







1. 函数基本概念
函数是带名字的代码块,用于完成具体的工作。
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段。
通过使用函数,程序的编写、阅读、测试和修复都将更容易。
2. 函数定义及调用:
使用def关键字定义一个函数,定义函数不会执行定义的代码,需要调用才会执行;
定义函数的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()。
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数。
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
- 函数内容以冒号起始,并且缩进。
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
#定义一个简单的函数:
def greet_user(): #函数声明;定义函数名为greet_user
print("Hello!") #函数体
greet_user() #调用函数
#输出:
Hello!3.向函数传递信息:
只需稍作修改,就可以让上面的函数greet_user() 不仅向用户显示Hello! ,还将用户的名字用作抬头。为此,可在函数定义def greet_user() 的括号内添加username 。
通过在这里添加username ,就可让函数接受你给username 指定的任何值。
现在,这个函数要求你调用它时给username 指定一个值。调用greet_user() 时,可将一个名字传递给它,如下所示:
def greet_user(username):
"""显示简单的问候语,因为它是函数体需要缩进,否则会报错"""
print("Hello, " + username.title() + "!")
greet_user('sarah')
greet_user('lusy')
#输出:
Hello, Sarah!
Hello, Lusy!
4. 函数参数
4.1 位置参数(形参)
调用函数时,Python必须将函数调用中的每个实参都关联到函数定义中的一个形参。
为此,最简单的关联方式是基于实参的顺序。这种关联方式被称为位置参数。
一个简单的示例,定义一个"def add(x,y)"函数,但是没有直接在函数名内直接写死入参,
这样每次调用的时候,就可以自由的给括号内的x和y进行传值
#案例1:
def add(x,y): #定义一个add函数,括号内x,y为形参
print(x + y)
add(123,4869) #调用的时候,动态传入实际参数
add(789,903)
#输出:
4992
1692为什么不能直接写死参数,而要用形参的方式?
因为形参通过函数调用时动态传入实参,更加灵活。
比如:一个登录系统,有100个用户,如果直接在函数体内写死为用户A的账号和密码,那么输入其他用户的账号和密码,在登录进行后台验证的时候,都只能是用户A。
示例如下:
#案例登录功能
def login():
username = "wang"
pwd = "123"
print(f"{username}用户验证,密码为{pwd}")
login()
#输出:wang用户验证,密码为123改为动态传参:
#改成如下:
def login(username,pwd):
print(f"{username}用户验证,密码为{pwd}")
login("wang","123") #动态传参
login("yuan","234")
#输出:
wang用户验证,密码为123
yuan用户验证,密码为234函数可多次调用:
函数可多次调用:
可以根据需要调用函数任意次。要再描述一个宠物,只需再次调用describe_pet() 即可:
#案例1:
def describe_pet(animal_type, pet_name):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet('hamster', 'harry')
describe_pet('dog', 'willie') #第二次调用
#输出:
I have a hamster.
My hamster's name is Harry.
I have a dog.
My dog's name is Willie.再比如:
有一份20多行的打印菱形的代码,如果需要多次进行菱形打印,我们不可能去反复写代码,那么就可以把它封装为一个函数,每次直接进行调用就行,省时省力!~
#定义打印菱形的函数,菱形层数由rows决定
def pringling(rows):
i = j = k = 1
for i in range(rows):
for j in range(rows - i):
print(" ",end = " ")
j += 1
for k in range(2 * i -1):
print("*",end = " ")
k += 1
print("\n")
#菱形的下半部分:
for i in range(rows):
for j in range(i):
print(" ",end = " ")
j += 1
for k in range(2 * (rows - i) - 1):
print("*",end = " ")
k += 1
print("\n")
pringling(3) #调用的时候,根据需要给rows动态传参;3层菱形
print("do something……")
pringling(6) #再想打印一个6层菱形,再调用
#输出:
*
* * *
* * * * *
* * *
*
do something……
*
* * *
* * * * *
* * * * * * *
* * * * * * * * *
* * * * * * * * * * *
* * * * * * * * *
* * * * * * *
* * * * *
* * *
*
位置参数的顺序很重要:
使用位置实参来调用函数时,参数值的位置需要和参数名位置对应
如果参数的顺序不正确,结果可能出乎意料:
比如,上面的describe_pet函数中,我们想要通过形参的方式,打印一只叫“harry”的仓鼠
但是调用的函数的时候,把名字放在了前面,输出效果如下:
def describe_pet(animal_type, pet_name):
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet('harry', 'hamster') #把仓鼠名字放在前,仓鼠放在后
#输出:
I have a harry.
My harry's name is Hamster.
#正确的传参:调用函数,与最上面定义的形参名称呼应,宠物类型在前,宠物名在后
describe_pet('hamster', 'harry')
#输出:
I have a hamster.
