







目标url:小说_17K小说网|最新小说下载-一起免费看小说
网站特色:动态cookie
需要先注册一个账号
网站分为免费小说和vip小说,vip小说只能开头vip才能爬取
需要先将免费小说加入书架,然后进行爬取:
步骤: 模拟登陆爬取数据 -> 爬取章节 -> 爬取每本小说的完整内容
⑴ 模拟登陆爬取数据
经过一些列ua、Referer、cookie之后尝试之后,发现cookie是动态的
于是,使用session会话,去动态获取cookie
先退出登陆,打开f12,点击登陆,看请求方式、请求url、以及载荷
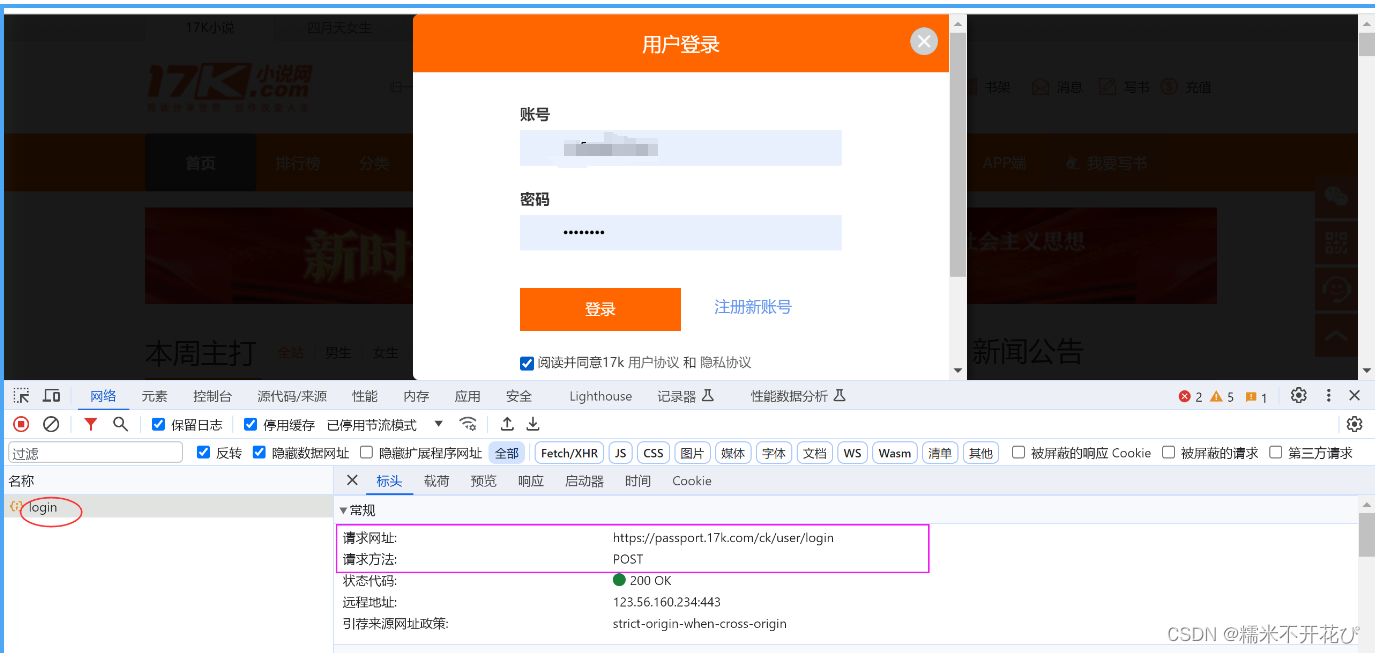
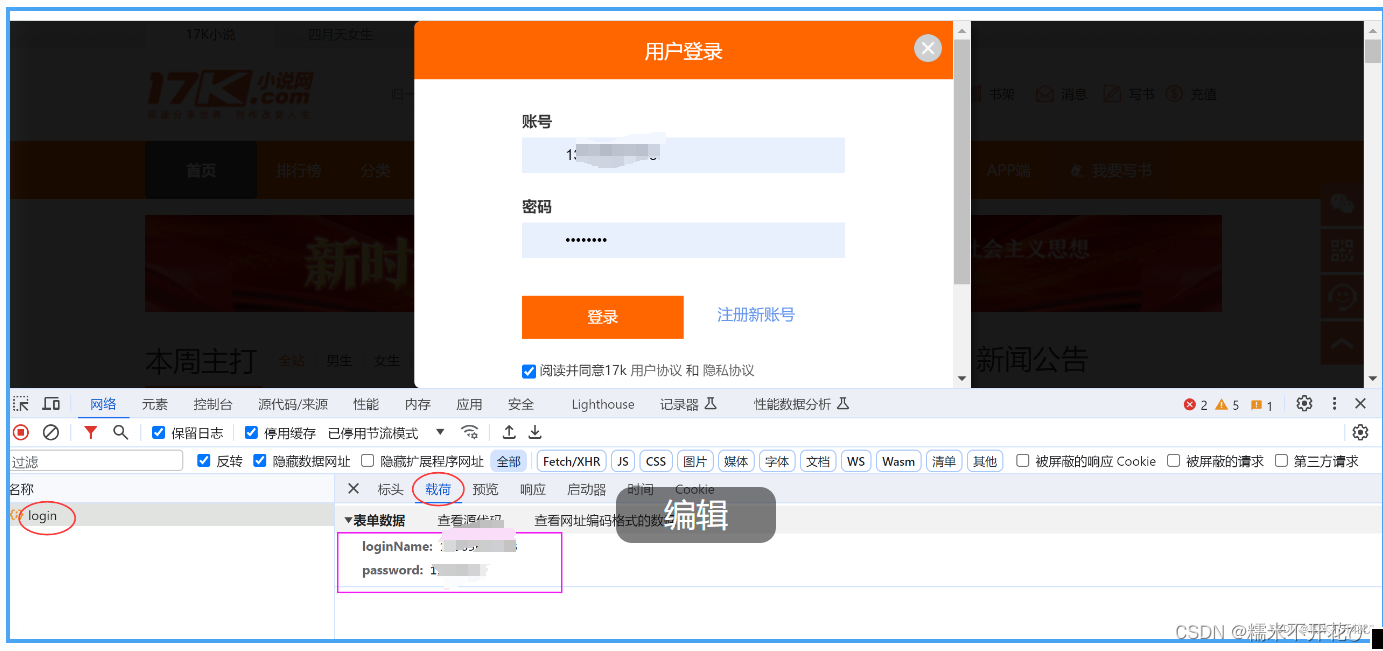
登陆后,手动从首页进入“书架”,会带一个"https://user.17k.com/www/"的Referer
但那并不是真正的ajax请求对应的书架url
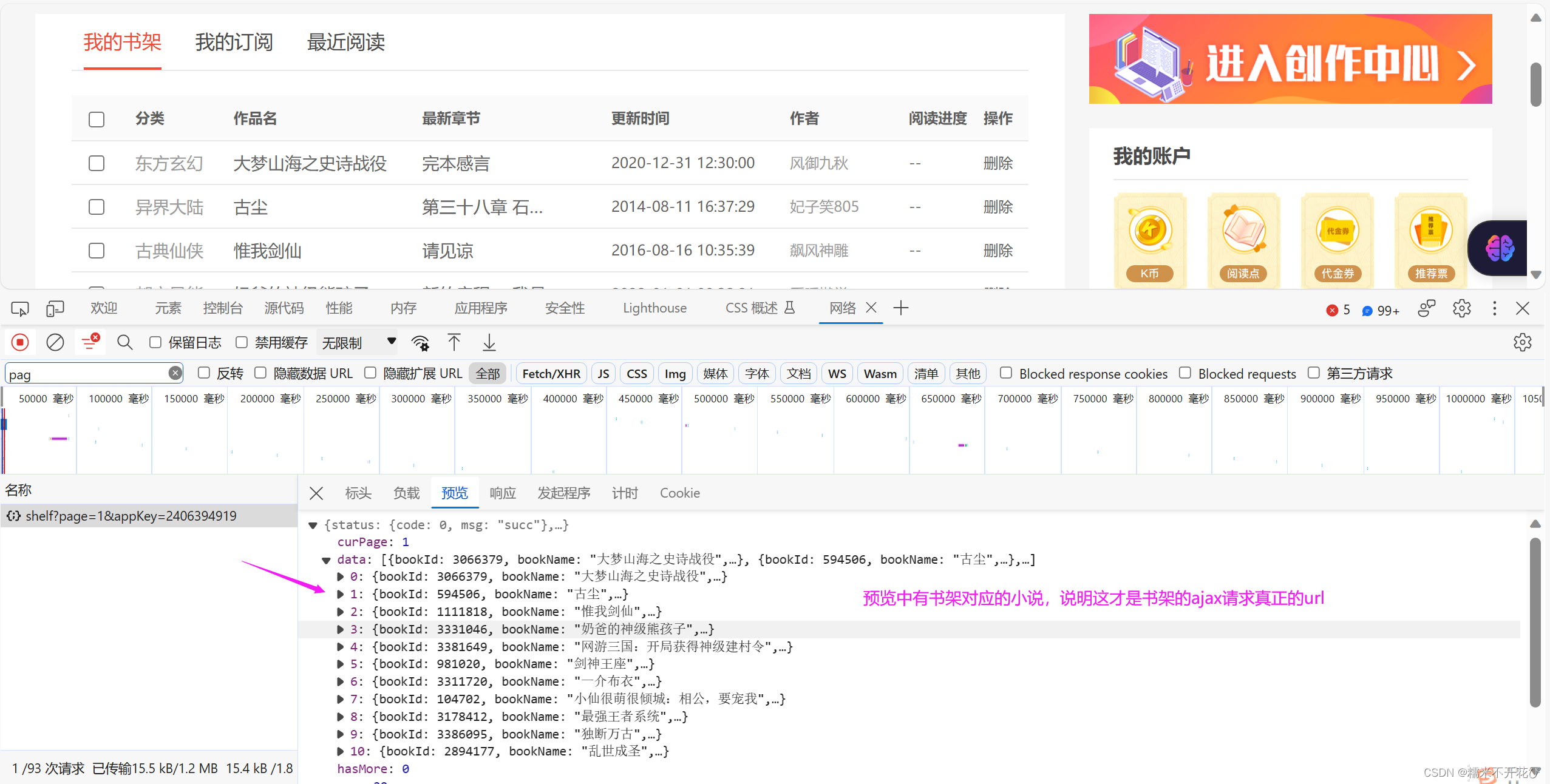
直接上代码:
import requests
#模拟登陆17k,获取cookie,并拿到书架里的小说
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
#定义session登陆,不会担心随机cookie,每次访问都带着session
session = requests.session()
session.post("https://passport.17k.com/ck/user/login",
data = {
"loginName": "13*********",
"password": "*******"},
headers = headers)
#错误的书架ajax请求url
# res = session.get("https://user.17k.com/www/bookshelf/")
#找到真正的书架对应的ajax请求url
res = session.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919")
res.encoding ="utf-8" #windows默认gbk,外面要写编码规则
