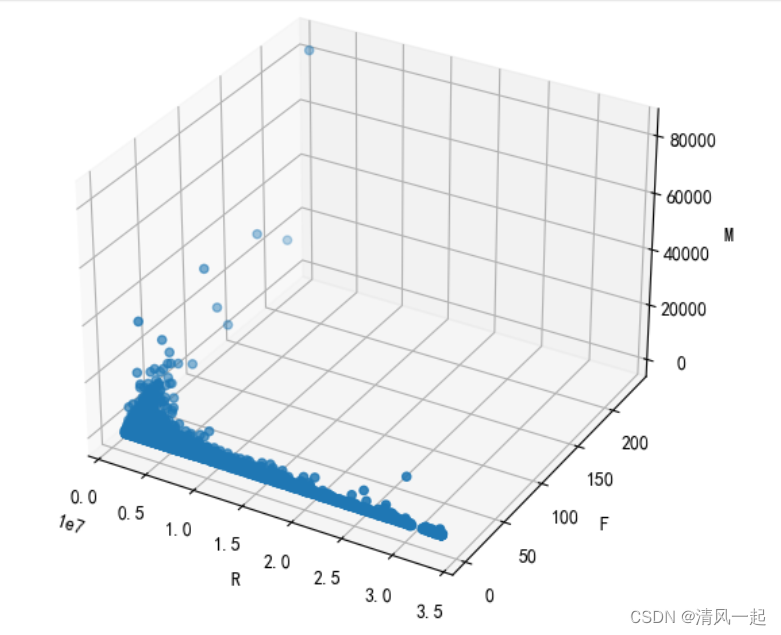
3.三维散点图
#三维散点图
k=4
# df['label'] = label_pred #在原数据表显示聚类标签
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 空间三维画图
#设置x、y、z轴
x=data['R']
y=data['F']
z=data['M']
#绘图
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, y, z) #c指颜色,c=label_pred刚好四个分类四个颜色。相比普通三维散点图只改了这里!!!
# 添加坐标轴
ax.set_xlabel('R', fontdict={'size': 10, 'color': 'black'})
ax.set_ylabel('F', fontdict={'size': 10, 'color': 'black'})
ax.set_zlabel('M', fontdict={'size': 10, 'color': 'black'})
plt.show()
4.数据标准化
#数据的离差标准化(把数据映射到[0,1]) 在不涉及距离度量、梯度,协方差计算以及数据需要被压缩到特定区间时使用广泛
def MinMaxScale(data):
data = (data-data.min())/(data.max()-data.min())
return data
# data1 = MinMaxScale(data)
# 数据标准差标准化(数据均值为0,标准差为1) 在PCA,聚类,逻辑回归,支持向量机,神经网络等算法中
def StandarScale(data):
data = (data-data.mean())/data.std()
return data
data1 = StandarScale(data)
display(data1)
# display(data2)
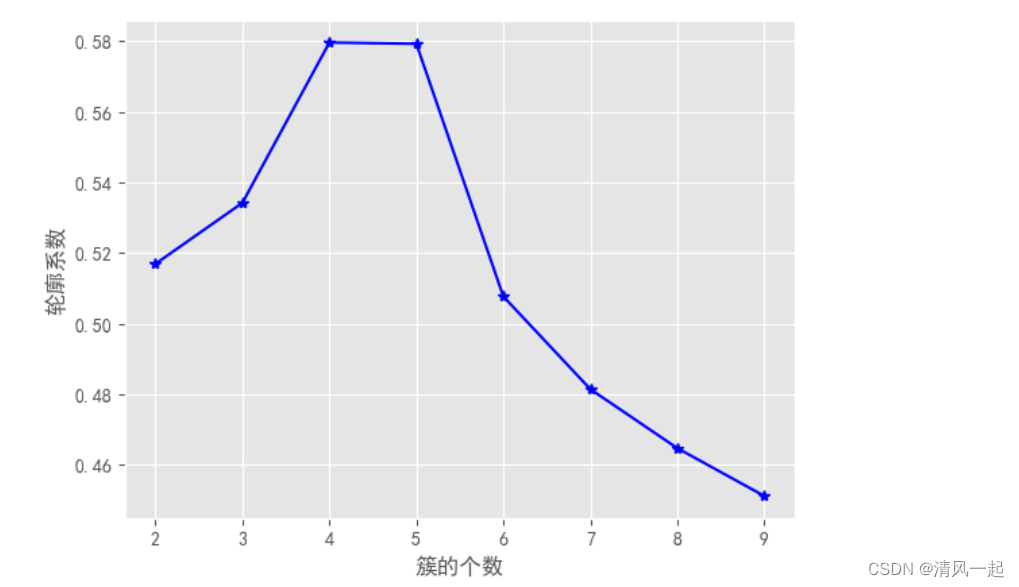
5.探索聚成多少类(CH系数和手肘法)
import seaborn as sns
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
from pandas import DataFrame
from sklearn import metrics
from sklearn.decomposition import PCA
# 轮廓系数法
K = range(2, 10)
# 构建空列表,用于存储个中簇数下的轮廓系数
S = []
for k in K:
kmeans = KMeans(n_clusters=k)
kmeans.fit(data1[['F','M','R']])
labels = kmeans.labels_
# 调用字模块metrics中的silhouette_score函数,计算轮廓系数
S.append(metrics.silhouette_score(data1[['F','M','R']], labels, metric='euclidean'))
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
# 绘制K的个数与轮廓系数的关系
plt.plot(K, S, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('轮廓系数')
# 显示图形
plt.show()
#轮廓系数图通常以轮廓系数最大时的 K 值为准。
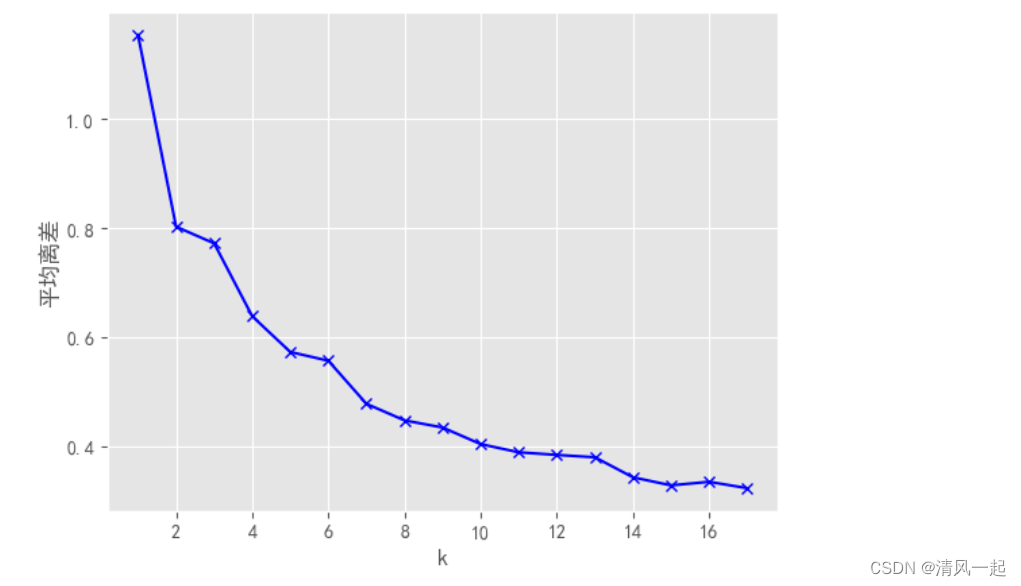
import numpy as np
# 手肘图法1——基于平均离差
K = range(1, 18)
meanDispersions = []
for k in K:
kemans = KMeans(n_clusters=k)
kemans.fit(data1[['F','M','R']])
# 计算平均离差
m_Disp = sum(np.min(cdist(data1[['F','M','R']], kemans.cluster_centers_, 'euclidean'), axis=1)) / data1[['R','M','F']].shape[0]
meanDispersions.append(m_Disp)
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使折线图显示中文
plt.plot(K, meanDispersions, 'bx-')
plt.xlabel('k')
plt.ylabel('平均离差')
plt.title('')
plt.show()
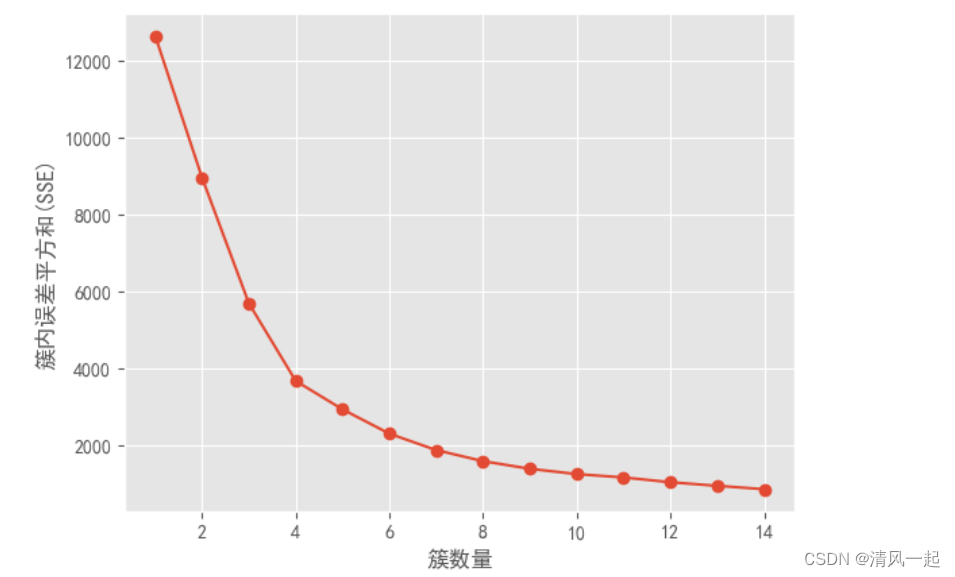
# 手肘图法2——基于SSE
distortions = [] # 用来存放设置不同簇数时的SSE值
for i in range(1,15):
kmModel = KMeans(n_clusters=i)
kmModel.fit(data1[['F','M','R']])
distortions.append(kmModel.inertia_) # 获取K-means算法的SSE
