







在写一道题时,首先想到的是怎么取存储输入输出的数据,使我们操作更加方便,处理的更快,所以我们来认识数据结构,认识数据存储:
单值:变量
连续:1维数组(行)、2维数组(面)、3维数组(体)
离散:链表(插入删除多的1维数组)
行长度不同的二维表:vector<string>或vector<vector>
…
不要拘泥于现有认知的数据结构,可以通过STL的组合灵活构造。
1 栈stack
只能在栈顶一端进行入栈和弹栈操作,它满足先进后出的特性
只能在栈顶一端进行入栈和弹栈操作,它满足先进后出的特性
只能在栈顶一端进行入栈和弹栈操作,它满足先进后出的特性
①STL栈stack:
#include <stack>中可以用stack<int> st来定义一个全局栈来储存整数的空的stack。当然stack可以存任何类型的数据,比如stack<string> st等等。
②数组模拟栈:
只能使用C语言机试的同学直接用数组模拟栈即可。
// 初始化栈
int stk[N], top=-1;
// 插入元素
stk[++top] = x;
// 弹出元素
c = stk[top--];
// 取栈顶值
stk[top];
// 判断栈是否为空
if (top == -1)
常见应用方式:
1、计算表达式的值
2、带优先级的括号匹配问题
2 队列queue
只能在队尾入队和队头出队操作,它满足先进先出的特性
只能在队尾入队和队头出队操作,它满足先进先出的特性
只能在队尾入队和队头出队操作,它满足先进先出的特性
STL队列queue:
#include <queue>中可以用queue<int> q来定义一个全局队列来储存整数的空的queue。当然queue可以存任何类型的数据,比如queue<string> q等等。
q.push(something);//入栈
q.pop();//出栈
q.top();//取栈顶元素值
q.empty();//判断栈空
STL优先队列priority_queue:自动排序(可重复)
#include <priority_queue>
//升序队列:小顶堆
priority_queue <int,vector<int>,greater<int> > q;
//降序队列:大顶堆
priority_queue <int,vector<int>,less<int> >q;
/*
和队列基本操作相同:
top 访问队头元素
empty 队列是否为空
size 返回队列内元素个数
push 插入元素到队尾 (并排序)
emplace 原地构造一个元素并插入队列
pop 弹出队头元素
swap 交换内容
*/
//使用基本数据类型时,只需要传入数据类型,默认是大顶堆。
//对于基础类型 默认是大顶堆
priority_queue<int> a; //等同于 priority_queue<int, vector<int>, less<int> > a;
//用自定义类型,需重载自定义类型的<运算符
struct tmp1 {
int x;
//构造函数
tmp1(int a) {x = a;}
//运算符重载<
bool operator<(const tmp1& a) const {
return x < a.x; //大顶堆
}
};
priority_queue<tmp1> d;
3 链表
对于使用OJ测评的院校的同学来说,这类问题可以用数组来实现,没有必要用链表去实现,写起来慢不说,还容易出错,所以我们一般都直接用数组来实现,反正最后OJ能AC就行。
但是对于非OJ测评的院校来说,链表类问题可以说是必考的题型。
一般来说有以下三种常见考点:
1、约瑟夫环
解析:n个节点的循环链表建立之后,按照题意(间隔m个节点)删除节点,求删除顺序。三种解法:数组、循环链表、递归
//循环链表实现
#include<bits/stdc++.h>
using namespace std;
#define rep(i,s,e) for(int i=s;i<e;i++)
#define per(i,s,e) for(int i=s;i>e;i--)
struct node{
int num;
node* next=nullptr;
};
//创建循环链表
struct node* create(int n) {
