






电影数据分析
背景概述
电影是工业、科技与艺术的结合产物,作为一种国际性的大众传播媒介,其必然与世界电影艺术潮流和国际电影市场密不可分。电影所具有的艺术性、经济型、文化性是与人们的生活密不可分的,因此不论从文化传播还是经济发展的角度来看,我们都需要对电影的发展趋势进行深入研究,从而更好的推动电影繁荣发展。
本次项目中针所收集的的电影多种数据指标进行可视化分析,从而对电影的发展趋势进行合理的分析解释。
提出问题
本文主要研究以下几个问题:
问题一:电影类型如何随着时间的推移发生变化的?
问题二:电影类型与利润的关系?
问题三:Universal Pictures和Paramount Pictures两家影视公司发行电影的对比情况如何?
问题四:改编电影和原创电影的对比情况如何?
问题五:电影时长与电影票房及评分的关系
问题六:分析电影关键字
导入对应的包
import pandas as pd
import numpy as np
import re
import json
import matplotlib
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import warnings
warnings.filterwarnings('ignore')# 忽略python运行过程中的警告
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
理解数据
导入数据
#路径替换为自己的数据文件所在路径
data = pd.read_csv(r'C:\Users\CTM123\Desktop\电影数据分析\tmdb_5000_credits.csv', skiprows=0)
data
| movie_id | title | cast | crew | |
|---|---|---|---|---|
| 0 | 19995 | Avatar | [{"cast_id": 242, "character": "Jake Sully", "... | [{"credit_id": "52fe48009251416c750aca23", "de... |
| 1 | 285 | Pirates of the Caribbean: At World's End | [{"cast_id": 4, "character": "Captain Jack Spa... | [{"credit_id": "52fe4232c3a36847f800b579", "de... |
| 2 | 206647 | Spectre | [{"cast_id": 1, "character": "James Bond", "cr... | [{"credit_id": "54805967c3a36829b5002c41", "de... |
| 3 | 49026 | The Dark Knight Rises | [{"cast_id": 2, "character": "Bruce Wayne / Ba... | [{"credit_id": "52fe4781c3a36847f81398c3", "de... |
| 4 | 49529 | John Carter | [{"cast_id": 5, "character": "John Carter", "c... | [{"credit_id": "52fe479ac3a36847f813eaa3", "de... |
| ... | ... | ... | ... | ... |
| 4798 | 9367 | El Mariachi | [{"cast_id": 1, "character": "El Mariachi", "c... | [{"credit_id": "52fe44eec3a36847f80b280b", "de... |
| 4799 | 72766 | Newlyweds | [{"cast_id": 1, "character": "Buzzy", "credit_... | [{"credit_id": "52fe487dc3a368484e0fb013", "de... |
| 4800 | 231617 | Signed, Sealed, Delivered | [{"cast_id": 8, "character": "Oliver O\u2019To... | [{"credit_id": "52fe4df3c3a36847f8275ecf", "de... |
| 4801 | 126186 | Shanghai Calling | [{"cast_id": 3, "character": "Sam", "credit_id... | [{"credit_id": "52fe4ad9c3a368484e16a36b", "de... |
| 4802 | 25975 | My Date with Drew | [{"cast_id": 3, "character": "Herself", "credi... | [{"credit_id": "58ce021b9251415a390165d9", "de... |
4803 rows × 4 columns
count = []
for i in list(data['crew']):
sum = 0
for j in i:
if j == '{':
sum += 1
count.append(sum)
data2 = pd.DataFrame({'name':data['title'], 'ans':count})
data2
| name | ans | |
|---|---|---|
| 0 | Avatar | 153 |
| 1 | Pirates of the Caribbean: At World's End | 32 |
| 2 | Spectre | 155 |
| 3 | The Dark Knight Rises | 217 |
| 4 | John Carter | 132 |
| ... | ... | ... |
| 4798 | El Mariachi | 11 |
| 4799 | Newlyweds | 8 |
| 4800 | Signed, Sealed, Delivered | 13 |
| 4801 | Shanghai Calling | 2 |
| 4802 | My Date with Drew | 5 |
4803 rows × 2 columns
查看数据集信息
#路径替换为自己的数据文件所在路径
data3 = pd.read_csv(r"C:\Users\CTM123\Desktop\电影数据分析\tmdb_5000_movies.csv", skiprows=0)
data3.columns=["预算(美元)", "风格列表", "主页", "id", "关键字", "初始语言", "电影名称", "剧情摘要", "电影页面查看次数", "制作公司", "生产国", "首次上映日期", "收入(美元)", "电影时长", "语言", "社会地位", "收尾语", "标题", "平均评分", "评分次数"]
# data3
数据清洗
1、由于credits数据集使用到的数据不多,故并未直接把其与moviedf数据集中的数据合并在一起,而是统计其crew列中每部电影的观看人数,在将数据添加moviedf数据集中(为方便使用,已将columns转换为中文)。
2、由于数据集中包含的信息过多,其中部分数据并不是我们研究的重点,故从中选取了我们需要的数据data5:由于后面的数据分析涉及到电影类型的利润计算;又(利润=收入-预算),且收入和预算两列存在0值,则使用平均值替换列中0值;然后求出每部电影的利润,并在数据data5中增加“利润”数据列。
data4 = data3.drop('主页', axis='columns')
data4 = data4.drop('初始语言', axis='columns')
data4 = data4.drop('剧情摘要', axis='columns')
data4 = data4.drop('社会地位', axis='columns')
data4 = data4.drop('收尾语', axis='columns')
data4['观看人数']=data2['ans']
