








大家好,我叫蒋晓峰,哔哩哔哩资深开发工程师,也是Apache Paimon PPMC,今天我要给大家分享的主题是 Apache SeaTunnel 架构的剖析与 Apache Paimon 集成。
文|蒋晓峰
编辑整理| 曾辉
讲师介绍

蒋晓峰
哔哩哔哩资深开发工程师
01
Apache SeaTunnel 设计目标
在大数据行业快速发展的今天,各类数据库和数据仓库等技术不断产生和发展。对于企业来说,如何同步异构数据源与目标端的数据已经成为了一个非常重要的问题。尤其是当 Apache Sqoop 退役后,实时同步、整库同步以及 Change Data Capture (CDC) 等场景也开始受到企业的关注。针对这些数据集成的场景,Apache SeaTunnel 的愿景是打造下一代的数据集成平台。

Apache SeaTunnel 的核心任务是解决大数据领域数据集成的一些核心需求。
它可以提供用户一个高效、易用且同步速度快的连接器,用以进行数据同步。
Apache SeaTunnel 是一个高吞吐、低延迟、分布式且可扩展的数据集成平台,旨在应对数据集成面临的多种问题。
其次,数据源众多且类型各异,包括各类数据库、消息系统和数据湖等。Apache SeaTunnel 作为数据集成平台,需要支持大量的数据源。其次,单个数据源也存在不同的版本,版本间的兼容性问题往往是难以解决的。
此外,资源使用率高,例如在进行 MySQL 表同步时,如果需要同步多张表,那么会频繁地处理 Binlog 数据,这可能会对数据源端造成很大的影响。同时,大数据事务和 schema 变更也可能对下游产生影响。JDBC 同步时连接过多,可能会导致数据同步不及时;
现在每家公司的技术栈都有差异,可能会存在一些问题:
数据集成的学习成本较高;
同步场景复杂,如全量增量同步、CDC同步,以及整库同步等;
数据质量难以保证,常见的问题包括数据丢失或重复,很难保证数据的一致性;
同步过程中出现异常时,大部分任务都无法执行回滚或断点续传;
由于监控指标缺失,数据同步过程中的信息不够透明,无法判断数据同步是否存在问题。
对于这些问题,Apache SeaTunnel 都提出了解决方案。
02
Apache SeaTunnel V1 架构
谈到 Apache SeaTunnel 的架构时,我们先来看看V1的架构。V1的架构强依赖于计算引擎,即强依赖 Spark 和 Flink 引擎,所有的任务都需要经过计算引擎来完成。虽然计算引擎能够提供大量的计算能力,但这也导致了数据同步的速度较慢。
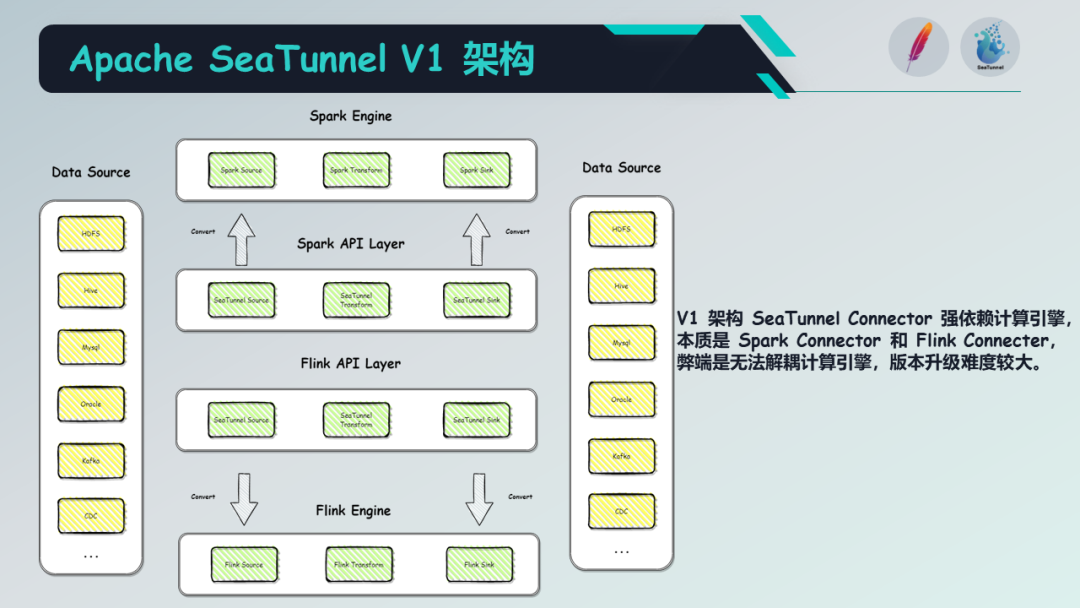
另外,由于各种原因,这种架构在处理长任务时存在缺陷。例如,计算引擎在进行任务提交时,其启动和关闭的速度较慢,这就导致了任务的启动和关闭时间过长。同时,计算引擎的一些特性,例如 Checkpoint,也对长任务造成了影响。当然,Apache SeaTunnel V1 的架构也有其优点,由于其基于 Spark 和 Flink,因此具有丰富的计算能力,可以进行一些复杂的数据处理操作。
03
Apache SeaTunnel V2 架构
然后,让我们来看一下 Apache SeaTunnel V2 的架构。
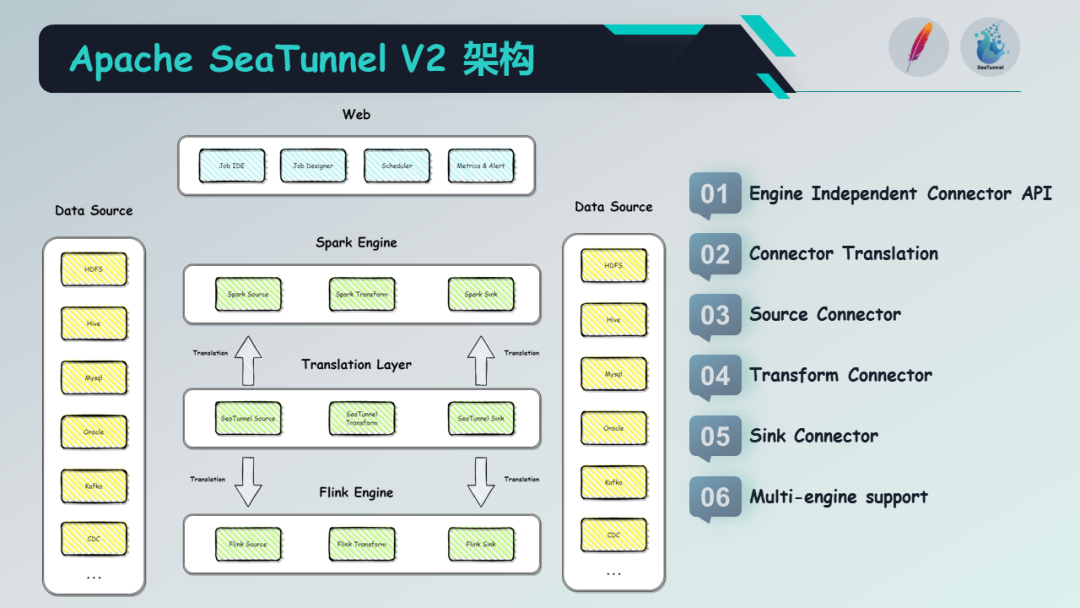
V2 版本的架构目标是解决 V1 版本存在的一些问题,尤其是在数据同步速度和长任务处理上的问题。V2版本的架构由多个部分组成,包括数据源连接器、任务提交引擎、任务调度器、和元数据存储等。
数据源连接器负责提供各种类型的数据源连接,以便进行数据同步。
任务提交引擎负责将数据同步任务提交给计算引擎,以便于执行数据同步。
任务调度器负责对数据同步任务进行调度,确保任务按照预定的时间或者事件触发。
元数据存储负责存储任务相关的元数据,例如任务配置、任务状态等。
04
Apache SeaTunnel 工作流程
Apache SeaTunnel 的工作流程主要分为两大部分:Apache SeaTunnel的执行流程和连接器(connector)的执行流程。
首先,让我们来看一下 Apache SeaTunnel 的执行流程。
