







2022华数杯数学建模竞赛C题(插层熔喷)思路 - 哔哩哔哩 (bilibili.com)
题目1
研究插层后结构变量、产品性能的变化规律
import pandas as pd
'''
问题1 相关代码
https://www.bilibili.com/read/cv17932799
'''
# step1 数据读取及初步处理
def data_split(data,l):
# df1 没有插层 df2 经过插层
df1 = pd.DataFrame(index=['index'],
columns=['厚度mm','孔隙率(%)','压缩回弹性率(%)','过滤阻力Pa','过滤效率(%)','透气性 mm/s'])
df2 = pd.DataFrame(index=['index'],
columns=['厚度mm', '孔隙率(%)', '压缩回弹性率(%)', '过滤阻力Pa', '过滤效率(%)', '透气性 mm/s' ,'插层率(%)'])
for i in range(0,l,2):
new1 = pd.DataFrame(
{'厚度mm': data.loc[i]['厚度mm'],
'孔隙率(%)': data.loc[i]['孔隙率(%)'], '压缩回弹性率(%)': data.loc[i]['压缩回弹性率(%)'], '过滤阻力Pa': data.loc[i]['过滤阻力Pa'],
'过滤效率(%)': data.loc[i]['过滤效率(%)'], '透气性 mm/s': data.loc[i]['透气性 mm/s'], },
index=[i])
new2 = pd.DataFrame(
{'厚度mm': data.loc[i+1]['厚度mm'],
'孔隙率(%)': data.loc[i+1]['孔隙率(%)'], '压缩回弹性率(%)': data.loc[i+1]['压缩回弹性率(%)'], '过滤阻力Pa': data.loc[i+1]['过滤阻力Pa'],
'过滤效率(%)': data.loc[i+1]['过滤效率(%)'], '透气性 mm/s': data.loc[i+1]['透气性 mm/s'],'插层率(%)': data.loc[i+1]['插层率(%)']},
index=[i])
df1 = pd.concat([df1, new1], ignore_index=True)
df2 = pd.concat([df2, new2], ignore_index=True)
return df1,df2
df = pd.read_excel('data_b.xlsx')
df.drop(df.tail(1).index,inplace=True) # 丢弃最后一行数据
print(df.head(5))
# print(df.isna().sum())
'''
组号 25
插层率(%) 25
'''
l_df = len(df)
# 将数据分为两个数据 一个是有插层 一个是没有插层
df1, df2 = data_split(df,l_df) # 数据分成两个dataframe,df1 没有进行插层 df2 进行插层
df1.drop(df.head(1).index,inplace=True)
df2.drop(df.head(1).index,inplace=True)
print('df1', '\n', df1.head(5))
print('df2', '\n', df2.head(5))
# step2 数据分析
# 对两者的方差进行分析
# var1 = df1.var()
# var2 = df2.var()
# print(var1)
# print(var2)
# 做表格用以之后的说明
# var_compare = pd.DataFrame(
# columns=['是否插层','厚度mm','孔隙率(%)','压缩回弹性率(%)','过滤阻力Pa','过滤效率(%)','透气性 mm/s'])
# new_1 = pd.DataFrame({'是否插层':'0', '厚度mm':var1[0],
# '孔隙率(%)': var1[1], '压缩回弹性率(%)': var1[2], '过滤阻力Pa': var1[3],
# '过滤效率(%)': var1[4], '透气性 mm/s':var1[5]},index=[0])
# new_2 = pd.DataFrame({'是否插层':'1', '厚度mm':var2[0],
# '孔隙率(%)': var2[1], '压缩回弹性率(%)': var2[2], '过滤阻力Pa': var2[3],
# '过滤效率(%)': var2[4], '透气性 mm/s':var2[5]},index=[1])
# var_compare = pd.concat([var_compare, new_1], ignore_index=True)
# var_compare = pd.concat([var_compare, new_2], ignore_index=True)
# print(var_compare)
# var_compare.to_excel('t1-方差比较.xlsx',index=False)
# 其余同理 中位数 平均数
def data_analyse(data1,data2, way,save_name):
if way == 'var':
aly1 = data1.var().round(2)
aly2 = data2.var().round(2)
elif way == 'mean':
aly1 = data1.mean().round(2)
aly2 = data2.mean().round(2)
else:
aly1 = data1.median().round(2)
# print(aly1)
aly2 = data2.median().round(2)
# print(aly2)
newd = pd.DataFrame(
columns=['是否插层','厚度mm','孔隙率(%)','压缩回弹性率(%)','过滤阻力Pa','过滤效率(%)','透气性 mm/s'])
new_1 = pd.DataFrame({'是否插层':'0', '厚度mm':aly1[0],
