







⑴ 中间件
中间件基本介绍
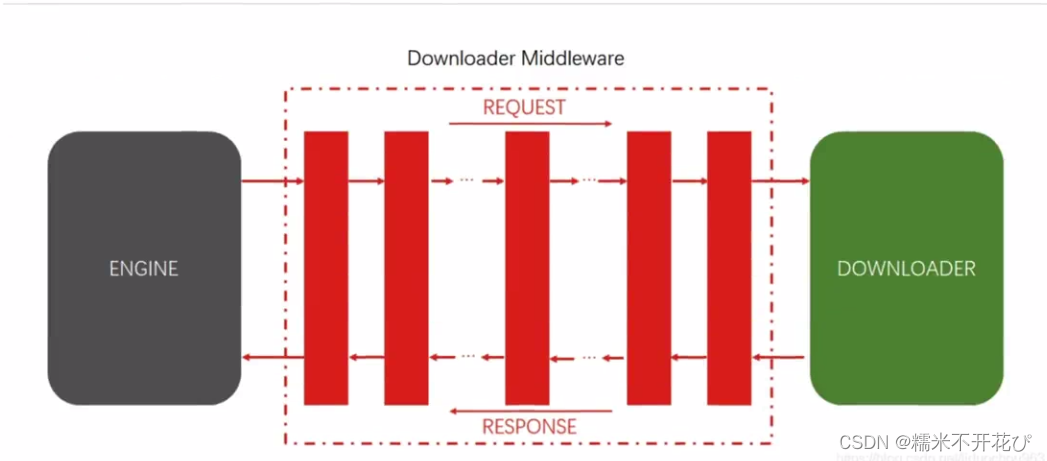
在Scrapy中,中间件是一种插件机制
它允许你在发送请求和处理响应的过程中对Scrapy引擎的行为进行干预和定制。
Scrapy中间件的用途:
修改请求、处理响应、处理异常、设置代理、添加自定义的HTTP头部等等。
=====================================================================
Scrapy中间件主要分为以下几种类型:
下载中间件(Download Middleware):下载中间件是用于处理Scrapy发送请求和接收响应的过程。它可以用于修改请求的头部、处理代理、处理重定向、处理异常、修改请求URL等。你可以通过编写下载中间件来实现自定义的下载逻辑。
爬虫中间件(Spider Middleware):爬虫中间件用于处理爬虫发送的请求和接收的响应。它可以用于修改请求、处理响应、处理异常、修改爬取策略等。通过编写爬虫中间件,你可以实现一些高级的爬取逻辑,比如动态生成请求、处理请求的优先级等。
服务中间件(Service Middleware):服务中间件是用于处理Scrapy引擎和其他服务(比如缓存服务、代理服务等)之间的交互。通过编写服务中间件,你可以实现与外部服务的集成、数据的缓存、代理的管理等功能。
可以通过编写自定义的中间件来扩展和定制Scrapy的功能,实现一些高级的爬取和处理逻辑。Scrapy中间件的灵活性和可扩展性使得它成为一个非常强大的爬虫框架。
=====================================================================
从开发角度举个例子:
我们都知道,一个Django开发的web网站,有一个路由分发,有一堆辑函数。
当浏览器带着url访问服务器时,路由来判断需要哪个逻辑函数来处理,再由函数完成对数据库的增删改查,返回给浏览器响应。
比如一些大的网站会做一些ip黑名单反爬措施,当某一个ip来访问时,路由分发后交给函数进行验证是否为黑名单,但是如果有成百上千个逻辑函数,每一个函数都去判断一遍那就太扯了。
所以可以在路由分发之前加一个中间件,当ip进行访问时先经过中间件定义的验证类1/2/3依次进行验证,如果是黑名单,就不用往下分发了。