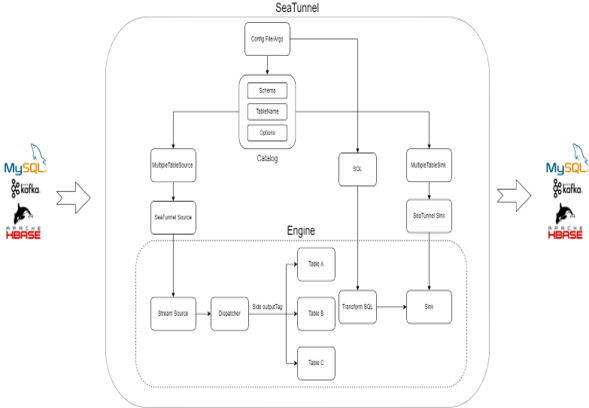
这个过程开始于对不同计算引擎的数据源(Source connector)进行处理。SeaTunnel 会对源连接器做一层翻译,让 Source connector 进行数据读取。接着,转换连接器(transform connector)会进行数据的标准化。
最终,目标连接器(Sink connector)会进行最终的数据写入,将数据传送至目标端。这是 Apache SeaTunnel 的整个执行流程。
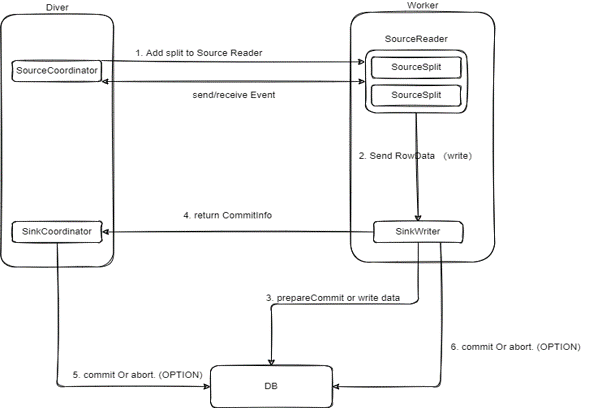
接下来,我们来看连接器的执行流程。连接器主要包含两部分:驱动器(driver)和工作器(worker)。
在驱动器中,Sourcecoordinator 负责管理工作器端的 source split 分配。接着,source split emulator 会将拆分好的 source split 发送给 source reader 进行数据读取。读取完数据的 source reader 会将数据发送给 Sink writer。Sink writer 在接收到数据后,会对分布式快照进行处理,最后将处理完成的数据写入到目标端。这是 Apache SeaTunnel 的连接器执行流程。
05
Engine Independent Connector API
Apache SeaTunnel V2 的架构中包含了六大核心元素。第一个元素是专为数据集成场景设计的独立引擎 API,其目标是解耦计算引擎。
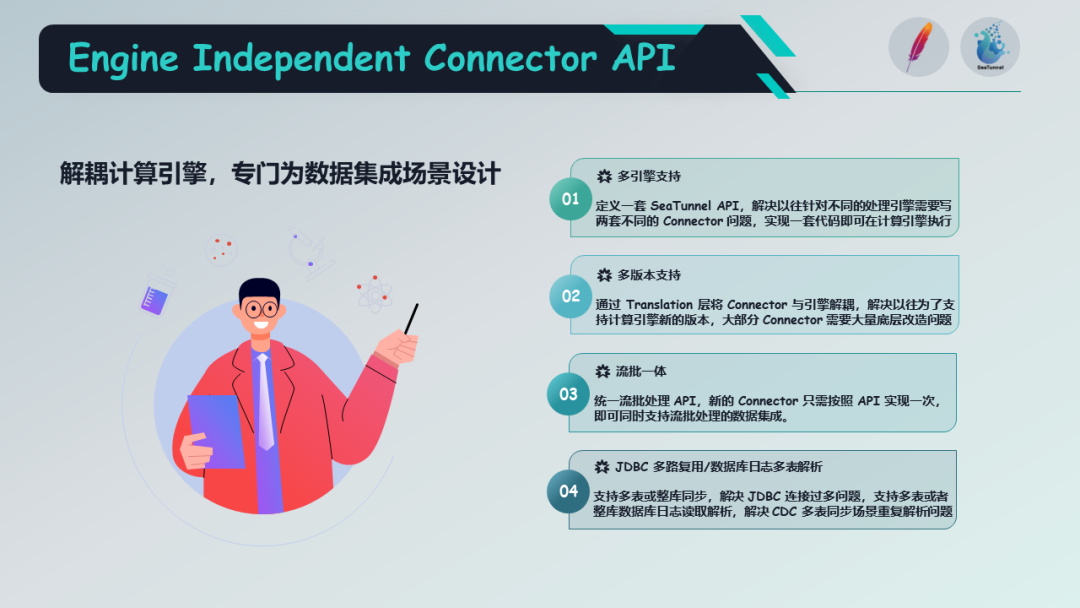
这一套 API 主要涵盖了四个方面:
多引擎支持:定义了一套通用的API,可以解决不同计算引擎需要编写不同 connector 的问题,实现一套代码在不同的计算引擎上执行。
计算引擎的多版本支持:通过 translation 层将 connector 与引擎解耦,以解决为了支持计算引擎新版本需要对大部分 connector 进行升级改造的问题。
解决流批一体的问题:这套 API 是一套流批统一的处理 API,新的 connector 只需按照这一套 API 实现,就可以支持流式处理和批式处理的数据同步工作。
JDBC 的多路复用和数据库日志的多表解析:Apache SeaTunnel 支持多表或整库的同步,解决了过多的 JDBC 连接导致同步速度变慢的问题,同时也支持多表或整库的数据库日志解析,解决了 CDC 场景下多表同步重复解析的问题。
06
Connector Translation
这个翻译层可以根据例如 Spark 的 connector API,将 SeaTunnel 的 API 实现的 connector 包装成一个 Spark connector。
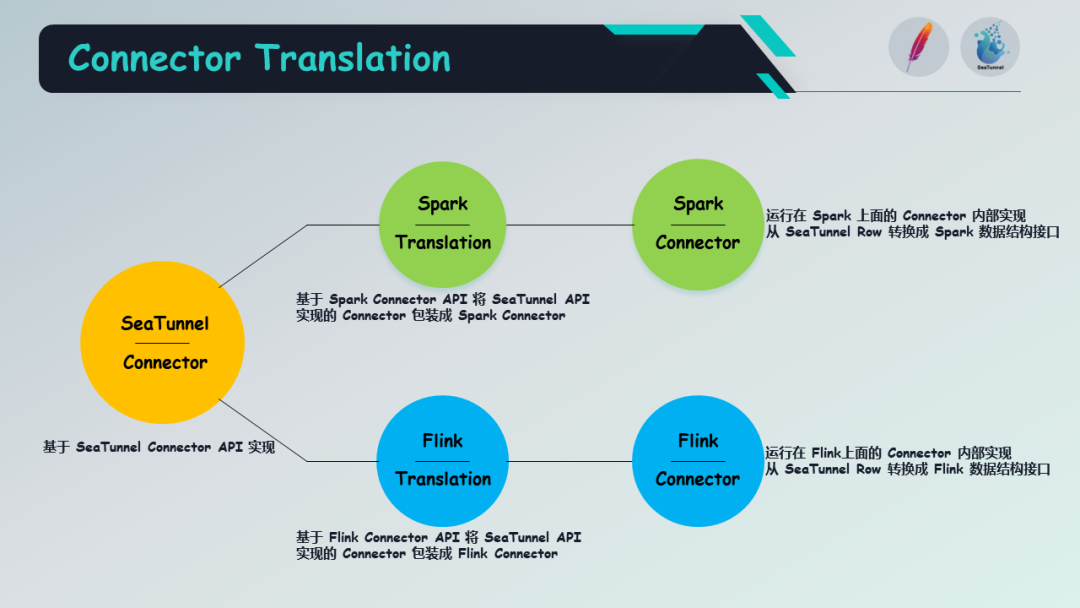
比如,可以将 Hudi 的 Connector 运行在 Spark 引擎上。Flink 的实现原理也是相同的。
接下来来谈谈 API 层的抽象。首先是 Source 层的 API 抽象。这个抽象引入了 Boundedness,支持了实时与离线的统一 API。
通过引入 SourceReader 和 Source split,支持并行读取。后面 Apache SeaTunnel 会支持 Source Sink transform 的并行优化处理以提高吞吐。对于引入 Source split 和 Enumerator,其目标是支持动态发现分片。同时引入了 SupportCoordinate & SourceEvent 以解决协调读取的问题。
最后是分布式快照能力,Apache SeaTunnel 在 Spark 引擎上也支持了这个能力,以支持状态的存储和恢复。在新的 Source API 下,实现了两个特定的 Source。
第一个是 CoordinatedSource,这个 Source 的主要执行流程是通过 SourceSplitEnumerator 分发包括 Checkpoint、流批情况等信息到 ReaderThread 里面的 SourceReader。