# print(res.text)
#写入是还需要定义编码规则,否则html文件中还是有乱码
# with open("17k.html","w",encoding="utf-8") as f:
# f.write(res.text)
#将ajax的json数据反序列化为字典,并获取data这个键
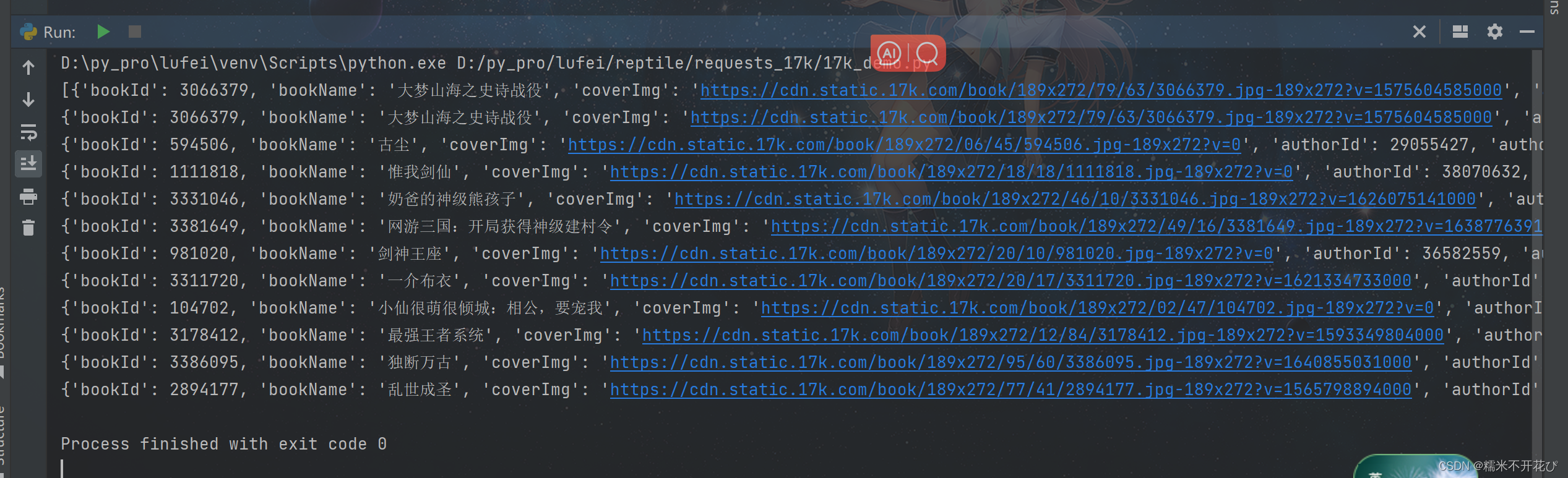
data = res.json().get("data")
print(data) #查看data
#取出字典里的每个item
for item in data:
print(item)
⑵ 爬取章节及链接
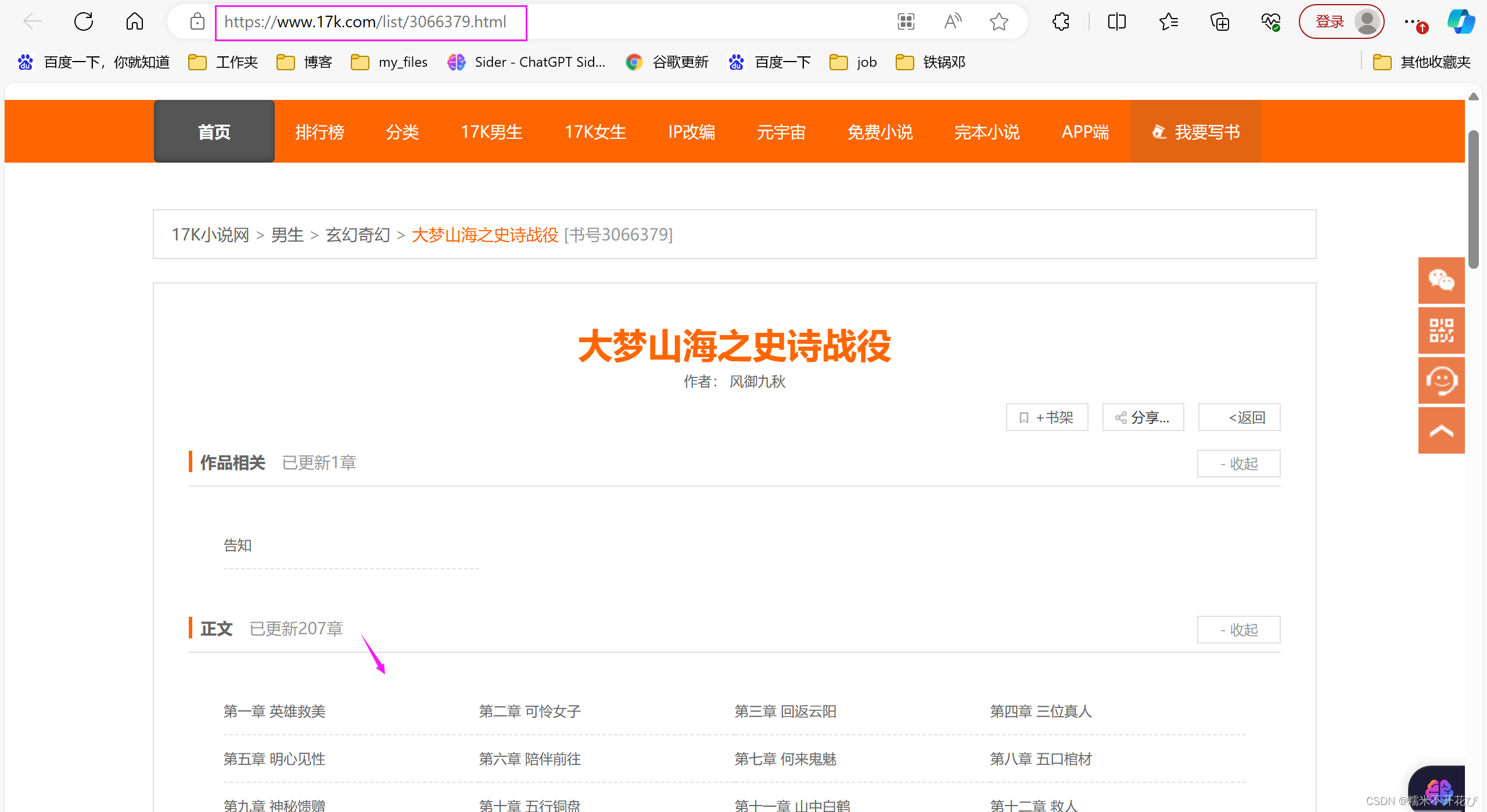
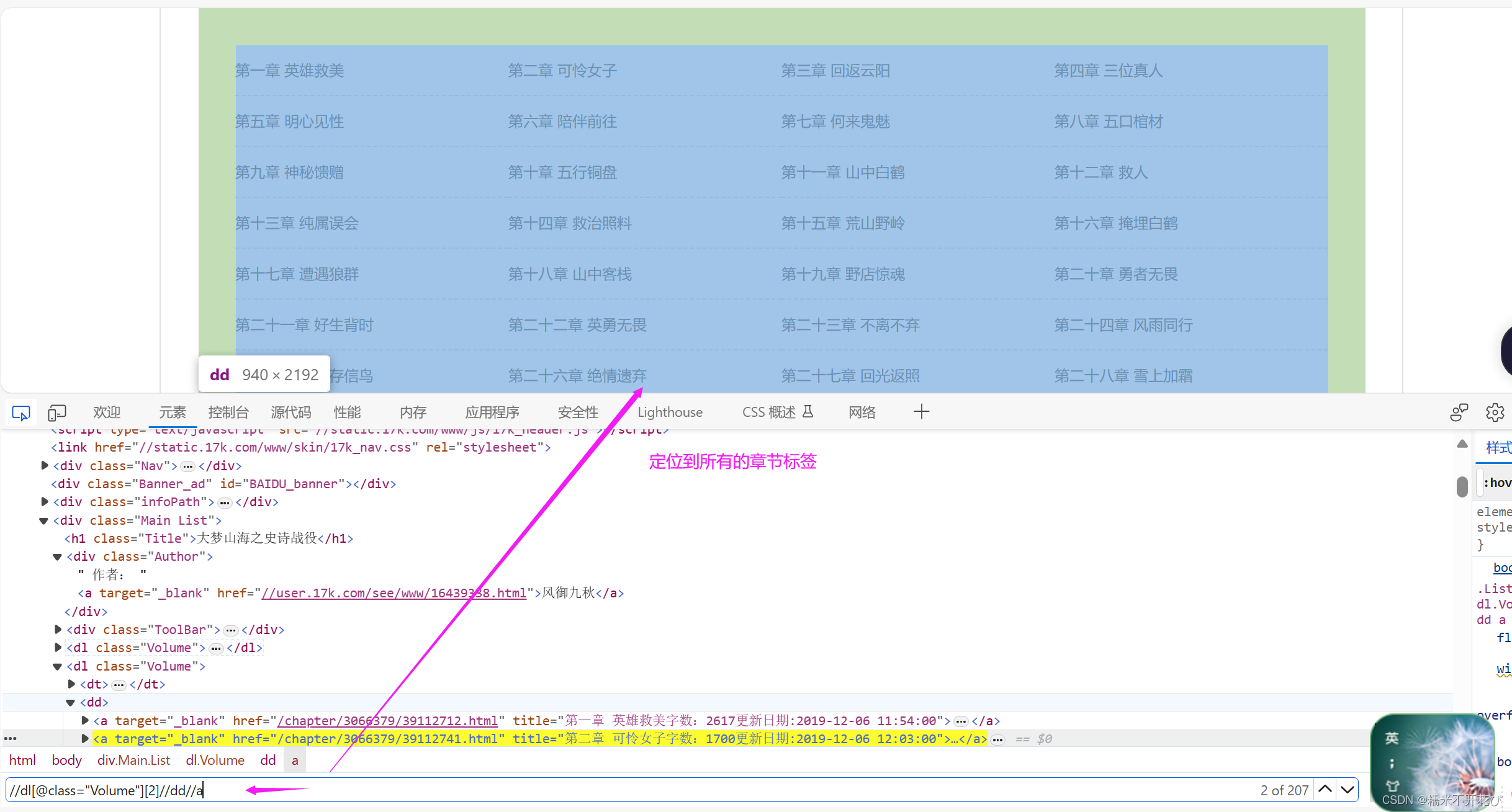
由于每本小说的Volume属性值数量不同,这里先爬下来所有的Volume下的所有a标签
import requests
from lxml import etree
#模拟登陆17k,获取cookie,并拿到书架里的小说
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
#定义session登陆,不会担心随机cookie,每次访问都带着session
session = requests.session()
session.post("https://passport.17k.com/ck/user/login",
data = {
"loginName": "13*******",
"password": "*******"},
headers = headers)
#找到真正的书架对应的ajax请求url
res = session.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919")
res.encoding ="utf-8" #windows默认gbk,外面要写编码规则
data = res.json().get("data")
#book已在data中;循环处理每一本书籍
for bookDict in data:
print(bookDict)