struct node *head, *now, *pre;
rep(i,1,n+1) {
now = new node;
if (i == 1) {
head = now; //头节点
pre = now; //now前一个
}
now->num = i;
now->next = head;
pre->next = now;
pre = now;
}
return head;
};
void print(node*root){
int flag=1;
node *current=root,*pre;
while(current->next!=current){
if(flag){
flag=0;
pre=current->next;//当前表演的前一个
current=pre->next;//推进两下
pre->next=current->next;
}
else{
pre=current->next->next;//当前表演的前一个
current=pre->next;//推进三下
pre->next=current->next;
}
cout<<current->num;
}
}
int main(){
int n;
cin>>n;
node *root=create(n);
print(root);
return 0;
}
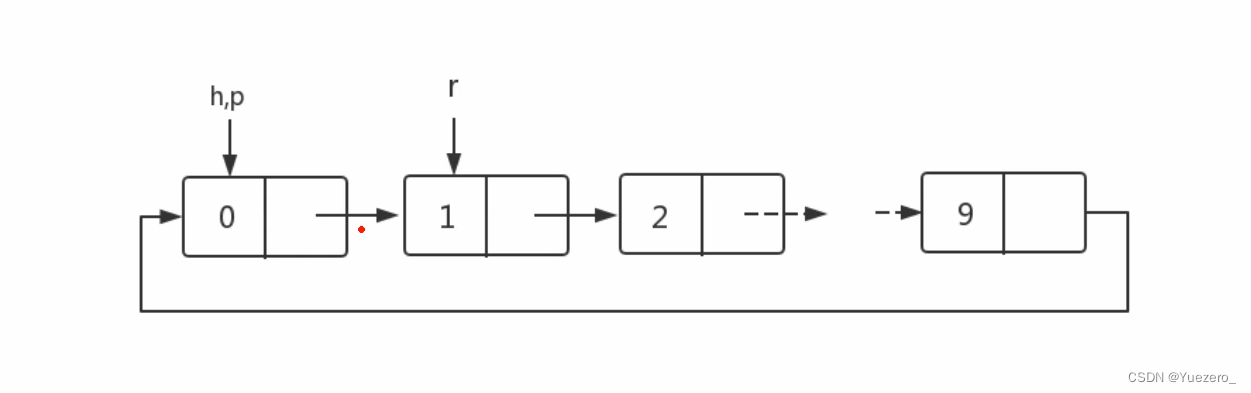
//数组实现
#include<bits/stdc++.h>
using namespace std;
#define rep(i,s,e) for(int i=s;i<e;i++)
#define per(i,s,e) for(int i=s;i>e;i--)
int a[101]={0};//开数组的大小根据题目上限决定,初始全0
//a[i]=0表示i没有出局,a[i]=1表示i出局,a[0]不用
int main(){
int n,m;
int cnt=0,i=0,k=0;//cnt记录当前出局的人数,i用于控制循环遍历n个人,k用于记录是否循环m个人
cin>>n>>m;//n表示约瑟夫环总人数,m表示每隔m个人就出局
while(cnt!=n){
i++;
if(i>n) i=1;//i超过n时,返回1进行循环
if(a[i]==0){
k++;
if(k==m){
a[i]=1;//i号出局
cnt++;//出局人数++
cout<<i<<" ";
k=0;//清空k,重新从0开始报数
}
}
}
return 0;
}

//递归实现
2、有序链表合并
解析:这个和两个有序数组合并为一个有序数组原理一样。
3、链表排序
解析:使用冒泡排序进行链表排序,因为冒泡排序是相邻两个元素进行比较交换,适合链表。
4 二叉树
- 树的本质就是多个子节点的链表,根节点指针=表头指针,子节点用
vector<node*> childern保存。 - 二叉树就是限定每个节点的子节点不超过2个,子节点用
node* left; noed* right保,左子树和右子树是有顺序的,次序不能任意颠倒。
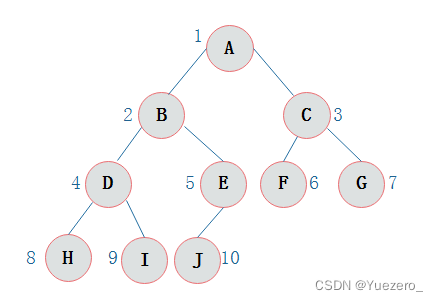
二叉树的建立:
二叉树的遍历:(递归实现)
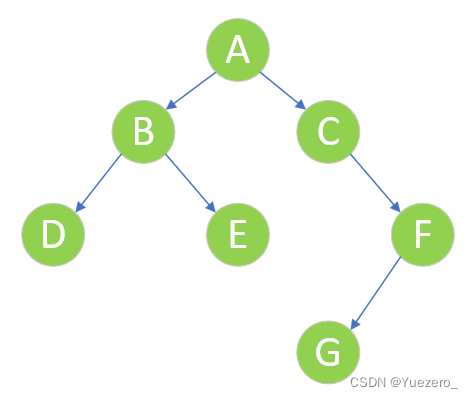
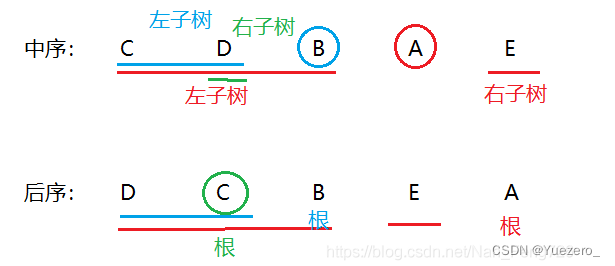
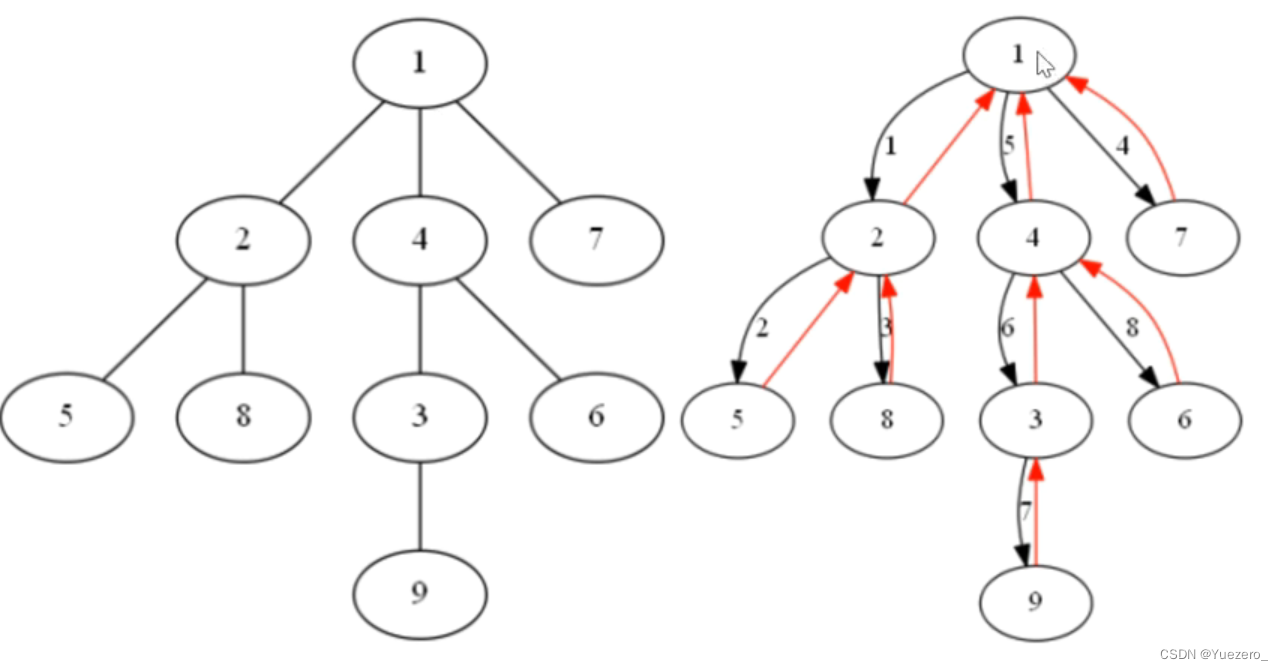
前序遍历(根左右):从二叉树的根结点出发,当第一次到达结点时就输出结点数据,按照先向左再向右的方向访问。对于上图,遍历顺序如下:ABDHIEJCFG中序遍历(左根右):从二叉树的根结点出发,当第二次到达结点时就输出结点数据,按照先向左再向右的方向访问。对于上图,遍历顺序如下:HDIBJEAFCG后序遍历(左右根):从二叉树的根结点出发,当第三次到达结点时就输出结点数据,按照先向左再向右的方向访问。对于上图,遍历顺序如下:HIDJEBFGCA层序遍历:按照树的层次自上而下的遍历二叉树。对于上图,遍历顺序如下:ABCDEFGHIJ
判断二叉树对称:先建树,先序遍历的“根左右” = 先序遍历的“根右左”,则二叉树对称。
遍历常考考点(建树!!!)
