






哇塞!谷歌竟然也涉足“小”模型领域啦,这一出手简直就是惊天动地的王炸操作,竟然一举超越了参数远远多于自己的 GPT-3.5 以及 Mixtral 等竞品模型!
在今年 6 月末的时候,谷歌将 9B、27B 版的 Gemma 2 模型系列进行了开源操作。而且,自从其亮相之后,27B 版本极为迅速地成为了大模型竞技场 LMSYS Chatbot Arena 当中排名处于前列的开放模型其中之一,在真实的对话任务里,其表现甚至比规模在自身两倍以上的模型还要出色。

当下,仅仅才过去一个多月的时间,谷歌在致力于追求负责任 AI 的前提下,进一步着重思考该系列模型的安全性与可访问性,并且取得了一连串的新成果。
此次,Gemma 2 不但拥有了更为轻量级的“Gemma 2 2B”版本,而且构建了一个安全内容分类器模型“ShieldGemma”以及一个模型可解释性工具“Gemma Scope”。具体情况如下:
-
Gemma 2 2B 具备内置的安全改进功能,达成了性能与效率之间强有力的平衡;
-
ShieldGemma 基于 Gemma 2 所构建,用于对 AI 模型的输入和输出进行过滤,以保障用户的安全;
-
Gemma Scope 提供对模型内部工作原理的无与伦比的洞察力。
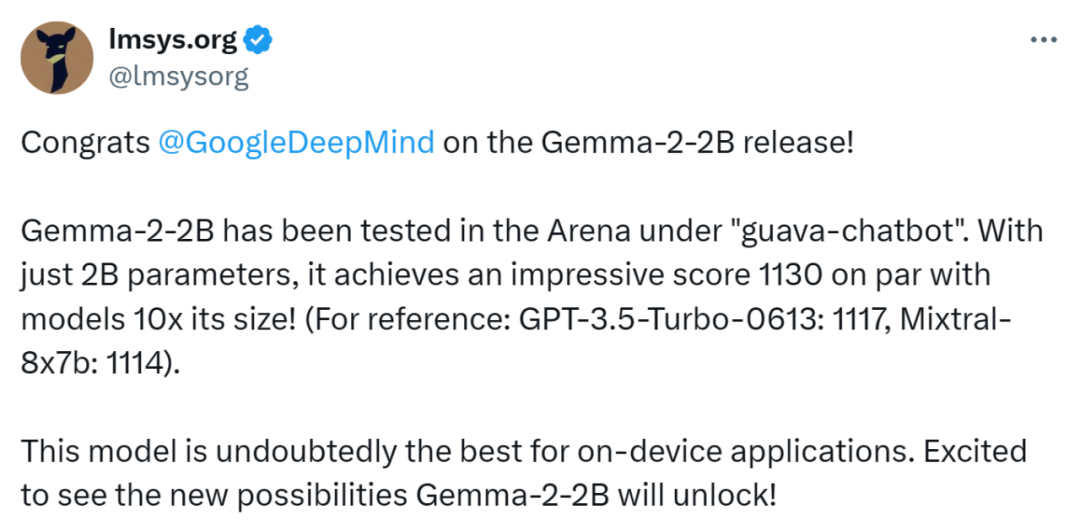
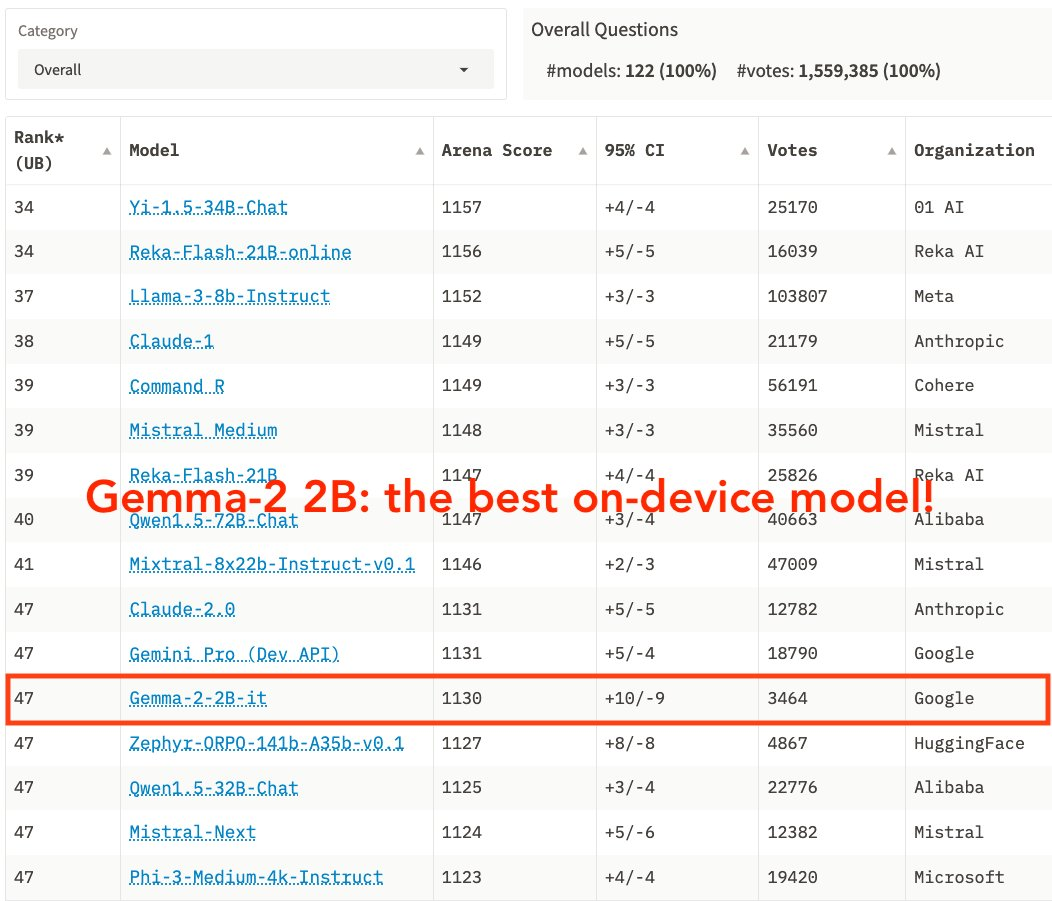
