







五种常见回归模型
1. Linear Regression
- 核心思想:线性回归,通过属性的线性组合来拟合一条直线、平面或者超平面 f ( x i ) = w x i + b f(x_i)=wx_i+b f(xi)=wxi+b,使得真实值与预测值之间的均方误差最小。
- 损失函数:平方损失 L ( y , f ( x i ) ) = ( y − f ( x i ) ) 2 L(y,f(x_i)) =(y-f(x_i))^2 L(y,f(xi))=(y−f(xi))2
- 目标函数:
w
^
∗
=
a
r
g
m
i
n
w
^
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
\hat{w}^* = \underset{\hat{w}}{arg \ min}(y-X\hat{w})^T(y-X\hat{w})
w^∗=w^arg min(y−Xw^)T(y−Xw^)
y − X w ^ = ( y 1 y 2 ⋮ y m ) − ( x 11 x 12 . . . x 1 d 1 x 21 x 22 . . . x 2 d 1 ⋮ ⋮ ⋱ ⋮ ⋮ x m 1 x m 2 . . . x m d 1 ) ( w 1 w 2 ⋮ w d b ) y-X\hat{w} = \left(\begin{matrix} y_1 \\ y_2 \\ \vdots \\ y_m \end{matrix}\right)-\left(\begin{matrix} x_{11} & x_{12} &... & x_{1d} & 1\\ x_{21} & x_{22} &... & x_{2d} & 1 \\ \vdots & \vdots & \ddots & \vdots & \vdots \\ x_{m1} & x_{m2} &... & x_{md} & 1 \end{matrix}\right) \left(\begin{matrix} w_1 \\ w_2\\ \vdots \\ w_d \\ b \end{matrix}\right) y−Xw^=⎝⎜⎜⎜⎛y1y2⋮ym⎠⎟⎟⎟⎞−⎝⎜⎜⎜⎛x11x21⋮xm1x12x22⋮xm2......⋱...x1dx2d⋮xmd11⋮1⎠⎟⎟⎟⎞⎝⎜⎜⎜⎜⎜⎛w1w2⋮wdb⎠⎟⎟⎟⎟⎟⎞ 其 中 , d : 特 征 维 度 , m : 样 本 数 量 , w ^ : 权 重 参 数 , b : 偏 置 其中,d:特征维度,m:样本数量,\hat{w}:权重参数,b:偏置 其中,d:特征维度,m:样本数量,w^:权重参数,b:偏置 - 求解方法:
- 最小二乘法:
- 第一步:令经验风险
E
w
^
=
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
E_{\hat{w}} = (y-X\hat{w})^T(y-X\hat{w})
Ew^=(y−Xw^)T(y−Xw^),则
E
w
^
=
y
T
y
−
y
T
X
w
^
−
w
^
T
X
T
y
+
w
^
T
X
T
X
w
^
E_{\hat{w}} =y^Ty-y^TX\hat{w}-\hat{w}^TX^Ty+\hat{w}^TX^TX\hat{w}
Ew^=yTy−yTXw^−w^TXTy+w^TXTXw^

- 第二步:当矩阵 X T X X^TX XTX为满秩矩阵或正定矩阵时,另导数 ∂ E w ^ ∂ w ^ = 0 \frac{\partial E_{\hat{w}}}{\partial \hat{w}}=0 ∂w^∂Ew^=0,得到解析解 w ^ ∗ = ( X T X ) − 1 X T y \hat{w}^*=(X^TX)^{-1}X^Ty w^∗=(XTX)−1XTy
- 第三步:当矩阵 X T X X^TX XTX不满秩时(属性数量大于样本数),需要利用奇异值分解-SVD求逆矩阵 ( X T X ) − 1 (X^TX)^{-1} (XTX)−1,进而求得 w ^ ∗ \ \hat{w}^* w^∗。此时,存在多个解。
- 第一步:令经验风险
E
w
^
=
(
y
−
X
w
^
)
T
(
y
−
X
w
^
)
E_{\hat{w}} = (y-X\hat{w})^T(y-X\hat{w})
Ew^=(y−Xw^)T(y−Xw^),则
E
w
^
=
y
T
y
−
y
T
X
w
^
−
w
^
T
X
T
y
+
w
^
T
X
T
X
w
^
E_{\hat{w}} =y^Ty-y^TX\hat{w}-\hat{w}^TX^Ty+\hat{w}^TX^TX\hat{w}
Ew^=yTy−yTXw^−w^TXTy+w^TXTXw^
- 梯度下降法: G r a d i e n t D e s c e n t Gradient Descent GradientDescent,迭代更新 w i + 1 = w i − α ∂ E w ^ ∂ w ^ w_{i+1} = w_i - \alpha\frac{\partial E_{\hat{w}}}{\partial \hat{w}} wi+1=wi−α∂w^∂Ew^
- 最小二乘法:
- 优点:权重参数直观表达了属性的重要程度,可解释性好。
2. Lasso Regression
- 核心思想:Least Absolute Shrinkage and Selection Operator (最小绝对值收敛和选择算子)。线性回归+ L 1 L_1 L1正则化项。
- 目标函数: w ^ ∗ = a r g m i n w ^ ( y − X w ^ ) T ( y − X w ^ ) + λ ∣ ∣ w ^ ∣ ∣ 1 \hat{w}^* = \underset{\hat{w}}{arg \ min}(y-X\hat{w})^T(y-X\hat{w})+\lambda||\hat{w}||_1 w^∗=w^arg min(y−Xw^)T(y−Xw^)+λ∣∣w^∣∣1
3. Ridge Regression
- 核心思想:岭回归,线性回归+ L 2 L_2 L2正则化项。
- 目标函数: w ^ ∗ = a r g m i n w ^ ( y − X w ^ ) T ( y − X w ^ ) + λ ∣ ∣ w ∣ ∣ 2 2 \hat{w}^* = \underset{\hat{w}}{arg \ min}(y-X\hat{w})^T(y-X\hat{w})+\lambda||w||^2_2 w^∗=w^arg min(y−Xw^)T(y−Xw^)+λ∣∣w∣∣22
4. ElasticNet Regression
- 核心思想:弹性网络,线性回归 + L 1 L_1 L1正则化项 + L 2 L_2 L2正则化项
- 目标函数: w ^ ∗ = a r g m i n w ^ ( y − X w ^ ) T ( y − X w ^ ) + λ ( α ∣ ∣ w ∣ ∣ 1 + ( 1 − α ) ∣ ∣ w ∣ ∣ 2 2 ) \hat{w}^* = \underset{\hat{w}}{arg \ min}(y-X\hat{w})^T(y-X\hat{w})+\lambda(\alpha||w||_1+(1-\alpha)||w||^2_2) w^∗=w^arg min(y−Xw^)T(y−Xw^)+λ(α∣∣w∣∣1+(1−α)∣∣w∣∣22)
5. Ridge VS LASSO
- 稀疏解:LASSO 回归的平方误差等值线 与 L 1 L_1 L1正则化项等值线交点更容易出现在坐标轴上,即 w 1 w_1 w1或 w 2 w_2 w2为0;Ridge 回归的平方误差等值线 与 L 2 L_2 L2正则化项等值线交点更容易出现在坐标系中。因此,LASSO 回归 比 Ridge 回归更容易得到稀疏解。LASSO可以进行 feature selection,而 Ridge不行。

