







定义Definition:
The process of extracting valid, previously unknown, comprehensible, and actionable information from large databases and using it to make crucial business decisions. 从大数据库中提取合法、未知、可行的信息用于决策。
Involves the analysis of data and the use of software techniques for finding hidden and unexpected patterns and relationships in sets of data. 包括数据分析,和软件技术寻找隐藏信息关联的运用。
特点Characteristics:
1、揭露隐藏在数据库中的信息Reveals information that is hidden and unexpected.
2、关系需要通过数据库中数据的特点得出Patterns and relationships are identified by examining the underlying rules and features(底层规则和特征) in the data.
3、准确的数据结论需要大量数据做支撑 Most accurate results normally require large volumes of data to deliver reliable conclusions.
使用和优势Use andadvantages:
1、大量投入会获得大量回报 Data mining can provide huge paybacks for companies who have made a significant investment in data warehousing
2、越来越多的行业开始使用数据挖掘• A relatively new technology but is already being used in more and more industries.
操作Operations:
技术是数据挖掘操作的特定实现,每种方法使用的操作不一样
Predictive modelling 模型预测
使用监督学习方法(supervised learning approach)开发
(和人类学习经历类似)利用观察来形成某些现象的重要特征的模型,把新数据纳入一半框架, Can analyse a database to determine essential characteristics (model) about the data set可以分析一个数据库,以确定关于数据集的基本特征(模型).
Two phases两个阶段
*Training:建模 builds a model using a large sample of historical data called a training set.
*Testing:试验模型involves trying out the model on new, previously unseen data to determine its accuracy and physical performance characteristics.
Two technique:
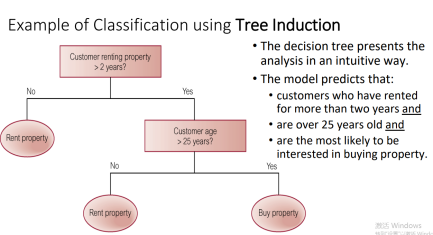
*Classification 分类: 从有限的可能的类值集合中为数据库中的每个记录建立一个特定的预定类Used to establish a specific predetermined class for each record in a database from a finite set of possible, class values
//两种专门化specializations
Tree induction树诱导:直观方式展现分析
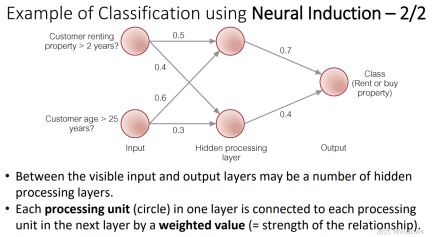
Neural induction神经诱导
结合算数与数据点,模拟大脑中的操作
输入输出层中有很多隐藏层
*Value Prediction 估值预测:
估计与数据库记录相关的连续数据,,利用大量数据记录估计,,传统方法 线性/非线性回归( traditional statistical techniques of linear/non-linear regression),,相对易于理解和使用
Database segmentation 数据库划分
用于提高数据库中相关数据的准确性
对冗余和不相关的特征不敏感
与人口统计学、神经聚集相关
Link analysis 联系分析
在数据库之间找到相关联的实体并建立连接
Types:
1、associations discovery 关联发现
2、sequential pattern discovery数据模式发现
3、similar time sequence discovery时间顺序发现
Deviation detection 误差检测
识别异常值(偏离了一些先前已知的期望和范数)Identifies outliers, which express deviation from some previously known expectation and norm.
通过数据统计和可视化执行Can be performed using statistics and visualization techniques //e.g., using regression to identify outliers.

和Data Warehousing数据仓库比较
数据仓库可以为挖掘提供数据:数据质量和一致性是挖掘的先决条件,以确保预测模型的准确性。Mining建立在Warehousing的基础上 Data warehousing relates to the storage of the data used for data mining.
No SQL(Not Only SQL 非关系型数据库)
应对当今大数据时代以及传统Relational Model的限制而产生的新型数据库
来源origin:谷歌,亚马逊
开源社区Vibrant Open Source community:followed with Hadoop, HBase, MongoDB, Cassandra, RabbitMQ, and countless other projects
Key features关键特性:
Flexible Schema 灵活
Quicker/Cheaper Set up 低成本快速
Massive Scalability 数据大规模
Relaxed Consistency ——High Performance/Availability可用性强
缺点:
No declarative query language --> more programming没有声明的语言
Relaxed consistency --> fewer guarantees缺乏一致性
BASE:(not ACID)
对读取的一致性有限
BASE” instead of “ACID”:
• BASE = Basically Available, Soft state, Eventually consistent 基本可用,软状态,最终一致的
• ACID = Atomicity, Consistency, Isolation, Durability原子性,一致性,隔离,持久性
放弃ACID约束,可以实现更高的性能和可伸缩性By giving up ACID constraints, one can achieve much higher performance and scalability.

NoSQL System Types
MapReduce frameworks MapReduce框架
(Google,For processing and generating big data sets with a parallel, distributed algorithm on a cluster.用于在集群上使用并行的分布式算法来处理和生成大数据集)
Key-value stores关键词储存
简单接口Extremely simple interface:
-Data model: (key, value) pairs
-Operations: Insert(key,value), Fetch(key), Update(key),
Document stores文档储存
同上,储存值为文档Like Key-Value Stores except value is document
-Data model: (key, document) pairs
-Document: JSON, XML, other semi-structured formats
-Basic operations: Insert(key,document), Fetch(key),Update(key), Delete(key)
Graph database systems图形数据库储存
数据模型:节点和边节点可能有属性(包括ID)边可能有标签或角色界面和查询语言不同的单步与“路径表达式”与完整递归Data model: nodes and edges• Nodes may have properties (including ID)• Edges may have labels or roles• Interfaces and query languages vary• Single-step versus “path expressions” versus full recursion
Why we need:
更新少,频繁访问//没有固定结构//处理简单的
Not be used for不能用于
需要频繁更新数据库的,或者是ACID要求的//大型,分散的数据库 更适合Relational Model//类似Transaction的操作模型
其他:
NoSQL is an alternative, non-traditional DB technology to be used in large scale environments where (ACID) transactions are not a priority.NoSQL是一种替代的非传统DB技术,用于(ACID)事务不是优先级的大规模环境中。















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