My hamster's name is Harry.其次是,调用时传入的实参个数,需要与形参相匹配,多一个或少一个都会报错
错误示例如下:
def info(name,age):
print("name:",name)
print("age:", age)
info(19,"wang") #传入实参顺序与形参不匹配
#输出:
name: 19
age: wang
info("小红",30,"小明") #多写一个实参
#报错如下:
TypeError: info() takes 2 positional arguments but 3 were given
info(19) #少写一个实参
#报错如下:
TypeError: info() missing 1 required positional argument: 'age'
4.2 关键字参数
关键字实参是传递给函数的名称—值对。
直接在实参中将名称和值关联起来了,因此向函数传递实参时不会混淆(不会得到上述名为Hamster的harry这样的结果)。
关键字实参无需考虑函数调用中的实参顺序,还清楚地指出了函数调用中各个值的用途。
与形参不同的是:
调用时直接对参数进行 = 赋值
从此,妈妈再也不用担心,出现位置实参顺序与形参不匹配的情况了~
特别是当一个函数要多个不同的文件中调用时,或者是我们调用别人的包,我们不可能记得或清楚每个参数的位置,通过这种方式,可以简单高效且顺利的完成调用。
示例如下:
def describe_pet(animal_type, pet_name):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
#括号内的两个值,也可以反过来写,因为直接对参数名做了赋值,所以位置顺序不受影响
describe_pet(animal_type ='hamster', pet_name ='harry')
#输出:
I have a hamster.
My hamster's name is Harry.4.3 函数的默认值
编写函数时,可给每个形参指定默认值 。
就是当某一个参数基本是固定的时候,我们不需要先定义形参,然后每次都重复传入同一个实参,偷懒的写法,就是直接给形参指定默认值。
使用默认值可简化函数调用,还可清楚地指出函数的典型用法。
例如:
调用describe_pet() 时,描述的基本都是是小狗,就可将形参animal_type 的默认值设置为'dog' 。这样,调用describe_pet() 来描述小狗时,每次就只需要传pet_name的实参即可:
# 定义函数时,直接给animal_type指定了默认值,无需再通过该实参来指定动物类型
def describe_pet(pet_name, animal_type='dog'):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet(pet_name='willie') #调用是就不用再传animal_type
#输出:
I have a dog.
My dog's name is Willie.如果定义函数时,已经指定了默认值,但实际调用又需要更改实参,要怎么办呢?
只需要在调用时重新传入对应的实参,就相当对实参重复赋值。
示例如下:
# 定义函数时,直接给animal_type指定默认值为 = dog
def describe_pet(pet_name, animal_type='dog'):
"""显示宠物的信息"""
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
#调用时把animal_type改为cat
describe_pet(pet_name ='willie', animal_type = 'cat')
#输出:
I have a cat.
My cat's name is Willie.
4.4 不定长参数
*args:
一个*表示不定长参数(不确定长度)
可以传任意长度的参数,可以是0个,也可以是多个
#示例1:
def add(*args):
print(type(args))
#返回传入参数的和:
sum = 0
for item in args:
sum += item
return sum
a = add(1,2,3,4,6)
print(a)
#输出:
<class 'tuple'>
16
#示例2:
a = add(1,2,3,4,6)
print(a)
print("*" *100)
def cal(caozuo,*nums):
if caozuo == "+":
print(nums)
s = 0
for i in nums:
s += i
print(s)
cal("+",3,88,73)
#输出:
(3, 88, 73)
164**kwargs:
2**kwargs也表示不定长参数,初始值是字典类型、传key和value
在调用函数时,多余的键值对都会写入形参**kwargs字典
如下所示:
● 初始定义3个形参和一个不定长参数
● 第一次调用时,第4个实参对应**kwargs
● 第二次调用时,第4个、第5个实参都对应**kwargs
def print_stu_info(name,age,gender,**kwargs):
print("name:",name)
print("age:", age)
print("gender:", gender)
print("kwargs:", kwargs)
print_stu_info(name = "张三",age = 22,gender = "male",weight = "70KG")
print("*" *100)
print_stu_info(name="李四", age=22, gender="male", weight="70KG",haight = 180)
#输出:
name: 张三
age: 22
gender: male
kwargs: {'weight': '70KG'}
****************************************************************************************************
name: 李四
age: 22
gender: male
kwargs: {'weight': '70KG', 'haight': 180}4.5等效的函数调用
鉴于可混合使用位置实参、关键字实参和默认值,通常有多种等效的函数调用方式。
例如下面的函数describe_pets() 的定义,其中给一个形参提供了默认值:
def describe_pet(pet_name, animal_type='dog'):基于这种定义,在任何情况下都必须给pet_name 提供实参;
指定该实参时可以使用位置方式,也可以使用关键字方式。
如果要描述的动物不是小狗,还必须在函数调用中 给animal_type 提供实参;
同样,指定该实参时可以使用位置方式,也可以使用关键字方式。
下面对这个函数的所有调用都可行:
#一条名为Willie的小狗
describe_pet('willie')