其中,Gemma 2 2B 无疑是“最耀眼的存在”,它在大模型竞技场 LMSYS Chatbot Arena 中的表现令人瞩目:仅仅凭借 20 亿参数便获得了 1130 分,这一分数高于 GPT-3.5-Turbo(0613)和 Mixtral-8x7b。
这也表明,Gemma 2 2B 会成为端侧模型的最优之选。
苹果机器学习研究(MLR)团队的研究科学家 Awni Hannun 展示了 Gemma 2 2B 在 iPhone 15 pro 上的运行情况,采用了 4bit 量化版本,其结果表明速度相当迅捷。
,时长00:25
00:25
视频来源:https://x.com/awnihannun/status/1818709510485389563
此外,针对前段时间众多大模型都出错的“9.9 和 9.11 谁大”这一问题,Gemma 2 2B 也能够轻松应对。
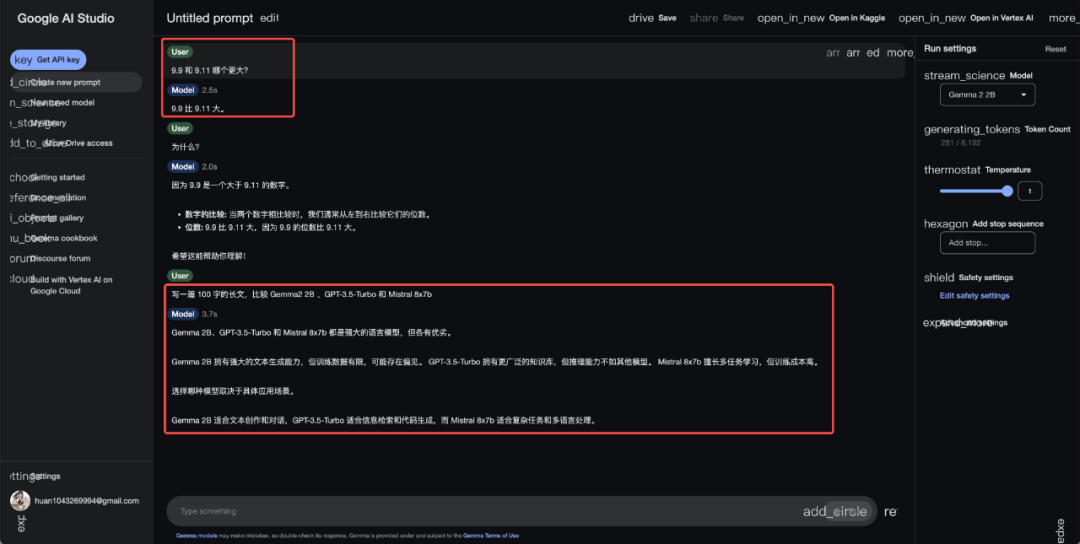
图源:https://x.com/tuturetom/status/1818823253634564134
与此同时,从谷歌 Gemma 2 2B 的强大性能当中也能够看出一种趋向,那就是“小”模型渐渐具备了与尺寸更大的模型相抗衡的信心和效能优势。
这种趋势还引发了部分业内人士的关注,例如知名的人工智能科学家、Lepton AI 的创始人贾扬清提出了这样一种看法:大语言模型(LLM)的模型大小是否正在重蹈卷积神经网络(CNN)的覆辙呢?