对于二叉树的遍历有一类典型题型。
通过中序遍历和先序遍历 可以 确定一个树
通过中序遍历和后续遍历 可以 确定一个树
通过先序遍历和后序遍历 不可以 确定一个树。
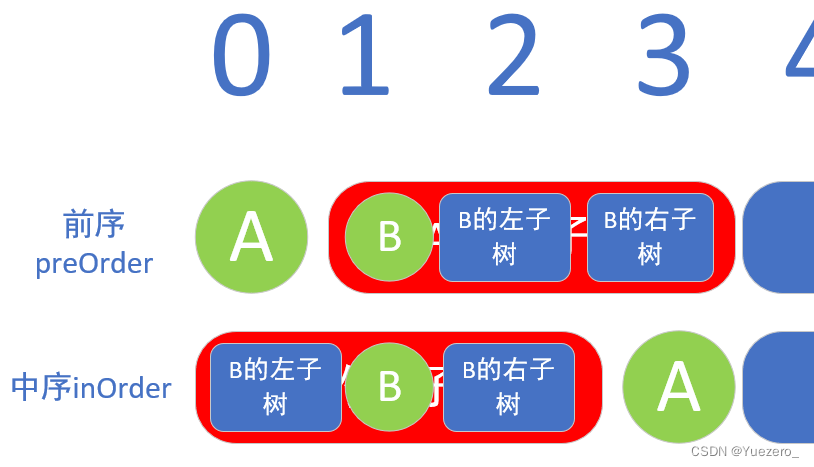
1)前序序列+中序序列,构建二叉树。
- 前序遍历是ABDECFG
- 中序遍历是DBEACGF
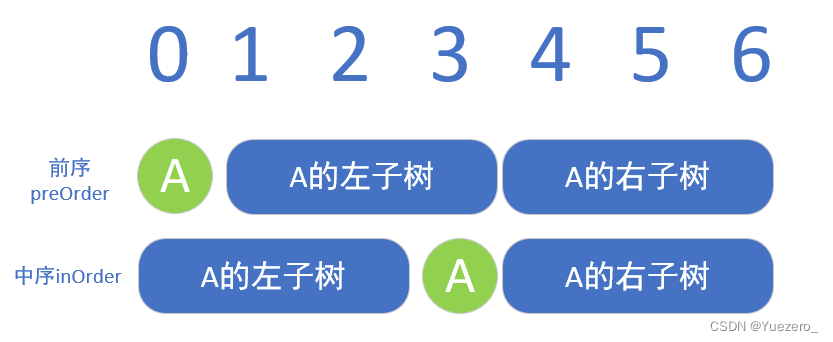
这样我们就构造出第一个点。以preOrder[1…3]作为新的前序,inOrder[0…2]作为新的中序,就可以构造出A的左子树(右也同理)。
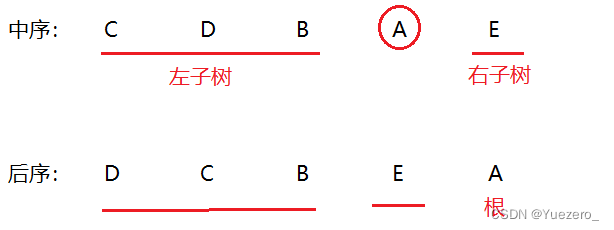
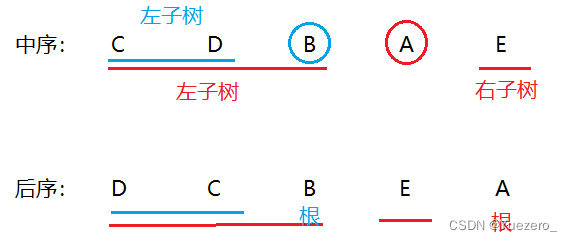
2)后序序列+中序序列,构建二叉树。
后序遍历中最后访问的为根结点,因此可以按照上述同样的方法,找到根结点后分成两棵子树,进而继续找到子树的根结点,一步步确定二叉树的形态。
#include<bits/stdc++.h>
using namespace std;
#define rep(i,s,e) for(int i=s;i<e;i++)
#define per(i,s,e) for(int i=s;i>e;i--)
const int MAXN = 100005;
const int INF = 1e9;
typedef struct Tnode{
string data;
Tnode* lchild;
Tnode* rchild;
};
void pre_travse(Tnode* T){
if(T==NULL)return;
else{
cout<<T->data;
pre_travse(T->lchild);
pre_travse(T->rchild);
}
}
void post_travse(Tnode* T){
if(T==NULL)return;
else{
post_travse(T->lchild);
post_travse(T->rchild);
cout<<T->data;
}
}
//BFD A EGC
//FDB GEC A
Tnode* build_tree(string mid, string post) {
if (post.empty()) return NULL;
char r = post[post.size()-1]; // 根节点
int r_idx = mid.find(r); // 根节点在中序遍历中的位置
Tnode* root = new Tnode;
root->data = r;
root->lchild = build_tree(mid.substr(0, r_idx), post.substr(0, r_idx));
root->rchild = build_tree(mid.substr(r_idx+1), post.substr(r_idx, post.size()-r_idx-1));
return root; // 返回根节点
}
//BFD A EGC
//A BDF CEG
Tnode* build_tree2(string mid, string pre) {
if (pre.empty()) return NULL;
char r = pre[0]; // 根节点
int r_idx = mid.find(r); // 根节点在中序遍历中的位置
Tnode* root = new Tnode;
root->data = r;
root->lchild = build_tree2(mid.substr(0, r_idx), pre.substr(1, r_idx));
root->rchild = build_tree2(mid.substr(r_idx+1), pre.substr(r_idx+1));
return root; // 返回根节点
}
int main() {
string mid, pre;
cin >> mid >> pre;
Tnode* root = build_tree2(mid, pre);
post_travse(root);
return 0;
}
5 哈夫曼树与编码
哈夫曼树定义:给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree)。哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近。
考法:
1、直接要求构造哈夫曼树,输出WPL带权路径长度。
2、考察概念的理解,如例题合并果子。
3、考察哈夫曼编码
哈夫曼编码:广泛地用于数据文件压缩的十分有效的变长编码。实际应用中各字符的出现频度不相同,用短(长)编码表示频率大(小)的字符,使得编码序列的总长度最小,使所需总空间量最少 。
若假设 A, B, C, D 的编码分别为 0,00,1,01,则电文 ‘ABACCDA’ 便为 ‘000011010’(共 9 位),但此编码存在多义性:可译为: ‘BBCCDA’、‘ABACCDA’、‘AAAACCACA’ 等。所以我们要求任一字符的编码都不能是另一字符编码的前缀,这种编码称为前缀编码(其实是非前缀码)。 在编码过程要考虑两个问题,数据的最小冗余编码问题,译码的惟一性问题,利用哈夫曼树可以很好地解决上述变长编码问题。左0右1,字符在叶子节点