'孔隙率(%)': aly1[1], '压缩回弹性率(%)': aly1[2], '过滤阻力Pa': aly1[3],
'过滤效率(%)': aly1[4], '透气性 mm/s':aly1[5]},index=[0])
new_2 = pd.DataFrame({'是否插层':'1', '厚度mm':aly2[0],
'孔隙率(%)': aly2[1], '压缩回弹性率(%)': aly2[2], '过滤阻力Pa': aly2[3],
'过滤效率(%)': aly2[4], '透气性 mm/s':aly2[5]},index=[1])
newd = pd.concat([newd, new_1], ignore_index=True)
newd = pd.concat([newd, new_2], ignore_index=True)
newd.to_excel(save_name + '.xlsx', index=False)
data_analyse(df1,df2,'var','t1-方差比较')
data_analyse(df1,df2,'median','t1-中位数比较')
data_analyse(df1,df2,'mean','t1-均值比较')分析插层率对于这些变化是否有影响
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
from numpy import *
'''
问题1 相关代码
https://www.bilibili.com/read/cv17932799
'''
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 #有中文出现的情况,需要u'内容'
# step1 数据读取及初步处理
def data_split(data,l):
# df1 没有插层 df2 经过插层
df1 = pd.DataFrame(index=['index'],
columns=['厚度mm','孔隙率(%)','压缩回弹性率(%)','过滤阻力Pa','过滤效率(%)','透气性 mm/s'])
df2 = pd.DataFrame(index=['index'],
columns=['厚度mm', '孔隙率(%)', '压缩回弹性率(%)', '过滤阻力Pa', '过滤效率(%)', '透气性 mm/s' ,'插层率(%)'])
for i in range(0,l,2):
new1 = pd.DataFrame(
{'厚度mm': data.loc[i]['厚度mm'],
'孔隙率(%)': data.loc[i]['孔隙率(%)'], '压缩回弹性率(%)': data.loc[i]['压缩回弹性率(%)'], '过滤阻力Pa': data.loc[i]['过滤阻力Pa'],
'过滤效率(%)': data.loc[i]['过滤效率(%)'], '透气性 mm/s': data.loc[i]['透气性 mm/s'], },
index=[i])
new2 = pd.DataFrame(
{'厚度mm': data.loc[i+1]['厚度mm'],
'孔隙率(%)': data.loc[i+1]['孔隙率(%)'], '压缩回弹性率(%)': data.loc[i+1]['压缩回弹性率(%)'], '过滤阻力Pa': data.loc[i+1]['过滤阻力Pa'],
'过滤效率(%)': data.loc[i+1]['过滤效率(%)'], '透气性 mm/s': data.loc[i+1]['透气性 mm/s'],'插层率(%)': data.loc[i+1]['插层率(%)']},
index=[i])
df1 = pd.concat([df1, new1], ignore_index=True)
df2 = pd.concat([df2, new2], ignore_index=True)
return df1,df2
df = pd.read_excel('data_b.xlsx')
df.drop(df.tail(1).index,inplace=True) # 丢弃最后一行数据
# print(df.head(5))
# print(df.isna().sum())
'''
组号 25
插层率(%) 25
'''
l_df = len(df)
# 将数据分为两个数据 一个是有插层 一个是没有插层
df1, df2 = data_split(df,l_df) # 数据分成两个dataframe,df1 没有进行插层 df2 进行插层
df1.drop(df.head(1).index,inplace=True)
df2.drop(df.head(1).index,inplace=True)
# print('df1', '\n', df1.head(5))
print('df2', '\n', df2.head(5))
# step2 分析插层率的影响
# 无量纲化
def dimensionlessProcessing(df):
newDataFrame = pd.DataFrame(index=df.index)
columns = df.columns.tolist()
for c in columns:
d = df[c]
MAX = d.max()
MIN = d.min()
MEAN = d.mean()
newDataFrame[c] = ((d - MEAN) / (MAX - MIN)).tolist()
return newDataFrame
data = dimensionlessProcessing(df2)
print(data.head(5))
def get_Gra(gray):
std = gray.iloc[:, -1] # 为标准要素
std.index = std.index - 1
# print(std)
ce = gray.iloc[:, 0:-1] # 为比较要素
ce.index = ce.index - 1
# print(ce)
shape_n, shape_m = ce.shape[0], ce.shape[1] # 计算行列