#data4
data5=data4.loc[:, ['风格列表', '关键字', '电影名称', '预算(美元)', '收入(美元)', '制作公司', '首次上映日期', '电影时长', '平均评分', '观看人数']]
#data5
#将"收入(美元)"列中的0值全部替换为平均值
avg = 0
sum = 0
count = 0
for i in range(4803):
if data5['收入(美元)'][i] != 0:
sum += data5['收入(美元)'][i]
count += 1
avg = sum//count
data5['收入(美元)'] = data5['收入(美元)'].replace({0:avg})
#将"预算(美元)"列中的0值全部替换为平均值
avg = 0
sum = 0
count = 0
for i in range(4803):
if data5['预算(美元)'][i] != 0:
sum += data5['预算(美元)'][i]
count += 1
avg = sum//count
data5['预算(美元)'] = data5['预算(美元)'].replace({0:avg})
data5['利润'] = data5['收入(美元)']-data5['预算(美元)']
data5
| 风格列表 | 关键字 | 电影名称 | 预算(美元) | 收入(美元) | 制作公司 | 首次上映日期 | 电影时长 | 平均评分 | 观看人数 | 利润 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | [{"id": 1463, "name": "culture clash"}, {"id":... | Avatar | 237000000 | 2787965087 | [{"name": "Ingenious Film Partners", "id": 289... | 2009-12-10 | 162.0 | 7.2 | 153 | 2550965087 |
| 1 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | [{"id": 270, "name": "ocean"}, {"id": 726, "na... | Pirates of the Caribbean: At World's End | 300000000 | 961000000 | [{"name": "Walt Disney Pictures", "id": 2}, {"... | 2007-05-19 | 169.0 | 6.9 | 32 | 661000000 |
| 2 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | [{"id": 470, "name": "spy"}, {"id": 818, "name... | Spectre | 245000000 | 880674609 | [{"name": "Columbia Pictures", "id": 5}, {"nam... | 2015-10-26 | 148.0 | 6.3 | 155 | 635674609 |
| 3 | [{"id": 28, "name": "Action"}, {"id": 80, "nam... | [{"id": 849, "name": "dc comics"}, {"id": 853,... | The Dark Knight Rises | 250000000 | 1084939099 | [{"name": "Legendary Pictures", "id": 923}, {"... | 2012-07-16 | 165.0 | 7.6 | 217 | 834939099 |
| 4 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | [{"id": 818, "name": "based on novel"}, {"id":... | John Carter | 260000000 | 284139100 | [{"name": "Walt Disney Pictures", "id": 2}] | 2012-03-07 | 132.0 | 6.1 | 132 | 24139100 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4798 | [{"id": 28, "name": "Action"}, {"id": 80, "nam... | [{"id": 5616, "name": "united states\u2013mexi... | El Mariachi | 220000 | 2040920 | [{"name": "Columbia Pictures", "id": 5}] | 1992-09-04 | 81.0 | 6.6 | 11 | 1820920 |
| 4799 | [{"id": 35, "name": "Comedy"}, {"id": 10749, "... | [] | Newlyweds | 9000 | 117031352 | [] | 2011-12-26 | 85.0 | 5.9 | 8 | 117022352 |
| 4800 | [{"id": 35, "name": "Comedy"}, {"id": 18, "nam... | [{"id": 248, "name": "date"}, {"id": 699, "nam... | Signed, Sealed, Delivered | 37042837 | 117031352 | [{"name": "Front Street Pictures", "id": 3958}... | 2013-10-13 | 120.0 | 7.0 | 13 | 79988515 |
| 4801 | [] | [] | Shanghai Calling | 37042837 | 117031352 | [] | 2012-05-03 | 98.0 | 5.7 | 2 | 79988515 |
| 4802 | [{"id": 99, "name": "Documentary"}] | [{"id": 1523, "name": "obsession"}, {"id": 224... | My Date with Drew | 37042837 | 117031352 | [{"name": "rusty bear entertainment", "id": 87... | 2005-08-05 | 90.0 | 6.3 | 5 | 79988515 |
4803 rows × 11 columns
3、对于缺失值处理:通过上面的数据集信息可以知道,整个数据集缺失的数据中,“首次上映日期”缺失1个数据,“电影时长”缺失2个数据,故通过网上查询,使用fillna函数补齐数据。
# for i in range(4803):
# if pd.isnull(data5['首次上映日期'][i]):
# print(i, data5['电影名称'][i])
# data5['首次上映日期'][i]='2014-06-01'
data5['首次上映日期'] = data5['首次上映日期'].fillna('2014-06-01')
# for i in range(4803):
# if pd.isnull(data5['电影时长'][i]):
# print(i, data5['电影名称'][i])
value1 = {'电影时长':98.0}
value2 = {'电影时长':81.0}
data5.fillna(value=value1, limit=1, inplace=True)
data5.fillna(value=value2, limit=1, inplace=True)
4、①对于“风格列表”列数据处理:提取出每一列数据,使用正则表达式去除两边"[“和”]"字符,再用字符分隔函数,将剩余字符转换成列表;而后使用json中的json.loads函数将列表中每个元素转换为字典格式,并取出字典中“name”的值,即电影类型,将每部电影的电影类型存入列表,并在data5中新增“电影类型”列。