第二个 Source 是 ParallelSource,它支持并行处理,需要在连接器里定义分区逻辑以及自定义分区算法,并且支持多并发处理。
07
SeaTunnel Sink Connector
在这个“流水线”的过程中,我们有很多这种固定化的一些东西,一方面是内部的一个规范性的约束,另一方面我们也从开源的里边学习到一些东西,然后把它用在我们这边。
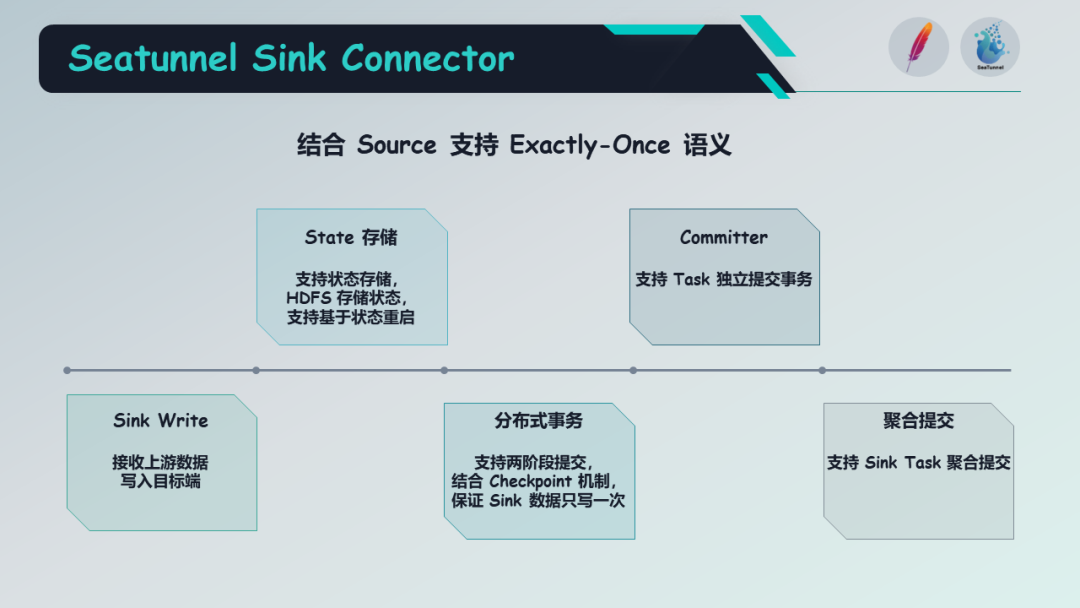
在关于 Sink 的部分,Apache SeaTunnel 的设计结合了源连接器的概念,旨在实现精确一次语义。
Sink API 的抽象可以分为五个主要部分:
第一部分是 Sink Writer,它负责接收上游数据并将其写入目标端。
第二部分是状态存储,该功能支持将状态存储在例如 HDFS 中,以便在同步任务故障后能够从状态中恢复并重新启动。
第三部分是分布式事务,Apache SeaTunnel 的 Sink 支持两阶段提交,并结合 Checkpoint 机制,确保精确一致的语义,即保证数据只写入一次。
第四部分是 Committer,它允许单个任务独立提交事务。
第五部分是聚合提交,由于 SeaTunnel 在 Spark 引擎中支持 Checkpoint 机制,在这种情况下,它可以支持 Sink 任务的聚合指标。
08
SeaTunnel Sink Commit
在新引入的 Sink API 中,存在三种类型的提交(commit)方式。
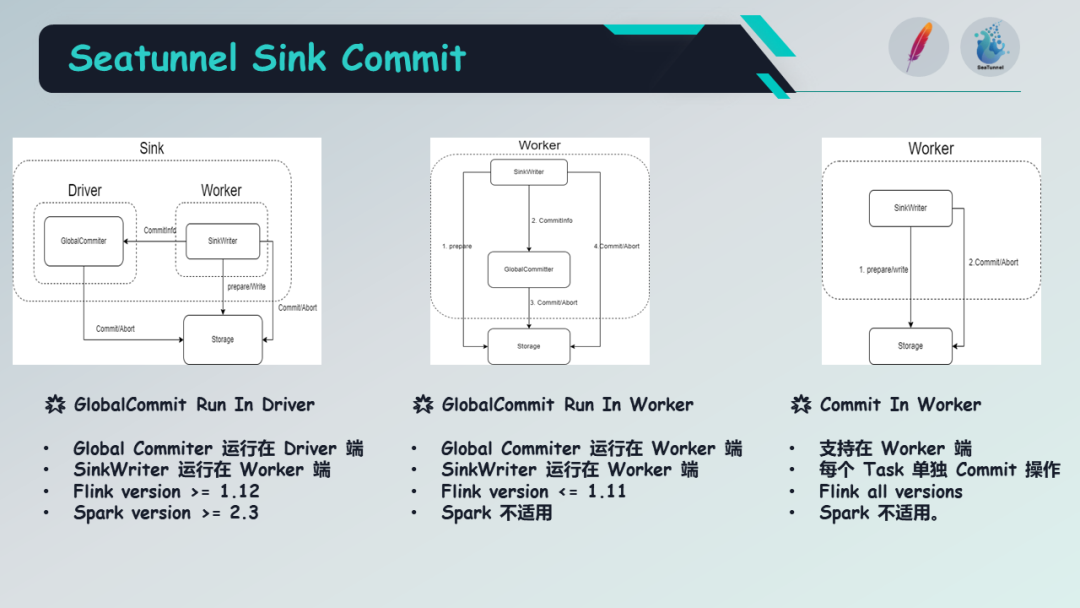
第一种是 GlobalCommit Run In Driver,它在驱动器端运行,全局提交器(global committer)在驱动器端执行,而 Sink Writer 在工作器端执行。这里还有一些限制适用于 Flink 和 Spark 版本的限制。
第二种是 GlobalCommit Run In Worker,全局提交器和 Sink Writer 都在工作器端运行,但不适用于 Spark,并且仅适用于 Flink 版本小于 1.11。
最后一种是 Commit In Worker,它支持在工作器端运行,每个任务可以单独执行提交事务的操作。此方法适用于所有 Flink 版本,但不适用于 Spark。
因此,这些是关于 Sink API 的抽象,具体实现取决于当前的一些约束条件。
09
SeaTunnel Table & Catalog
在我们刚开始的那个架构图中,我们实际上使用的是 Azkaban ,这是因为当时我们没有太多的时间去测试不同的产品,所以我们选择了最简单的 Azkaban 来做我们整个集群的资源调度工具。
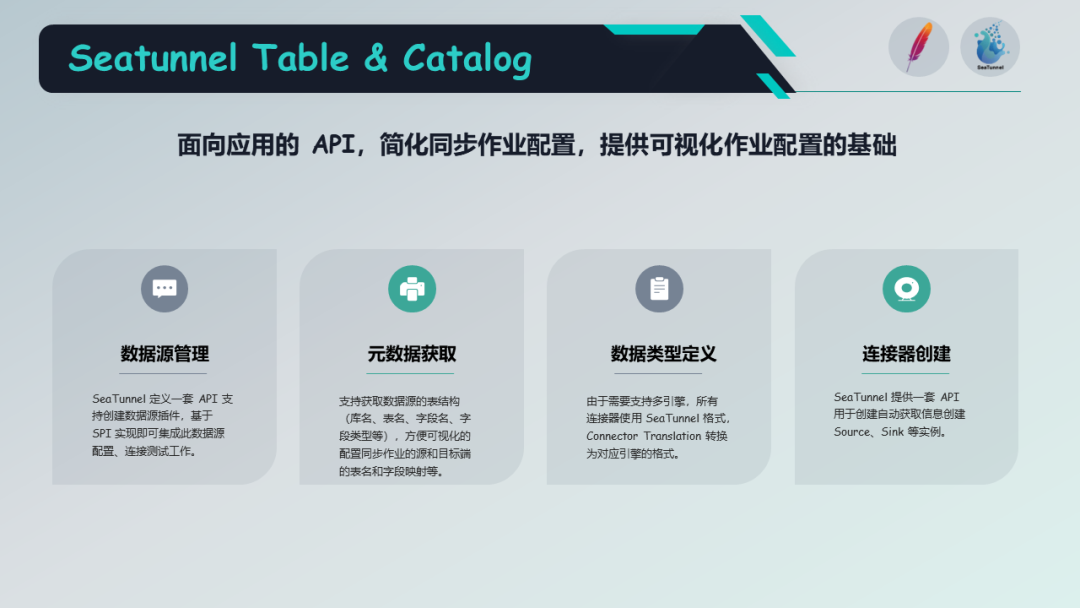
关于 Table 和 Catalog 的 API 抽象,它旨在解决简化同步作业配置的问题,为应用程序提供一个简化的接口。
该接口主要包含四个功能:数据源管理、元数据获取、数据类型定义和连接器创建。连接器创建用于创建源和汇等实例,元数据获取用于获取表和数据库的元信息,数据类型定义允许通过 Table Catalog 的 API 定义数据类型。数据源管理功能注册了表和数据库的元数据,提供元数据管理功能。
Table 和 Catalog 的 API 抽象支持多个引擎的目的是为了降低企业用户的使用成本。目前,它支持 Flink、Spark 和 Apache SeaTunnel 自研的 Zeta 引擎。对于 Flink 引擎,它支持多个版本,并天然支持 Flink 的 Checkpoint 机制和分布式快照算法。
对于 Spark 引擎,它支持微批处理模式,并提供了 Checkpoint 机制以支持聚合提交的特性。Apache SeaTunnel 提供了一套数据同步引擎,专为数据同步场景设计,为没有大数据环境的企业提供了选择的机会。
今年,Apache SeaTunnel 推出了自己的 Zeta 引擎,该引擎具备高吞吐、低延迟和强一致性的同步作业运行保障。
10
SeaTunnel Zeta 架构
Apache SeaTunnel Zeta 引擎的设计思路如下:
首先,它致力于提供简单易用的特性,通过 Zeta 引擎,用户可以减少对第三方服务的依赖,无需依赖于 ZooKeeper、HDFS 等大数据组件进行集群管理、状态快照存储和高可用功能。这样,即使没有这些组件,公司也可以使用 Apache SeaTunnel。
其次,Zeta 引擎通过 CPU 层面的 Dynamic Thread Sharing 技术实现了资源的节省。对于实时同步,如果同步的表较多但单个表的数据量较少,Zeta 引擎可以减少不必要的线程创建,节省系统资源。Zeta 引擎将这些同步任务放置在共享线程中运行,并且尽量减少与 JDBC 的连接数,以不影响同步速度。对于 CDC 场景,它还实现了可以复用日志处理解析资源,避免重复解析日志,从而节省计算资源。
第三,稳定性是一个关键考量。Apache SeaTunnel 的 Zeta 引擎将数据同步任务以 pipeline 作为最小粒度进行 Checkpoint 和容错。如果一个任务失败,只会影响与该任务有上下游关系的任务,避免整个作业的失败或回滚。
此外,Zeta 引擎支持开启数据缓存,自动缓存源端读取的数据,即使目标端出现故障导致数据无法写入,也不会影响源端数据的读取,同时可以防止远端数据过期被删除。
另外,Zeta 引擎的执行计划优化器以减少数据网络传输为主要目标,优化执行计划,降低数据序列化和反序列化的性能损耗,尽快完成数据同步操作。同时,它支持变速功能,按照合理的速度同步相应流量的数据。
最后,Zeta 引擎支持全场景的数据同步,包括离线批量同步下的全增量一体同步、实时同步和 CDC 同步。
11
SeaTunnel Zeta 服务
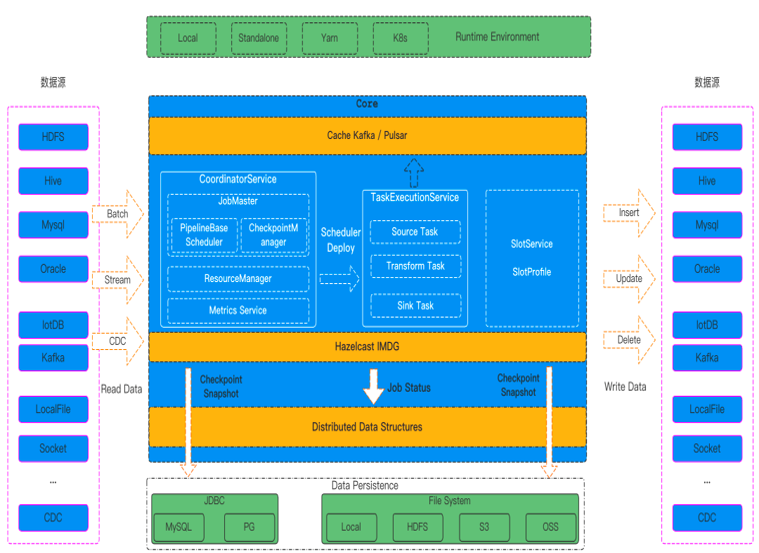
SeaTunnel Zeta 主要由一套数据同步处理的 API 和核心计算引擎组成,其中包括三个主要的服务:CoordinatorService、TaskExecutionService 和 SlotService。

🌟 CoordinatorService
CoordinatorService 是集群的 Master 服务,负责生成作业的 LogicalDag、ExecutionDag 和 PhysicalDag,以及调度执行和监控作业的状态。它包括以下组件:
JobMaster:负责生成作业的 LogicalDag、ExecutionDag 和 PhysicalDag,并由 PipelineBaseScheduler 进行调度运行。
CheckpointCoordinator:负责作业的 Checkpoint 流程控制。
ResourceManager:负责作业资源的申请和管理,目前支持 Standalone 模式,未来将支持 On Yarn 和 On K8s。
Metrics Service:负责统计和汇总作业的监控信息。
🌟 TaskExecutionService
TaskExecutionService 是集群的 Worker 服务,为作业中的每个 Task 提供运行时环境。TaskExecutionService 使用 Dynamic Thread Sharing 技术降低 CPU 使用。
🌟 SlotService
SlotService 在集群的每个节点上运行,主要负责资源的划分、申请和回收。
Apache SeaTunnel 架构的主要特性体现在高吞吐、精确性和低延迟。
高吞吐体现在连接器中的源(Source)、转换(Transform)和汇(Sink)的并行处理。通过并行化处理数据同步,SeaTunnel 提高了数据同步的吞吐量。
精确性体现在 SeaTunnel 实现了分布式快照算法,并采用两阶段提交和幂等写入等机制来实现 exactly-once 语义。
低延迟体现在 Spark 和 Flink 引擎提供的实时处理和微批处理能力上,使得 SeaTunnel 能够实现低延迟的数据同步。
12
Apache Paimon
接下来给大家介绍一下 Apache Paimon。Apache Paimon 是最近进入Apache软件基金会孵化器项目的一项技术,前身是 Flink Table Store,于今年3月12日正式进入Apache 软件基金会,并更名为Paimon。Paimon 这个名字源于原神游戏中的NPC。