# 绘制曲线
plt.plot(range(1, 15), distortions, marker="o")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel("簇数量")
plt.ylabel("簇内误差平方和(SSE)")
plt.show()
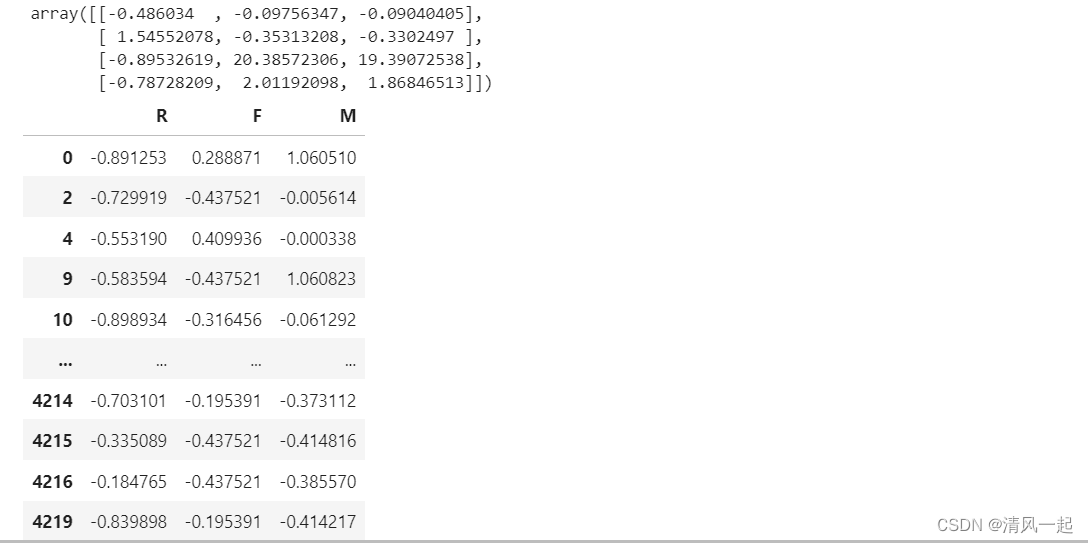
6.聚类结果
#综合评估后我们将客户聚成4类,k=4
# K-means聚类
kms = KMeans(n_clusters=4, init='k-means++')
data_fig = kms.fit(data1[['R','F','M']]) # 模型拟合
centers = kms.cluster_centers_ # 计算聚类中心
display(centers)
labs = kms.labels_ # 为数据打标签
df_labels = DataFrame(kms.labels_) # 将标签存放为DataFrame
# df_labels.to_excel('RFM聚类后.xlsx') # 输出数据标签,其实输出可有可无
# 将聚类结果为 0,1,2,3 的数据筛选出来 并打上标签
df_A_0 = data1[kms.labels_ == 0]
df_A_1 = data1[kms.labels_ == 1]
df_A_2 = data1[kms.labels_ == 2]
df_A_3 = data1[kms.labels_ == 3]
m = np.shape(df_A_0)[1]
k = np.shape(df_A_1)[1]
display(df_A_0)
display(df_A_1)
display(df_A_2)
display(df_A_3)
# print(m)
# print(k)
# print(df_A_0)
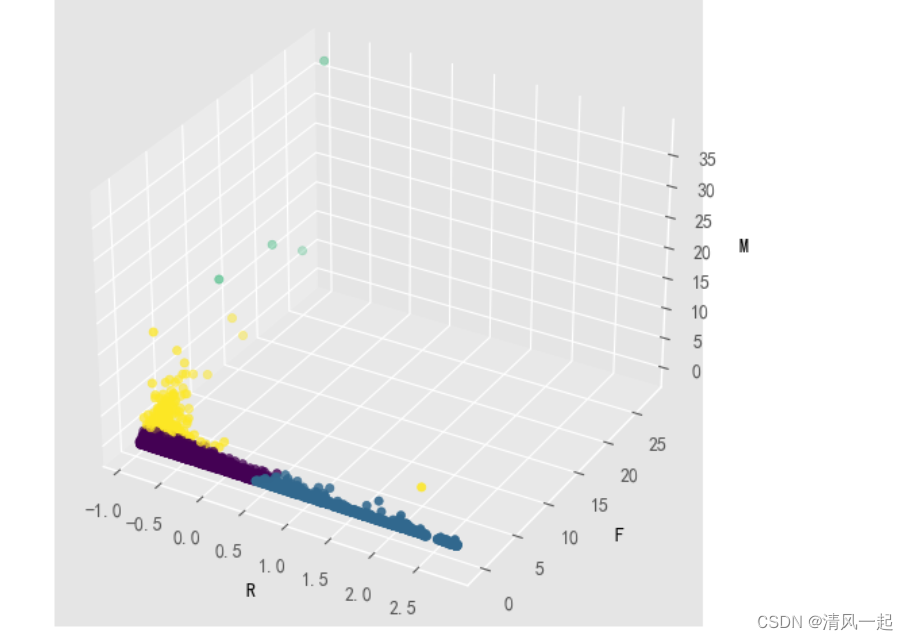
7.聚类结果可视化(三维散点图)
k=4
# df['label'] = label_pred #在原数据表显示聚类标签
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D # 空间三维画图
#设置x、y、z轴
x=data1['R']
y=data1['F']
z=data1['M']
#绘图
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, y, z, c=labs) #c指颜色,c=labs刚好四个分类四个颜色。相比普通三维散点图只改了这里!!!
# 添加坐标轴
ax.set_xlabel('R', fontdict={'size': 10, 'color': 'black'})