# print(shape_n, shape_m) # 25行 6列
# 与标准要素比较,相减
a = zeros([shape_m, shape_n])
for i in range(shape_m):
for j in range(shape_n):
a[i, j] = abs(ce.iloc[j, i] - std[j])
# # 取出矩阵中最大值与最小值
c, d = amax(a), amin(a)
# 计算值
result = zeros([shape_m, shape_n])
for i in range(shape_m):
for j in range(shape_n):
result[i, j] = (d + 0.5 * c) / (a[i, j] + 0.5 * c)
# 求均值,得到灰色关联值,并返回
result_list = [mean(result[i, :]) for i in range(shape_m)]
print(result_list)
# get_Gra(data)
# 无量纲化
def dimensionlessProcessing(df):
newDataFrame = pd.DataFrame(index=df.index)
columns = df.columns.tolist()
for c in columns:
d = df[c]
MAX = d.max()
MIN = d.min()
MEAN = d.mean()
newDataFrame[c] = ((d - MEAN) / (MAX - MIN)).tolist()
return newDataFrame
def GRA_ONE(gray, m=0):
# 读取为df格式
gray = dimensionlessProcessing(gray)
# 标准化
std = gray.iloc[:, m] # 为标准要素
std.index = std.index - 1
gray.drop(str(m),axis=1,inplace=True)
ce = gray.iloc[:, 0:] # 为比较要素
ce.index = ce.index - 1
shape_n, shape_m = ce.shape[0], ce.shape[1] # 计算行列
# 与标准要素比较,相减
a = zeros([shape_m, shape_n])
for i in range(shape_m):
for j in range(shape_n):
a[i, j] = abs(ce.iloc[j, i] - std[j])
# 取出矩阵中最大值与最小值
c, d = amax(a), amin(a)
# 计算值
result = zeros([shape_m, shape_n])
for i in range(shape_m):
for j in range(shape_n):
result[i, j] = (d + 0.5 * c) / (a[i, j] + 0.5 * c)
# 求均值,得到灰色关联值,并返回
result_list = [mean(result[i, :]) for i in range(shape_m)]
result_list.insert(m,1)
return pd.DataFrame(result_list)
def GRA(DataFrame):
df = DataFrame.copy()
list_columns = [
str(s) for s in range(len(df.columns)) if s not in [None]
]
df_local = pd.DataFrame(columns=list_columns)
df.columns=list_columns
for i in range(len(df.columns)):
df_local.iloc[:, i] = GRA_ONE(df, m=i)[0]
return df_local
# 灰色关联结果矩阵可视化
# 灰色关联结果矩阵可视化
import seaborn as sns
def ShowGRAHeatMap(DataFrame):
colormap = plt.cm.RdBu
ylabels = DataFrame.columns.values.tolist()
f, ax = plt.subplots(figsize=(14, 14))
ax.set_title('GRA HeatMap')
# 设置展示一半,如果不需要注释掉mask即可
# mask = np.zeros_like(DataFrame)
# mask[np.triu_indices_from(mask)] = True
with sns.axes_style("white"):
sns.heatmap(DataFrame,
cmap="YlGnBu",
annot=True,
# mask=mask,
)
plt.show()
data_gra = GRA(df2)
ShowGRAHeatMap(data_gra)
题目2
建模绘图部分
import pandas as pd
import numpy as np
from sklearn.neural_network import MLPRegressor
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error #MSE
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import r2_score#R 2
'''
BP 神经网络进行回归预测
'''
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
data = data.drop(columns=['过滤阻力Pa','过滤效率(%)','透气性 mm/s'])
print(data.head())
# 数据归一化
scaler = MinMaxScaler() #实例化
# data = scaler.fit_transform(data)
data = np.array(data)
# print(data)
# 划分数据集
test_size = 0.2