在 Flink 社区的不断成熟和发展过程中,越来越多的公司开始使用 Flink 进行实时数据处理,从而提高数据时效性,并且实现业务的实时化效果。与此同时,在大数据领域,数据湖技术日益成为一种新的趋势。许多公司,包括我们的B站,采用 Lakehouse 架构,构建新一代的数据仓库。因此,Flink 社区希望通过结合 Flink 流处理的计算能力和 Paimon 的存储架构,推出新一代的流式数据仓库技术,使数据能够真正在数据服务中运行,并且为用户提供实时和离线一体化的开发体验。
目前市场上主流的一些数据湖存储项目格式主要面向批处理场景设计,无法满足流式数据仓库的需求。因此,Flink 社区在一年多前推出一款名为 Flink Table Store 的项目,它是一种面向流式和实时的数据湖存储。综上所述,Apache Paimon 是一项流式数据湖存储技术,它可以为用户提供高吞吐低延迟的数据摄入和流式订阅能力,并具备查询 Paimon 表中数据的能力。Paimon 采用开放的数据格式,与当前主流的数据湖存储格式相同,可以与Apache Spark、Apache Flink、Apache Doris 等主流大数据引擎进行对接,推动流式Lakehouse架构在大数据领域的普及和发展。
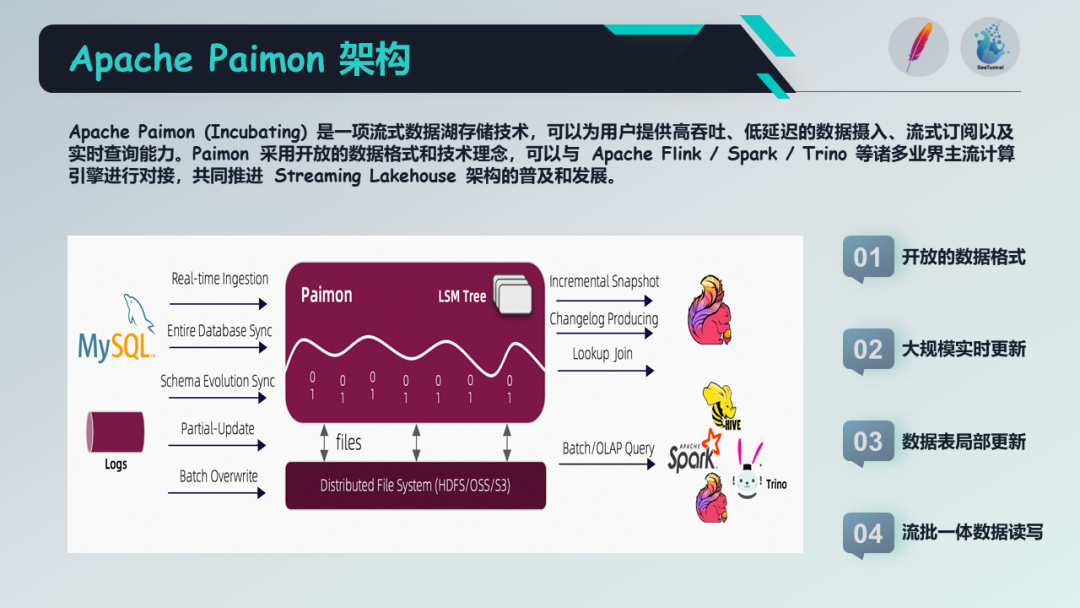
Paimon 主要包含以下四个要素:第一个要素是开放的数据格式。Paimon 以无存储的方式管理元数据,使用 Parquet、ORC、Avro 等文件格式。同时,它支持多种主流引擎,如Hive、Flink、Spark、Trino 和 Presto,并将来会支持更多引擎,如Doris DB和StarRocks。
第二个要素是大规模的实时更新能力。由于 Paimon 底层采用LSM(Log-Structured Merge)的数据结构和追加写入的能力,Paimon 能够在大规模数据更新场景中实现良好的性能。最新版本的 Paimon 已经与 Flink CDC(Continuous Growth Controller)对接,通过 Flink 数据流提供了两个合适的能力。第一个能力是可以实时将 MySQL的单表同步到 Paimon 表中,并实时同步上游 MySQL 表的变更到下游的 Paimon 表。第二个能力是支持实时同步 MySQL 的表级别和整库级别的表结构和数据同步,同时在同步过程中尽量复用资源,以减少数据同步的资源消耗。因此,通过 Paimon 与Flink CDC的整合,可以使业务数据更加简单高效地流式写入数据湖中。
接下来是局部表的更新能力,主要面向打宽表的业务场景。
最后一点是流批一体的数据主体。Paimon 作为一个流批一体的存储,提供了流读、流写、批读和批写的能力。使用 Paimon 可以构建流式数据处理流水线,并将数据沉淀到存储中。例如,在 Flink 流处理作业中,可以在实时更新的同时,支持对 Paimon 表中的历史数据和实时数据进行 OLAP 查询。同时,Paimon 也支持通过 Flink 进行Paimon 表的历史分区回填(Backfill),支持批量读写操作。这就是 Paimon 的四个主要要素。
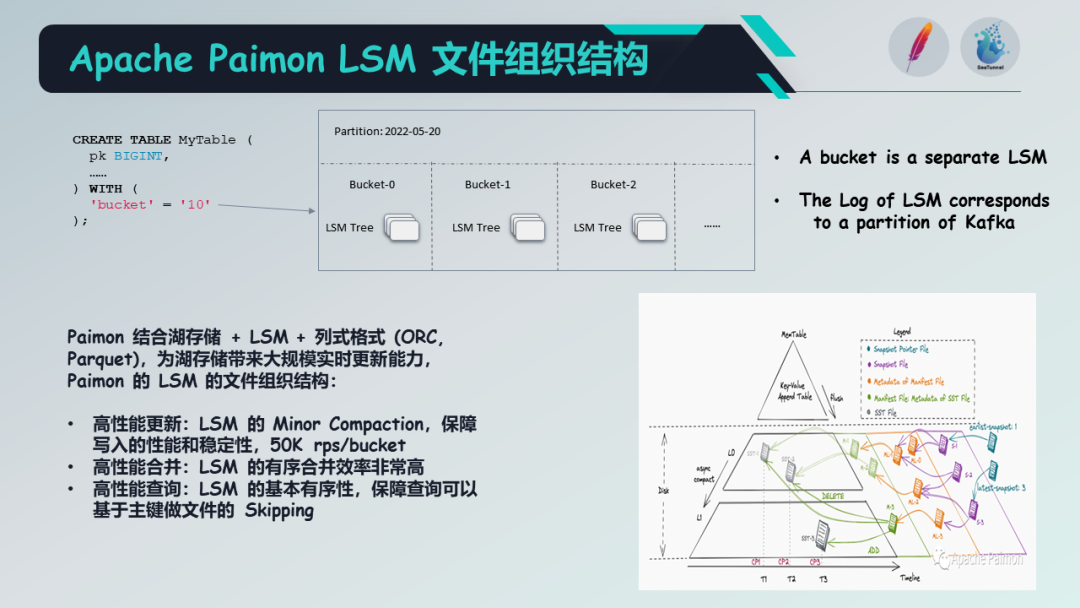
接下来让我们简单了解一下 Paimon 的文件布局。Paimon 的文件布局由快照文件(Snapshot Files)构成。整个文件布局与 Apache Iceberg 类似,即快照由清单列表(Manifest List)组成,而快照中保存了一些模式(Schema)的信息,清单列表由多个清单(Manifest)组成。每个清单由存储桶(Bucket)来决定,而每个存储桶实际上对应一个 LSM 树的数据结构。因此,这就是 Paimon 文件的布局。
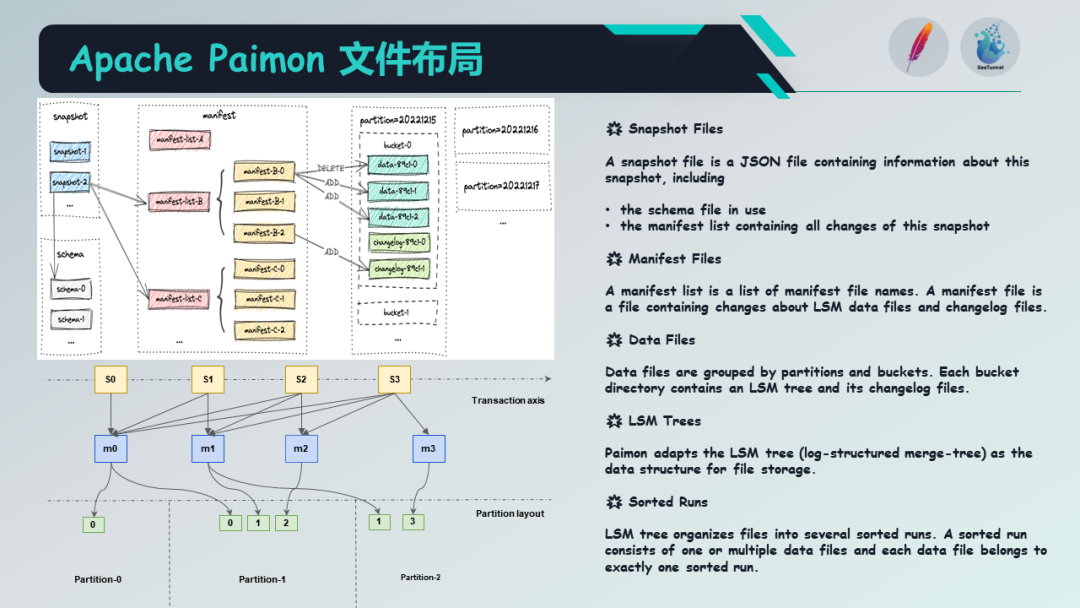
对于每个存储桶来说,它实际上是一个独立的 LSM 树,同时也对应于 Kafka 消息分区。Paimon创新地将湖存储与 LSM 树结合,并利用优势存储格式(如 ORC)来实现大规模实时更新的能力。