②对于“首次上映日期”列数据处理:先提取出每一列数据,再对其进行切片,取出前4个字符,即发行年份,再将其转换为int型数值,并在data5中新增“发行年份”列,再将“首次上映日期”列删除。
③对于“关键字”和“制作公司”两列:则是直接应用apply函数将json.loads函数应用于该列所有元素,将其直接转换为列表-元素都为字典格式。
all_movie_type = []
all_movie = set() #记录所有电影类型
for i in list(data5['风格列表']):
con = re.findall(re.compile(r'[[](.*?)[]]', re.S), i)[0]
list1 = con.split(", ")
str1 = ""
dict_list = []
for j in range(len(list1)):
if j%2 == 0:
str1 += str(list1[j]) + ", "
else:
str1 += str(list1[j])
dict_list.append(json.loads(str1))
str1=""
#提取电影类型
movie_type=[]
for j in dict_list:
all_movie.add(j['name'])
movie_type.append(j['name'])
all_movie_type.append(movie_type)
data5['电影类型'] = pd.Series(all_movie_type)
# all_movie
#首次上映日期处理
#时间格式转换
# data5['首次上映日期'] = pd.to_datetime(data5['首次上映日期'], format='%Y-%m-%d')
show_year = []
for i in list(data5['首次上映日期']):
year = int(i[0:4])
show_year.append(year)
data5['发行年份'] = pd.Series(show_year)
data5 = data5.drop('首次上映日期', axis='columns')
data5
| 风格列表 | 关键字 | 电影名称 | 预算(美元) | 收入(美元) | 制作公司 | 电影时长 | 平均评分 | 观看人数 | 利润 | 电影类型 | 发行年份 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | [{"id": 1463, "name": "culture clash"}, {"id":... | Avatar | 237000000 | 2787965087 | [{"name": "Ingenious Film Partners", "id": 289... | 162.0 | 7.2 | 153 | 2550965087 | [Action, Adventure, Fantasy, Science Fiction] | 2009 |
| 1 | [{"id": 12, "name": "Adventure"}, {"id": 14, "... | [{"id": 270, "name": "ocean"}, {"id": 726, "na... | Pirates of the Caribbean: At World's End | 300000000 | 961000000 | [{"name": "Walt Disney Pictures", "id": 2}, {"... | 169.0 | 6.9 | 32 | 661000000 | [Adventure, Fantasy, Action] | 2007 |
| 2 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | [{"id": 470, "name": "spy"}, {"id": 818, "name... | Spectre | 245000000 | 880674609 | [{"name": "Columbia Pictures", "id": 5}, {"nam... | 148.0 | 6.3 | 155 | 635674609 | [Action, Adventure, Crime] | 2015 |
| 3 | [{"id": 28, "name": "Action"}, {"id": 80, "nam... | [{"id": 849, "name": "dc comics"}, {"id": 853,... | The Dark Knight Rises | 250000000 | 1084939099 | [{"name": "Legendary Pictures", "id": 923}, {"... | 165.0 | 7.6 | 217 | 834939099 | [Action, Crime, Drama, Thriller] | 2012 |
| 4 | [{"id": 28, "name": "Action"}, {"id": 12, "nam... | [{"id": 818, "name": "based on novel"}, {"id":... | John Carter | 260000000 | 284139100 | [{"name": "Walt Disney Pictures", "id": 2}] | 132.0 | 6.1 | 132 | 24139100 | [Action, Adventure, Science Fiction] | 2012 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4798 | [{"id": 28, "name": "Action"}, {"id": 80, "nam... | [{"id": 5616, "name": "united states\u2013mexi... | El Mariachi | 220000 | 2040920 | [{"name": "Columbia Pictures", "id": 5}] | 81.0 | 6.6 | 11 | 1820920 | [Action, Crime, Thriller] | 1992 |
| 4799 | [{"id": 35, "name": "Comedy"}, {"id": 10749, "... | [] | Newlyweds | 9000 | 117031352 | [] | 85.0 | 5.9 | 8 | 117022352 | [Comedy, Romance] | 2011 |
| 4800 | [{"id": 35, "name": "Comedy"}, {"id": 18, "nam... | [{"id": 248, "name": "date"}, {"id": 699, "nam... | Signed, Sealed, Delivered | 37042837 | 117031352 | [{"name": "Front Street Pictures", "id": 3958}... | 120.0 | 7.0 | 13 | 79988515 | [Comedy, Drama, Romance, TV Movie] | 2013 |
| 4801 | [] | [] | Shanghai Calling | 37042837 | 117031352 | [] | 98.0 | 5.7 | 2 | 79988515 | [] | 2012 |
| 4802 | [{"id": 99, "name": "Documentary"}] | [{"id": 1523, "name": "obsession"}, {"id": 224... | My Date with Drew | 37042837 | 117031352 | [{"name": "rusty bear entertainment", "id": 87... | 90.0 | 6.3 | 5 | 79988515 | [Documentary] | 2005 |
4803 rows × 12 columns
数据分析及可视化
问题一:电影类型如何随着时间的推移发生变化的?
