







前言
随着时代的更新交替,人工智能领域出现在人们生活的场景越来越多,人工智能专业也越来越火爆,可是作为普通人的我们,该怎样学习人工智能这个方向,它真的很难吗?下面请跟着我的介绍,来看一看机器学习下的KNN算法吧。
一、KNN是什么?
KNN是一种用于解决分类问题和回归问题的最常见的方法,虽然它很平凡,但是它的功能很强大。学习一个算法最好的方法便是通过案例来加深我们对它的印象。下面开始吧!
二、实例引入
1.问题描述
在我们生活里有已经划分好种类的数据,它们分类的依据是根据各自的特性,比如尺寸、形状、大小等等特征,但是当一个新的东西出现时,我们应该怎么判断它的种类?
代码如下(数据集可视化):
# 这是已知的数据和种类
import numpy as np
import matplotlib.pyplot as plt
# 样本数据
data_X = [
[1.3, 6],
[3.5, 5],
[4.2, 2],
[5, 3.3],
[2, 9],
[5, 7.5],
[7.2, 4],
[8.1, 8],
[9, 2.5]
]
# 样本特征
data_y = [0,0,0,0,1,1,1,1,1]# 训练集
X_train = np.array(data_X)
y_train = np.array(data_y)
# 图像呈现
plt.scatter(X_train[y_train == 0,0],X_train[y_train == 0,1],color='red',marker='o')
plt.scatter(X_train[y_train == 1,0],X_train[y_train == 1,1],color='black',marker='x')
plt.show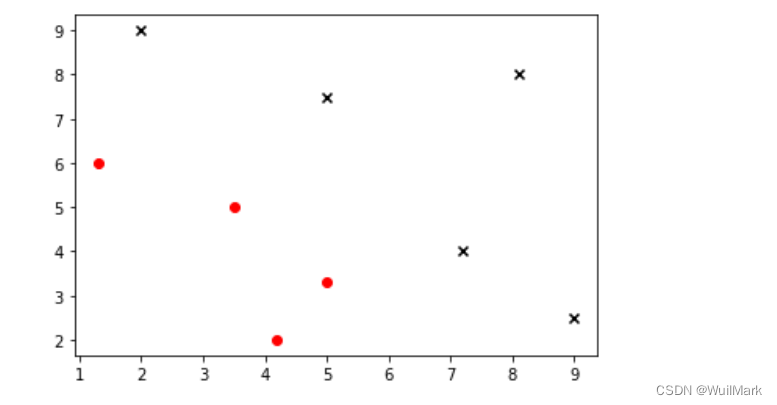
2.观察图像
通过图像我们可以明显看出来,给出的数据点有明显的两类,它们分布大致成两块。
3.问题引入
此刻,有一个位置的点(4,5),我们想判断它是属于红色部分还是蓝色部分,该怎么判断呢?
三、算法原理和核心思想
1.算法原理
KNN分类的基本原理有以下几条:
1.“近朱者赤,近墨者黑”(最重要的!!!)
这句话的意思是,靠近哪一个就属于哪一类,也就是knn的核心思想。
2.k个最近的邻居
这里的k是我们自己定义的,k也就是说在未知点的周围一次取k个点,将它看作该点的邻居。
3.投票制度
这里的投票制度是说,我们根据上面k个邻居中的种类个数,采取“少数服从多数”即投票制度,来将未知划分为多数的那一类。
2.核心问题
问题1:如何选择K值?
对于一个值的问题,我们将它分成三种情况即过大、过小、合适。
过大:K太大,会出现“欠拟合”的现象,所谓的“欠拟合”,就是拟合效果不好,就好比一个人买裤子,他买的裤子特别的大,会让他的腿显得特别臃肿,会导致决策率很低。
过小:K过小,会出现“过拟合”,所谓的“过拟合”,用一种极端的比喻,就是在这个位置点周围,我只取K=1,也就是一个点,我根据这一个点来判断位置点的种类,这样得到的结果误差太大,不具有说服力。
我们最希望取的K值是最合适的,因为这样的拟合效果最好,得到的结果也是最有说服力的。
问题2:怎样确定数据与数据间的量度?
