








前几天学习了怎么使用HDFS,今天稍微深入一下,HDFS是怎么工作的;
HDFS读取数据的方式:
以下是极简的读取数据:
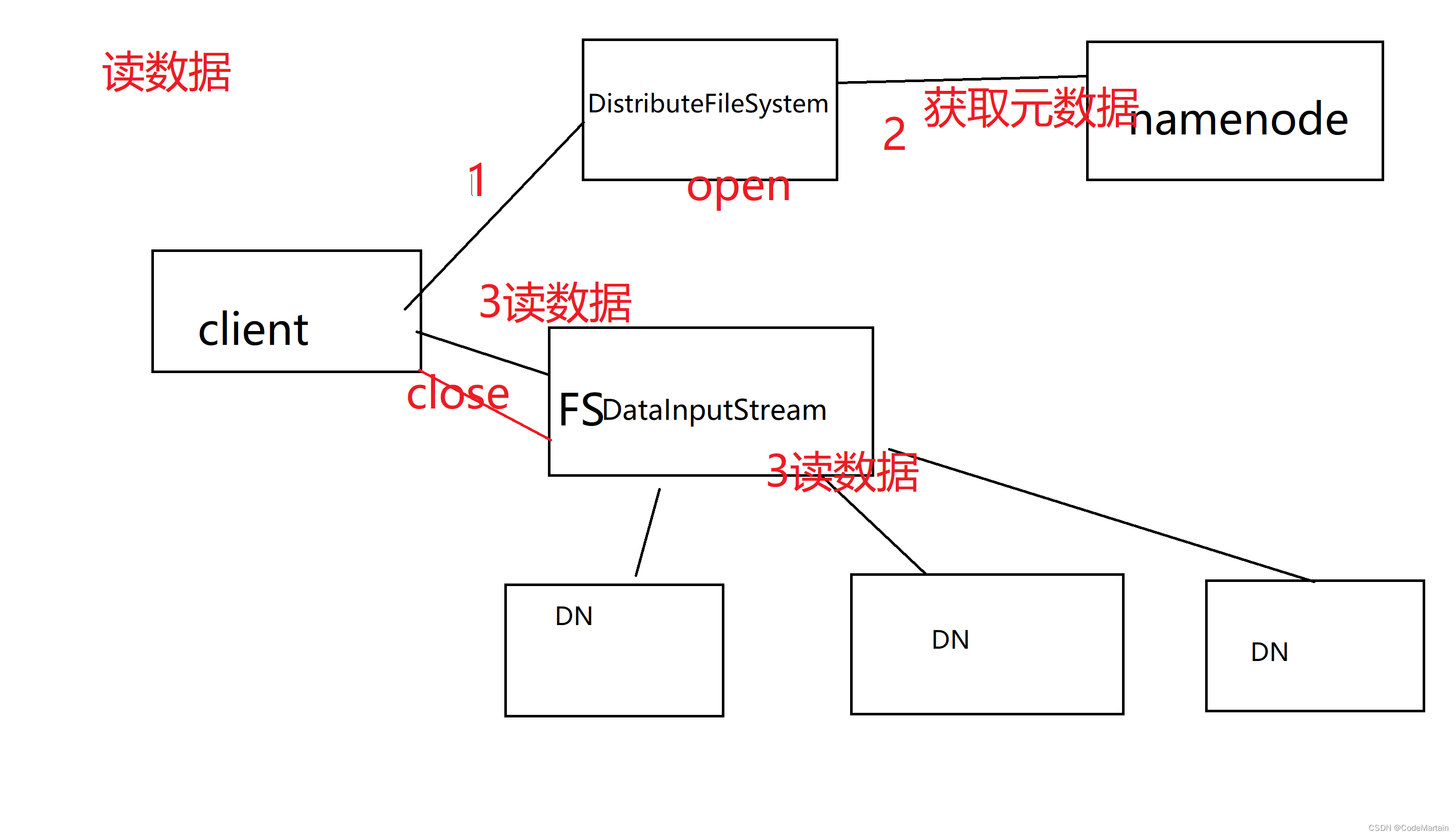
客户端读取数据,首先通过DistributefileSystem 获取数据的元数据(即元数据存在哪里)
为了加快读取速度,首先考虑读取位置离客户端最近的 数据,那怎么判断呢?
