







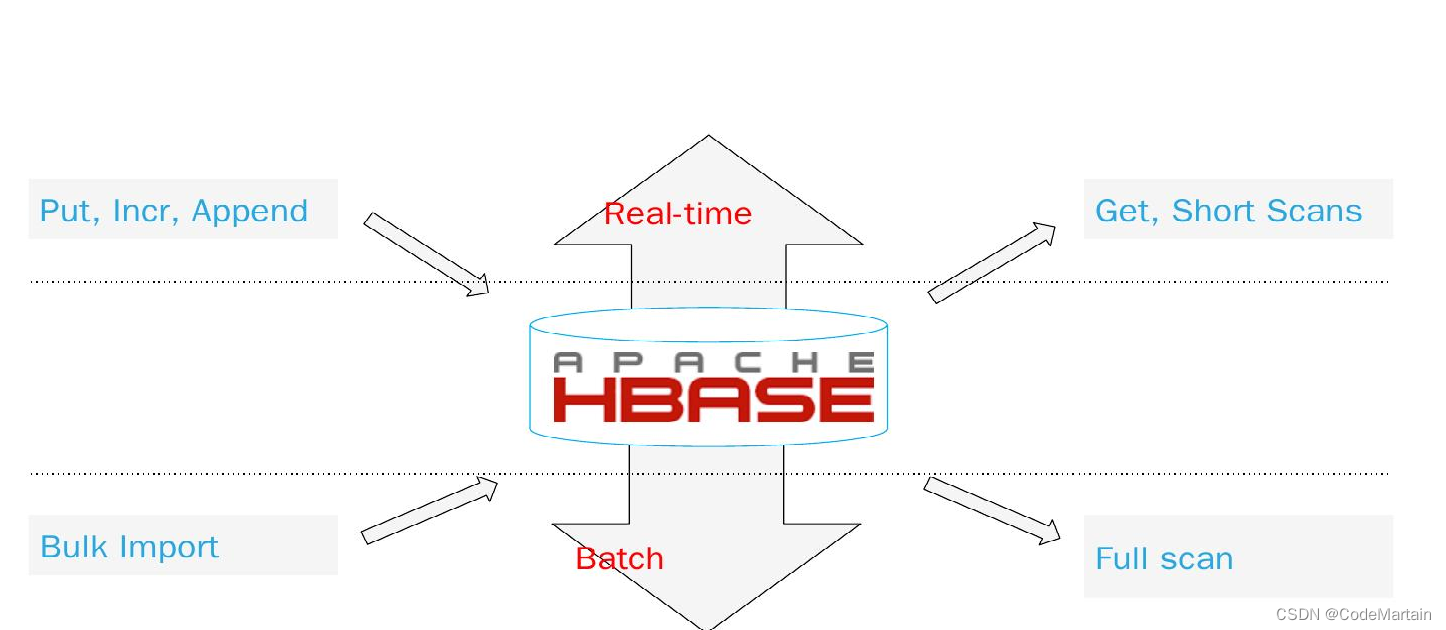
前段时间学习了Hbase的一些基础知识,下面学习一下Hbase在实际应用中的知识
Hbase性能优化方法
我们知道在Hbase存储中要存储行键,我们可以通过在行键上下功夫,
行键优化
比如时间靠近的数据都存在一起~ 按照时间戳 升序排列,随着时间的推移,后面的时间戳会越来越大,此时我们可以通过 long.max_value-timestamp的方式使得排序反过来;
提升读写性能:
设置HclumnDescriptor.setInMemory选项为true来使得相关的表放到Region服务器的缓存中,根据需要决定是否放入缓存;
节省存储空间:
设置最大版本数,如果只需要保留最新版本数,那么只需要设置保留版本数为1即可;
数据保留时常
通过设置TimetoLive参数使得数据一旦超过生命周期就成为了过期数据,系统会自动删除掉;
setTimetoLive=22460
Hbase集群的性能监控工具
自带的masterstatu~web界面的方式查询Hbase运行状态;
Ganglia,openTSDB可以从大规模集群中获取相关的性能参数,进行存储索引然后以可视化的方式提供给管理员;
Ambari
通过SQL语言与编写语句来实现Hbase的访问;