describe_pet(pet_name='willie')
# 一只名为Harry的仓鼠
describe_pet('harry', 'hamster')
describe_pet(pet_name='harry', animal_type='hamster')
describe_pet(animal_type='hamster', pet_name='harry')总结:
1. 综上,不论是哪种函数参数的形式,本质上来讲:
定义函数,就是定义一个变量、定义变量参数(形参相当于临时变量)
调用函数,就是对变量进行赋值(赋予实际变量值)
2. 四种参数同时出现,固定写法顺序排列:
位置参数、不定长参数、默认参数、关键字参数不定长参数一定要在关键字参数之前,不然会报错
5. 函数的回值
函数并非总是直接显示输出,相反,它可以处理一些数据,并返回一个或一组值。
函数返回的值被称为返回值 。
在函数中,可使用return 语句将值返回到调用函数的代码行
如果不加return会默认返回一个None值
返回简单值:
#下面来看一个函数,它接受名和姓并返回整洁的姓名:
def get_formatted_name(first_name, last_name):
"""返回整洁的姓名"""
full_name = first_name + ' ' + last_name
return full_name.title()
musician = get_formatted_name('jimi', 'hendrix')
print(musician)
#输出:
Jimi Hendrix返回默认值None:
当函数体内没有retrun语句时,会默认返回一个None值
示例如下:
#不加return
def add(x,y):
print(x+y)
ret = add(1,2)
print(ret)
#输出:
3
None
#加上return:
def add(x,y):
return x+y
ret = add(1,2)
print(ret)
#输出:
3返回多个值:
如果想要返回多个值,只需要return后的值中间以逗号相隔即可
例如:
def cal(x,y):
return x+y,x*y
ret = cal(3,7) #一个变量接受,打印值就合在一个元组内
print(ret)
#分开打印,用两个变量接受:
he,cheng = cal(3,7)
print(he,cheng)
#输出:
(10, 21)
10 21
让实参变为可选的:
有时候,需要让实参变成可选的,这样使用函数的人就只需在必要时才提供额外的信息,可使用默认值来让实参变成可选的。
例如,假设我们要扩展函数get_formatted_name() ,使其还处理中间名。为此,可将其修改成类似于下面这样:
def get_formatted_name(first_name, middle_name, last_name):
full_name = first_name + ' ' + middle_name + ' ' + last_name
return full_name.title()
musician = get_formatted_name('john', 'lee', 'hooker')
print(musician)
#输出:
John Lee Hooker然而,并非所有的人都有中间名,但如果你调用这个函数时只提供了名和姓,它将不能正确地运行。
为让中间名变成可选的,可给实参middle_name 指定一个默认值——空字符串,并在用户没有提供中间名时不使用这个实参。
为让get_formatted_name() 在没有提供中间名时依然可行,可给实参middle_name 指定一个默认值——空字符串,并将其移到形参列表的末尾:
def get_formatted_name(first_name, last_name, middle_name=''):
if middle_name:
full_name = first_name + ' ' + middle_name + ' ' + last_name
else:
full_name = first_name + ' ' + last_name
return full_name.title()
musician = get_formatted_name('jimi', 'hendrix')
print(musician)
musician = get_formatted_name('john', 'hooker', 'lee')
print(musician)
#输出:
Jimi Hendrix
John Lee Hooker当前,字符串'jimi' 和'hendrix' 被标记为名和姓。
还可以轻松地扩展这个函数,使其接受可选值,如中间名、年龄、职业或你要存储的其他任何信息。
例如,下面的修改让你还能存储年龄:
def build_person(first_name, last_name, age=''):
"""返回一个字典,其中包含有关一个人的信息"""
person = {'first': first_name, 'last': last_name}
if age:
person['age'] = age
return person
musician = build_person('jimi', 'hendrix', age=27)
print(musician)
print("*" * 100)
#输出:
{'first': 'jimi', 'last': 'hendrix', 'age': 27}函数结合while循环:
while 循环存在一个问题:没有定义退出条件。
请用户提供一系列输入时,该在什么地方提供退出条件呢?
我们要让用户能够尽可能容易地退出,因此每次提示用户输入时,都应提供退出途径。
每次提示用户输入时,都使用break 语句提供了退出循环的简单途径:
def get_formatted_name(first_name, last_name):
"""返回整洁的姓名"""
full_name = first_name + ' ' + last_name
return full_name.title()
while True:
print("\nPlease tell me your name:")
print("(enter 'q' at any time to quit)")
f_name = input("First name: ")
if f_name == 'q':
break
l_name = input("Last name: ")
if l_name == 'q':
break
formatted_name = get_formatted_name(f_name, l_name)
print("\nHello, " + formatted_name + "!")
#输出:
Please tell me your name:
(enter 'q' at any time to quit)
First name: 小红
Last name: 小明
Hello, 小红 小明!