在 ImageNet 时代,我们目睹了参数大小迅速增加,随后我们转向了规模更小、效率更高的模型。这是在大语言模型(LLM)时代来临之前的情况,我们当中的许多人或许已经遗忘了。
-
大型模型的曙光:我们把 AlexNet(2012)当作基线开启,接着历经了大概 3 年的模型大小的增长。VGGNet(2014)不管在性能还是尺寸方面都能够称作强大的模型。
-
缩小模型:GoogLeNet(2015)把模型大小从 GB 级缩减到 MB 级,缩小了 100 倍,并且维持了不错的性能。类似的工作比如 SqueezeNet(2015)以及其他工作也遵循着相似的趋势。
-
合理的平衡:后来的工作诸如 ResNet(2015)、ResNeXT(2016)等等,都保持着适度的模型大小。请注意,我们实际上非常愿意运用更多的算力,不过参数高效同样十分重要。
-
设备端学习?MobileNet(2017)是谷歌的一项格外有趣的工作,占用空间极小,但性能却极为出色。上周,我的一个朋友跟我说「哇,我们仍旧在使用 MobileNet,因为它在设备端有着出色的特征嵌入通用性」。是的,嵌入式嵌入的确是实实在在非常好用。
最后,贾扬清发出灵魂一问,“LLM 会遵循同样的趋势吗?”
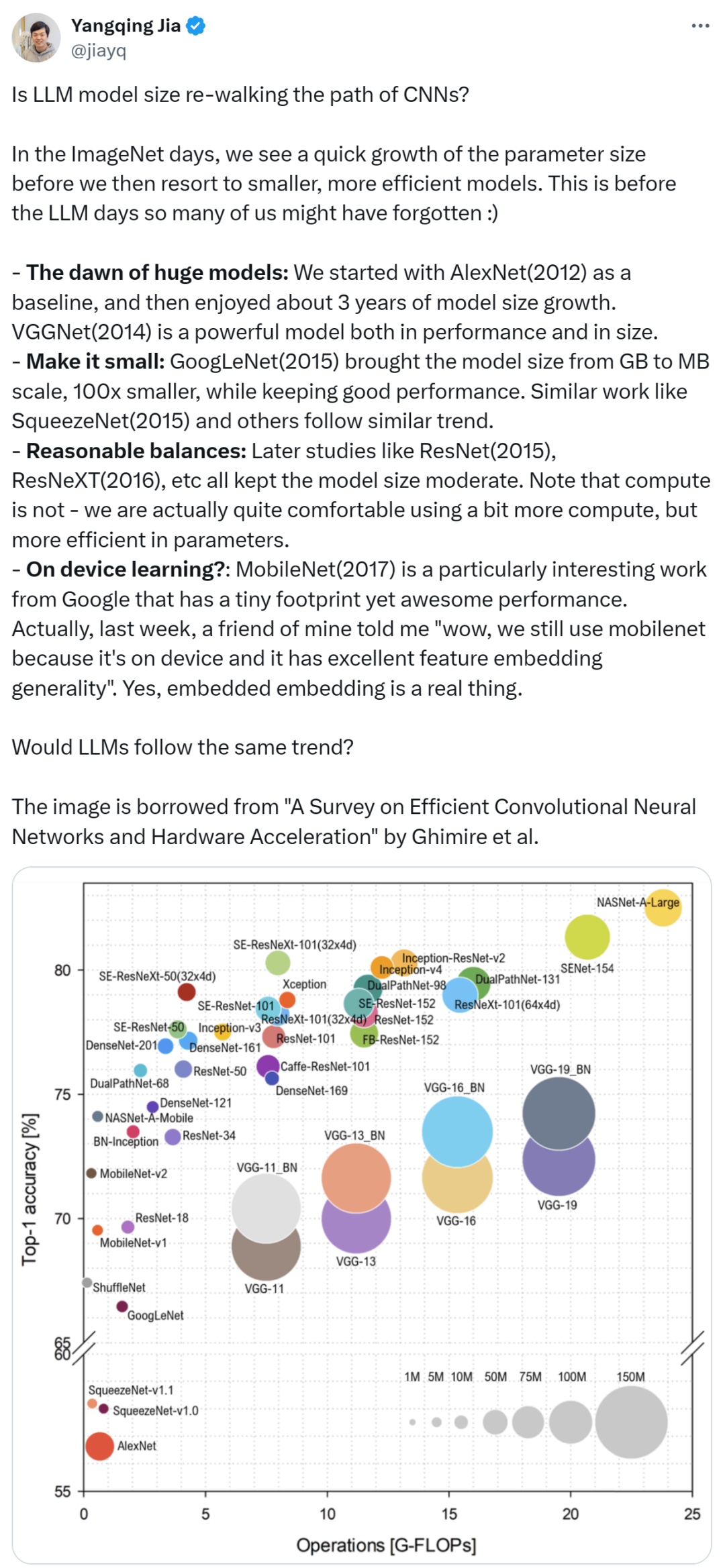
图像出自 Ghimire 等人论文《A Survey on Efficient Convolutional Neural Networks and Hardware Acceleration》。
Gemma 2 2B 越级超越 GPT-3.5 Turbo
Gemma 2 家族新增 Gemma 2 2B 模型,深受大家期待。谷歌运用先进的 TPU v5e 硬件在庞大的 2 万亿个 token 上进行训练而成。