构建Hbase二级索引
Hbase数据库本身只支持对行键构建索引,对其他的列不支持构建二级索引,但是也是有办法实现的;
利用Hbase Coprocessor构建二级索引:
Hindex
endpoint 与observer,当数据插入数表时,会同步去写如数据到索引表;
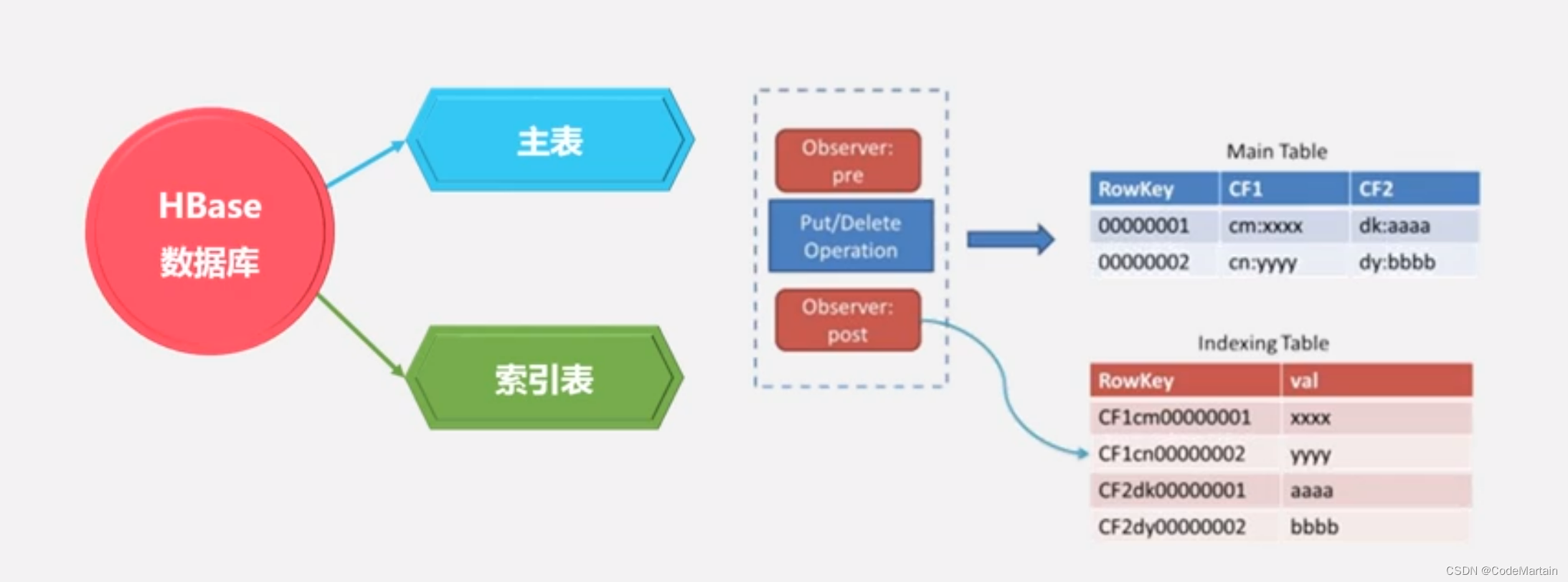
通过这种方式实现的工具主要有 Hindex(华为开发);
专门针对Hbase数据库开发,支持多个表的索引也支持多个列的索引,也支持基于部分列值的索引;
但是这会对机器的性能带来影响,每插入一条数据,就会向索引表插入数据,这回加大对IO的消耗;
Hbase+Redis组合方案
将索引数据先写入Redis,然后再写入Hbase中
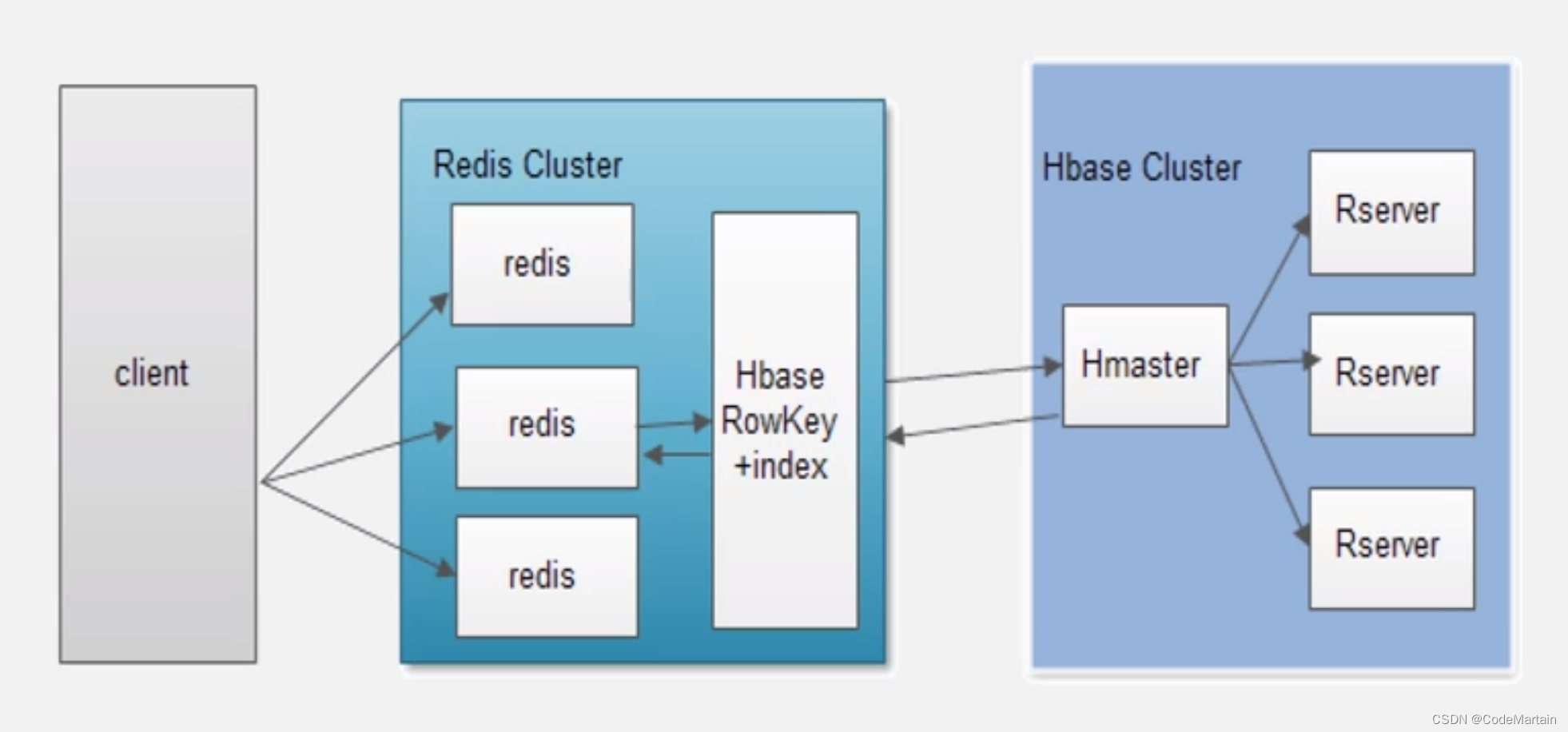
通过定期写入的方式来避免频繁更新索引带来的IO问题
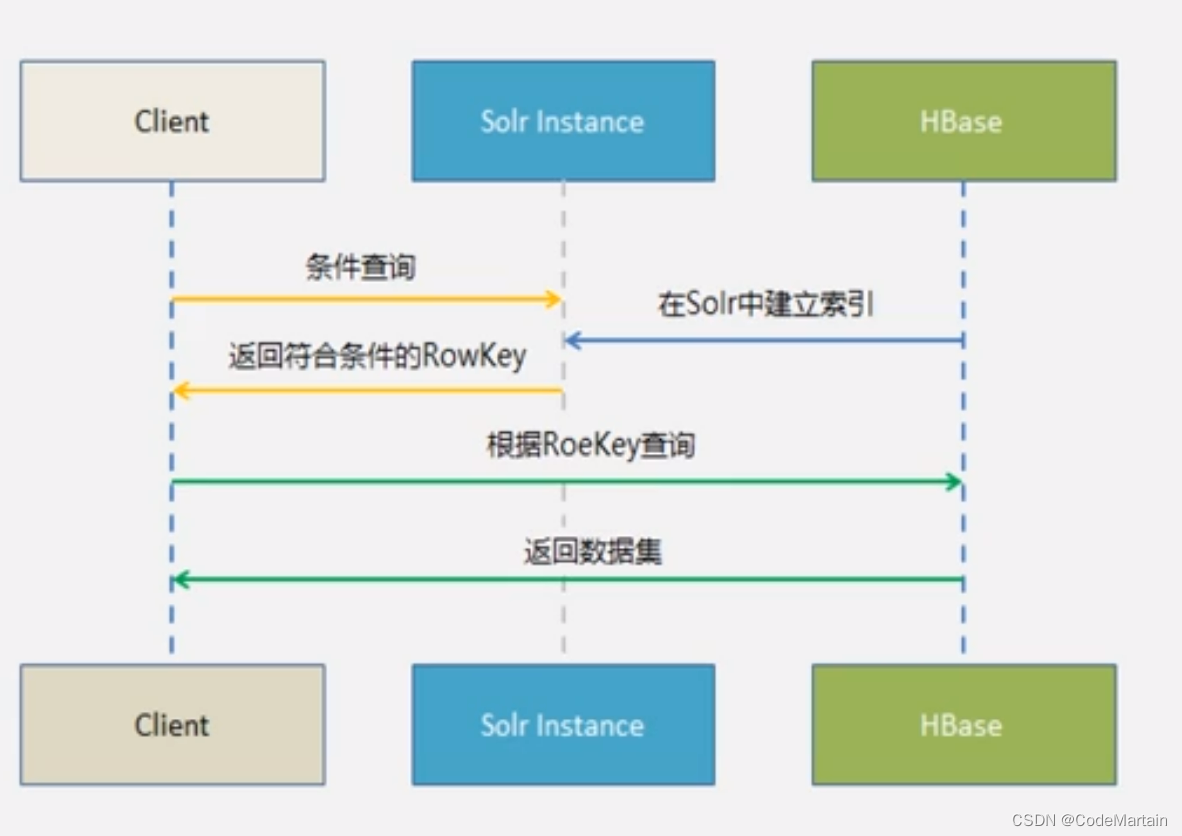
Hbase+Solr
通过solr实现全文搜索,通过solr构建其其他列和行键之间的对应关系
Hbase的安装与使用
Hbase的运行有三种模式:单机伪分布式,分布式;
单机模式:在一台计算机上安装和使用Hbase,不涉及数据的分布式存储;