通过一个关于位置的API来获取数据存储的位置(机架号) ,通过对比客户端所在机架号跟数据所在机架号,如果一致则优先读取,否则就会随机读取;
其中我们编写代码时是通过FsDatainputStream,其实现了hadoop中的dfsDataInputStream
HDFS写入数据
那怎么写入数据呢?
还是这些组件,只不过在写入的时候是串联的方式,
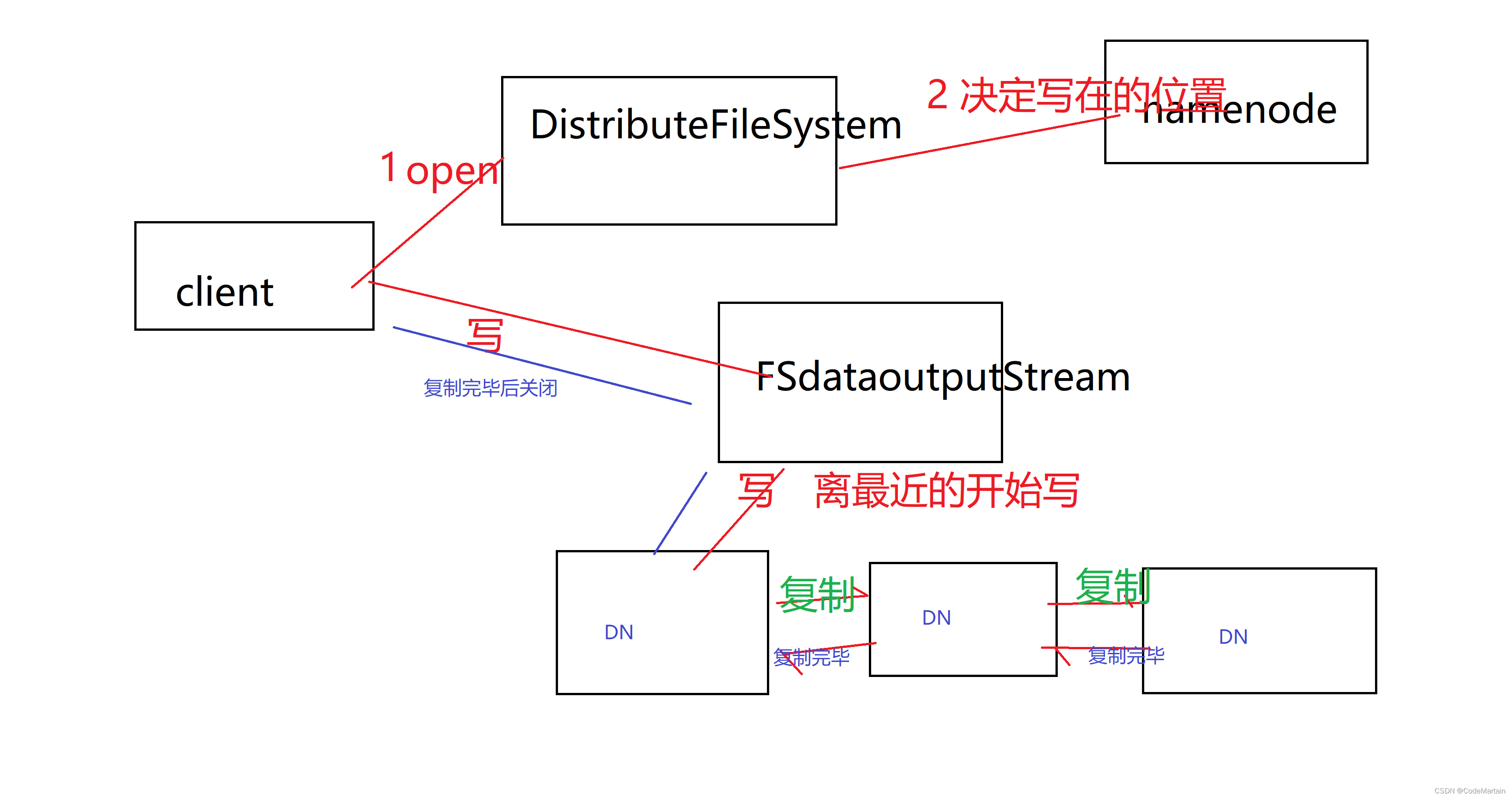
写的时候先检查有没有写的权限,有权限之后检查是不是已经写了(重名的),然后开始写,首先是写入离自己近的机架,写入第一个后返回写入成功,然后由第一个赋值给第二个,完成后第二个发送通知给第一个,以此类推,直到所有的节点都写完了;
如果集群出现问题怎么办?