假设各个字符在电文中出现的次数(或频率)为 wi ,其编码长度为 li,电文中只有 n 种字符,则电文编码总长为:

设计电文总长最短的编码,设计哈夫曼树(以 n 种字符出现的频率作权)。
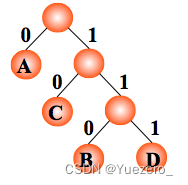
(1)编码
例:如果需传送的电文为 ‘ABCACCDAEAE’,即:A, B, C, D, E 的频率(即权值)分别为0.36, 0.1, 0.27, 0.1, 0.18,试构造哈夫曼编码。
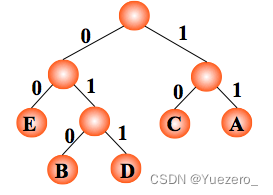
编码: A:11,C:10,E:00,B:010,D:011 ,则电文 ‘ABCACCDAEAE’ 便为 ‘110101011101001111001100’(共 24 位,比 33 位短)。
(2)译码
从哈夫曼树根开始,对待译码电文逐位取码。若编码是“0”,则向左走;若编码是“1”,则向右走,一旦到达叶子结点,则译出一个字符;再重新从根出发,直到电文结束。
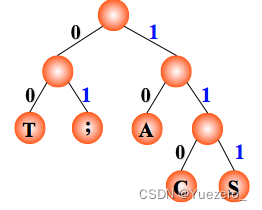
电文为 “1101000” ,译文只能是“CAT”
下面用的是最笨的办法,更优的方法实现哈夫曼树是用 优先队列 或 <运算符重载,来维持树集合的有序性。
#include<bits/stdc++.h>
using namespace std;
#define rep(i,s,e) for(int i=s;i<e;i++)
#define per(i,s,e) for(int i=s;i>e;i--)
typedef struct Tnode {
int data;
Tnode* lchild=NULL;
Tnode* rchild=NULL;
} Tnode;
void INSERT(vector<Tnode*> &tree_set,Tnode* c){
rep(i,0,tree_set.size()){
if(tree_set[i]->data >= c->data){
tree_set.insert(tree_set.begin()+i,c);
return;
}
}
tree_set.push_back(c); // 如果找不到比插入节点大的,就直接插入到最后面
}
Tnode* build_hfmtree(vector<int> w){
vector<Tnode*> tree_set;
sort(w.begin(),w.end());
rep(i,0,w.size()){
Tnode* a=new Tnode;
a->data=w[i];
tree_set.push_back(a);
}
while(tree_set.size()!=1){
Tnode* a=tree_set[0];
Tnode* b=tree_set[1];
Tnode* c=new Tnode; c->data=a->data+b->data;
c->lchild=a;c->rchild=b;
tree_set.erase(tree_set.begin(),tree_set.begin()+2);
INSERT(tree_set,c);
}
return tree_set[0];
}
int w_sum = 0;
void Sum_of_weight(Tnode* t, int layer) {
if (t->lchild == NULL && t->rchild == NULL) {
w_sum += t->data * layer;
return ;
}
if (t->lchild != NULL) Sum_of_weight(t->lchild, layer + 1);
if (t->rchild != NULL) Sum_of_weight(t->rchild, layer + 1);
}
int main() {
int n,t; vector<int> w;
while(cin>>n){
rep(i,0,n) {cin>>t;w.push_back(t);}
Tnode* root = build_hfmtree(w);
Sum_of_weight(root,0);
cout<<w_sum<<endl;
w_sum=0;
w.clear();
}
return 0;
}
6 二叉排序树
二叉排序树(Binary Sort Tree),又称二叉查找树(Binary Search Tree),亦称二叉搜索树。
(左小右大)中序遍历就可以得到关键码从小到大的排列
定义:一棵空树,或者是具有下列性质的二叉树:
(1)若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
(2)若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
(3)左、右子树也分别为二叉排序树;
(4)没有键值相等的结点。
二叉排序树有两种考法
1、考察定义的理解,根据定义建立二叉排序树,然后输出其先序、中序、后序。
2、考察二叉排序树的应用,例如多次查找,建立二叉排序树之后将查找的复杂度从线性降低到log级别。对于可以使用C++的同学而言,直接用前面讲过的map即可。
#include<bits/stdc++.h>
using namespace std;
#define rep(i,s,e) for(int i=s;i<e;i++)
#define per(i,s,e) for(int i=s;i>e;i--)
struct Tnode {