这个轻量级模型是从更大的模型中蒸馏所得,产生了极为出色的结果。因其占用空间小,尤其适合设备应用程序,或许会对移动 AI 和边缘计算带来重大影响。
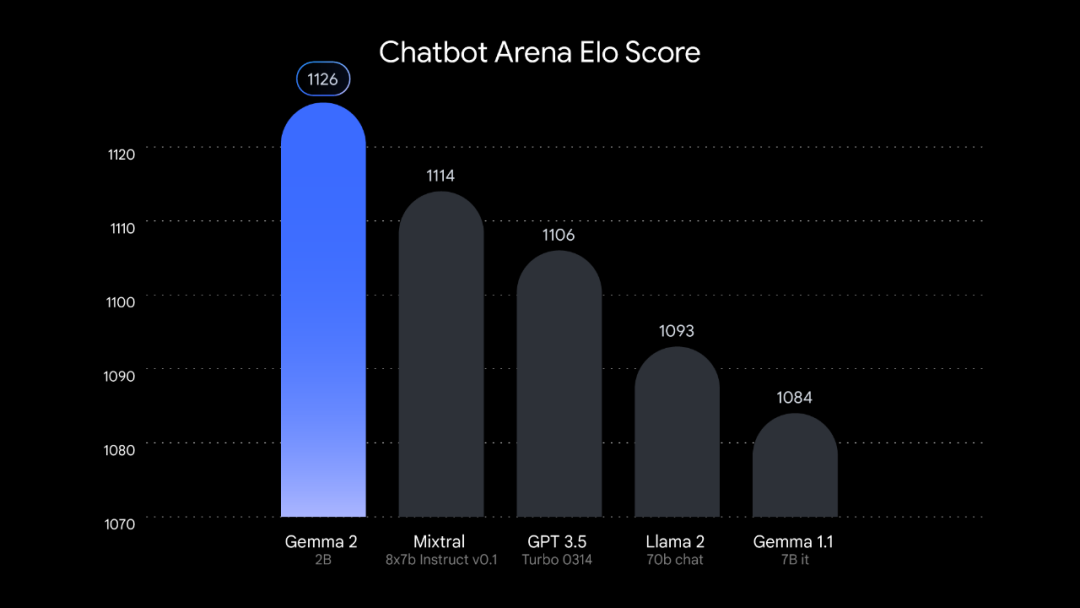
实际上,谷歌的 Gemma 2 2B 模型在 Chatbot Arena Elo Score 排名中超越大型 AI 聊天机器人,展现了小型、更高效的语言模型的潜力。下方图表显示了 Gemma 2 2B 与 GPT-3.5 和 Llama 2 等知名模型相比的卓越性能,对“模型越大越好”的观念发起了挑战。
Gemma 2 2B 提供了:
-
性能超群:于相同规模之中呈现出同类别最优性能,凌驾于同类别其他开源模型之上;
-
部署便捷且成本效益可观:能够在各类硬件上高效运作,涵盖边缘设备、笔记本电脑,乃至借助云部署如 Vertex AI 和 Google Kubernetes Engine (GKE) 。为更显著地提升速度,此模型运用了 NVIDIA TensorRT-LLM 库予以优化,并且能够当作 NVIDIA NIM 加以使用。另外,Gemma 2 2B 能够与 Keras、JAX、Hugging Face、NVIDIA NeMo、Ollama、Gemma.cpp 以及即将问世的 MediaPipe 实现无缝融合,以精简开发流程;
-
开源并且易于获取:能够用于研究以及商业运用,鉴于其规模较小,甚至能够在 Google Colab 的 T4 GPU 免费层级上运转,让实验和开发相较以往变得更为简便。
从今天开始,用户可以从 Kaggle、Hugging Face、Vertex AI Model Garden 下载模型权重。用户还可以在 Google AI Studio 中试用其功能。
下载权重地址:https://huggingface.co/collections/google/gemma-2-2b-release-66a20f3796a2ff2a7c76f98f