bookId = bookDict.get("bookId")
#获取每一本书架书籍的章节页面,通过bookId获取
#错误路径,没有章节信息
# res = requests.get(f"https://www.17k.com/list/{bookId}}.html")
#正确路径:对应页面"点击阅读"后,显示有所有章节的url
res = requests.get(f"https://www.17k.com/list/{bookId}.html")
res.encoding = "utf8"
#解析每一本书籍的章节链接
selector = etree.HTML(res.text)
#拿到一本数据对应的所有a标签(作品,正文/章节,外传所有的a标签)
items = selector.xpath('//dl[@class="Volume"]/dd/a')
#处理每一本书籍的每一章节信息
for item in items:
chapter_href = item.xpath("./@href")[0] #获取a标签里的href
chapter_title = item.xpath("./span/text()")[0].strip() #获取a标签里的第一个文本,即章节名
print("链接:",chapter_href)
print("章节名:",chapter_title)
#爬取章节内容:href上面已解析,包含bookId和章节id
res = requests.get("https://www.17k.com/" + chapter_href)
res.encoding = "utf8"
chapter_html = res.text #获取章节对应的html文件
print(chapter_html)
selector = etree.HTML(res.text) #解析章节内容
#拿到出最后p标签外的所有章节内容对应的p标签,排除最后一个p标签
chapter_text = selector.xpath('//div[contains(@class,"content")]/div[@class="p"]/p[position()<last()-1]/text()')
print(chapter_text)
break
⑶ 爬取每本小说的完整内容