int data;
Tnode* lchild=NULL;
Tnode* rchild=NULL;
};
Tnode* insert(Tnode* root,Tnode* t){
if(root->data==t->data) return root;
else if(root->data > t->data){
if(root->lchild==NULL) {root->lchild=t;return root;}
else return insert(root->lchild,t);
}
else{
if(root->rchild==NULL) {root->rchild=t;return root;}
else return insert(root->rchild,t);
}
}
//1 6 5 9 8
Tnode* build_sorttree(Tnode* tree_root,vector<int> num){
Tnode* root = NULL;
rep(i,0,num.size()){
Tnode* t=new Tnode;
t->data=num[i];
if(i==0) root=t;
else insert(root,t);
}
return root;
}
void pre_travse(Tnode* t){
if(t==NULL){
return;
}else{
cout<<t->data<<' ';
pre_travse(t->lchild);
pre_travse(t->rchild);
}
}
void mid_travse(Tnode* t){
if(t==NULL){
return;
}else{
mid_travse(t->lchild);
cout<<t->data<<' ';
mid_travse(t->rchild);
}
}
void post_travse(Tnode* t){
if(t==NULL){
return;
}else{
post_travse(t->lchild);
post_travse(t->rchild);
cout<<t->data<<' ';
}
}
int main() {
int n,t; vector<int> num;
while(cin>>n){
rep(i,0,n) {cin>>t;num.push_back(t);}
Tnode* root = build_sorttree(root,num);
num.clear();
}
return 0;
}
7 前缀树
8 搜索(DFS/BFS/A*)
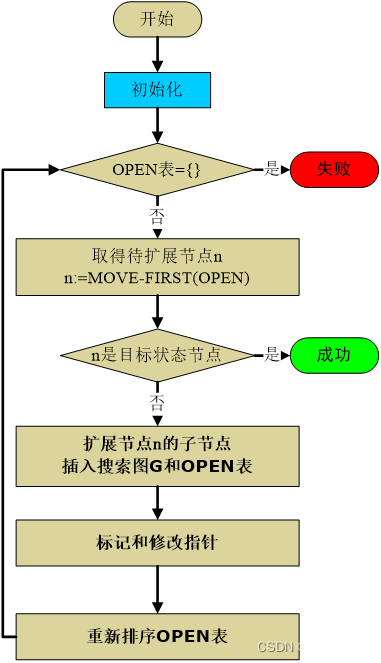
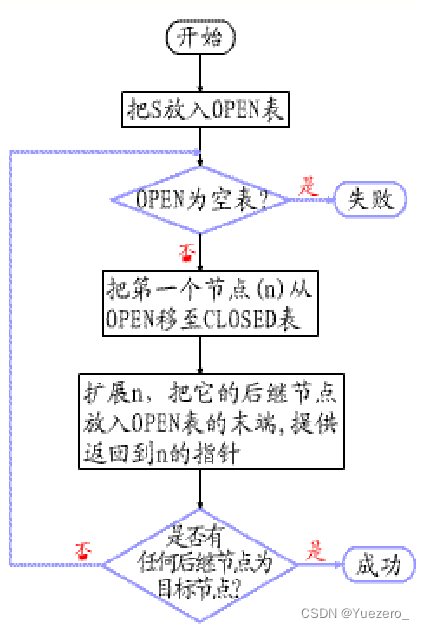
OPEN表存待扩展节点,CLOSE表存已经扩展节点。
OPEN表首节点,扩展子节点(每次保证扩展顺序不变!),OPEN表的重排顺序不同,导致搜索方法不同。
BFS广搜:OPEN表是队列
DFS深搜:OPEN表是栈(可以用递归模拟)
8.1 暴力搜索(枚举)
枚举算法是在分析问题时,逐个列举出所有可能情况,然后根据条件判断此答案是否合适,合适就保留,不合适就丢弃,最后得出一个结论。主要利用计算机运算速度快、精确度高的特点,对要解决问题的所有可能情况,一个不漏地进行检验,从中找出符合要求的答案,因此枚举法是通过牺牲时间来换区答案的全面性。
多层for嵌套枚举,经典例题:百钱百鸡
8.2 BFS广度优先搜索
层次遍历(OPEN表是队列):从起点开始一层一层的扩散出去,要实现这个一层一层的扩散就要用到队列的先进先出的思想,所以一般我们都用队列来实现广度优先搜索算法。
例题、走迷宫(开一个二维数组做map,不单独设置close表,而是设置一个与map等大小的标记数组vis标记节点是否被扩展过)
//#include<bits/stdc++.h>
#include<iostream>
#include<string>
#include<cstring>
#include<vector>
#include<queue>
using namespace std;
#define rep(i,s,e) for(int i=s;i<e;i++)
#define per(i,s,e) for(int i=s;i>e;i--)
const int maxn = 100 + 5;
char mpt[maxn][maxn];//map
int vis[maxn][maxn];//is visited = 0/1
int dir[4][2] = {0, 1, 1, 0, 0, -1, -1, 0};//(x+0,y+1),(x+1,y+0),(x+0,y-1),(x-1,y+0),
struct node {
int x, y;
int step;
};
//使用广度优先搜索求解
int bfs(int sx, int sy) {
memset(vis, 0, sizeof(vis));
queue<node> q;//使用队列open来维护一层层发散的优先级
q.push(node{sx, sy, 0});
vis[sx][sy] = 1;
int ans = -1;
while(!q.empty()) {//直到open表为空
node now = q.front();//队首元素
q.pop();//队首出队
if (mpt[now.x][now.y] == 'E') {//找到终点
ans = now.step;