ax.set_ylabel('F', fontdict={'size': 10, 'color': 'black'})
ax.set_zlabel('M', fontdict={'size': 10, 'color': 'black'})
plt.show()
8.聚类结果可视化特征分析(雷达图)
#雷达图
import numpy as np
k=3
labels = ['R','F','M','R']
#每个类别中心点数据
plot_data = kms.cluster_centers_
#指定颜色
color = ['b', 'g', 'r', 'c']
# 设置角度
angles = np.linspace(0, 2*np.pi, k, endpoint=False)
# 闭合
angles = np.concatenate((angles, [angles[0]]))
plot_data = np.concatenate((plot_data, plot_data[:,[0]]), axis=1)
fig = plt.figure()
ax = fig.add_subplot(111, polar=True) # polar参数为True即极坐标系
for i in range(len(plot_data)):
ax.plot(angles, plot_data[i], 'o-', color = color[i], label = '客户群'+str(i+1), linewidth=2)
ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
ax.set_title('聚类类别特征分析')
plt.legend(loc = 4) # 设置图例位置
plt.show()
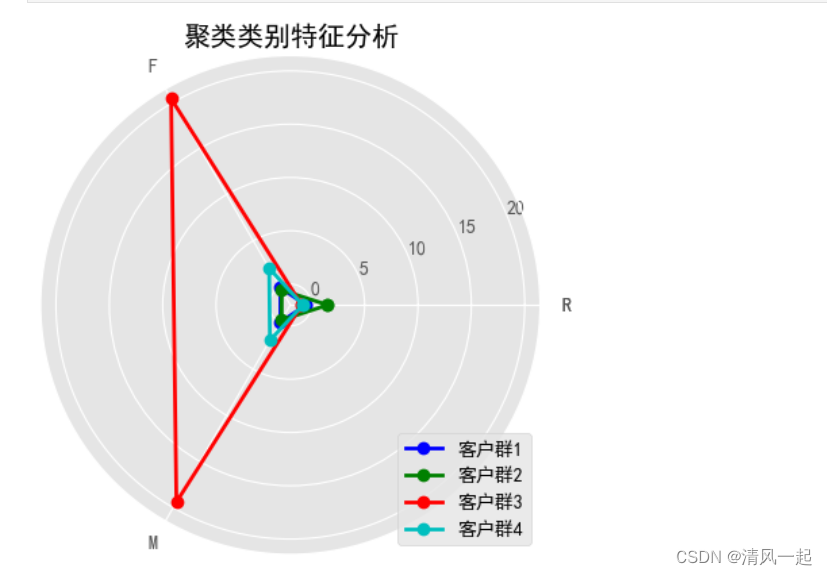
结果分析:对聚类结果进行分析可得,客户群4在F,M属性上最大,在R属性上最小; 客户群3中在R属性上最大,在F,M属性上最小; 客户群2中在F,M属性大于客户群1,客户群2中在R属性小于客户群1。
得出结论:客户4,客户2,客户1,客户3分别为全天候战略合作伙伴、全面战略协作伙伴、战略合作伙伴、一般伙伴。(doge)
9.与em聚类对比
# 导入基本库
import matplotlib.pyplot as plt
#from sklearn.datasets.samples_generator import make_blobs
from sklearn.datasets import load_iris
from sklearn.mixture import GaussianMixture
# iris = load_iris()
X=data2