Please tell me your name:
(enter 'q' at any time to quit)
First name: q6. 函数传递列表
你经常会发现,向函数传递列表很有用,这种列表包含的可能是名字、数字或更复杂的对象(如字典)。
将列表传递给函数后,函数就能直接访问其内容。下面使用函数来提高 处理列表的效率。
假设有一个用户列表,我们要问候其中的每位用户。
如下示例:
将一个名字列表传递给一个名为greet_users() 的函数,这个函数问候列表中的每个人:
def greet_users(names):
"""向列表中的每位用户都发出简单的问候"""
for name in names:
msg = "Hello, " + name.title() + "!"
print(msg)
usernames = ['hannah', 'ty', 'margot']
greet_users(usernames)
#输出:
Hello, Hannah!
Hello, Ty!
Hello, Margot!在函数中修改列表:
将列表传递给函数后,函数就可对其进行修改。
在函数中对这个列表所做的任何修改都是永久性的,这让你能够高效地处理大量的数据。
下面是一家为用户提交的设计制作3D打印模型的公司。需要打印的设计存储在一个列表中,打印后移到另一个列表中。下面是在不使用函数的情况下模拟这个过程的代码:
# 首先创建一个列表,其中包含一些要打印的设计
unprinted_designs = ['iphone case', 'robot pendant', 'dodecahedron']
completed_models = []
# 模拟打印每个设计,直到没有未打印的设计为止
# 打印每个设计后,都将其移到列表completed_models中
while unprinted_designs:
current_design = unprinted_designs.pop()
#模拟根据设计制作3D打印模型的过程
print("Printing model: " + current_design)
completed_models.append(current_design)
# 显示打印好的所有模型
print("\n The following models have been printed:")
for completed_model in completed_models:
print(completed_model)
#输出:
Printing model: dodecahedron
Printing model: robot pendant
Printing model: iphone case
The following models have been printed:
dodecahedron
robot pendant
iphone case为重新组织这些代码,我们可编写两个函数,每个都做一件具体的工作。