break;
}
for (int i = 0; i < 4; i++) {//上下左右四个方向 扩展入队
int nx = now.x + dir[i][0];
int ny = now.y + dir[i][1];
if ((mpt[nx][ny] == '*' || mpt[nx][ny] == 'E')&&vis[nx][ny] == 0) {
q.push(node{nx, ny, now.step + 1});
vis[nx][ny] = 1;
}
}
}
return ans;
}
int main() {
int h, w;
while (scanf("%d%d", &h, &w) != EOF) {
if (h == 0 && w == 0) break;
int sx = 0, sy = 0;
memset(mpt, 0, sizeof(mpt));
memset(vis, 0, sizeof(vis));
for (int i = 1; i <= h; i++) {
scanf("%s", mpt[i] + 1);
for (int j = 1; j <= w; j++) {
if (mpt[i][j] == 'S') {
sx = i, sy = j;//记录起点坐标
}
}
}
int ans = bfs(sx, sy);
printf("%d\n", ans);
}
return 0;
}
8.3 DFS深度优先搜索
简单来说,BFS和DFS到底有什么区别呢?
对于一棵二叉树,
BFS就是二叉树的层次遍历,一层一层的扩展下去。
DFS就是二叉树的中序遍历,一条路走到底,然后回溯走第二条,直到所有路都走完。
递归实现DFS很重要的一个操作是回溯!
void dfs(vertex V){
visited[V]=1;
for(V的每个邻接节点W){
if(!visiited[W]){
visiited[W]=1;
dfs(W);
visiited[W]=0;//跳出dfs递归后,回溯取消访问标记
}
}
}
大家需要注意的是,DFS一般情况下效率不如BFS,比如求DFS中的迷宫的最短路径使用DFS就会超时。
例. 全排列
#include<bits/stdc++.h>
#define rep(i,s,e) for(int i=s;i<e;i++)
#define per(i,s,e) for(int i=s;i>e;i--)
using namespace std;
string s,substring;//substring起到了原板子中step深度记录的作用,也可以理解为OPEN表的栈
vector<int> v;
void digui(string s){
rep(i,0,s.size()){
if(v[i]==0){
//记录当前节点
substring+=s[i];
v[i]=1;
//递归继续向下遍历,直到substring与原字符串等长,输出
if(substring.size()==s.size()) cout<<substring<<endl; // dfs剪枝:剪去序列长度大于原序列的枝条
else digui(s);
//回溯还原v[i]且删除该节点
substring.erase(substring.end()-1,substring.end());
v[i]=0;
}
}
}
int main() {
getline(cin,s);
rep(i,0,s.size()) v.push_back(0);
digui(s);
return 0;
}
8.4 搜索剪枝
常用的搜索有DFS和BFS,剪枝就是:把不会产生答案的,或不必要的枝条“剪掉”。
BFS剪枝:通常就是判重,因为一般BFS寻找的是步数最少,重复的话必定不会在之前的情况前产生最优解。
DFS剪枝:深搜的进程近似一颗树(通常叫DFS树)。
常用的剪枝有:可行性剪枝、最优性剪枝、记忆化搜索、搜索顺序剪枝。
1.可行性剪枝
如果当前条件不合法就不再继续搜索,直接return。这是非常好理解的剪枝,搜索初学者都能轻松地掌握,而且也很好想。一般的搜索都会加上。
dfs(int x)
{
if(x>n)return;
if(!check1(x))return;
....
return;
}
2.最优性剪枝
如果当前条件所创造出的答案必定比之前的答案大,那么剩下的搜索就毫无必要,甚至可以剪掉。
我们利用某个函数估计出此时条件下答案的‘下界’,将它与已经推出的答案相比,如果不比当前答案小,就可以剪掉。
long long ans=987474477434487ll;
... Dfs(int x,...)
{
if(x... && ...){ans=....;return ...;}
if(check2(x)>=ans)return ...; //最优性剪枝
for(int i=1;...;++i)
{
vis[...]=1;
dfs(...);
vis[...]=0;
}
}
//一般实现:在搜索取和最大值时,如果后面的全部取最大仍然不比当前答案大就可以返回。
//在搜和最小时同理,可以预处理后缀最大/最小和进行快速查询。
3.记忆化搜索
记忆化搜索其实很像动态规划(DP)。
它的关键是:如果对于相同情况下必定答案相同,就可以把这个情况的答案值存储下来,以后再次搜索到这种情况时就可以直接调用。还有就是不能搜出环来,不能互相依赖。
long long ans=987474477434487ll;
... Dfs(int x,...)