tr_x = data[:int(len(data)*(1-test_size)),:2]
tr_x = scaler.fit_transform(tr_x)
tr_y = data[:int(len(data)*(1-test_size)),2:]
# print(tr_y)
tr_y = scaler.fit_transform(tr_y)
# print(tr_y)
# print(tr_x)
# print(tr_y)
te_x = data[int(len(data)*(1-test_size)):,:2]
te_x = scaler.fit_transform(te_x)
print(te_x)
te_y = data[int(len(data)*(1-test_size)):,2:]
te_y = scaler.fit_transform(te_y)
mlp=MLPRegressor(hidden_layer_sizes=(100,50),
activation='relu',
solver='adam',
alpha=0.01,
batch_size='auto',
learning_rate='constant',
learning_rate_init=0.01,
power_t=0.5,max_iter=2000,shuffle=True, random_state=5, tol=0.0001)
mlp.fit(tr_x,tr_y)
# pre = mlp.predict(te_x) # 模型预测
# print(pre)
# 出图
tr_pre = mlp.predict(tr_x) # 模型预测
print('训练集MSE',mean_squared_error(tr_y,tr_pre))
print('训练集MAE',mean_absolute_error(tr_y,tr_pre))
print('训练集RMSE',np.sqrt(mean_squared_error(tr_y,tr_pre)))
print('训练集R2',r2_score(tr_y,tr_pre))
tr_pre = scaler.inverse_transform(tr_pre)
tr_real = scaler.inverse_transform(tr_y)
plt.figure(0,figsize=(15,20))
for i in range(3):
plt.subplot(3,1,i+1)
x = range(len(tr_real))
y1 = tr_real[:,i]
y2 = tr_pre[:,i]
p1, = plt.plot(x,y1)
p2, =plt.plot(x, y2)
plt.legend([p1,p2],['真实','预测'])
if i == 0:
plt.title('训练集 厚度mm 预测效果图 ')
elif i == 1:
plt.title('训练集 孔隙率(%)预测效果图')
elif i == 2:
plt.title('训练集 压缩回弹性率(%))预测效果图')
te_pre = mlp.predict(te_x) # 模型预测
print('测试集MSE',mean_squared_error(te_y,te_pre))
print('测试集MAE',mean_absolute_error(te_y,te_pre))
print('测试集RMSE',np.sqrt(mean_squared_error(te_y,te_pre)))
print('测试集R2',r2_score(te_y,te_pre))
te_pre = scaler.inverse_transform(te_pre)
te_real = scaler.inverse_transform(te_y)
plt.figure(1,figsize=(15,20))
for i in range(3):
plt.subplot(3,1,i+1)
x = range(len(te_real))
y1 = te_real[:,i]
y2 = te_pre[:,i]
p1, = plt.plot(x,y1)
p2, =plt.plot(x, y2)
plt.legend([p1,p2],['真实','预测'])
if i == 0:
plt.title('测试集 厚度mm 预测效果图 ')
elif i == 1:
plt.title('测试集 孔隙率(%)预测效果图')
elif i == 2:
plt.title('测试集 压缩回弹性率(%))预测效果图')
plt.show()填表部分
import pandas as pd
import numpy as np
from sklearn.neural_network import MLPRegressor
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error #MSE
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import r2_score#R 2
'''
BP 神经网络进行回归预测
'''
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
data = data.drop(columns=['过滤阻力Pa','过滤效率(%)','透气性 mm/s'])
print(data.head())
# 数据归一化
scaler = MinMaxScaler() #实例化
# data = scaler.fit_transform(data)
data = np.array(data)
# print(data)
# 划分数据集
test_size = 0.2
tr_x = data[:int(len(data)*(1-test_size)),:2]
tr_x = scaler.fit_transform(tr_x)
tr_y = data[:int(len(data)*(1-test_size)),2:]
# print(tr_y)
tr_y = scaler.fit_transform(tr_y)
# print(tr_y)
# print(tr_x)
# print(tr_y)
te_x = data[int(len(data)*(1-test_size)):,:2]