伪分布式模式:在一台计算机上模拟一个集群;
分布式模式:使用多台计算机实现物理意义上的分布式存储;
安装Hbase
下载Hbase
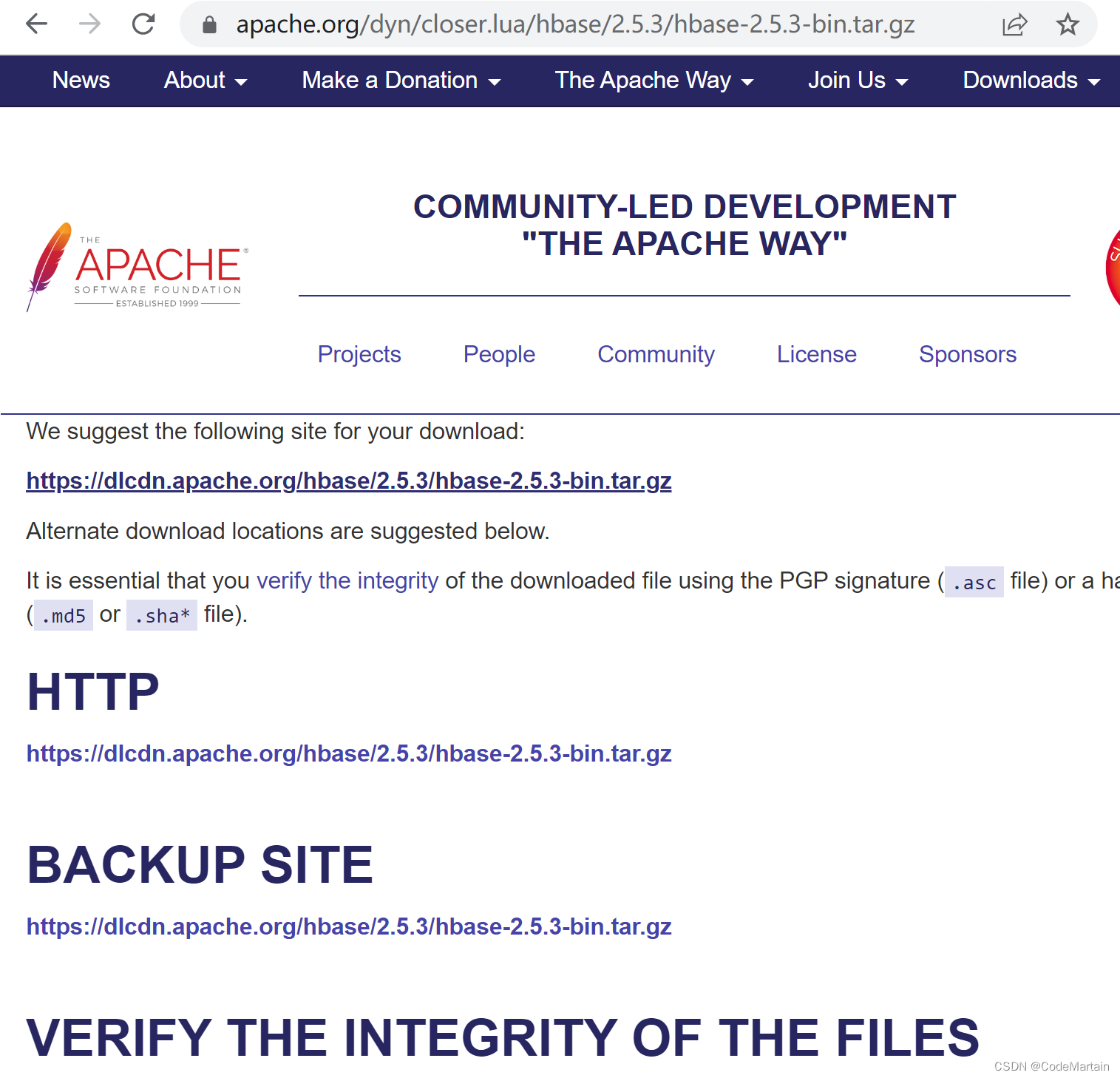
选择合适的版本下载即可;
注意在安装hbase之前要安装Hadoop,否则…你懂的
下载之后解压缩~
tar -zxf hbase-2.5.3-bin.tar.gz
将解压后的文件夹授予hadoop用户权限:
[root@master local]# chown -R hadoop hbase
[root@master local]# chmod 700 hbase
配置环境变量

看一下hbase文件夹下的bin~
检查hadoopde的环境变量:
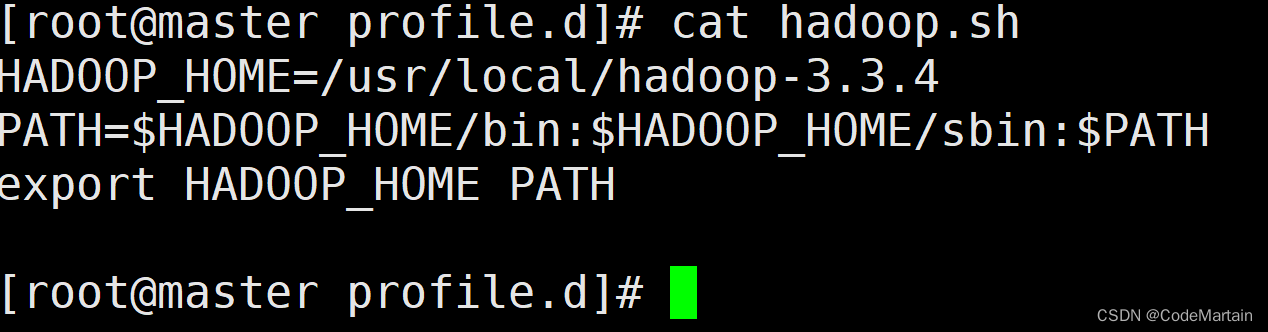
配置hbase环境变量结束后 source hadoop.sh使得用户的环境变量生效;

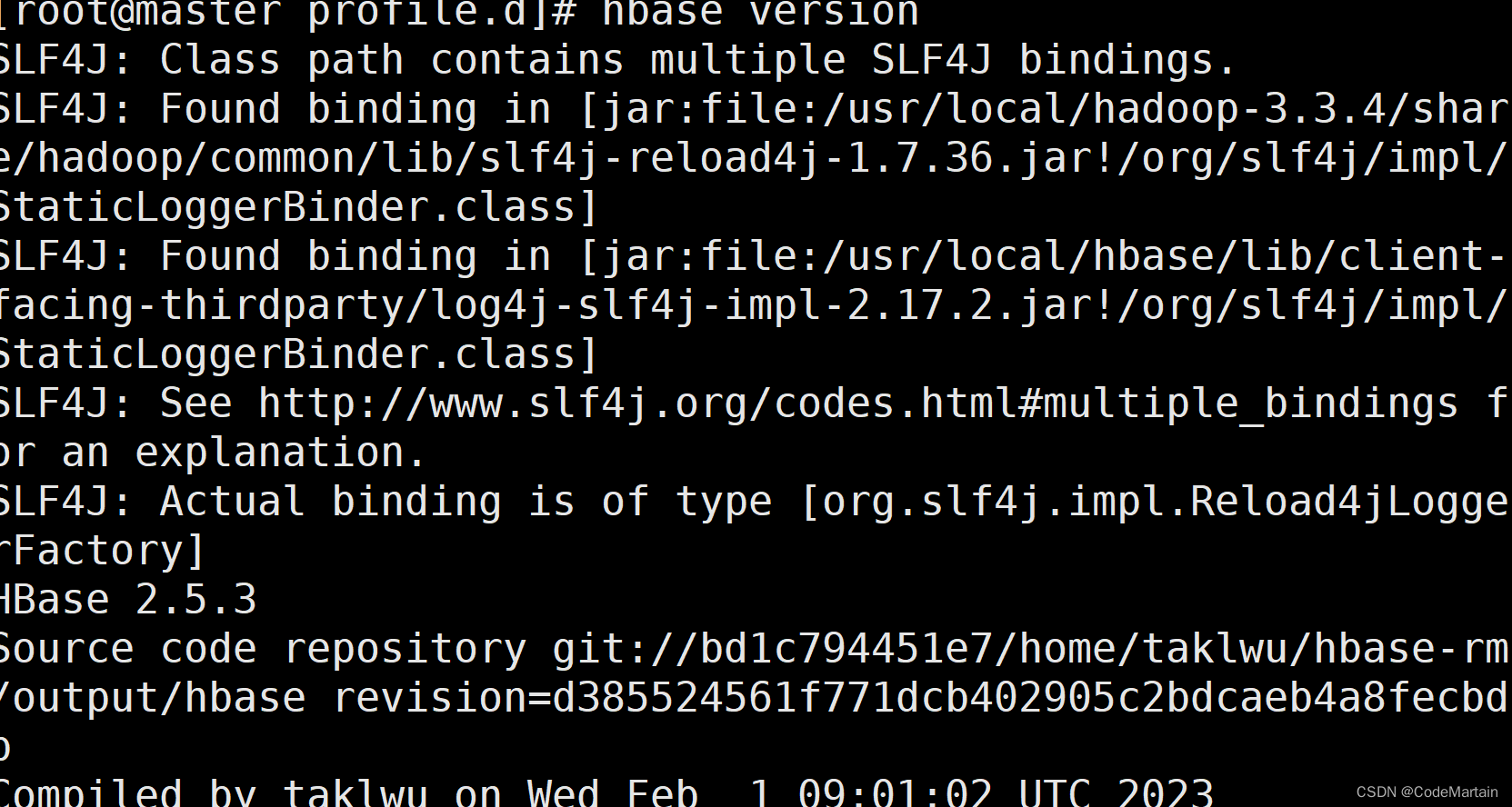
查看hbase版本
hbase version
单机模式配置
编辑hbase-env.sh
配置java环境变量参数:
vi hbase-env.sh
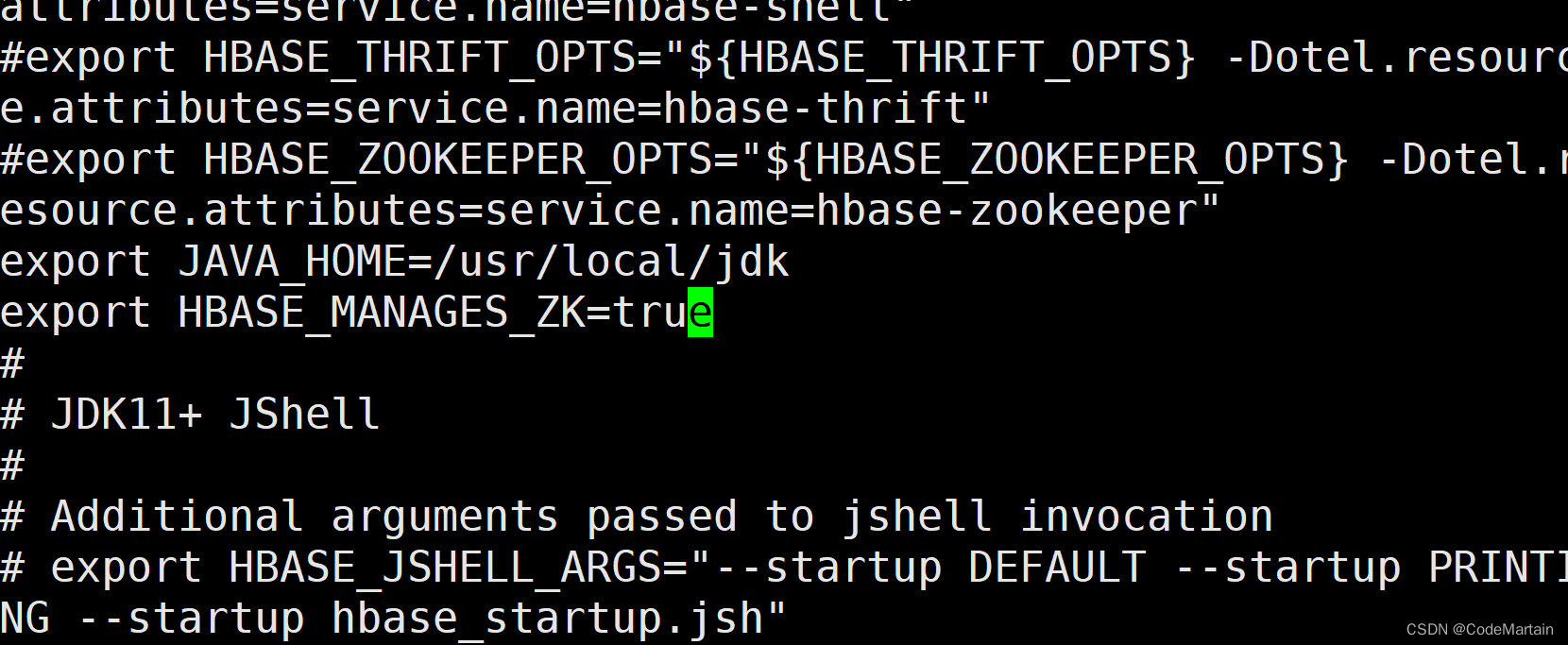