{
if(x... && ...){ans=....;return ...;}
if(vis[x]!=0)return f[x];vis[x]=1;
for(int i=1;...;++i)
{
vis[...]=1;
dfs(...);
vis[...]=0;
f[x]=...;
}
}
4.搜索顺序剪枝
在一些迷宫题,网格题,或者其他搜索中可以贪心的题,搜索顺序(节点扩展顺序)显得十分重要。我们经常听见有人说(我自己也说过):“从左边搜会T,从右边搜就A了”之类的语句。
其实在迷宫、网格类的题目中,以入口在左上->出口在右下为例,<右下左上>就明显比<左上右下>优秀!!
在一些推断搜索题中,从已知信息最多的地方开始搜索显然更加优秀。
在一些题中,先搜某个值大的,再搜某个值小的(比如树的度数,产生答案的预计(A*),速度明显会比乱搜更快。
搜索的复杂度明显讲不清,这种剪枝自然是能加就加。
8.5 搜索骗分技巧
当你想不到正解只会搜索的时候,千万不要气馁,用科学解析那些玄学骗分技巧,那句话怎么说来着,没有挖不走的墙角,只有…
1、利用预处理的思想
这是一种中规中矩的处理方式,先将搜索过程中可能会用到的值预先处理出来,本质是用空间换时间。例如A*(启发式搜索)就是用的这个思想,这样可以大大节约搜索时的时间开销,也能保证答案的正确性。
2、暴力剪枝
这种方法就好像一棵树上结了一个果子,你不再是每一个树枝都去寻找,而是直接砍掉一些树枝不要,然后再在剩下的树上寻找,很明显这种方法不能保证一定正确,但是却可以大大减少时间的消耗,也可以变成递归到多少层就不继续往下递归了,不管是否后面有没有果子。
3、利用贪心的思想
贪心是一种很简单的思想,虽然贪心不一定是正确,但是却有可能正确。
4、利用概率论的思想
我们都知道现在图像识别已经进入了大家的生活,但是识别不是都能100%的准确,现在看各个厂家的产品都是说识别率能达到百分之多少,而不是100%。
那么我们可以根据对应的题目去解析几个特征值,然后设置一下概率来-触发搜索的条件。
后面三种的使用效果要看各人的天赋,毕竟是绝招嘛,一般情况下不会使用的。
本质上都是利用了机试题目一般都不会特别强的弱点。
9 图论算法(并查集、最小生成树、最短路径、拓扑)
对于大部分图论问题,直接套算法模板即可解决。
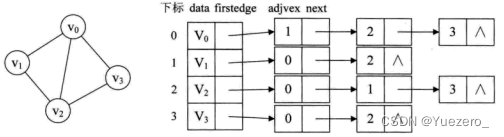
图的存储:邻接矩阵(稠密图适合)、邻接表(稀疏图适合)
9.1 并查集
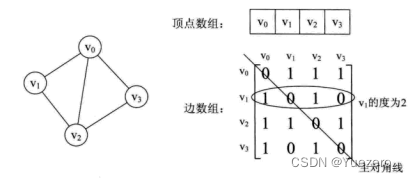
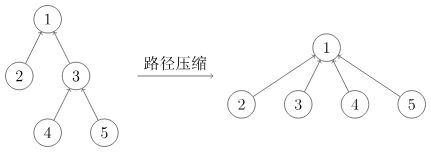
并查集是一种用于管理元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素,每个集合都有一个祖先,用于标识该集合。 如下图左边集合的祖先(代表元素)为1,右边集合的代表元素为6。我们如果想快速知道节点5属于哪个集合?一个暴力办法是不断递归查询父节点,直到祖先,时间复杂度高。而并查集则直接存储节点的祖先为自己的父节点,压缩了递归查找路径,实现单步查找祖先!

总结:
并查集是解决集合类问题的,比如朋友关系,家谱查询,道路连通关系等等(集合联通关系题型)。并查集本质是利用树形结构 来加快 区分集合的算法,这么一看,用map来区分也是可以的。但是并查集在树形结构的特点上加入了路径压缩的思想,使得算法效率远高于map。
初始化:
#define MAXN 100
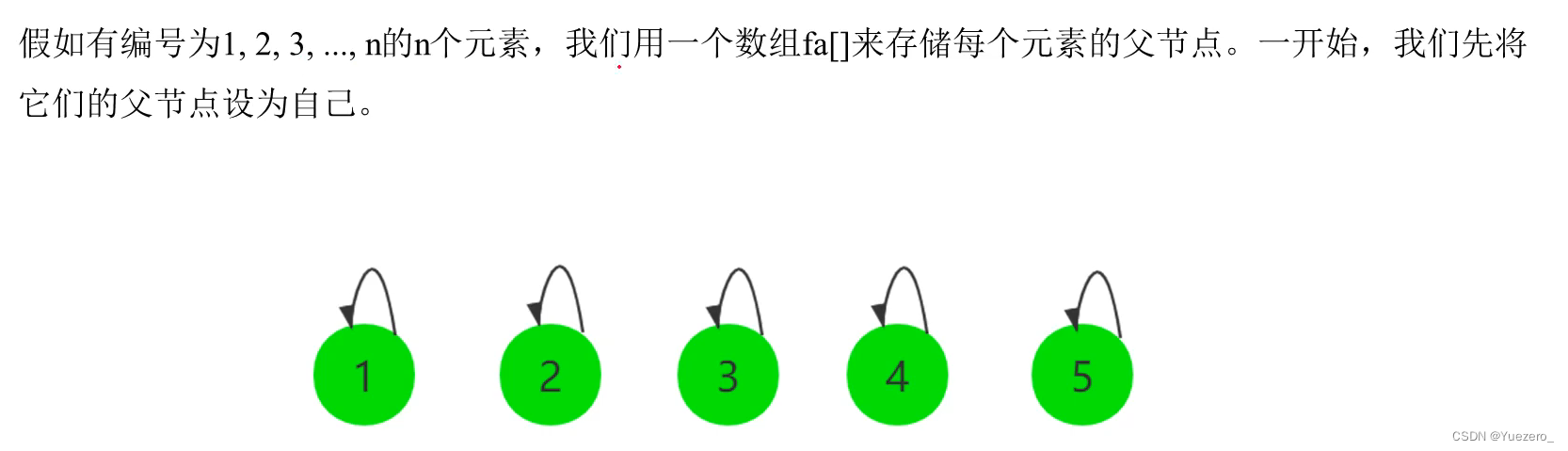
int fa[MAXN];//fa[x]是x的父节点,初始化设为自己
void init(int n){
for(int i=1;i<=n;i++)
fa[i]=i;
}
查询 与 合并:
- 合并(Union):合并两个元素所属集合(合并对应的树),用于构建集合。
- 查询(Find):查询某个元素所属
集合的祖先(查询树的代表元素),这可以用于判断两个元素是否属于同一集合。
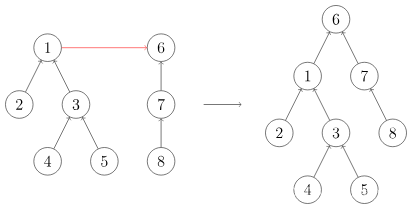
暴力实现:

#define MAXN 100
int fa[MAXN];//fa[x]是x的父节点,初始化设为自己
void init(int n){//初始化每个节点的父节点为他自己
for(int i=1;i<=n;i++)
fa[i]=i;
}
int find(int i){//查找当前节点的祖先(父亲的父亲的...)
if(fa[i]==i)//当到达祖先时return
return i;
else
return find(fa[i]);//没到达,继续递归查找父节点
}
void unionn(int i,int j){//合并i和j所在集合,i_fa指向j_fa
int i_fa=find(i);//查找i的祖先i_fa
int j_fa=find(j);//查找j的祖先j_fa
fa[i_fa]=j_fa;//将j和i的祖先合并
}
并查集: 在暴力的基础上进行路径压缩:存储i的祖先为i的父节点。背会下面的模板就行。
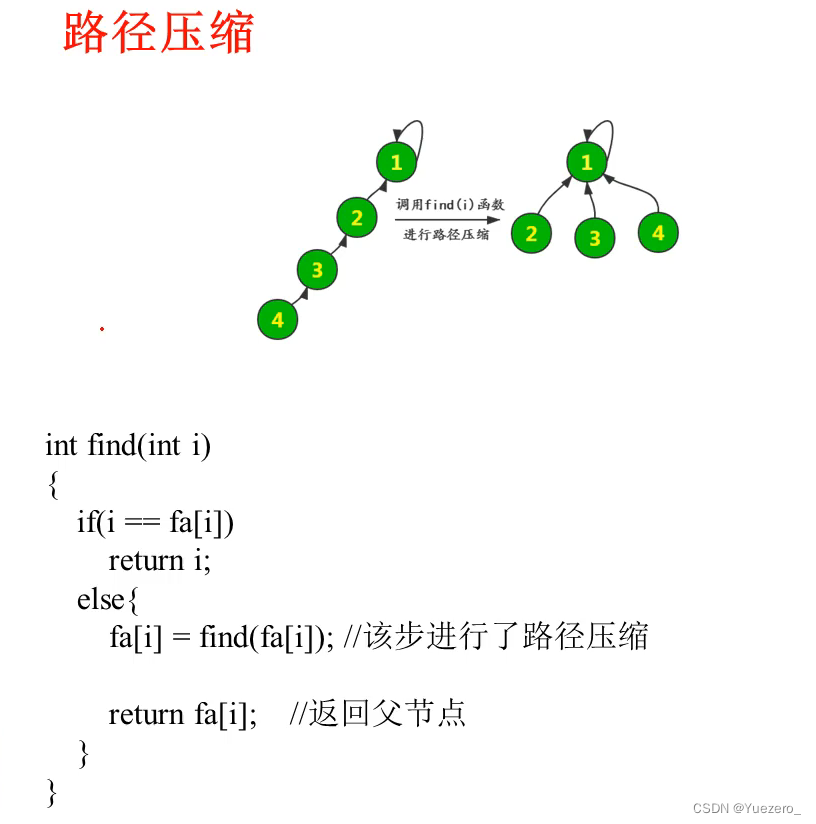
#define MAXN 100
int fa[MAXN];//fa[x]是x的父节点,初始化设为自己
void init(int n){//初始化每个节点的父节点为他自己
for(int i=1;i<=n;i++)
fa[i]=i;
}
int find(int i){
if(i==fa[i])
return i;
else{
fa[i]=find(fa[i]);//该步进行了路径压缩:存储i的祖先为i的父节点
return fa[i];//返回父节点
}
}
void unionn(int i,int j){//合并i和j所在集合,i_fa指向j_fa
int i_fa=find(i);//查找i的祖先i_fa
int j_fa=find(j);//查找j的祖先j_fa
fa[i_fa]=j_fa;//将j和i的祖先合并
}
9.2 最短路径
9.3 最小生成树
- 普卢姆算法:贪心加点
- 克鲁斯卡尔算法:贪心加边
掌握原理,刷题来不及了,直接跳过
9.4 拓扑排序
刷题来不及了,直接跳过

















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