最后:创建总的文件夹、每本书的文件夹、以及每个章节的文件
完整代码如下:
import requests
from lxml import etree
import os
#模拟登陆17k,获取cookie,并拿到书架里的小说
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
}
#定义session登陆,不会担心随机cookie,每次访问都带着session
session = requests.session()
session.post("https://passport.17k.com/ck/user/login",
data = {
"loginName": "1*******",
"password": "********"},
headers = headers)
#找到真正的书架对应的ajax请求url
res = session.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919")
res.encoding ="utf-8" #windows默认gbk,外面要写编码规则
data = res.json().get("data")
#创建个人书架的文件夹
root_path = "my_books" #根路径
if not os.path.exists(root_path):
os.mkdir(root_path)
#book已在data中;循环处理每一本书籍
for bookDict in data:
print(bookDict)
bookId = bookDict["bookId"]
bookName = bookDict["bookName"]
#创建一个书籍的文件夹
book_path = os.path.join(root_path,bookName)
if not os.path.exists(book_path):
os.mkdir(book_path)
#获取每一本书架书籍的章节页面,通过bookId获取
#错误路径,没有章节信息
# res = requests.get(f"https://www.17k.com/list/{bookId}}.html")
#正确路径:对应页面"点击阅读"后,显示有所有章节的url