count_type = dict.fromkeys(all_movie,0)
for i in data5['电影类型']:
for j in i:
count_type[j] += 1
count_type
{'Romance': 894,
'Family': 513,
'War': 144,
'Foreign': 34,
'Horror': 519,
'Drama': 2297,
'History': 197,
'Mystery': 348,
'Music': 185,
'Adventure': 790,
'TV Movie': 8,
'Action': 1154,
'Fantasy': 424,
'Western': 82,
'Animation': 234,
'Thriller': 1274,
'Comedy': 1722,
'Crime': 696,
'Documentary': 110,
'Science Fiction': 535}
dt = {'电影类型':count_type.keys(),'电影数量(部)':count_type.values()}
data6 = pd.DataFrame(dt)
data6
| 电影类型 | 电影数量(部) | |
|---|---|---|
| 0 | Romance | 894 |
| 1 | Family | 513 |
| 2 | War | 144 |
| 3 | Foreign | 34 |
| 4 | Horror | 519 |
| 5 | Drama | 2297 |
| 6 | History | 197 |
| 7 | Mystery | 348 |
| 8 | Music | 185 |
| 9 | Adventure | 790 |
| 10 | TV Movie | 8 |
| 11 | Action | 1154 |
| 12 | Fantasy | 424 |
| 13 | Western | 82 |
| 14 | Animation | 234 |
| 15 | Thriller | 1274 |
| 16 | Comedy | 1722 |
| 17 | Crime | 696 |
| 18 | Documentary | 110 |
| 19 | Science Fiction | 535 |
绘制各种电影类型数量统计图
plt.figure(figsize=(9,6))
plt.barh(range(20), count_type.values(), height=0.7, color='steelblue', alpha=0.8)
plt.yticks(range(20), count_type.keys())
plt.xlim(0, 2400)
plt.xlabel("电影数量(部)")
plt.ylabel("电影类型")
plt.title("各种电影类型数量统计图")
for x,y in enumerate(count_type.values()):
plt.text(y+0.2, x-0.1, '%s'%y+"部")
# plt.savefig('./img/各种电影类型数量统计图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
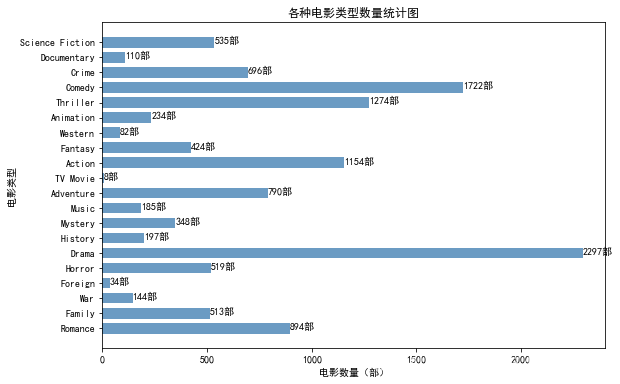
分析结论:从图中清晰看出从1910~2015年以来最受欢迎的三种电影类型分别为:Drama、Comedy、Thriller。
绘制各种电影类型占比的饼图
plt.rcParams['figure.figsize']=(18, 15)
movie_count = data6['电影数量(部)'].values
movie_sum = data6['电影数量(部)'].sum()
#计算各个电影类型所占百分比
percentage = (movie_count/movie_sum)*100
#保留两位小数
np.set_printoptions(precision=2)
labels = data6['电影类型'].values
plt.axes(aspect=1)
plt.pie(x = percentage, labels=labels, autopct='%.2f %%', shadow=False,
labeldistance=1.2, startangle = 90, pctdistance = 0.7)
plt.legend(loc='upper right')
# plt.savefig('./img/各种电影类型占比图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
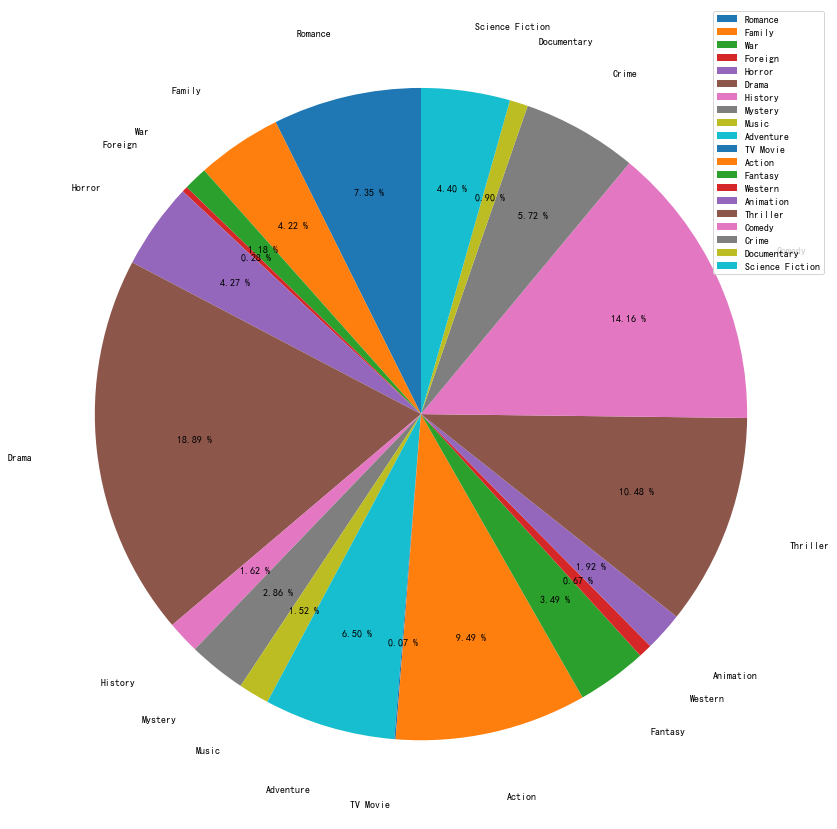