大部分代码都与原来相同,只是效率更高。
第一个函数将负责处理打印设计的工作,而第二个将概述打印了哪些设计:
def print_models(unprinted_designs, completed_models):
""" 模拟打印每个设计,直到没有未打印的设计为止
打印每个设计后,都将其移到列表completed_models中
"""
while unprinted_designs:
current_design = unprinted_designs.pop()
# 模拟根据设计制作3D打印模型的过程
print("Printing model: " + current_design)
completed_models.append(current_design)
def show_completed_models(completed_models):
"""显示打印好的所有模型"""
print("\nThe following models have been printed:")
for completed_model in completed_models:
print(completed_model)
unprinted_designs = ['iphone case', 'robot pendant', 'dodecahedron']
completed_models = []
print_models(unprinted_designs, completed_models)
show_completed_models(completed_models)
#输出:
Printing model: iphone case
The following models have been printed:
iphone case7. lambda表达式和匿名函数
lambda 表达式可以用来声明匿名函数。l
mbda 函数是一种简单的、在同一行中定义函数的方法。
lambda 函数实际生成了一个四数对象。
lambda 表达式只允许包含一个表达式,不能包含复杂语句该表达式的计算结果就是函数的返回值。---------->>>>
简单的使用示例如下:
#lambda表达式使用
#定义一个lambda为a,b,c相加
f = lambda a,b,c: a + b +c
print(f)
result = f(3,5,6) #lambda动态传参
print(result)
#把函数对象作为元素放在列表中
g = [lambda a:a*2,lambda b:b*3]
print(g[0](6)) #动态传参并打印结果:给第一个元素传入参数为6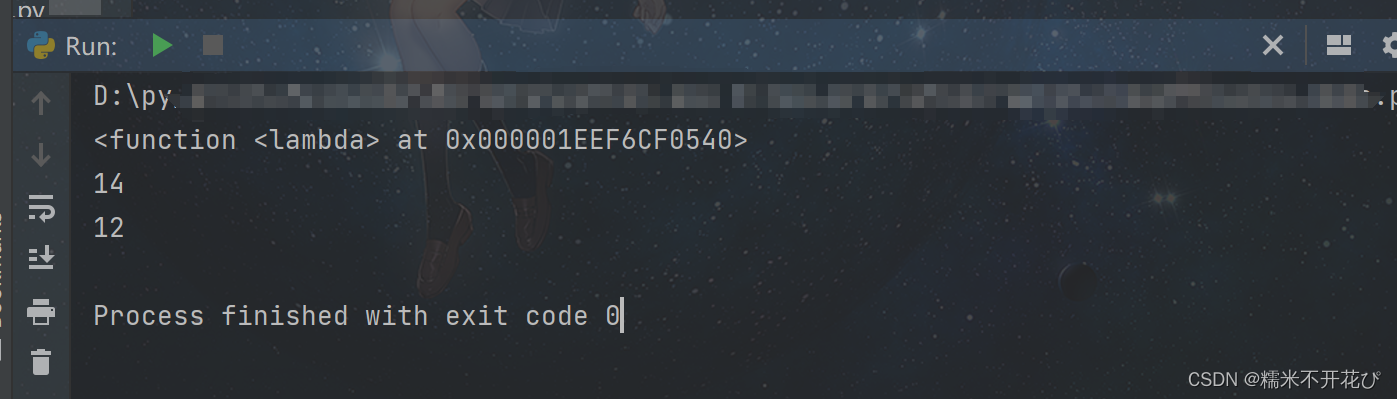
8. eval()函数
功能:将字符串 str 当成有效的表达式来求值并返回计算结果。
语法:eval(sourcel globalsl, locals]]) -> value