Gemma 2 2B 的现身对人工智能开发领域的主流看法发起了挑战,该看法认为模型越大,其性能必然越优。Gemma 2 2B 所取得的成功显示出,复杂的训练技法、高效的架构以及高品质的数据集能够弥补初始参数数量的匮乏。这一突破性成果或许会给该领域带来极为深远的影响,极有可能将关注点从对规模越来越大的模型的争夺,转向对更小且更高效的模型的改进。
Gemma 2 2B 的开发同样彰显了模型压缩和蒸馏技术不断增强的重要性。借由有效地将较大模型当中的知识提炼到较小的模型之中,研究人员能够在不折损性能的状况下打造出更便于获取的 AI 工具。此种方式不但降低了计算方面的需求,还化解了训练和运行大型 AI 模型给环境造成影响的忧虑。
ShieldGemma:最先进的安全分类器

技术报告:https://storage.googleapis.com/deepmind-media/gemma/shieldgemma-report.pdf
ShieldGemma 是一套先进的安全分类器,旨在检测和缓解 AI 模型输入和输出中的有害内容,帮助开发者负责任地部署模型。
ShieldGemma 专门针对四个关键危害领域进行设计:
-
仇恨言论
-
骚扰
-
色情内容
-
危险内容
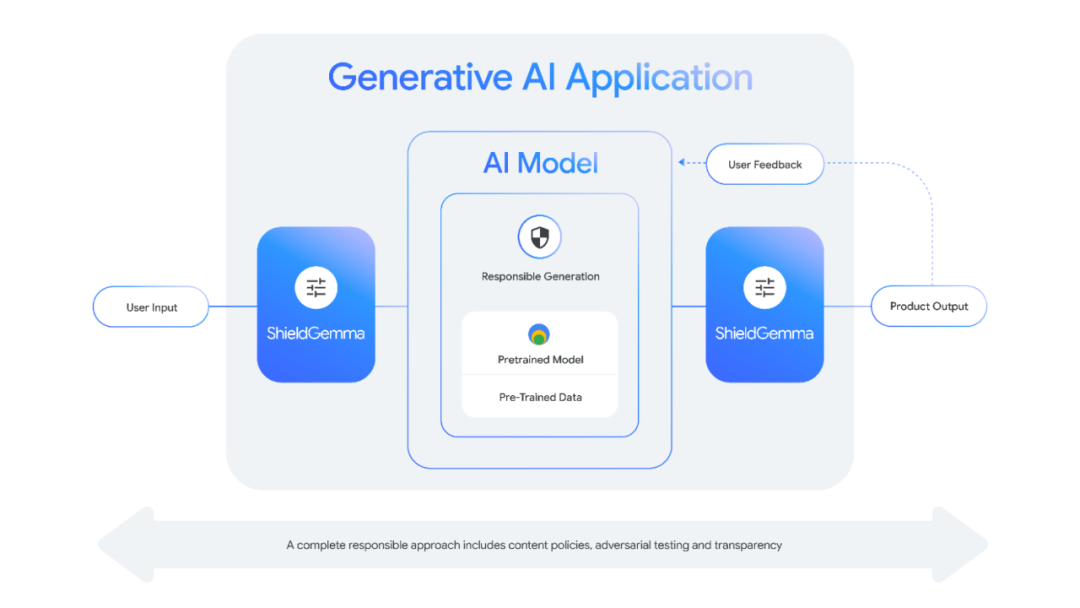
这些开放分类器是对负责任 AI 工具包(Responsible AI Toolkit)中现有安全分类器套件的补充。
借助 ShieldGemma,用户可以创建更加安全、更好的 AI 应用
SOTA 性能:作为安全分类器,ShieldGemma 已经达到行业领先水平;
规模不同:ShieldGemma 提供各种型号以满足不同的需求。2B 模型非常适合在线分类任务,而 9B 和 27B 版本则为不太关心延迟的离线应用程序提供了更高的性能。