配置结束hbase的JAVA环境变量之后,添加配置HBASE_MANAGES_ZK为true,这表示让hbase自己管理zookeeper,不需要单独的zookeeper
编辑hbase-site.xml
设置数据的存储位置,如果不设置的话,每次重启数据就会丢失;

编辑以上配置文件之后,启动hbase试一下
start-hbase.sh
检查进程是否存在:

如果启动失败,可以通过查看日志文件来看一下发生了什么问题:
停止hbase
stop-hbase.sh
伪分布式模式配置
配置hbase环境配置文件:
vim /usr/local/hbase/conf/hbase-site.xml
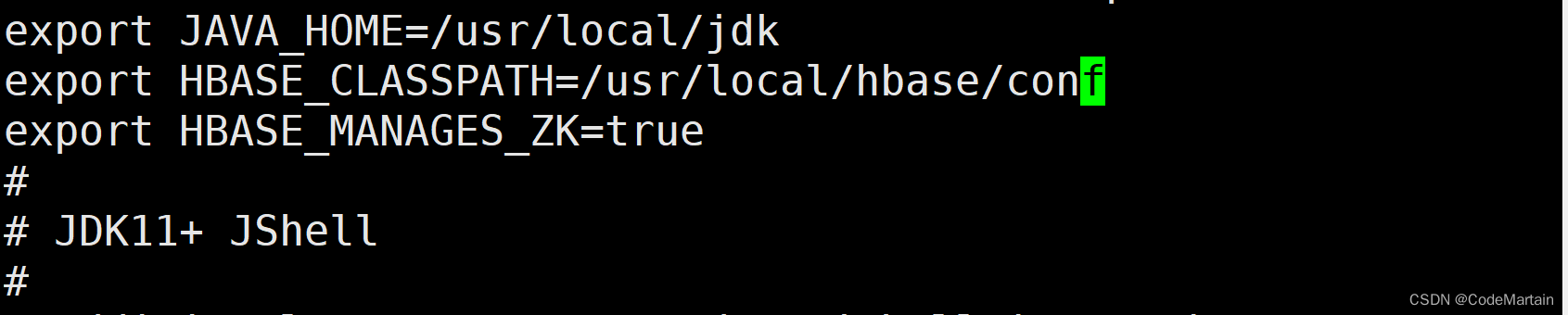
在单机版本的配置基础上添加了hbase的配置文件目录
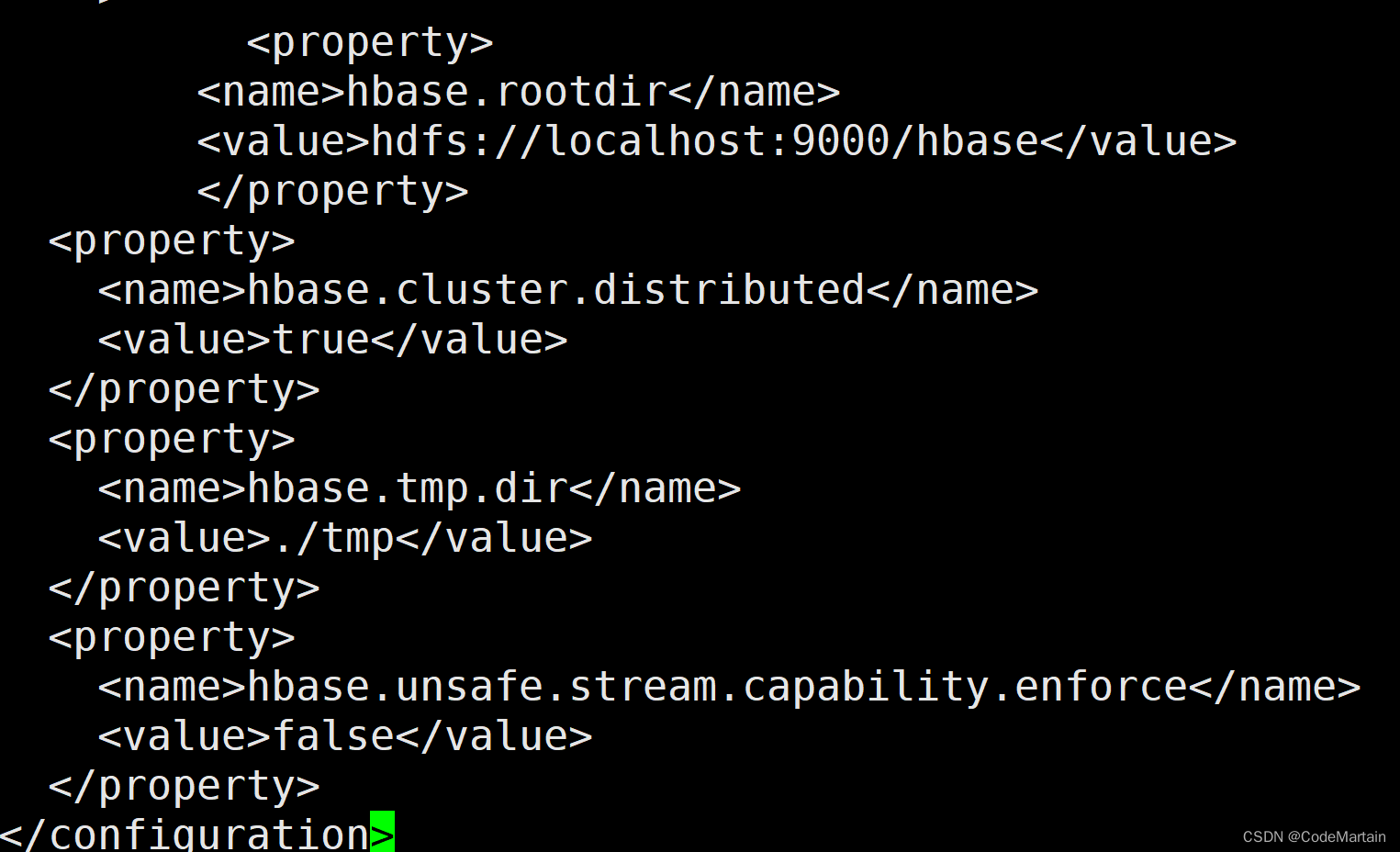
修改hbase的rootdir,指定hbase数据在HDFS上的存储路径;
将属性hbase.cluster.distributed设置为true,即设置集群处于分布式模式
上面配置文件中,hbase.unsafe.stream.capability.enforce这个属性的设置,是为了避免出现启动错误。也就是说,如果没有设置hbase.unsafe.stream.capability.enforce为false,那么,在启动HBase以后,会出现无法找到HMaster进程的错误
ERROR [master/localhost:16000:becomeActiveMaster] master.HMaster: Failed to become active master
java.lang.IllegalStateException: The procedure WAL relies on the ability to hsync for proper operation during component failures, but the underlying filesystem does not support doing so. Please check the config value of 'hbase.procedure.store.wal.use.hsync' to set the desired level of robustness and ensure the config value of 'hbase.wal.dir' points to a FileSystem mount that can provide it.