这里主要采用的是距离公式,常见的距离公式已经放在下方。
二维空间距离公式(欧氏距离)
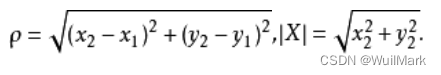
三维空间距离公式
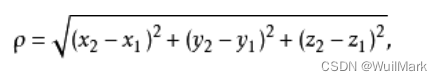
还有等等的距离公式,根据情况选择合适的公式来使用。
四、实战演示
将位置的点在之前的图像上面呈现:(代码如下)
# 要检测的测试点
data_new = np.array([4,5])
plt.scatter(X_train[y_train == 0,0],X_train[y_train == 0,1],color='red',marker='o')
plt.scatter(X_train[y_train == 1,0],X_train[y_train == 1,1],color='black',marker='x')
plt.scatter(data_new[0],data_new[1],color='blue',marker='^')
plt.show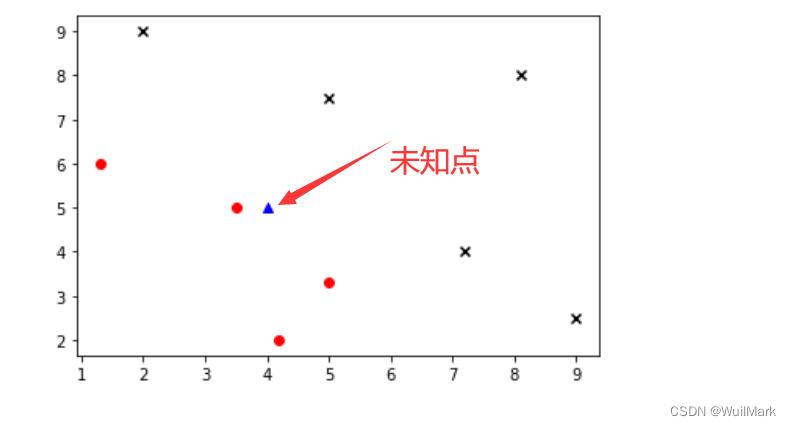
1.计算新样本点与已知样本点的距离
distances = [np.sqrt(np.sum((data-data_new)**2)) for data in X_train ]
distances
2.距离排序
sort_index = np.argsort(distances)
sort_index
3.确定k值
k = 54.距离最近的k个点 投票结果
first_k = [y_train[i] for i in sort_index[:k]]
first_k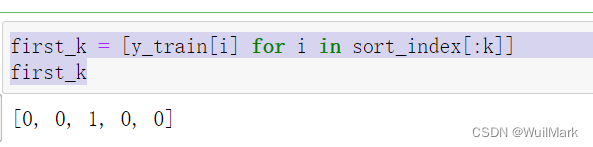
五、总结分析
根据上述训练集,我们通过四步走的方法,得到最终结果,因为在k=5的情况下,投票“0”的人数最多,有4个人,而投票“1”的仅有1个人,所以我们将未知点划分为0这一类,这也就是KNN算法的应用。
通过上述,我们可以了解到KNN的用途,以及它的强大,上面的步骤是我们一步一步来写的,回到现在,我们可以站在巨人的肩膀上,别人已经为我们封装好了这个KNN的库,我们只需要调用库函数传参即可完成KNN算法。
科技的力量(scikit-learn中的KNN算法)
from sklearn.neighbors import KNeighborsClassifier
knn_classifier = KNeighborsClassifier(n_neighbors=5)
knn_classifier.fit(X_train,y_train)
knn_classifier.predict(data_new.reshape(1,-1))
六、展望
我是一个刚刚开始机器学习的小白,希望我的讲解能够帮助到有需要的人,如果有不足的地方,还请大家多多谅解,有建议可以发表在评论区。还请大家多多支持,我会持续更新的谢谢!
长风破浪会有时,直挂云帆济沧海!















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









