







K-最近邻算法
引入:是不是鸭子?
“如果走像鸭子,叫像鸭子,看起来还像鸭子,那么它很可能就是只鸭子。”
上面这句谚语可以这样理解,将“走”、“叫”,“看”刻画成三个维度:“走路姿态”、“声音”、“外观”,已知的每个样例(是否是鸭子)都是三维空间的一个点,现在有一个测试样例,如果它的“走路姿态”、“声音”、“外观”与数据点中k个“是鸭子”类别近似(邻近)那么就认为该点代表的测试样例“是鸭子”。
这样就得到了最近邻分类的概念:如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。
也就是我们常听到的“近朱者赤,近墨者黑”的思想。
案例为本的学习(Case based learning)——惰性学习
KNN最近邻算法是数据挖掘中最基本的一个学习算法,它甚至不是一种可以进行自身学习的方法,只是机械的进行距离的计算。因为他是基于检验样本和已知的训练样本距离的计算称案例为本的学习,同时它也是一种惰性学习方法。
惰性学习法(lazy learner)简单地存储给定训练元组,直到等待给定一个检验元组时才进行泛化,以便根据与已储存的训练元组的相似性进行分类或数值预测。
对于分类问题,根据“少数服从多数”的原则判断类别;对于数值预测问题,用“求平均”的方法进行预测。
KNN的原理
KNN的原理就是将需要分类的数据与训练数据相比对,在事先指定的范围内(K的数量)找到与测试数据距离最近的k个邻居,根据它的类别判断测试样本的类别。
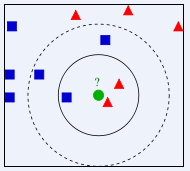
如上图,已有分好的三类训练样本,对于给定的新的测试样本:未知类别的绿色圆,通过计算最相似的K数据的类别确定新测试样本的类别。
若K=3,此时和它最相似(邻近)的三个样本中有两个是红三角,一个蓝方形,此时根据“多数表决”未知样本是“红三角”;
若K=5,此时和它最邻近的五个样本中3个蓝方块,2个红三角,此时未知样本是“蓝方块”。
相似性的度量
数据预处理
根据上面所说的概念和原理,一个很重要的问题就是相似性的度量,即距离的计算,然而影响距离的一个很重要的因素是数据的量纲。比如数据的两个维度是:年龄、收入。若收入以元做单位,此时变量数量级差别较大,分类结果容易受收入主导而弱化了年龄这个特征。
因此,在进行KNN算法之前,需要对数据进行预处理以消除量纲。
均值规范化
x
s
c
a
l
e
=
x
−
x
‾
s
x_{scale}=\frac{x-\overline x}{s}
xscale=sx−x其中
x
‾
\overline x
x为样本均值,
s
s
s为样本方差。规范化后的数据服从均值为0标准差为1的标准正态分布。
但是由于其取值的99%都在[-3,3]范围中,涉及到负值,而有些算法希望取值在0-1之间,因此还有下面的极值正规化的方法。
0-1规范化
x
s
c
a
l
e
=
x
−
x
m
i
n
x
m
a
x
−
x
m
i
n
x_{scale}=\frac{x-x_{min}}{x_{max}-x_{min}}
xscale=xmax−xminx−xmin规范化后的数据取值在0-1之间,具有良好的性质。
例:下面图片为年龄和收入的数据,求其极值正规化后的结果。

易得,上述数据中imcome最小为:20000,最大为:60000;年龄最小为20,最大为50。
以年龄25000为例,
x
s
c
a
l
e
=
x
−
x
m
i
n
x
m
a
x
−
x
m
i
n
=
25000
−
20000
60000
−
20000
=
0.125
x_{scale}=\frac{x-x_{min}}{x_{max}-x_{min}}=\frac{25000-20000}{60000-20000}=0.125
xscale=xmax−xminx−xmin=60000−2000025000−20000=0.125得到以下结果:

距离计算
- 闵可夫斯基距离(Minkowski Distance)
d i j = λ ∑ k = 1 n ∣ x i k − x j k ∣ λ d_{ij}=\lambda \sqrt{\sum_{k=1}^n|x_{ik}-x_{jk}|^\lambda} dij=λk=1∑n∣xik−xjk∣λ 其中 λ \lambda λ可以随意取值。 - 曼哈顿距离
d i j = ∑ k = 1 n ∣ x i k − x j k ∣ d_{ij}=\sum_{k=1}^n|x_{ik}-x_{jk}| dij=k=1∑n∣xik−xjk∣ - 欧氏距离
d i j = ∑ k = 1 n ( x i k − x j k ) 2 d_{ij}=\sqrt{\sum_{k=1}^n(x_{ik}-x_{jk})^2} dij=k=1∑n(xik−xjk)2
继续根据上述标准化以后的两个样本点ID=3,和ID=6计算距离(相似度),选择欧式距离,有: d 3 , 6 = ( 0.5 − 0.13 ) 2 + ( 0.83 − 0.33 ) 2 = 0.622 d_{3,6}=\sqrt{(0.5-0.13)^2+(0.83-0.33)^2}=0.622 d3,6=(0.5−0.13)2+(0.83−0.33)2=0.622
对于给定新的测试样本,和刚才一样与每一个训练样本计算距离得到最近的K个样本点的类别(或数值),再对类别进行多数表决(对数值求平均)。
算法步骤及实例计算

记K为最近邻数、D为训练样例集合。
(1)对每个测试样例
z
=
(
x
′
,
y
′
)
z=(x',y')
z=(x′,y′)计算其与每个训练样本之间的距离d(x’,x);
(2)选择距离k个训练样本点最近的训练样例的集合
D
z
D_z
Dz
(3)根据多数表决
y
′
=
a
r
g
m
a
x
v
∑
(
x
i
,
y
i
)
∈
D
z
I
(
v
=
y
i
)
y'=argmax_v\sum_{(x_i,y_i)\in D_z}I(v=y_i)
y′=argmaxv∑(xi,yi)∈DzI(v=yi),其中v为类标,
y
i
y_i
yi是最近邻的类标号,I(·)是示性函数。
假设新的数据点为Age=20,Income=30000
S
t
e
p
1
′
Step 1'
Step1′数据标准化:
x
a
g
e
=
x
−
x
m
i
n
x
m
a
x
−
x
m
i
n
=
0
x_{age}=\frac{x-x_{min}}{x_{max}-x_{min}}=0
xage=xmax−xminx−xmin=0
x
i
n
c
o
m
e
=
x
−
x
m
i
n
x
m
a
x
−
x
m
i
n
=
0.25
x_{income}=\frac{x-x_{min}}{x_{max}-x_{min}}=0.25
xincome=xmax−xminx−xmin=0.25
S
t
e
p
2
′
Step 2'
Step2′新测试样本和训练样本距离欧式计算:
| 测试样本和每个训练样本 | 距离(保留两位小数) |
|---|---|
| 1_new | 0.25 |
| 2_new | 1.01 |
| 3_new | 0.35 |
| 4_new | 0.53 |
| 5_new | 1.03 |
| 6_new | 0.87 |
S
t
e
p
3
′
Step 3'
Step3′根据K的值进行分类(多数表决)
取K=3,此时和测试样本最邻近的样本点有1、3、4。其中标签为两个“B”,一个“G”,根据多数表决原则,新测试样本标签为“B”。
KNN的优缺点
- 优点:
- 原理简单、容易实现。
- 使用和具体的训练实例进行预测,不必维护源自数据的模型(无须建模)
- 决策边界更加灵活
- 缺点:
- 分类测试集样例时的开销较大
- K值选取不易,K较大时容易忽略重要模式;K较小时容易受到噪声影响。
代码
KNN手写上述例子:☞代码请戳☜
参考文献
《数据挖掘导论》
CDA建模考试大纲解析















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