res = requests.get(f"https://www.17k.com/list/{bookId}.html")
res.encoding = "utf8"
#解析每一本书籍的章节链接
selector = etree.HTML(res.text)
#拿到一本数据对应的所有a标签(作品,正文/章节,外传所有的a标签)
items = selector.xpath('//dl[@class="Volume"]/dd/a')
#处理每一本书籍的每一章节信息
for item in items:
chapter_href = item.xpath("./@href")[0] #获取a标签里的href
chapter_title = item.xpath("./span/text()")[0].strip() #获取a标签里的第一个文本,即章节名
#爬取章节内容:href上面已解析,包含bookId和章节id
res = requests.get("https://www.17k.com/" + chapter_href)
res.encoding = "utf8"
chapter_html = res.text #获取章节对应的html文件
selector = etree.HTML(res.text) #解析章节内容
#拿到出最后p标签外的所有章节内容对应的p标签,排除最后一个p标签
chapter_text = selector.xpath('//div[contains(@class,"content")]/div[@class="p"]/p[position()<last()-1]/text()')
#进行下载章节,写入文件
chapter_path = os.path.join(book_path,chapter_title)
#这里chapter_path加了双引号,就不会生成章节对应的文件。。
with open(chapter_path,"w",encoding="utf8") as f:
for line in chapter_text:
f.write(line + "\n")
import time
import random
time.sleep(random.randint(1,3))