反之假设不是黑名单:
请求路线就是:url请求 - > 中间件1/2/3验证通过 -> 路由分发 -> 执行逻辑函数;
响应路线就是:逻辑函数返回响应信息 -> 路由分发 -> 中间件3/2/1层层执行返回给浏览器。
---------------->>>>
如开头的图片所示,对于爬虫而言,思路是一样的。
简单来说:中间件可以理解为python中的一个类
在一份代码中可以有多个中间件,每一个中间件都一个类
一个中间件的类里面封装两个核心方法:
process request(处理请求)
process response(处理响应)
中间件(Downloader)的配置及使用
对于做爬虫而言,我们常用的中间件是下载中间件(Download Middleware)
如果是用命令创建的项目,一般在项目文件下自动生成一个'middlewares.py'文件
middlewares.py文件中,有一个'NewsproDownloaderMiddleware'的类,它下面有4个方法:
from_crawler:创建中间件,可以获取Crawler对象的信息,比如配置、信号等process_request:处理请求,可以在方法中对请求进行预处理,比如修改请求头、添加代理等操作process_exception:处理请求过程中的异常,比如重新发送请求、记录日志等操作。process_response:处理响应,比如修改响应内容、记录日志、判断是否需要重新发送请求等操作spider_opened:开启爬虫后,可以在方法中对响应进行处理,比如修改响应内容、记录日志、判断是否需要重新发送请求等操作;-------------------------------------------------------------------------------------------------------------------------
5个方法中,使用最多的是:
process_request(使用占比约60%)、process_response(使用占比约30%)、 process_exception(使用占比约10%)其中process_request、process_response是核心
class MyDownMiddleware(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass
def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response
def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None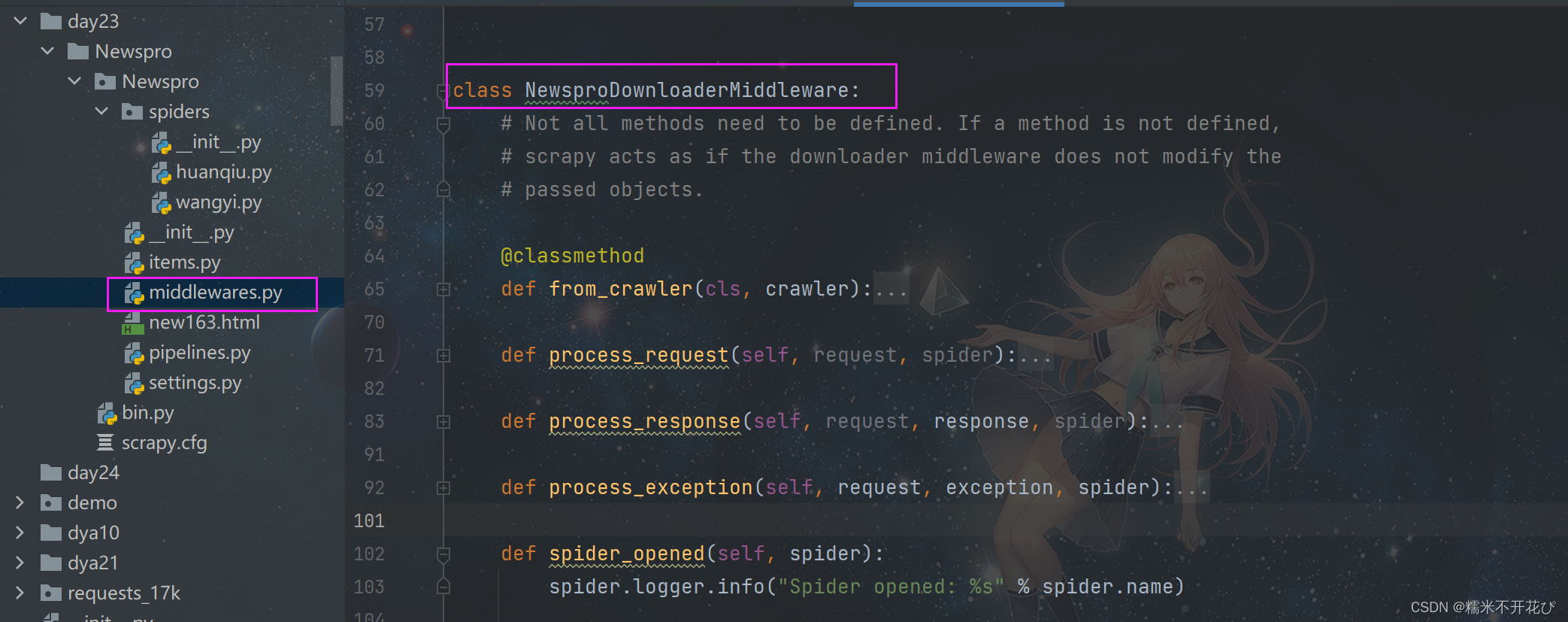
中间件的配置
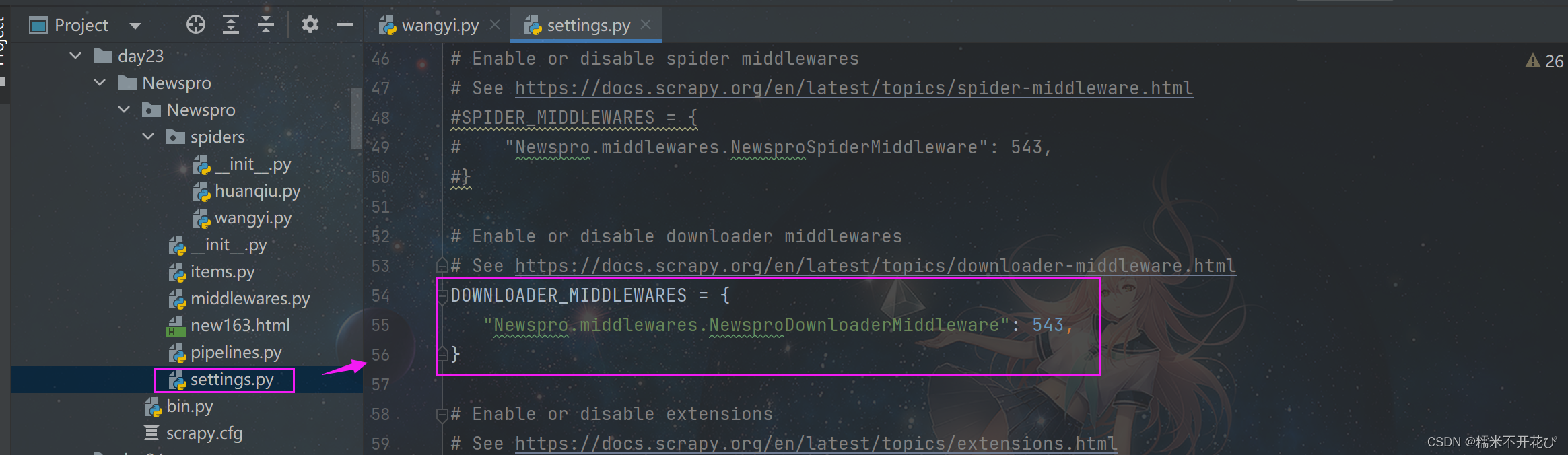
是否使用中间件,取决于'settings.py'文件中有没有配置Download方法
'settings.py'文件中Download默认是注释掉的,需要用的时候可以放开(54~56行)
里面的"Newspro.middlewares.NewsproDownloaderMiddleware"可以写很多个
方法命名自带完整的文件路径:Newspro是项目文件名,middlewares是py文件名,后面是方法
后面的数字表示权重,数字越小优先级越高
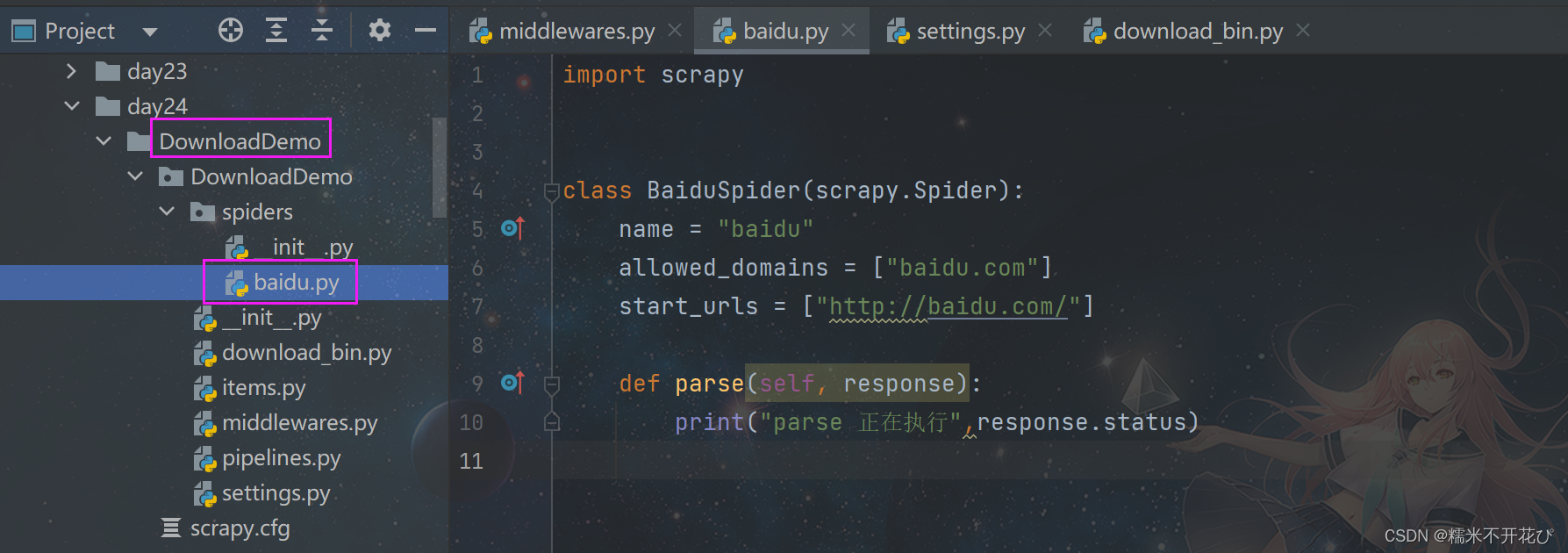
Downloader中间件简单案例
使用中间件请求百度,以及获取响应状态码:
❶ 新建DownloadDemo项目文件目录 -> 新建'baidu.py'文件
并添加输出响应状态码:response.status
❷ 自动生成'middlewares.py'文件添加及修改代码:
避免混淆,将类名改为TestMiddleware,'settings.py'文件的'DOWNLOADER_MIDDLEWARES'记得同步修改类名;
-> class TestMiddleware方法中,删除用不上的方法和注释内容,并添部分加代码:
from scrapy import signals
class TestMiddleware:
def process_request(self, request, spider):
print("request的方法属性:",dir(request 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 56万+
56万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