叁数 :
source:一个 Python 表达式或函数 compile0返回的代码对象globals:可选。必须是dictionary
locals:可选。任意映射对象---------->>>>
简单的使用示例如下:
# eval()函数的使用
eval("print('abcde')")
a,b = 10,20
c = eval("a+b")
print("a+b:",c)
#上下文的调用
dict1 = dict(a=100,b=200)
d = eval("a+b",dict1) #括号内指明变量名为dict1,即引用dict1的变量值进行sum
print("d:",d)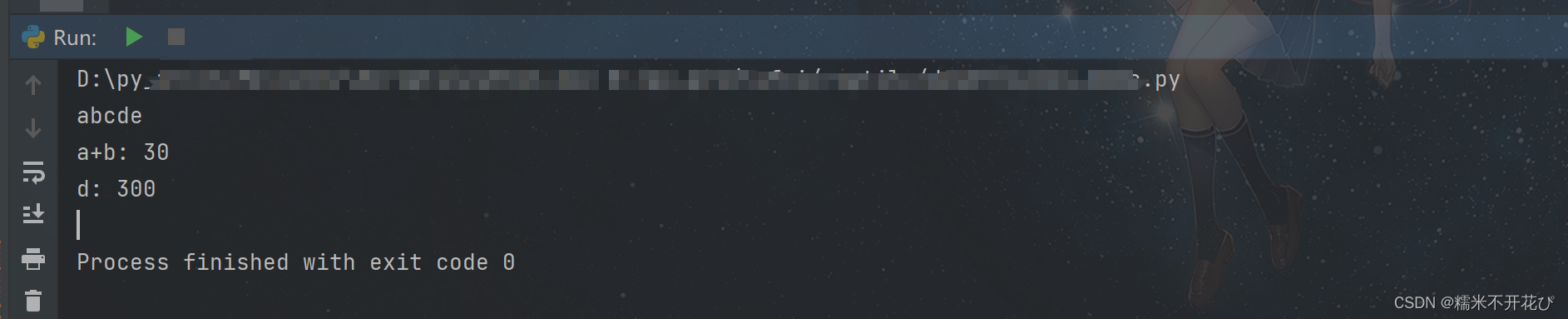
9. 函数递归
递归是指在函数中调用自身的过程。
递归函数通常包括两部分:基线条件和递归条件。
基线条件:是指递归过程中最简单的情况,当满足基线条件时,递归就不再继续,避免无限循环。
递归条件则:是指递归过程中需要调用自身的情况。
---------->>>
调用自身:
可以被调用,没有终止条件时,最终内存满了之后就会报错
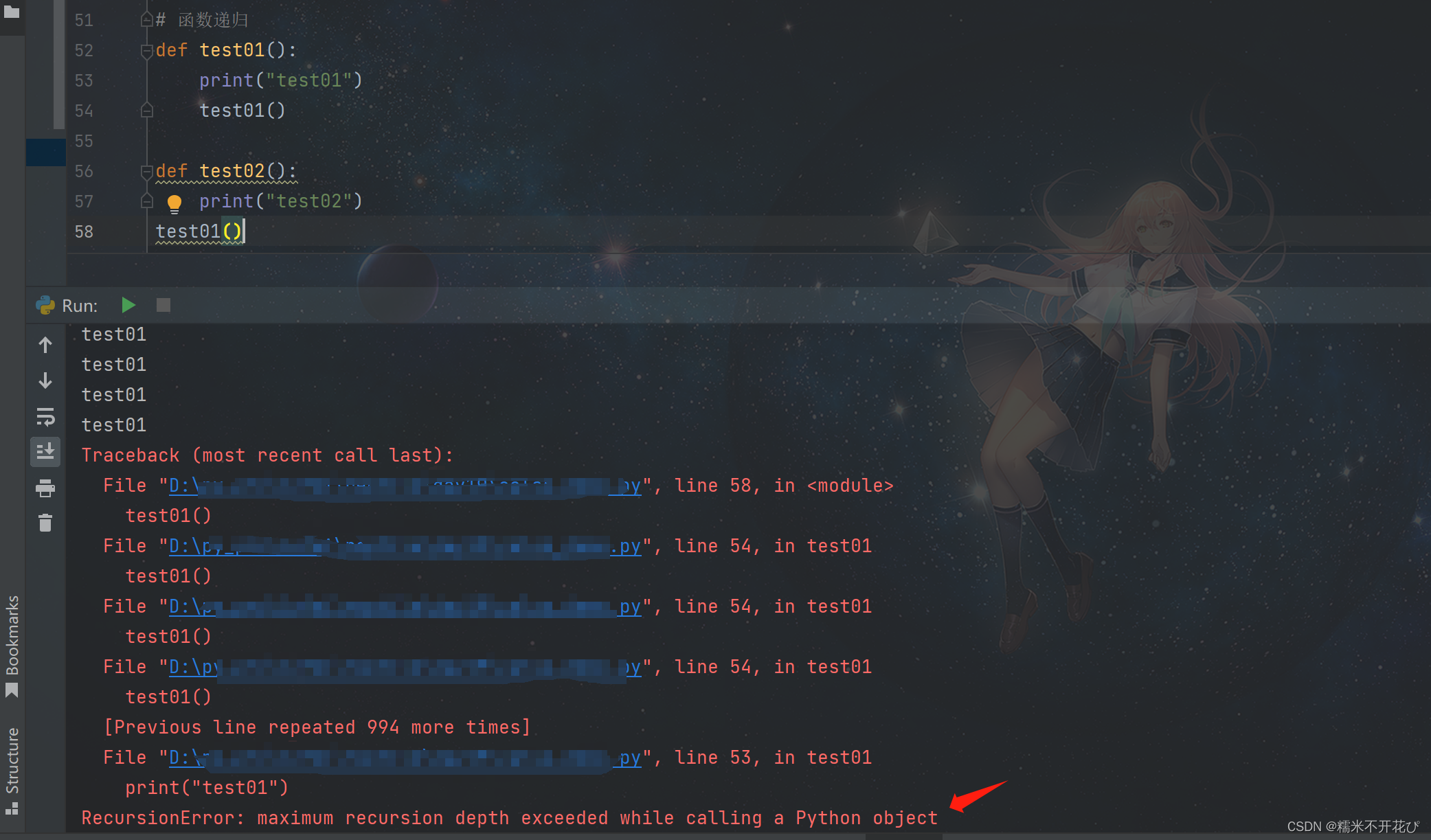
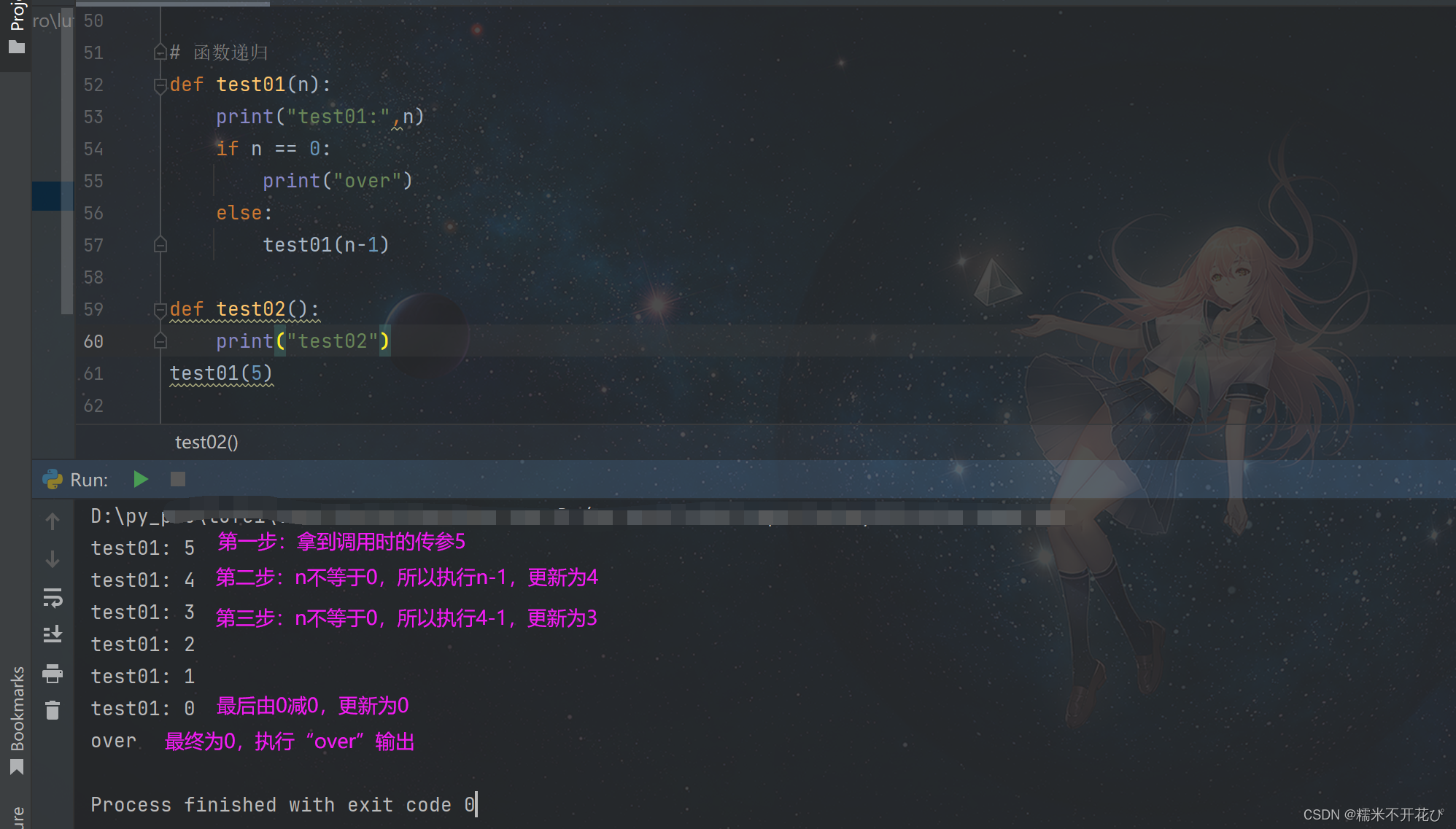
针对上面的代码进行改进,添加终止条件,所有条件都执行完毕之后就结束程序
相互调用:
相互调用即可以调用自身,也可以调用其他函数
如下:在第一个函数中调用第二个函数,所以最后执行调用的时候,两个函数都被执行了
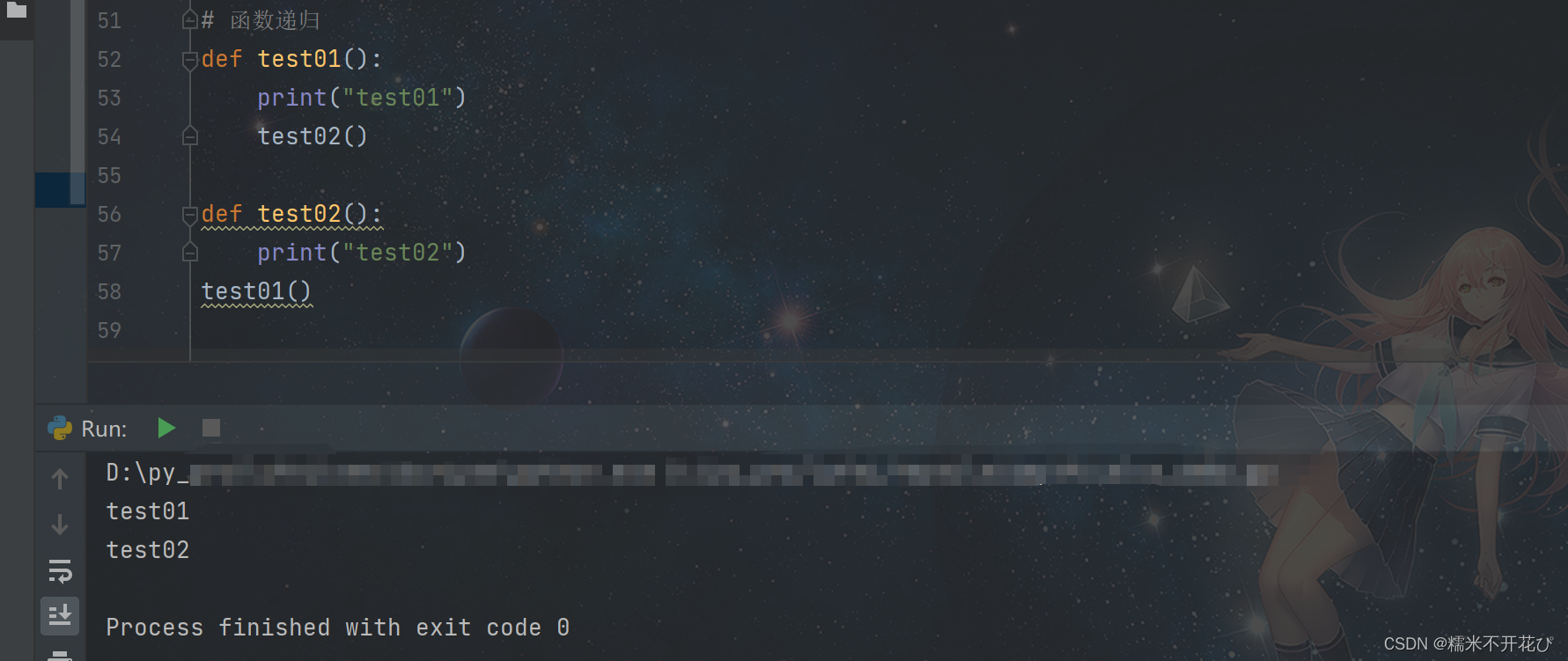
笔试题demo:
求阶乘
求阶乘:5的阶乘 5*4*3*2*1
循环和递归的两种写法对比:
# 1、for循环的写法:
n = int(input("请输入整数:"))
a = 1
for i in range(1,n+1):
a *= i
print(a)
print("*" * 100)
#输出:
请输入整数:8
40320
# 2、递归的写法:
n = int(input("请输入整数:"))
def f1(n): #此函数返回n*f1(n-1) ;
if n == 1: #递归退出的条件
return 1
return n*f1(n-1)
print(f1(n))
#输出:
请输入整数:8
40320斐波那契序列
使用斐波那契数列的方式,传入任意一个数字,求出对应的值
斐波那契规律:从第三个数开始,每个数等于前面两个数的和,例如:0,1,1,2,3,5,8,13……
def f1(n): #求的是当前第n个数的值 f1(5) = f1(4)+f1(3)
if n == 1:
return 0
elif n == 2:
return 1
return f1(n-1) + f1(n-2)
a = f1(8)
print(a)
#输出:
1310. 日期函数