LSM 树的文件组织结构如右图所示。可以看到,这种数据结构带来了高性能的更新能力,通过 LSM 树的合并操作,保证了性能和稳定性。在测试中,一个存储桶可以达到50K 的RPS(每秒请求数)。第二个能力是高性能的查询,因为 LSM 树中数据是有序的,可以基于数据文件的数据跳跃(Data Skipping)进行查询。这是 Paimon 底层 LSM 文件组织的特点。
接下来,让我们介绍一下 Paimon 中的合并引擎(Merge Engine)。Paimon的合并引擎用于合并具有相同组件的写入数据。Paimon 主要支持以下三种合并方式。

deduplicate:默认的 Merge Engine 是 deduplicate 即只保留最新的记录,其他的同 PK 数据则被丢弃,如果最新的记录是 DELETE 记录,那么相同 PK 的所有数据都将被删除。
partial-update:建表时指定'merge-engine' = 'partial-update',表示使用部分更新表引擎,做到多个 Flink 流任务去更新同一张表,每条流任务只更新一张表的部分列,最终实现一行完整的数据的更新。在数据仓库的业务场景下,经常会用到宽表数据模型,宽表模型通常是指将业务主体相关的指标、维表、属性关联在一起的模型表,也可以泛指将多个事实表和多个维度表相关联到一起形成的宽表。
对于宽表模型而言,partial-update 非常适合此场景,同时构建宽表操作相对简单。对于流读场景,partial-update 表引擎需要结合 Lookup 或者 full-compaction 的 Changelog Producer 一起使用,同时 partial-update 不能接收和处理 DELETE 消息。Paimon 的 Partial-Update 合并引擎可以根据相同的主键实时合并多条流,形成 Paimon 的一张大宽表,依靠 LSM 的延迟 Compaction 机制,以较低的成本完成合并。合并后的表可以提供批读和流读:
批读:在批读时,读时合并仍然可以完成 Projection Pushdown,提供高性能的查询
流读:下游可以看到完整的、合并后的数据,而不是部分列。
aggregation:建表时指定 'merge-engine' = 'aggregation',表示使用聚合表引擎,通过聚合函数做一些预聚合,每个除主键以外的列都可以指定一个聚合函数,相同主键的数据就可以按照列字段指定的聚合函数进行相应的预聚合,如果不指定则默认为 last-non-null value ,空值不会覆盖。Agg 表引擎也需要结合 Lookup 或者 full-compaction 的 Changelog Producer 一起使用,需要注意的是除了 SUM 函数,其他的 Agg 函数都不支持 Retraction。

接下来介绍 Paimon 支持的 Changelog producer。不管输入如何更新,或者业务要求如何合并 (比如 Partial-Update),使用 Paimon 的 Changelog 生成功能,总是能够在流读时获取完全正确的变更日志。
当面对主键表时,为什么你需要完整的 Changelog :
你的输入并不是完整的 Changelog,比如丢失了 UPDATE_BEFORE (-U),比如同个主键有多条 INSERT 数据,这就会导致下游的流读聚合有问题,同个主键的多条数据应该被认为是更新,而不是重复计算。
当你的表是 Partial Update ,下游需要看到完整的、合并后的数据,才可以正确的流处理。
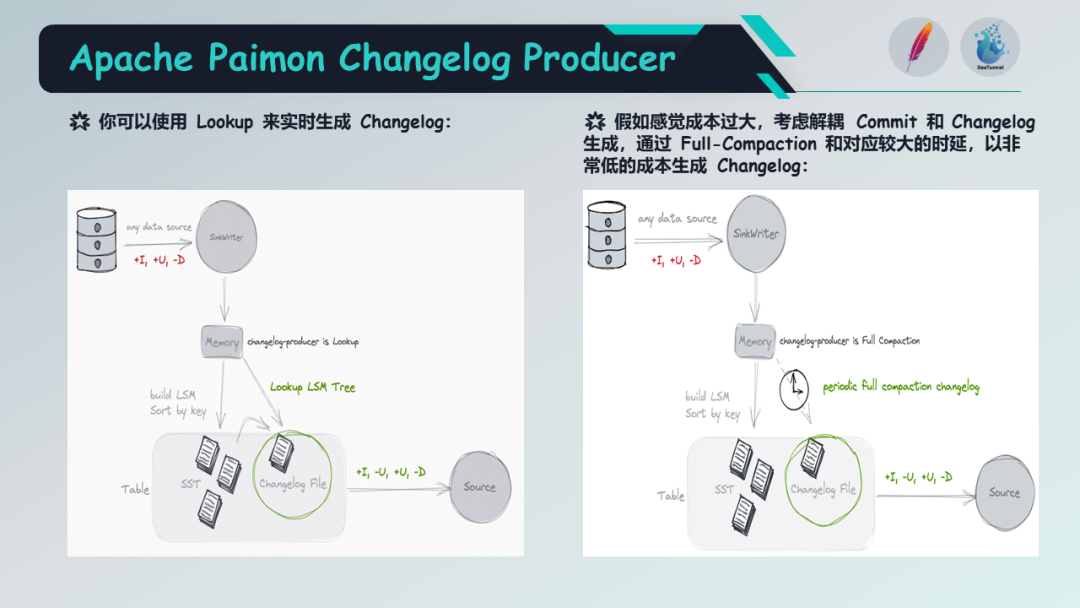
Paimon支持的changelog producer主要有4种:
none:如果不指定,默认就是 none,成本较高
input:当 Source 源是业务库的 Binlog ,即写入 Paimon 表 Writer 任务的输入是完整的 Changelog,此时能够完全依赖输入端的 Changelog, 并且将输入端的 Changelog 保存到 Paimon 的 Changelog 文件,由 Paimon Source 提供给下游流读