接下来启动hbase:
启动之前先启动一下hadoop:
启动的步骤~
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
启动hbase~
start-hbase.sh
启动之后查看进程
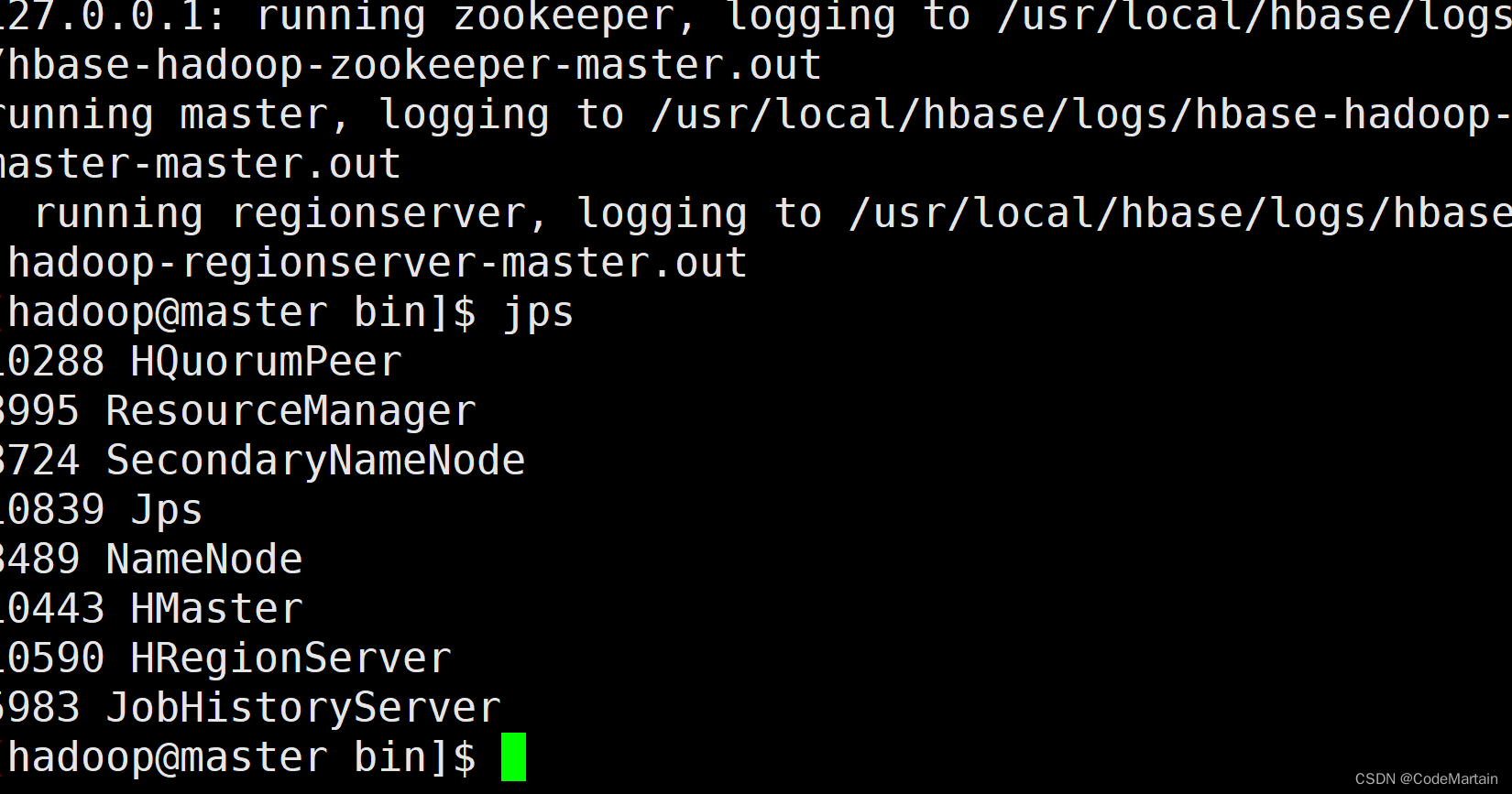
如果遇到hbase启动失败,报zookeeper链接失败,那可能是hbase所在文件夹的权限问题,授予用户hadoop权限,同时设置一下hbase所在文件夹的权限为700;
接下来就是见证时刻的奇迹~
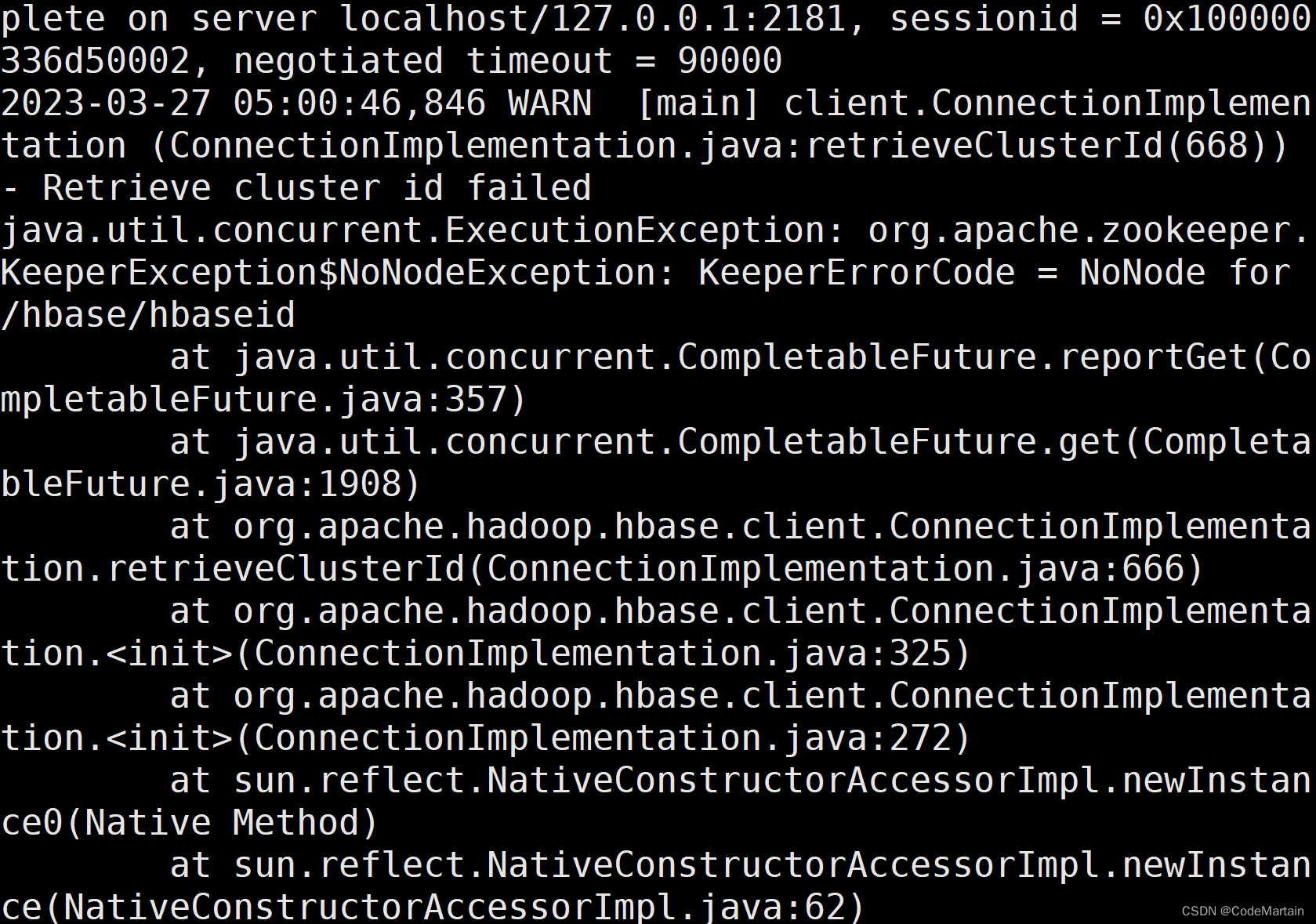
没错报错了,就是这么尴尬;
检查一下配置文件:
没什么问题~这里不再展示,这里停止habse的运行:
stop-hbase.sh

如果停止的过程很慢很慢,那么可以尝试下面的操作:
先停止master的守护进程
hbase-daemon.sh stop master
stop-hbase.sh
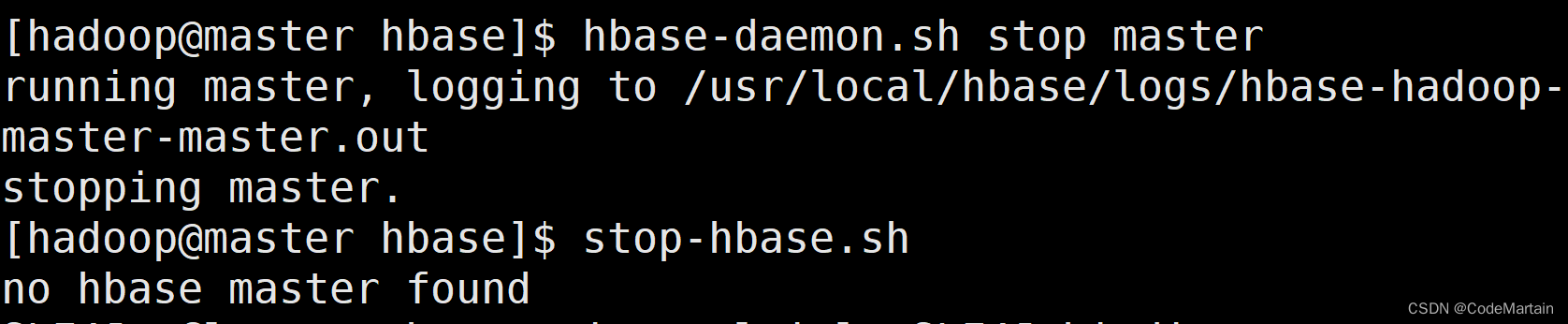
停止之后,我才发先其他节点上没有hbase文件,于是拷贝到各个节点上;
将hbase文件分别复制到各个节点上
进入hadoop的目录开启hdfs
启动hadoop,启动hbase
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
start-hbase.sh
检查启动的进程
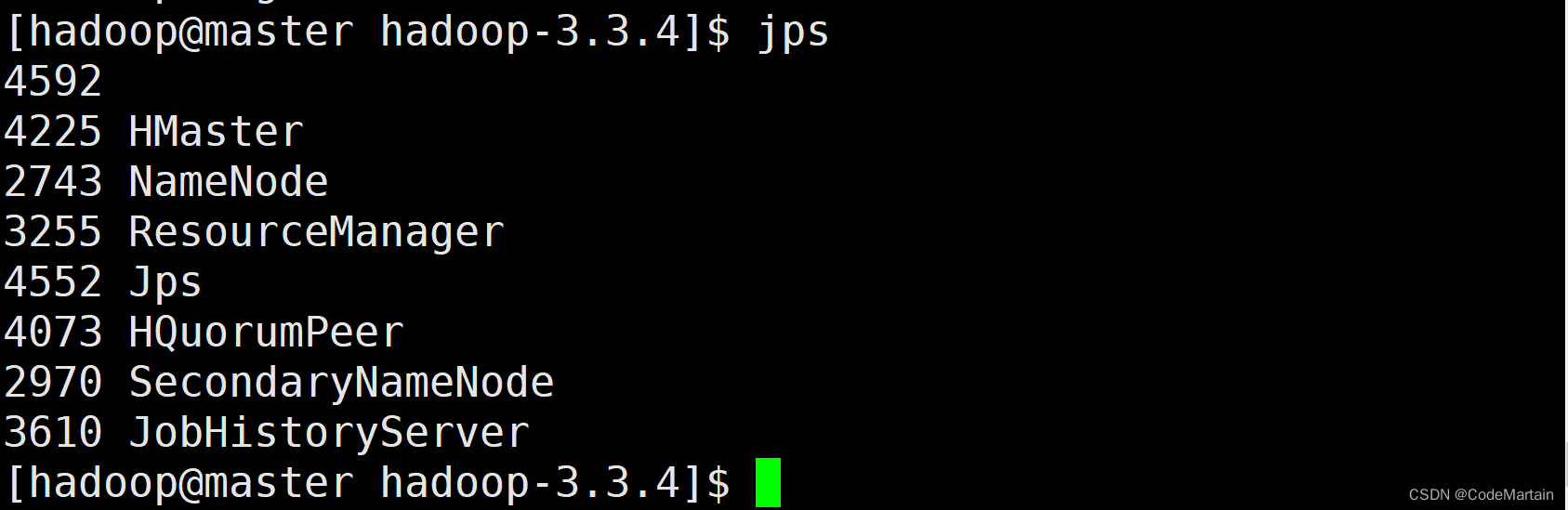
启动成功:
分布式模式