获取当前时间戳:
时间戳是指:格林威治时间 1970年01月01日00时00分00秒(北京时间1970年01月01日08时00分00秒)起至现在的总秒数。
import time #导入python内置时间包
timeStamp = time.time() #获取当前时间戳,到秒
print(timeStamp)
time.time()*1000 #求毫秒级的时间戳
#输出:
1697845379.406788time.sleep:延时等待
多用于web自动化,等待元素出现
import time
time.sleep(3) #等待几秒,再执行后续的代码;
print(3333)
#输出:
3333获取当前日期+时间:
#获取当前日期+时间:
import datetime #导入python内置-datetime日期文件包
a = datetime.datetime.now() #获取当前日期+时间
print(a)
from datetime import datetime #导入datetime这个文件的datetime类
a = datetime.now() #导入datetime类之后,就不需要再写datetime文件名
print(a)
#输出:
2023-10-21 07:45:33.232610
2023-10-21 07:45:33.232610
#获取年份:
year =datetime.now().year
print(f"今年是{year}年")
#获取月份:
month = datetime.now().month
print(f"现在是{month}月")
# 获取日期:
day = datetime.now().day
print(f"今天是{day}号")
# 获取今天星期几:星期一是从0开始的,星期一就是返回0
weekday = datetime.now().weekday()
print(f"今天是星期{weekday + 1}") # weekday+1,进行转换
#输出:
今年是2023年
现在是10月
今天是21号
今天是星期6时间格式化:
针对有些时候datetime返回的时间格式、并不是我们想要的
我们可能只需要年份货到月份、或日期:
strftime:时间格式化,方法引用,大小写格式固定
也可以:strftime("%Y/%m/%d %H:%M:%S")
%Y:年份
%m:月份
%d:日
%H:小时
%M:分钟
%S:秒
a = datetime.now().strftime("%Y-%m-%d %H:%M:%S") #把时间类型转换成字符串
print(a)
#输出:
2023-10-21 07:49:49求间隔时间:
from datetime import datetime
from datetime import timedelta
#获取当周周一的日期:
weekday = datetime.now().weekday()