lookup:当输入不是完整的 Changelog, 并且不想在下游流读时通过 Normalize 节点生成 Changelog, 通过 Lookup 的方式在数据写入的时候生成 Changelog,此 Changelog Produer 目前处于实验状态
full-compaction:Writer 端在 Compaction 后产生完整的 Changelog,并且写入到 Changelog 文件。通过设置 changelog-producer.compaction-interval 配置项控制 Compaction 的间隔和频率,不过此参数计划弃用,建议使用 full-compaction.delta-commits,此配置下默认为1 即每次提交都做 Compaction
如果觉得使用 Lookup 来实时生成 Changelog 成本过大,你也可以解耦 Commit 和 Changelog 生成,通过 Full-Compaction 和对应较大的时延,以非常低的成本生成 Changelog。
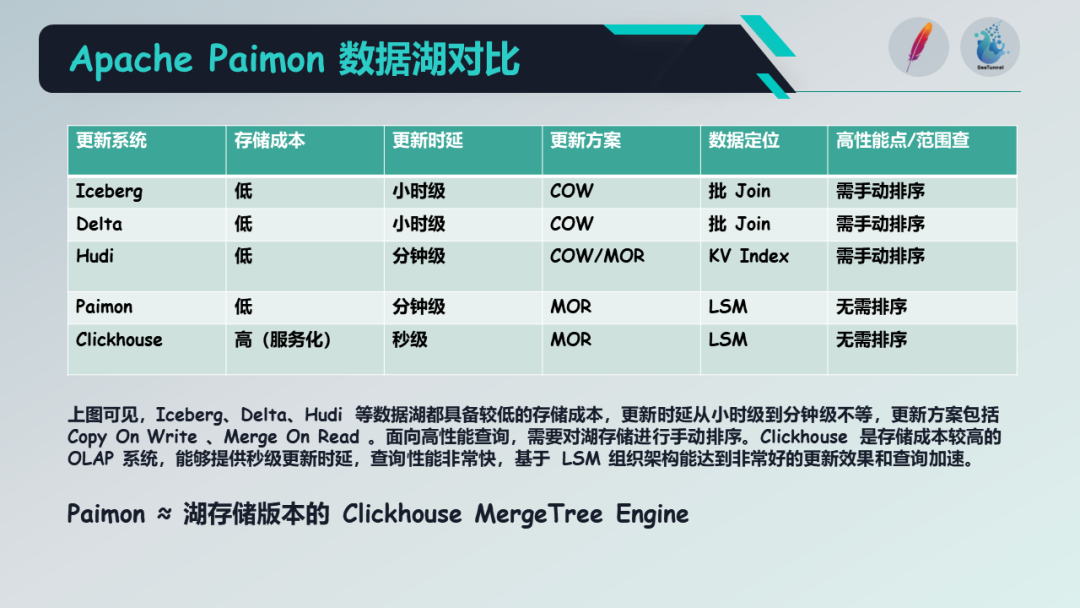
接着我们来看 Paimon 与其他数据湖产品的对比,从上图可见,Iceberg、Delta、Hudi 等数据湖都具备较低的存储成本,更新时延从小时级到分钟级不等,更新方案包括 Copy On Write 、Merge On Read 。面向高性能查询,需要对湖存储进行手动排序。Clickhouse 是存储成本较高的 OLAP 系统,能够提供秒级更新时延,查询性能非常快,基于 LSM 组织架构能达到非常好的更新效果和查询加速。总而言之,Paimon可以被视为一个湖存储版本的 ClickHouse。
接下来简单介绍一下 Paimon 的 Java API,包括读写API,分为批读、批写、流读和流写。

批读拆分为两个阶段:第一阶段是在一个中心节点生成计划拆分(Plan Split),第二阶段是通过分布式任务读取每个 Split 的数据。
批写拆分为两个阶段:第一阶段是通过分布式任务写入数据生成 Commit 消息,第二阶段是在一个中心节点收集所有 Commit 消息进行 Commit。如果发现 Commit 失败,可以调用 abort API 进行回滚。
对于流读而言,和批读的不同点在于 StreamTableScan 能够持续 Scan 和生成 Split,同时 StreamTableScan 提供 Checkpoint 和 Restore 的能力,允许用户在流读期间存储正确的状态。
对于流写而言,和批写的不同点在于 StreamTableCommit 能够持续 Commit,同时支持精确一次语义。
有了这些API,例如 Write和 Commit 等 API,我们就可以实现 Apache SeaTunnel 的 Paimon 连接器。

目前,该连接器仍处于基础版本,只实现了批读和批写的功能。我们将通过一个演示视频来展示这个过程,视频中介绍了如何批量读取和写入Paimon数据,只需指定表路径、表名和表的名称即可。
在Sink端,设置warehouse的地址、数据库名称和表名也是同样的操作。
13
Apache Paimon Connector 基础实现
通过Apache SeaTunnel,我们可以将数据写入Paimon中。Paimon连接器主要包括Paimon源读取器和Sink写入器。Sink写入器用于写入数据,它会调用前面提到的BatchTableWrite方法,先写入记录,获取提交消息,然后执行提交操作。
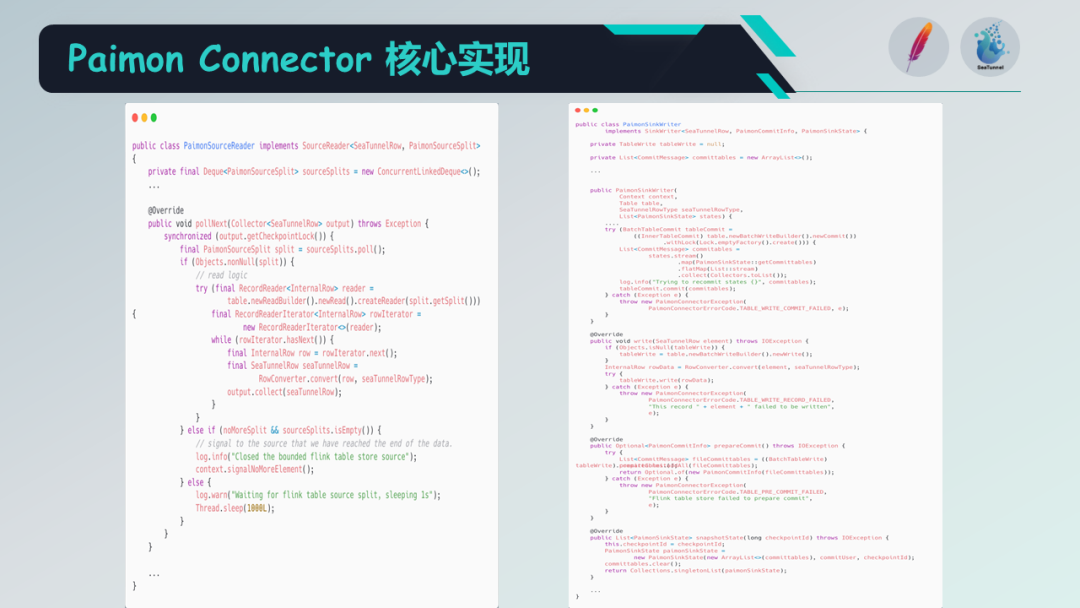
因此,Paimon Sink写入器已经实现了这个流程。对于Paimon源读取器来说,通过记录相等性,它可以读取和拆分Paimon数据,这是Paimon连接器的两个组成部分,实现了Sink和Source的功能。
接下来,我们将看一个场景,Paimon 作为库存组件,它支持大规模实时更新的写入能力。通过与Apache SeaTunnel配合使用,我们可以实现以前割裂的全量和增量同步,将数据库中的数据进行增量和全量入库,比如MySQL中的数据。