分析结论:从上面的结果可以看出,随着时间的推移,电影类型数量总体呈现逐年上升趋势,其中在所有电影类型中,数量排名前三的电影类型分别是:Drama、Comedy、Thriller,Drama的类型电影最多,占到了总体的18.9%。
data7 = pd.DataFrame()
# #以电影类型作为列索引,表中数据全部置为0
# for i in all_movie:
# data7[i] = 0
# data7['xx']=data5['风格列表']
# data7 = data7.drop('xx', axis='columns')
# #记录每一部电影中的对应电影类型
#缺点:运行效率较差
# for i in range(4803):
# for j in data5['电影类型'][i]:
# data7[j][i] += 1
# data7
绘制电影类型随时间变化的趋势图:
创建每种电影类型为特征的dataframe数据集data7,且使用dataframe.str.contains函数搜索每部电影中是否某种电影类型,若存在,则在data7对应电影的该电影类型中记录,然后使用groupby函数进行分组统计每个年份各种电影类型的发行数量,最后使用matplotlib中的plot函数绘制对应趋势图。
for genre in all_movie:
data7[genre] = data5['风格列表'].str.contains(genre).apply(lambda x:1 if x else 0)
data7.index = data5['发行年份']
movie_year = data7.groupby('发行年份').sum()
movie_year.head()
movie_year.tail()
| Romance | Family | War | Foreign | Horror | Drama | History | Mystery | Music | Adventure | TV Movie | Action | Fantasy | Western | Animation | Thriller | Comedy | Crime | Documentary | Science Fiction | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 发行年份 | ||||||||||||||||||||
| 2013 | 25 | 22 | 3 | 0 | 25 | 110 | 8 | 5 | 12 | 36 | 2 | 56 | 21 | 1 | 17 | 53 | 71 | 37 | 10 | 27 |
| 2014 | 24 | 23 | 10 | 0 | 21 | 110 | 7 | 15 | 9 | 37 | 0 | 54 | 16 | 3 | 14 | 66 | 62 | 27 | 7 | 26 |
| 2015 | 23 | 17 | 2 | 0 | 33 | 95 | 9 | 20 | 8 | 35 | 0 | 46 | 10 | 7 | 13 | 67 | 52 | 26 | 7 | 28 |
| 2016 | 9 | 9 | 3 | 0 | 20 | 37 | 6 | 6 | 1 | 23 | 0 | 39 | 13 | 1 | 4 | 27 | 26 | 10 | 0 | 11 |
| 2017 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
plt.figure(figsize=(12,8))
plt.plot(movie_year, label=movie_year.columns)
plt.xticks(range(1910,2018,5))
plt.legend(movie_year)
plt.title('电影类型随时间变化的趋势',fontsize=15)
plt.xlabel('年份',fontsize=15)
plt.ylabel('数量(部)',fontsize=15)
plt.grid(True) #显示网格线
# plt.savefig('./img/电影类型随时间变化的趋势图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
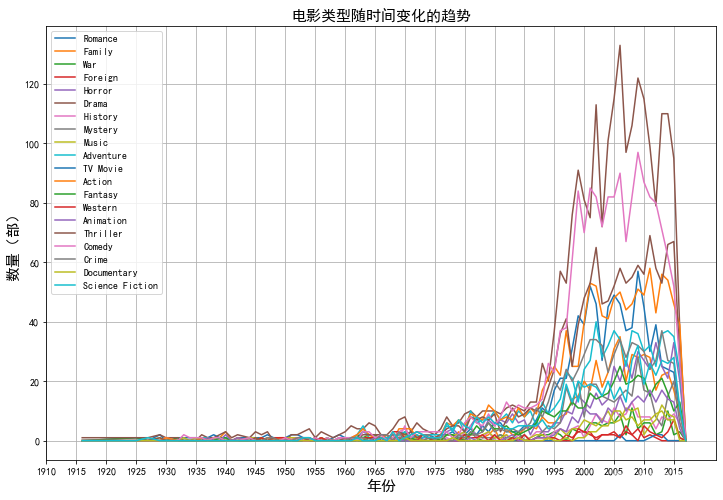
分析结论:从图中可知,可以看出随着时间的推移电影类型的数量越来越多,其中Drama(戏剧)和Comedy(喜剧)数量增长远比其他电影类型快,常年深受观众喜爱。
问题二:电影类型与利润的关系?