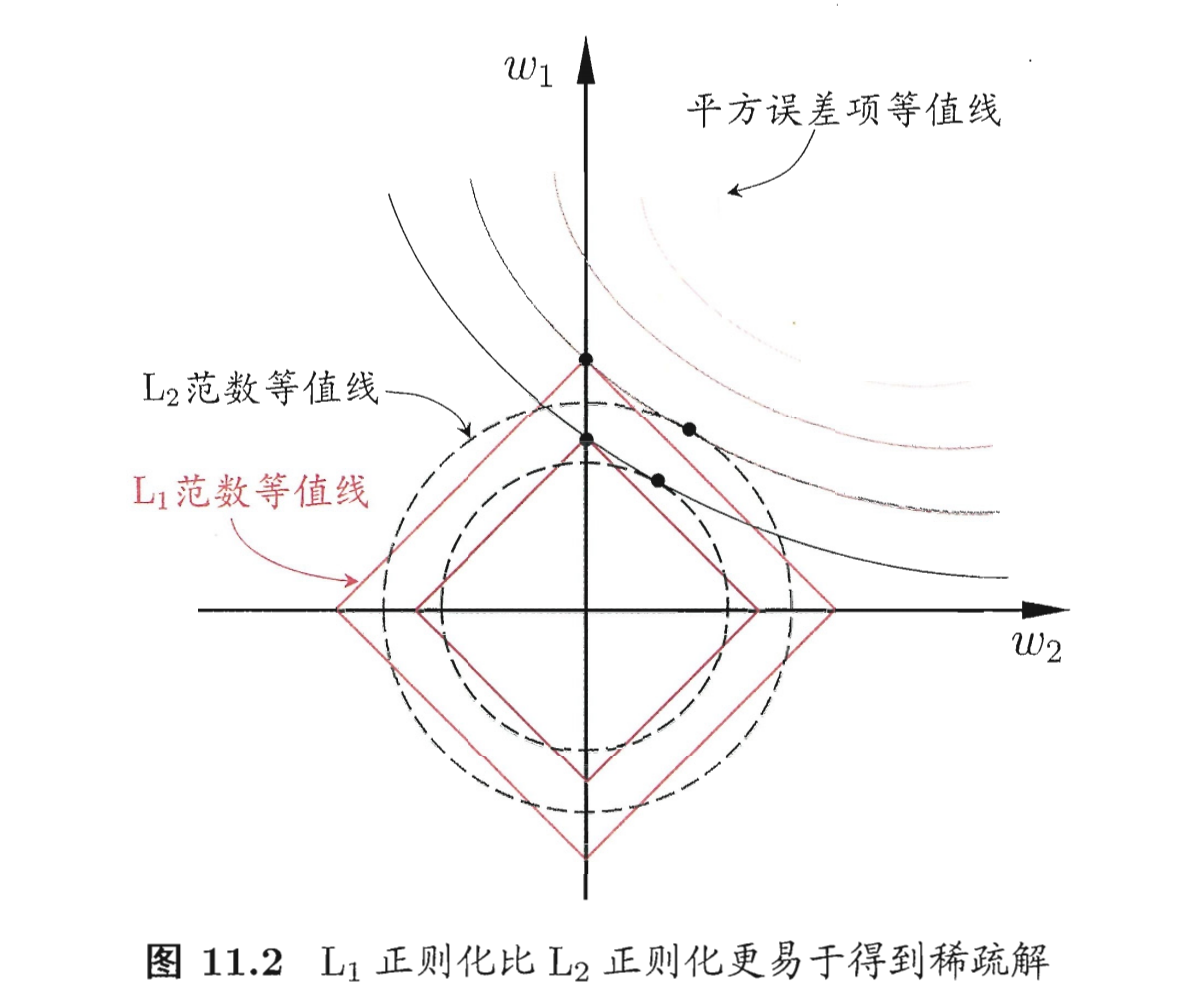
- 从贝叶斯角度看,L1 正则等价于参数 𝑤 的先验概率分布满足拉普拉斯分布,而 L2 正则等价于参数 𝑤 的先验概率分布满足高斯分布。
















 3234
3234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