在伪分布式模式的基础上改动了一下配置文件
1,将hbase-env.sh中的下面这个注释给放开
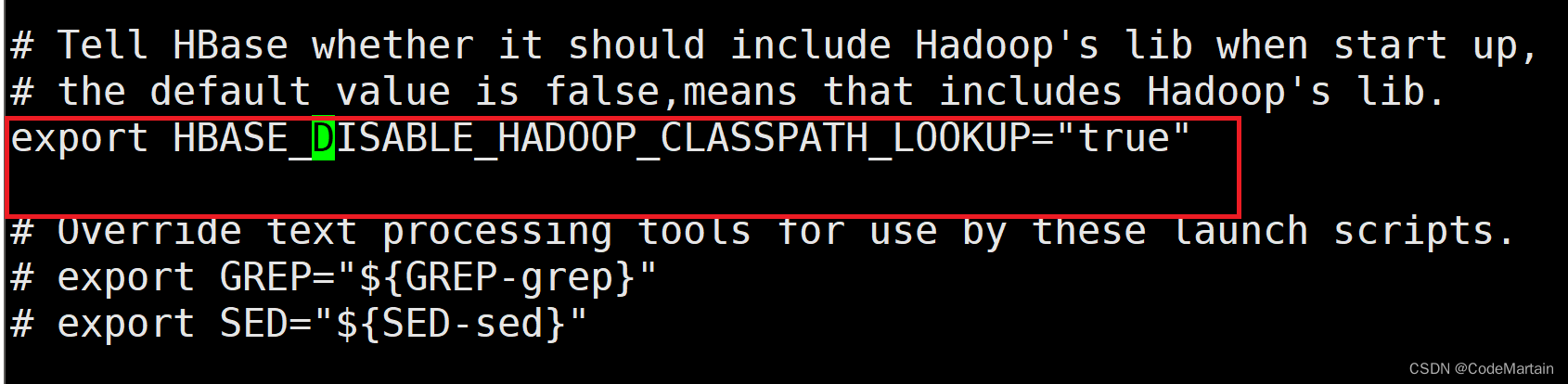
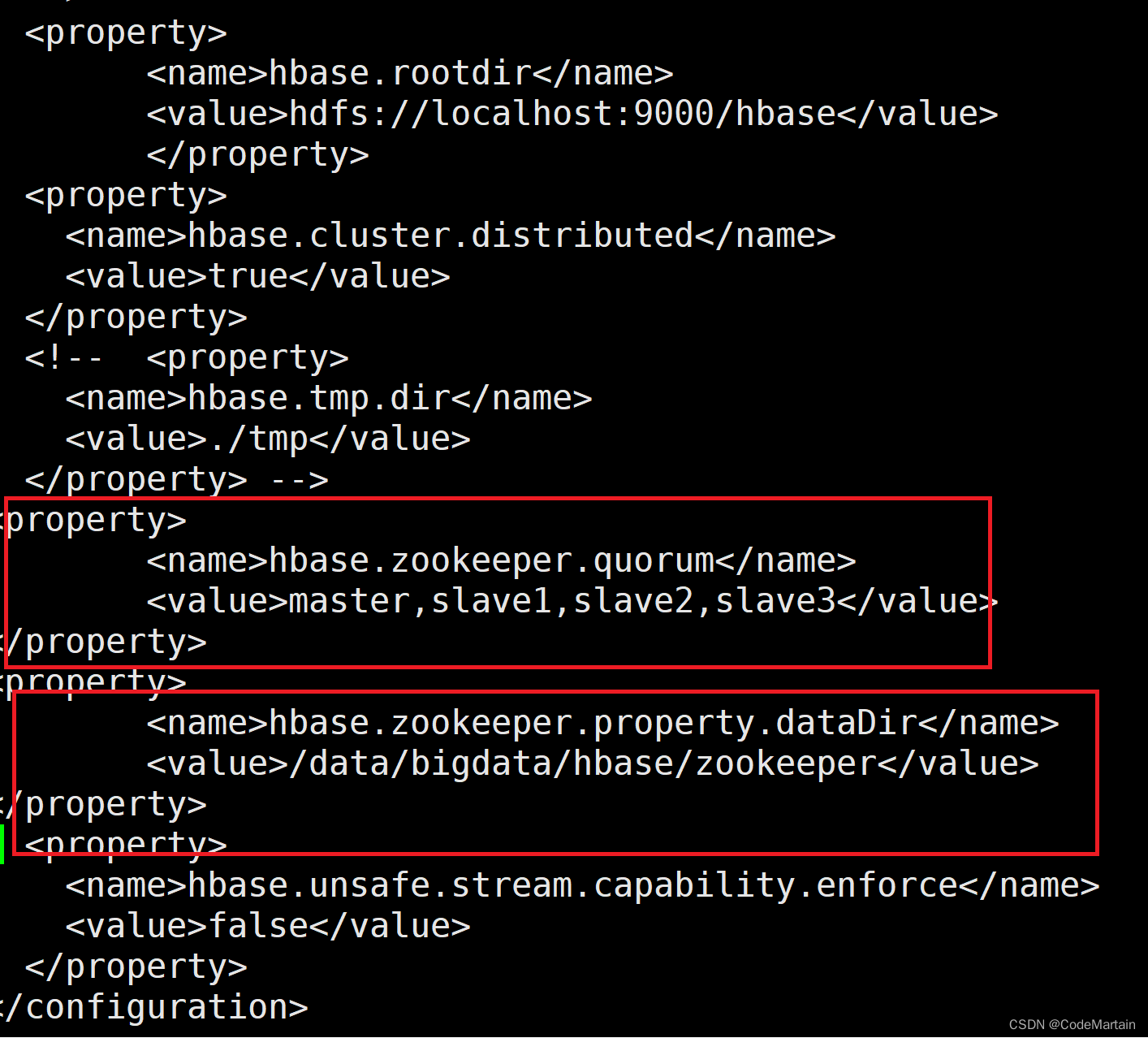
2,配置节点以及zookeeper配置信息
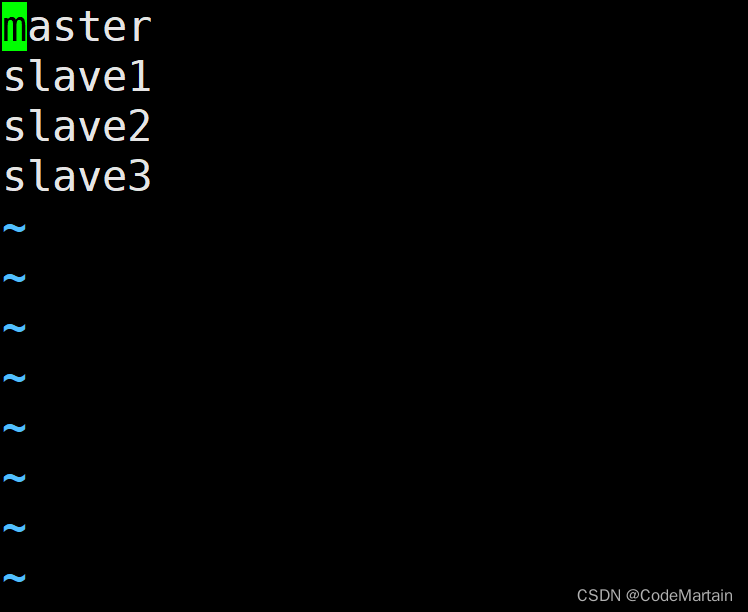
3,编辑区域服务器信息~ vi regionservers
最后启动hbase服务(注意此前已经启动了hadoop)
接着就是在hbase中创建表了
















 952
952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