genre_profit = dict.fromkeys(all_movie,0)
for i in range(4803):
for j in data5['电影类型'][i]:
genre_profit[j] += data5['利润'][i]
for i in data6['电影类型']:
genre_profit[i] /= count_type[i]
# genre_profit
dt = {'电影类型':genre_profit.keys(),'利润':genre_profit.values()}
genre_profit_data = pd.DataFrame(dt)
genre_profit_data
| 电影类型 | 利润 | |
|---|---|---|
| 0 | Romance | 6.878714e+07 |
| 1 | Family | 1.340737e+08 |
| 2 | War | 6.366630e+07 |
| 3 | Foreign | 6.775845e+07 |
| 4 | Horror | 6.043865e+07 |
| 5 | Drama | 6.157373e+07 |
| 6 | History | 4.971221e+07 |
| 7 | Mystery | 6.903151e+07 |
| 8 | Music | 6.342341e+07 |
| 9 | Adventure | 1.560404e+08 |
| 10 | TV Movie | 9.272958e+07 |
| 11 | Action | 1.069430e+08 |
| 12 | Fantasy | 1.460115e+08 |
| 13 | Western | 4.191084e+07 |
| 14 | Animation | 1.766170e+08 |
| 15 | Thriller | 7.216813e+07 |
| 16 | Comedy | 7.437827e+07 |
| 17 | Crime | 5.966100e+07 |
| 18 | Documentary | 5.602798e+07 |
| 19 | Science Fiction | 1.174366e+08 |
绘制各种电影类型的平均利润统计图
plt.rcParams['figure.figsize']=(9, 6)
# 对于‘利润’列数据按值大小进行降序排序
genre_profit_data.sort_values(by='利润',ascending=True).plot(kind='barh')
plt.yticks(range(20), genre_profit_data['电影类型'])
plt.title('各种电影类型的平均利润')
plt.xlabel('平均利润(美元)')
plt.ylabel('电影类型')
# plt.savefig('./img/各种电影类型的平均利润图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
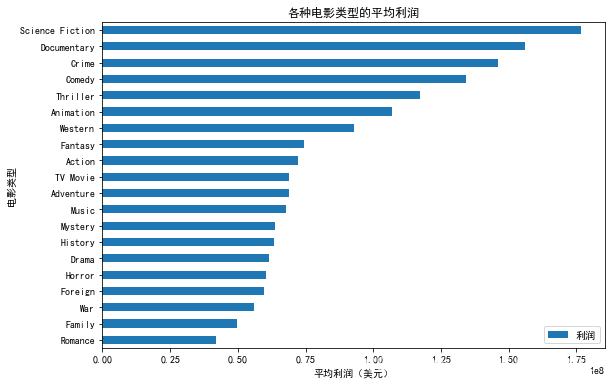
分析结论:History、Fantasy、Mystery三种电影类型利润最客观,然而电影类型数量排名第二的Comedy利润缺排在了倒数第一,可能是因为该类型电影的市场斗争太过激烈,拍摄此电影有一定的风险。
问题三:3.Universal Pictures和Paramount Pictures两家影视公司发行电影的对比情况如何?
data5['制作公司'] = data5['制作公司'].apply(json.loads) #格式转换
def decode(column):
z = []
for i in column:
z.append(i['name'])
return ' '.join(z)
data5['制作公司'] = data5['制作公司'].apply(decode)
data5['制作公司'].head(3)
0 Ingenious Film Partners Twentieth Century Fox ...
1 Walt Disney Pictures Jerry Bruckheimer Films S...
2 Columbia Pictures Danjaq B24
Name: 制作公司, dtype: object
company_st = pd.DataFrame()
company_st['Universal Pictures'] = data5['制作公司'].str.contains('Universal Pictures').apply(lambda x:1 if x else 0)
company_st['Paramount Pictures'] = data5['制作公司'].str.contains('Paramount Pictures').apply(lambda x:1 if x else 0)
company_st
| Universal Pictures | Paramount Pictures | |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 0 | 0 |
| 2 | 0 | 0 |
| 3 | 0 | 0 |
| 4 | 0 | 0 |