此演示仅基于Apache SeaTunnel和Paimon进行全量入库,并使用Apache SeaTunnel将MySQL中的数据导入,从而实现写入Paimon。主要的流程是演示流程,即创建ODS层的Paimon表,然后使用Apache SeaTunnel导入MySQL数据。最终创建了一个流水线,可将数据全量写入ODS的Paimon表。以下视频是演示的详细解释。
14
Apache SeaTunnel 社区规划
那最后讲一下 Apache SeaTunnel 的社区规划,作为数据集成平台,SeaTunnel 不断专注于解决数据集成领域的需求和问题,持续站在异构数据源的数量,数据集成的性能以及易用性角度满足用户使用体验。
🌟 V2 版本连接器数量翻倍
● Flink 和 Spark 连接器升级到 V2 版本
● 2023年 V2 版本支持80+连接器
🌟 发布 SeaTunnel Web
● 可视化作业管理
● 编程式和引导式的作业配置
● 内部调度(处理简单任务,Crontab 为主)和第三方调度(以 Dolphin Scheduler 为主)
🌟 发布 SeaTunnel Engine
● 通过减少 JDBC 的连接和 Binlog 的重复读取以达到更省资源效果
● 通过拆分任务为 Pipeline,Pipeline 之间的报错不会相互影响,同时支持独立重启操作
● 借助共享线程以及底层处理,推动整体同步任务更快完成
● 完善监控指标,监控同步任务运行过程 Connector 运行状态,其中包括数据数量和质量
Apache SeaTunnel
Apache SeaTunnel 是一个分布式、高性能、易扩展、用于海量数据(离线&实时)同步和转化的数据集成平台
仓库地址:
https://github.com/apache/seatunnel
网址:
https://seatunnel.apache.org/
Proposal:
https://cwiki.apache.org/confluence/display/INCUBATOR/SeaTunnelProposal
Apache SeaTunnel 下载地址:
https://seatunnel.apache.org/download
衷心欢迎更多人加入!
我们相信,在「Community Over Code」(社区大于代码)、「Open and Cooperation」(开放协作)、「Meritocracy」(精英管理)、以及「多样性与共识决策」等 The Apache Way 的指引下,我们将迎来更加多元化和包容的社区生态,共建开源精神带来的技术进步!
我们诚邀各位有志于让本土开源立足全球的伙伴加入 SeaTunnel 贡献者大家庭,一起共建开源!
提交问题和建议:
https://github.com/apache/seatunnel/issues
贡献代码:
https://github.com/apache/seatunnel/pulls
订阅社区开发邮件列表 :
dev-subscribe@seatunnel.apache.org
开发邮件列表:
dev@seatunnel.apache.org
加入 Slack:
https://join.slack.com/t/apacheseatunnel/shared_invite/zt-1kcxzyrxz-lKcF3BAyzHEmpcc4OSaCjQ
关注 Twitter:
https://twitter.com/ASFSeaTunnel
精彩推荐
Apache SeaTunnel Connector 使用文档和使用案例有奖征稿来了!一起玩开源
超大型纸业品牌“清风”也用上 Apache SeaTunnel 啦!
一文教会你用Apache SeaTunnel Zeta离线把数据从MySQL同步到StarRocks
点击阅读原文,点亮Star⭐️!


















 1467
1467

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