# print(type(weekday)) # 类型为init
diff = timedelta(weekday) #转换为日期格式
print(type(diff))
print(diff)
b = datetime.now() - diff
print(b)
#输出:
2023-10-21 07:51:23
<class 'datetime.timedelta'>
5 days, 0:00:00
2023-10-16 07:51:23.409633
str与datetime的互相转换:
a = "2021-05-04 12:00:00"
new_a = datetime.strptime(a,"%Y-%m-%d %H:%M:%S")
print(new_a)
diff = datetime.now() - new_a
print(f"时间差为{diff}")
#输出:
2023-10-21 07:52:45
2021-05-04 12:00:00
时间差为899 days, 19:52:45.055671日历模块:
import calendar
import datetime
a = calendar.monthrange(2022,2)
print(a)
b = datetime.date(2022,2,a[1]) #将年月日拼接起来,获取指定年的月份的最后一天
print(b)
#输出:
(1, 28)
2022-02-2811. 计算函数
数学计算的遇到的函数,只要会用就行
● abs():绝对值
● divmod():返回商和余数
● round():四舍五入(银行家算法):奇数四舍五入,偶数直接舍弃(只存在0.5这个区间)
● sum():求和
● min():最小值
● max():最大值
print(abs(-1)) #绝对值
a,b = divmod(5,9) #两个参数:一个是被除数,一个数除数,返回的值也是两个,商和余
print(a) #商
print(b) #余
print("=" * 100)
#四舍五入:
print(round(1.5))
print(round(2.5))
print(round(3.5))
print(round(4.5))
print(round(6.6))
print("=" * 100)
res1 = pow(10, 2) # 次方
print("次方:",res1)
list = [1, 2, 3, 4, 5, 6] #列表数字求和
print("列表求和:",sum(list))
list2 = (1, 2, 3, 4, 5, 6) #元组数字求和
print("元组求和:",sum(list2))
print("列表最小值:",min(list)) #最小值
print("元组最大值:",max(list2)) #最大值















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