1,在hadoop1.0版本时由于只有一个NameNode,所以当NameNode宕机之后,集群就挂了(停止运行),这时候要通过SecondryNameNode冷备来恢复;
在hadoop2.0版本的时候有了热备,此时主NameNode挂了之后,热备的会顶上;第二名名称节点还是一个备胎~冷备;
由于NameNode的数据存放在内存中,内存不能无限制大,所以当集群数据越来越多时,性能就会下降;
2,如果DataNode出现故障,此时NameNode所在节点会重新复制一份数据以使得副本数量符合要求;
那Namenode所在节点怎么知道DN出现故障的呢? DN会定时发送心跳给NameNode,就像一个注册中心一样;
简单的JAVAAPI
一个简单的例子:
假设在目录“hdfs://localhost:9000/user/hadoop”下面有几个文件,分别是file1.txt、file2.txt、file3.txt、file4.abc和file5.abc,这里需要从该目录中过滤出所有后缀名不为“.abc”的文件,对过滤之后的文件进行读取,并将这些文件的内容合并到文件“hdfs://localhost:9000/user/hadoop/merge.txt”中。
为了编写一个能够与HDFS交互的Java应用程序,一般需要向Java工程中添加以下JAR包:
(1)“/usr/local/hadoop/share/hadoop/common”目录下的所有JAR包,包括hadoop-common-3.1.3.jar、hadoop-common-3.1.3-tests.jar、haoop-nfs-3.1.3.jar和haoop-kms-3.1.3.jar,注意,不包括目录jdiff、lib、sources和webapps;
(2)“/usr/local/hadoop/share/hadoop/common/lib”目录下的所有JAR包;
(3)“/usr/local/hadoop/share/hadoop/hdfs”目录下的所有JAR包,注意,不包括目录jdiff、lib、sources和webapps;
(4)“/usr/local/hadoop/share/hadoop/hdfs/lib”目录下的所有JAR包。
import java.io.IOException;
import java.io.PrintStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
/**
* 过滤掉文件名满足特定条件的文件
*/
class MyPathFilter implements PathFilter {
String reg = null;
MyPathFilter(String reg) {
this.reg = reg;
}
@Override
public boolean accept(Path path) {
if (!(path.toString().matches(reg))) {
return true;
}
return false;
}
}
/***
* 利用FSDataOutputStream和FSDataInputStream合并HDFS中的文件
*/
public class MergeFile {
Path inputPath = null; //待合并的文件所在的目录的路径
Path outputPath = null; //输出文件的路径
