







目录
Database Design Methodology数据库设计方法
Database Design Methodology数据库设计方法
一种结构化方法,用辅助工具支持和促进设计过程
设计主要阶段main phases:
获得要求-概念数据库设计-逻辑数据库设计-物理数据库设计
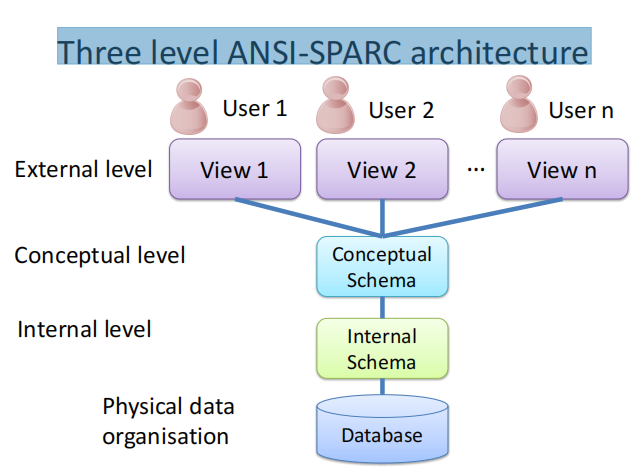
Conceptual database design概念数据库设计
The process of constructing a model of the data used in an enterprise, independent of all physical considerations.构建企业中使用的数据模型的过程,独立于所有物理考虑因素。
Logical database design逻辑数据库设计
Maps the conceptual data model on to a logical model (e.g. relational), but independent of a particular DBMS and other physical considerations.将概念数据模型映射到逻辑模型(如relational)中,独立于特别的DBMS和其他物理因素。(注:DBMS:一种软件系统,用户可以定义、创建、维护和控制对数据库的访问)
Physical database design物理数据库设计
The process of producing a description of the implementation of the database (tailored to specific DBMS); it describes the base relations, file organizations, and indexes design, and any associated integrity constraints and security measures.制作数据库实施说明过程(简化为特定DBMS),描述了基本关系、组织档案和质数设计,以及任何相关的完整性约束和安全措施。
Overview概述概念数据库设计:
Step 1 Build conceptual data model
Step 1.1 Identify entity types
Step 1.2 Identify relationship types
Step 1.3 Identify and associate attributes with entity or relationship types
Step 1.4 Determine attribute domains
Step 1.5 Determine candidate, primary, and alternate key attributes
– Guidelines for choosing candidate, primary, and alternate key attributes:
– the candidate key with the minimal set of attributes;
– the candidate key that is least likely to have its values changed;
– the candidate key with fewest characters (for those with textual attribute(s));
– the candidate key with smallest maximum value (for those with numerical attribute(s));
– the candidate key that is easiest to use from the users’ point of view.
Step 1.6 Consider use of enhanced modeling concepts (optional step)
Step 1.7 Check model for redundancy
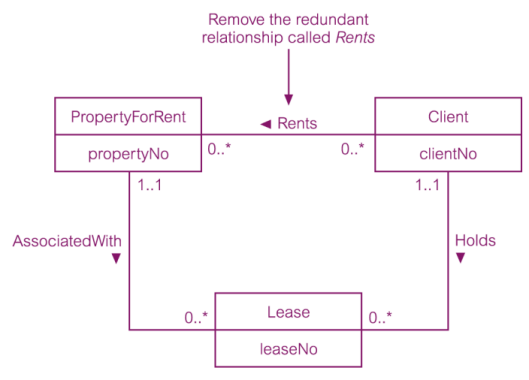
– Re-examine one-to-one (1:1) relationships;Client, Renter
– Remove redundant relationships;
– Consider time dimension.
Step 1.8 Validate conceptual model against user transactions
Step 1.9 Review conceptual data model with user

Step 2 Build and validate logical data model
Step 2.1 Derive relations for logical data model
Step 2.2 Validate relations using normalization
Step 2.3 Validate relations against user transactions
Step 2.4 Check integrity constraints
– To check integrity constraints are represented in the logical data model. This includes
identifying:
– Required data (value not allowed to be null)
– Attribute domain constraints
– Multiplicity (*:* relationships)
– Entity integrity (primary key can not be null)
– Referential integrity (foreign keys)
– General constraints
Step 2.5 Review logical data model with user
Step 2.6 Merge logical data models into global model (optional step)
Step 2.7 Check for future growth
参照完整性Referential integrity:


Step 3 Translate logical data model for target DBMS
– Step 3.1 Design base relations
– Step 3.2 Design representation of derived data
– Step 3.3 Design general constraints
Step 4 Design file organizations and indexes
– Step 4.1 Analyze transactions
– Step 4.2 Choose file organization
– Step 4.3 Choose indexes
– Step 4.4 Estimate disk space requirements
Step 5 Design user views
Step 6 Design security mechanisms
Step 7 Consider the introduction of controlled redundancy
Step 8 Monitor and tune the operational system
SQL JOIN
A NATURAL JOIN B joins on all duplicate attributes leaving a table with no duplicate
attributes
• A JOIN B USING (C) joins on attribute C only leaving a table with no duplicate attribute C.
• A JOIN B ON A.Attribute = B.Attribute is just the same as A, B WHERE A.Attribute = B.Attribute
• A CROSS JOIN B produces the Cartesian product
• Outer JOINS (LEFT JOIN, RIGHT JOIN, FULL JOIN) allow us to add NULL entries where there is no match
一个自然的JOINB在所有重复的属性上连接,留下一个没有重复属性的表。一个JOINB使用属性C上的(C)连接,只留下一个没有重复属性的表 C. • A连接b上 A. 属性“=” B. 属性和A,B一样 A. 属性“=” B. 属性A交叉连接B生成笛卡尔积外部连接(左连接,右连接,全连接)允许我们在没有匹配的地方添加NULL条目















 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