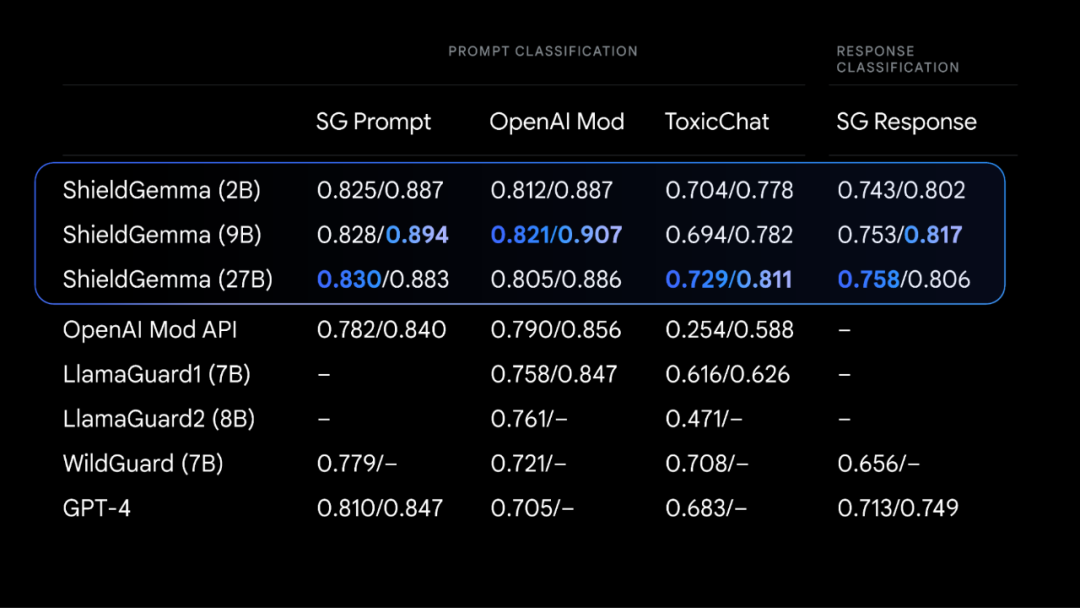
如下表所示,ShieldGemma (SG) 模型(2B、9B 和 27B)的表现均优于所有基线模型,包括 GPT-4。
Gemma Scope:让模型更加透明
Gemma Scope 旨在帮助 AI 研究界探索如何构建更易于理解、更可靠的 AI 系统。其为研究人员和开发人员提供了前所未有的透明度,让他们能够了解 Gemma 2 模型的决策过程。Gemma Scope 就像一台强大的显微镜,它使用稀疏自编码器 (SAE) 放大模型的内部工作原理,使其更易于解释。
Gemma Scope 技术报告:https://storage.googleapis.com/gemma-scope/gemma-scope-report.pdf
SAE 可以帮助用户解析 Gemma 2 处理的那些复杂信息,将其扩展为更易于分析和理解的形式,因而研究人员可以获得有关 Gemma 2 如何识别模式、处理信息并最终做出预测的宝贵见解。
以下是 Gemma Scope 具有开创性的原因:
-
开放的 SAE:超过 400 个免费 SAE,涵盖 Gemma 2 2B 和 9B 的所有层;
-
交互式演示:无需在 Neuronpedia 上编写代码即可探索 SAE 功能并分析模型行为;
-
易于使用的存储库:提供了 SAE 和 Gemma 2 交互的代码和示例。
参考链接:
https://developers.googleblog.com/en/smaller-safer-more-transparent-advancing-responsible-ai-with-gemma/















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