public MergeFile(String input, String output) {
this.inputPath = new Path(input);
this.outputPath = new Path(output);
}
public void doMerge() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://master:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fsSource = FileSystem.get(URI.create(inputPath.toString()), conf);
FileSystem fsDst = FileSystem.get(URI.create(outputPath.toString()), conf);
//下面过滤掉输入目录中后缀为.abc的文件
FileStatus[] sourceStatus = fsSource.listStatus(inputPath,
new MyPathFilter(".*\\.abc"));
FSDataOutputStream fsdos = fsDst.create(outputPath);
PrintStream ps = new PrintStream(System.out);
//下面分别读取过滤之后的每个文件的内容,并输出到同一个文件中
for (FileStatus sta : sourceStatus) {
//下面打印后缀不为.abc的文件的路径、文件大小
System.out.print("路径:" + sta.getPath() + " 文件大小:" + sta.getLen()
+ " 权限:" + sta.getPermission() + " 内容:");
FSDataInputStream fsdis = fsSource.open(sta.getPath());
byte[] data = new byte[1024];
int read = -1;
while ((read = fsdis.read(data)) > 0) {
ps.write(data, 0, read);
fsdos.write(data, 0, read);
}
fsdis.close();
}
ps.close();
fsdos.close();
}
public static void main(String[] args) throws IOException {
MergeFile merge = new MergeFile(
"hdfs://master:9000/user/hadoop/",
"hdfs://master:9000/user/hadoop/merge.txt");
merge.doMerge();
}
}
打包后的jar文件

然后在本地建立相应文件并上传到hdfs系统中:
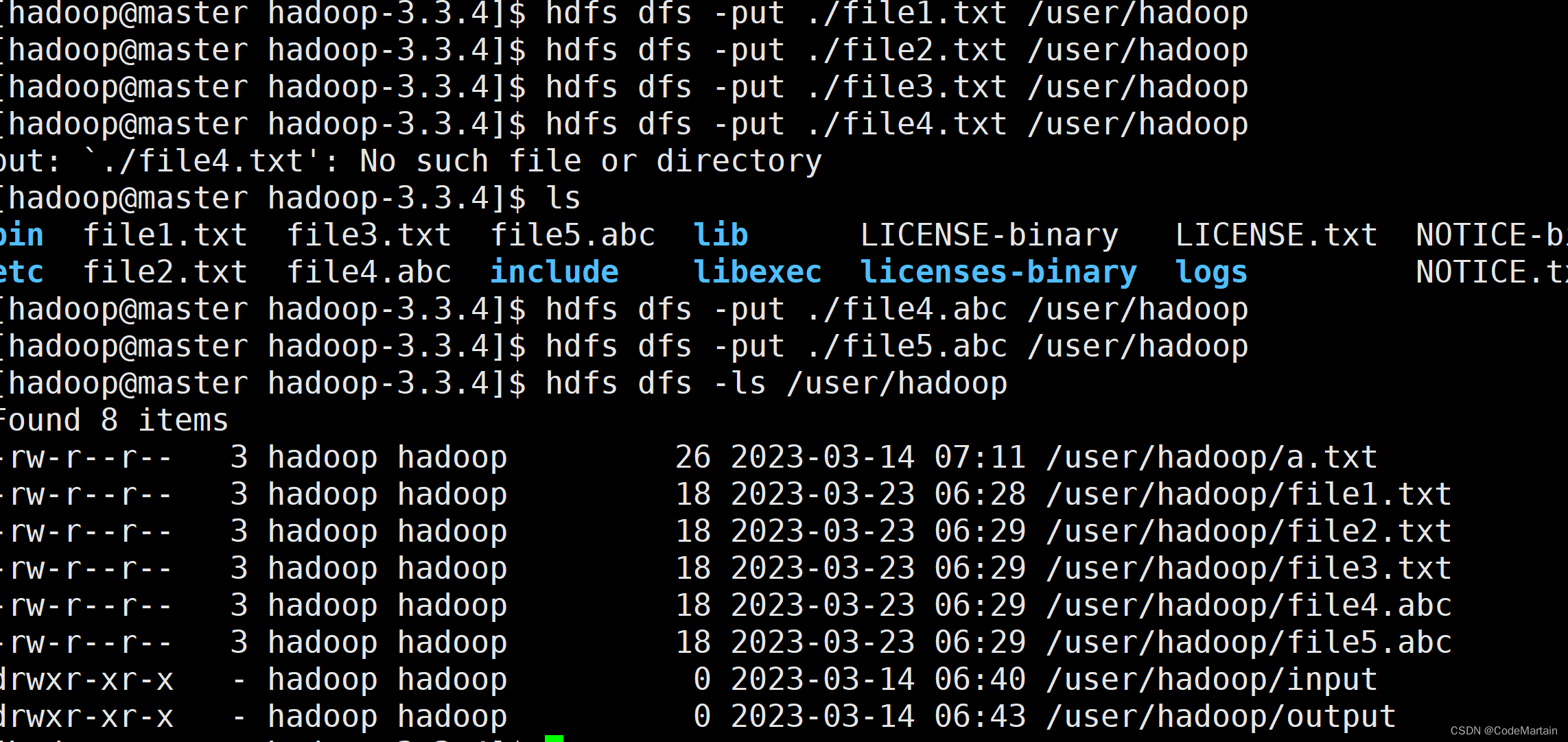
运行jar文件:

注意,运行前先检查一下是否有多余的文件,
否则会报错(因为代码未考虑其他文件)
[hadoop@master hadoop-3.3.4]$ hdfs dfs -ls /user/hadoop
Found 8 items
-rw-r--r-- 3 hadoop hadoop 26 2023-03-14 07:11 /user/hadoop/a.txt