print(f"{bookName}书籍的{chapter_title}章节下载完成!")书籍太多,先暂停运行了
⑷ 功能函数化,优化完整代码
上面的代码是第一版,里面也有一些小细节,但总的来说,内容可以爬下来,也正常生成了想要的3级目录。
但是代码比较乱,所以进行优化:将每一个功能封装为一个函数
import requests
from lxml import etree
import os
import time
import random
#定义session登陆,不会担心随机cookie,每次访问都带着session
session = requests.session()
#模拟登陆17k,获取cookie,并拿到书架里的小说
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36" }
#定义登陆17k的函数:
def login():
session.post("https://passport.17k.com/ck/user/login",
data={
"loginName": "1*******",
"password": "*******"},
headers=headers)
#定义获取每本书籍的函数:
def get_shelf_books():
res = session.get("https://user.17k.com/ck/author2/shelf?page=1&appKey=2406394919")
res.encoding ="utf-8" #windows默认gbk,外面要写编码规则
data = res.json().get("data")
return data
#定义下载每一本书籍的每一章节信息的函数:
def get_books(data):
for bookDict in data:
print(bookDict)
bookId = bookDict["bookId"]
bookName = bookDict["bookName"]
#创建一个书籍的文件夹
book_path = os.path.join(root_path,bookName)
if not os.path.exists(book_path):
