







 本文介绍了2014年Criteo在Kaggle上举行的展示广告点击率预估比赛,重点讨论了LogLoss作为评估指标的原因、数据分布特点、特征工程以及使用VW的logistic regression和xgboost进行模型训练的过程。通过模型预测,xgboost取得最佳效果,展示了CTR预估在计算广告领域的关键作用。
本文介绍了2014年Criteo在Kaggle上举行的展示广告点击率预估比赛,重点讨论了LogLoss作为评估指标的原因、数据分布特点、特征工程以及使用VW的logistic regression和xgboost进行模型训练的过程。通过模型预测,xgboost取得最佳效果,展示了CTR预估在计算广告领域的关键作用。
Display Advertising Challenge
---------2015/1/12
一:背景
CriteoLabs 2014年7月份在kaggle上发起了一次关于展示广告点击率的预估比赛。CriteoLabs是第三方展示广告的佼佼者,所以这次比赛吸引了很多团队来参赛和体验数据。

二:评估指标
比赛采用的评价指标是LoglLoss:
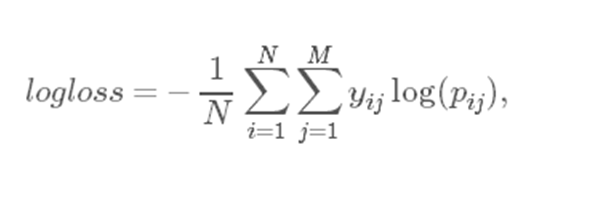
至于离线评估为何更倾向采用logloss,而不是采用AUC值。Facebook在他们发布的论文【1】中提到现实环境中更加关注预测的准确性,而不是相对的排序。而AUC值更侧重相对排序,比如把整体的预测概率提升1倍,AUC值保持不变,但是logloss是有变化的。
三:训练集和测试集数据分布
训练集: 4000w+, 测试集:600w+。
训练集是连续7天的Criteo广告展示数据,里面包含点击和非点击数据。里面对每天的负样本进行了不同采样率的采样,使得整体的正负样本比率不至于悬殊。
测试集是接着训练集后的一天广告展示数据,测试集的采样方式和训练集一致。
下面是kaggle上一位参赛者给出的训练集点击率分布:
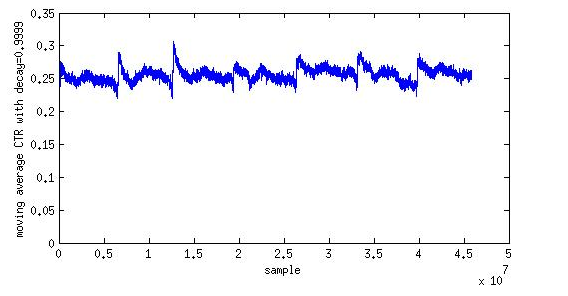
从上面很清楚的能看到7天周期性变化的数据,每天的点击率变化,有衰减的趋势,点击率平均值大约处在0.25左右。
其中数据特征介绍如下:

13个连续特征,26个类目特征。最终的效果提升更多体现在26个类目特征的处理和变换上面。其中类目特征要说明的是,有的类目特征的属性上万,有的属性展示和点击都少。
四:模型
ctr预估在工业界是个相对成熟的话题,在计算广告领域尤为重要,很多成熟的解决方案。我知道很多团队目前logistic regression + L1正则是主流,大多数工程师干的活就是挖特征。
这块百度的技术实力很强,据说
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