-rw-r--r-- 3 hadoop hadoop 18 2023-03-23 06:28 /user/hadoop/file1.txt
-rw-r--r-- 3 hadoop hadoop 18 2023-03-23 06:29 /user/hadoop/file2.txt
-rw-r--r-- 3 hadoop hadoop 18 2023-03-23 06:29 /user/hadoop/file3.txt
-rw-r--r-- 3 hadoop hadoop 18 2023-03-23 06:29 /user/hadoop/file4.abc
-rw-r--r-- 3 hadoop hadoop 18 2023-03-23 06:29 /user/hadoop/file5.abc
drwxr-xr-x - hadoop hadoop 0 2023-03-14 06:40 /user/hadoop/input
drwxr-xr-x - hadoop hadoop 0 2023-03-14 06:43 /user/hadoop/output
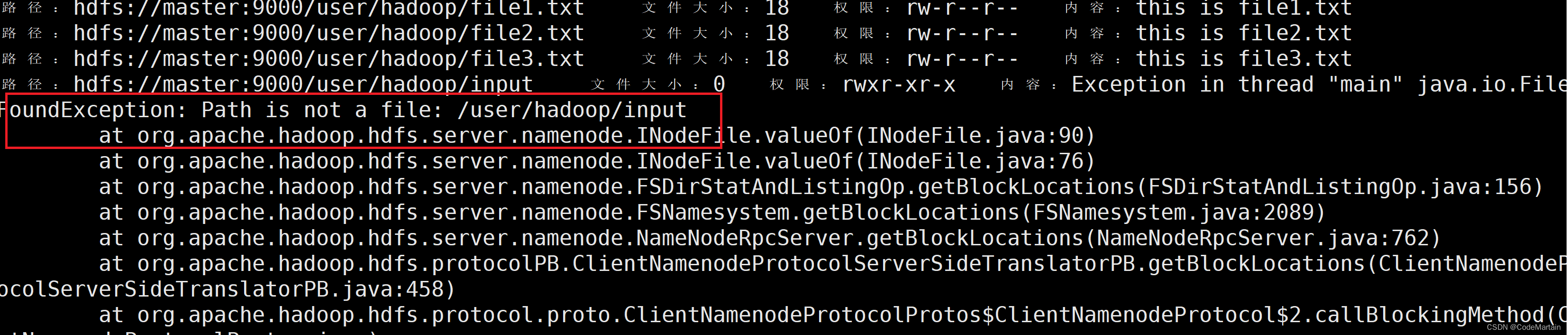
运行结束后查看是否生成了merge文件:

下面放几段常见的代码供学习参考:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
byte[] buff = "Hello world".getBytes(); // 要写入的内容
String filename = "test"; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println("Create:"+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class Chapter3 {
public static void main(String[] args) {
try {
String filename = "test";
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(filename))){
System.out.println("文件存在");
}else{
System.out.println("文件不存在");
}
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://localhost:9000");
conf.set("fs.hdfs.impl","org.apache.hadoop.hdfs.DistributedFileSystem");
FileSystem fs = FileSystem.get(conf);
Path file = new Path("test");
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}
}
以上代码的基本流程就是 先配置Configration,配置其属性HDFS地址以及其实现类,再然后读取文件的流程,再然后可以编写数据处理的逻辑;















 1557
1557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