| ... | ... | ... |
| 4798 | 0 | 0 |
| 4799 | 0 | 0 |
| 4800 | 0 | 0 |
| 4801 | 0 | 0 |
| 4802 | 0 | 0 |
4803 rows × 2 columns
dict_company = {'Universal Pictures':company_st['Universal Pictures'].sum(), 'Paramount Pictures':company_st['Paramount Pictures'].sum()}
company_vs = pd.Series(dict_company)
company_vs
Universal Pictures 314
Paramount Pictures 285
dtype: int64
绘制两家公司电影发行数量对比的饼状图
plt.rcParams['figure.figsize']=(12, 8)
#计算各个电影类型所占百分比
percentage = (company_vs.values/company_vs.sum())*100
#保留两位小数
np.set_printoptions(precision=2)
plt.axes(aspect=1)
plt.pie(x = company_vs, labels=company_vs.index, autopct='%.2f %%', shadow=False,
labeldistance=1.2, startangle = 90, pctdistance = 0.7)
plt.title('Universal Pictures和Paramount Pictures两家公司电影发行数量对比')
# plt.savefig('./img/Universal Pictures和Paramount Pictures两家公司电影发行数量对比图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
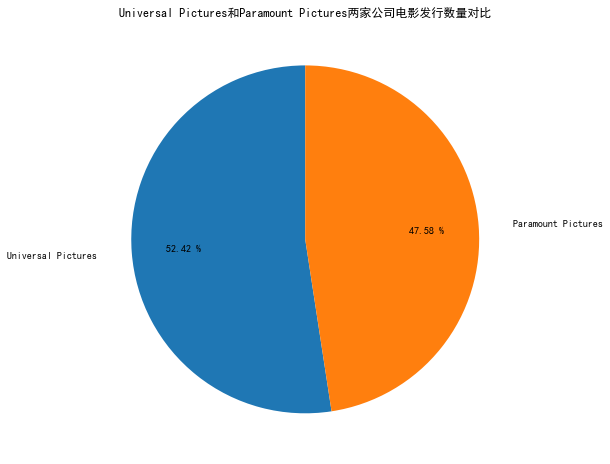
company_data = company_st[['Universal Pictures','Paramount Pictures']]
company_data.index = data5['发行年份']
company_data = company_data.groupby('发行年份').sum()
company_data
| Universal Pictures | Paramount Pictures | |
|---|---|---|
| 发行年份 | ||
| 1916 | 0 | 0 |
| 1925 | 0 | 0 |
| 1927 | 0 | 1 |
| 1929 | 0 | 0 |
| 1930 | 0 | 0 |
| ... | ... | ... |
| 2013 | 9 | 8 |
| 2014 | 10 | 8 |
| 2015 | 13 | 7 |
| 2016 | 10 | 5 |
| 2017 | 0 | 0 |
90 rows × 2 columns
绘制两家公司电影发行量的时间走势图
plt.figure(figsize=(12,8))
plt.plot(company_data, label=company_data.columns)
plt.xticks(range(1910,2018,5))
plt.legend(company_data)
plt.title('Universal Pictures和Paramount Pictures公司电影的发行量时间走势',fontsize=15)
plt.xlabel('年份',fontsize=15)
plt.ylabel('数量(部)',fontsize=15)
plt.grid(True) #显示网格线
# plt.savefig('./img/Universal Pictures和Paramount Pictures公司电影的发行量时间走势图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
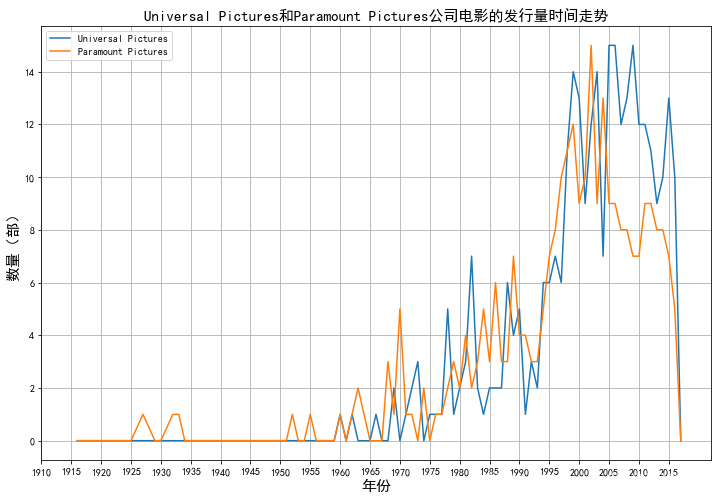
分析结论:两家公司针对电影发行数量相比差异不算很大,但Universal Pictures相比Paramount Picture仍然略胜一筹,从1965年开始两家电影公司发行数量开始增长迅速。
问题四:改编电影和原创电影的对比情况如何?
data5['关键字'] = data5['关键字'].apply(json.loads) #格式转换
def decode(column):
z = []
for i in column:
z.append(i['name'])
return ' '.join(z)
data5['关键字'] = data5['关键字'].apply(decode)
data5['关键字'].head(3)
0 culture clash future space war space colony so...
1 ocean drug abuse exotic island east india trad...
2 spy based on novel secret agent sequel mi6 bri...