os.mkdir(book_path)
get_chapter(bookName,bookId,book_path)
#定义处理章节内容的函数:
def get_chapter(bookName,bookId,book_path):
# 爬取每一本书架书籍的章节页面:
res = requests.get(f"https://www.17k.com/list/{bookId}.html")
res.encoding = "utf8"
# 解析每一本书籍的章节链接
selector = etree.HTML(res.text)
# 拿到一本数据对应的所有a标签(作品,正文/章节,外传所有的a标签)
items = selector.xpath('//dl[@class="Volume"]/dd/a')
# 处理每一本书籍的每一章节信息
for item in items:
chapter_href = item.xpath("./@href")[0] # 获取a标签里的href
chapter_title = item.xpath("./span/text()")[0].strip() # 获取a标签里的第一个文本,即章节名
# 爬取章节内容:href上面已解析,包含bookId和章节id
res = requests.get("https://www.17k.com/" + chapter_href)
res.encoding = "utf8"
chapter_html = res.text # 获取章节对应的html文件
selector = etree.HTML(res.text) # 解析章节内容
# 拿到出最后p标签外的所有章节内容对应的p标签,排除最后一个p标签
chapter_text = selector.xpath('//div[contains(@class,"content")]/div[@class="p"]/p[position()<last()-1]/text()')
dowlood(book_path,chapter_title,chapter_text)
time.sleep(random.randint(1, 3))
print(f"{bookName}书籍的{chapter_title}章节下载完成!")