# X = iris.data
# y = iris.target
#display(X)
#display(X['R'])
# ss = StandardScaler()
# X = ss.fit_transform(X)
# plt.scatter(X['R'],X['F'],X['M'],c="red")
# display(y)
#构建GMM聚类
gmm = GaussianMixture(n_components = 4,covariance_type = 'full')
gmm.fit(X)
#训练数据
label_pred = gmm.predict(X)
print('聚类结果','\n',label_pred)
print('真实类别','\n',y)
x0=X[label_pred == 0]
x1=X[label_pred == 1]
x2=X[label_pred == 2]
x3=X[label_pred == 3]
print(x0.shape,x1.shape, x2.shape, x3.shape)
三维散点图和雷达图与k-means聚类类似,读者可自行实现可视化。
三、模型应用
1.聚类结果分析
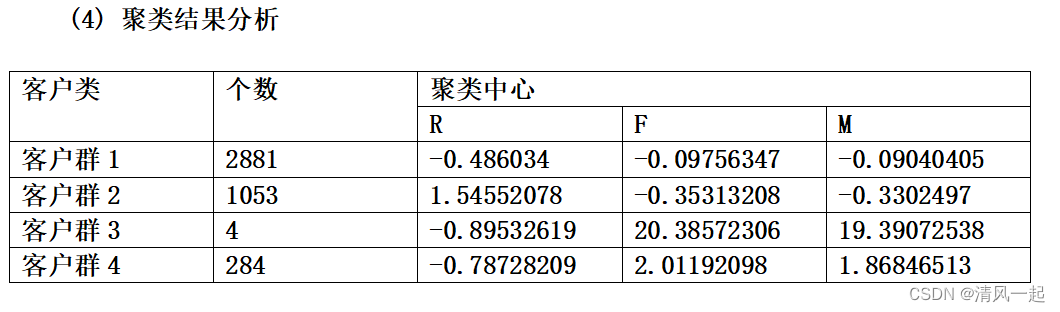
结果分析:对聚类结果进行分析可得,客户群3在F,M属性上最大,在R属性上最小;客户群1中在R属性上最大,在F,M属性上最小;客户群4中在F,M属性大于客户群2,在R属性小于客户群2
因此,我们可以根据对公司价值的不同对客户群进行分类,分别为重要保持客户、重要发展客户、重要挽留客户和一般客户。
1.重要保持客户:M,F均很高,R最小,对公司贡献最大,为我们理想客户,且数量较少,可以对该类客户进行差异性管理和一对一服务,提高该类客户忠诚度和满意度,尽可能延长这类客户该水平消费。
2.重要发展客户:当前价值不大,当有很大的潜力,是公司重要潜在客户。应与这类客户提高合作,提高其的满意度,提高他们转向竞争对手的转移成本,让其逐渐成为我们的忠诚客户。
3.重要挽留客户:该类客户价值不确定性很高。应维持与该类客户的互动,关注其最近动向,采取一定的销售手段,延长客户的生命周期。
4.一般客户:这部分客户价值较小,需要关注最近定向,一般不进行特殊的营销。
2.应用(销售策略)
1.可以给根据客户价值不同给予不同类型VIP卡,依次为金卡,银卡,VIP用户等。
不同VIP客户享受不同的服务和不同的折扣。
2.积分兑换,每一次购买金额都可以积累一定的积分,可以兑换相应的礼物。
读者可以自行思考,做出自己的销售策略
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









