







论文链接:
https://arxiv.org/pdf/1606.07792.pdf
一.论文背景
由于较少的特征工程,深度神经网络可以通过学习稀疏特征的低维密集嵌入来更好地泛化不可见的特征组合。然而,当用户与物品之间的交互是稀疏的、高秩的时,带有嵌入的深度神经网络会过度泛化并推荐相关度较低的物品。
1、“wide”类型的模型:一种浅层模型。它通过大量的单层网络节点,实现对训练样本的高度拟合性。利用cross-product方式进行特征交叉产生的特征具有很好的效果和很好的可解释性,但是需要较强的经验知识进行特征工程。泛化能力差。
2、“deep”类型的模型:一种深层模型。它通过多层的非线性变化,使模型具有很好的泛化性。通过将稀疏特征转换为稠密特征从而进一步挖掘高阶的特征组合,这种方式在用户-商品对比较稀疏的情况下,具备较强的泛化能力,可能给用户推荐不太相关的商品。拟合度欠缺。
3、为了进一步结合两者的优势,文章提出了一种全新的deep&wide网络结构。
二.推荐系统概述

当用户访问应用商店时,会生成一个查询(query),其中可以包含各种用户和上下文特征。推荐系统会返回一个应用列表(items),用户可以在该列表上进行点击或购买等操作(user Actions)。这些用户操作,连同查询和印象,作为学习者的训练数据记录在日志中(logs)。由于数据库中有超过100万个应用程序,所以很难在服务延迟要求(通常是o(10)毫秒)内,为每个查询都对每个应用程序进行详尽的评分。因此,接收到查询的第一步是检索(Retrieval)。检索系统使用各种信号(通常是机器学习模型和人类定义的规则的组合)返回与查询最匹配的条目的简短列表。在减少候选池后,排名系统将根据所有项目的得分对其进行排名(Ranking)。
所以有两个操作:
召回:从全部商品中选出一个和用户最匹配的候选集,这个候选集的规模是远小于全部商品集;
排序打分:筛选出候选集之后就这部分商品传递给排序模块进行排序打分,最终将得分Top的商品展现给用户。
三.Wide&Deep模型
3-1.Wide部分

输入特征包括两部分,一部分是原始的输入特征,另一部分是cross-product transformation叉积变换,公式如下:

是一个布尔变量,如果第i个特征是第k个变换的一部分,则为1,否则为0。
3-2.Deep部分

Deep部分简单理解就是Embedding+MLP这种非常普遍的结构,随着近几年深度学习在推荐系统中的大规模应用,Embedding+MLP这种网络结构基本成为了标配,中间隐藏层的激活函数都是ReLu,最后一层的激活函数是sigmoid。

网络的训练方式采用的是联合训练,并不是单独的训练两部分网络,然后在预测的时候在一起使用,而是直接在训练阶段就同时训练两部分的网络参数。这种联合训练的方式有两个好处:一方面联合训练同时训练两部分网络的参数更有利于整体的最优化;另一方面联合训练可以有效降低整个网络的大小。在训练的过程中,wide部分主要采用带L1正则的FTRL算法进行优化,deep部分采用AdaGrad进行优化。
四、系统部署与应用
整个pipeline流程如下图所示:
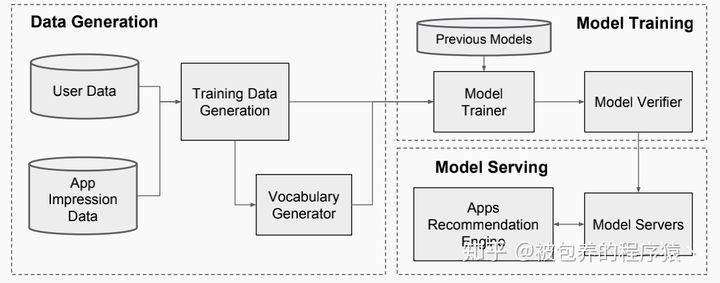
系统运行Pipeline
整个pipeline由三部分组成:数据生成、模型训练、模型部署。
1、数据生成
训练数据主要由两部分组成,一部分是用户相关的日志,另一部分是app的曝光点击数据(因为论文的业务场景是APP推荐),同时还会生成相关的字典,字典主要是将类别的信息以及相关的字符串信息按照一个固定的key进行存储,同时在该部分还会进行诸如归一化、分箱等一些数据预处理的操作。
2、模型训练
当有新的数据生成的时候,都需要重新进行模型训练以及模型的推送过程,这样是十分耗时的,而且也没法保证模型的时效性(当然可以考虑online learning的方式),为了解决这个问题,模型采用的一种解决思路就是加载上一次模型训练得到的embedding网络和线性模型的权重进行增量学习。在推送模型上线之前,需要确保模型指标正常,所以需要进行离线的一些验证。
3、模型部署
模型部署上线之后,在一个用户请求发送给系统之后,只需要进行前向预测过程从而得到最后的预测分数进行后续的排序即可,为满足线上延迟的要求,可以考虑采用分布式运行的方式来进行计算。
五、实验结果
文章对Wide&Deep模型的效果进行了线上的验证,实验结果如下:(消融实验---控制变量法)
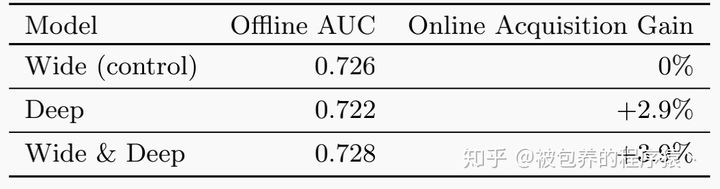
从实验结果可以看到相较于Wide模型,Wide&Deep模型可以带来接近4%的收益提升,同时AUC也有0.2%的提升;同时相较于Deep模型,Wide&Deep模型也可以带来接近1%的收益提升,AUC也有0.6%的提升。
六、结论
从现在来看Wide&Deep仍然是一种十分有效的并且可以实际进行线上部署的CTR预估模型,也有很多公司的Base模型采用的是Wide&Deep模型,可以说该模型对后来CTR深度模型的发展具有很大的指导意义,所以该论文是CTR预估模型领域非常经典的论文,推荐大家有时间能够仔细阅读几遍。















 1856
1856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