#定义写入章节内容的函数:
def dowlood(book_path, chapter_title, chapter_text):
chapter_path = os.path.join(book_path, chapter_title + ".txt")
with open(chapter_path, "w", encoding="utf8") as f:
for line in chapter_text:
f.write(line.strip() + " ")
'''
主要逻辑:
(1) 模拟登陆,获取cookie
'''
login()
#(2)爬取书架上的书籍信息
data = get_shelf_books()
#(3)创建个人书架的文件夹
root_path = "my_books" #根路径
if not os.path.exists(root_path):
os.mkdir(root_path)
#(4) 遍历下载每一本书籍的每一章节信息
get_books(data)
由于小说内容太多,一本小说200个多章节☹,这里我在爬完一整本小说293章后,先暂停程序
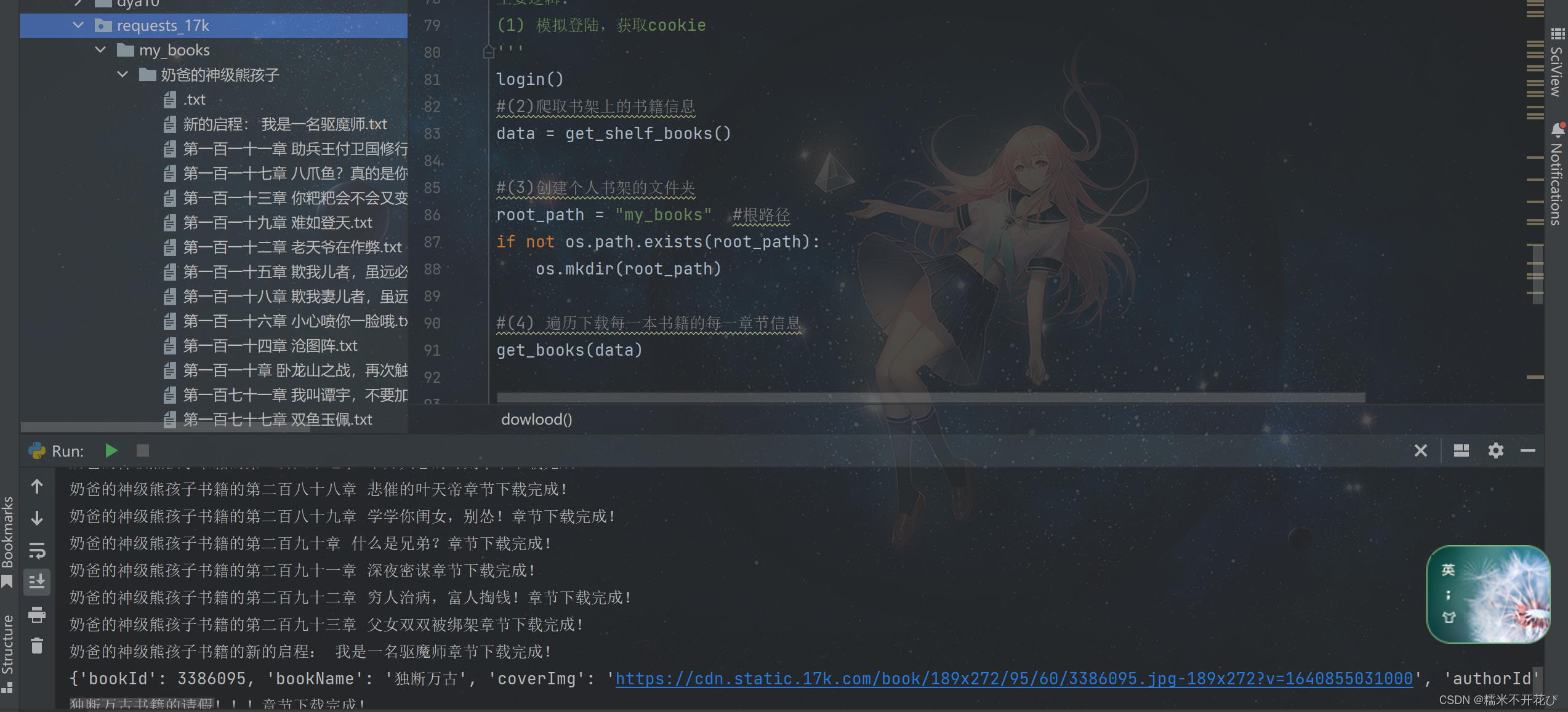
最后的整理好的代码,还有优化的空间,就先到这里了

















 2711
2711

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