Name: 关键字, dtype: object
data5['原创与改编'] = data5['关键字'].str.contains('based on novel').apply(lambda x: 'no original' if x else 'original')
data5['原创与改编'].value_counts()
original 4606
no original 197
Name: 原创与改编, dtype: int64
original_profit = data5[['原创与改编','预算(美元)','收入(美元)','利润']]
original_profit = original_profit.groupby(by='原创与改编').mean()
original_profit
| 预算(美元) | 收入(美元) | 利润 | |
|---|---|---|---|
| 原创与改编 | |||
| no original | 4.795794e+07 | 1.545032e+08 | 1.065453e+08 |
| original | 3.657600e+07 | 1.154287e+08 | 7.885267e+07 |
绘制改编电影与原创电影在预算、收入及利润三方面进行比较的柱状图
plt.figure(figsize=(12,8))
original_profit.plot(kind='bar')
plt.title('改编电影与原创电影在预算、收入和利润的比较')
plt.xlabel('改编电影与原创电影')
plt.ylabel('金额(美元)')
# plt.savefig('./img/改编电影与原创电影在预算、收入和利润的比较图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
<Figure size 864x576 with 0 Axes>
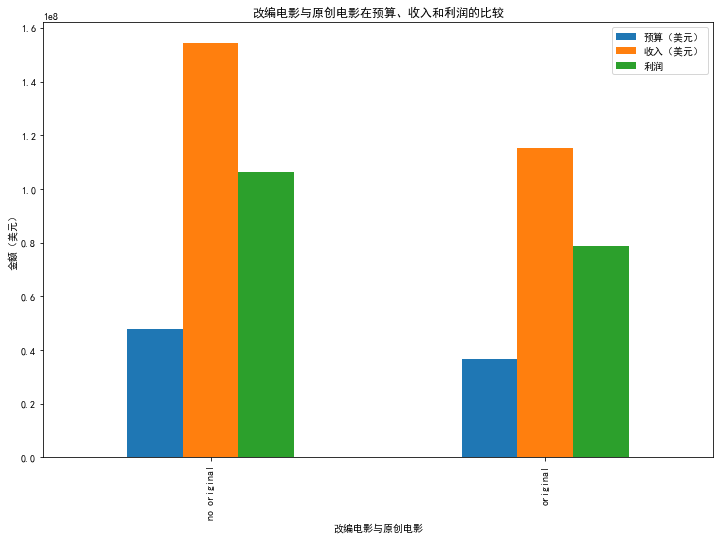
分析结论:如图可以看出改编电影不管是预算、收入还是利润相比原创电影都更略胜一筹,这可能是改变电影的资金投入更多导致的原因
问题五:电影时长与电影票房及评分的关系
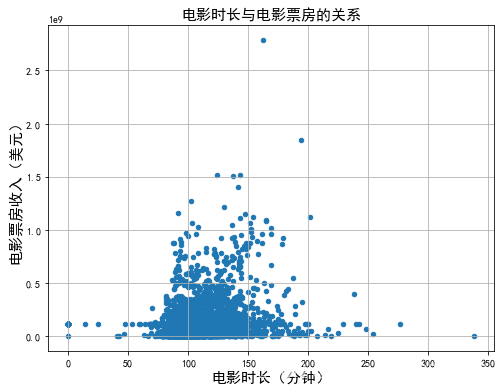
绘制电影时长与电影票房收入关系图
#电影时长与电影票房的关系:
data5.plot(kind='scatter', x='电影时长', y='收入(美元)', figsize=(8,6))
plt.title('电影时长与电影票房的关系',fontsize = 15)
plt.xlabel('电影时长(分钟)',fontsize=15)
plt.ylabel('电影票房收入(美元)',fontsize=15)
plt.grid(True)
# plt.savefig('./img/电影时长与电影票房的关系图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
绘制电影时长与电影票房平均评分关系图
#电影时长与电影平均评分的关系:
data5.plot(kind='scatter', x='电影时长', y='平均评分', figsize=(8,6))
plt.title('电影时长与电影票房的关系',fontsize = 15)
plt.xlabel('电影时长(分钟)',fontsize=15)
plt.ylabel('电影平均评分',fontsize=15)
plt.grid(True)
# plt.savefig('./img/电影时长与电影票房的关系图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()

分析结论:从图上可以看出,拍摄电影要想获得较高的票房及口碑,电影的时长应保持在90~150分钟之间。
问题六:分析电影关键字
keywords_list = []
for i in data5['关键字']:
keywords_list.append(i)
keywords = ''.join(keywords_list)
生成电影关键字词云图
mv_wc = WordCloud(background_color='black',
max_words=2000,
max_font_size=100,
random_state=12)
# 根据字符串生成词云
mv_wc.generate(keywords)
plt.figure(figsize=(16,8))
# 显示图片
plt.imshow(mv_wc)
plt.axis('off') #关闭坐标轴
# plt.savefig('./img/词云图.png', dpi=600, format='png', bbox_inches='tight')
plt.show()
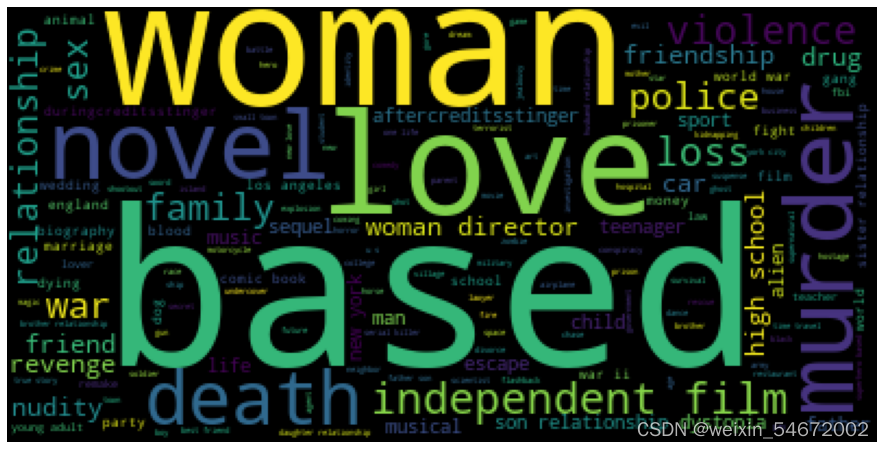
分析结论:通过对电影关键字的分析,电影出现数量最多的词是based,其次是women、love、novel、murder。可以看出女性和爱这方面题材电影最受大众喜爱,小说类和犯罪类的电影同样也深受大家的欢迎。
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