te_x = scaler.fit_transform(te_x)
print(te_x)
te_y = data[int(len(data)*(1-test_size)):,2:]
te_y = scaler.fit_transform(te_y)
mlp=MLPRegressor(hidden_layer_sizes=(100,50),
activation='relu',
solver='adam',
alpha=0.01,
batch_size='auto',
learning_rate='constant',
learning_rate_init=0.01,
power_t=0.5,max_iter=2000,shuffle=True, random_state=5, tol=0.0001)
mlp.fit(tr_x,tr_y)
# 结果预测写入数据
data_in = np.array([[38,850],
[33,950],
[28,1150],
[23,1250],
[38,1250],
[33,1150],
[28,950],
[23,850]])
data_in = scaler.fit_transform(data_in)
# 归一化的特点
d = data[:,2:]
d = scaler.fit_transform(d)
data_out = mlp.predict(data_in)
data_out = scaler.inverse_transform(data_out)
print('题目二填入的数据','\n',data_out)题目3
变量相关性分析绘图
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
# data = data[['厚度mm','孔隙率(%)','压缩回弹性率(%)']]
data = data[['过滤阻力Pa','过滤效率(%)','透气性 mm/s']]
print(data.head())
# 相关性分析
# 所有变量整体分析
# all_cor = data.corr(method='pearson')#默认为'pearson'检验,可选'kendall','spearman'
# plt.figure(1)
# sns.heatmap(all_cor,annot=True, vmax=1, square=True)#绘制new_df的矩阵热力图
# plt.show()#显示图片
plt.figure(0,figsize=(25,10))
m_l = ['pearson','kendall','spearman']
for i in range(3):
plt.subplot(1,3,i+1)
all_cor = data.corr(method=m_l[i])
sns.heatmap(all_cor, annot=True, vmax=1, square=True)
plt.title("产品性能"+m_l[i]+'相关性分析')
plt.show()过滤效率 预测模型设计
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import r2_score#R 2
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
'''
研究当工艺参数为多少时,产品的过滤效率将会达到最高
BP 神经网络模型求解
用遗传算法找最优情况
'''
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
data = data[['接收距离(cm)','热风速度(r/min)','过滤效率(%)']]
print(data.head())
# BP 神经网络进行模拟
mlp = MLPRegressor(hidden_layer_sizes=(100,50),
activation='relu',
solver='adam',
alpha=0.01,
batch_size='auto',
learning_rate='constant',
learning_rate_init=0.05,
power_t=0.5, max_iter=2000, shuffle=True, random_state=5, tol=0.0001)
scaler = StandardScaler()
data = np.array(data)
print(data)
d = np.array([40,800,100])
data = np.append(data,d).reshape(76,3)
print(data)
data = scaler.fit_transform((data))
print(data)
x = data[:-1,:2]
print(x)
y = data[:-1,2:]
y = y.reshape(len(y),)
mlp.fit(x, y)
# 训练集
y_pre = mlp.predict(x) # 模型预测
print('训练集MSE', mean_squared_error(y, y_pre))
print('训练集MAE',mean_absolute_error(y, y_pre))
print('训练集RMSE',np.sqrt(mean_squared_error(y, y_pre)))
print('训练集R2',r2_score(y, y_pre))
'''
绘图
'''
# print(y_pre)
# data_s = data
# data_s[:,-1] = y_pre
# data_s = scaler.inverse_transform(data_s)
# y_pre = data_s[:,-1]
# print(y_pre)
plt.figure(0)
p_x = range(len(x))
data_r = data
data_r[:-1,-1] = y
data_r[:-1,:-1] = x
data_r = scaler.inverse_transform(data_r)
p_y_real = data_r[:-1,-1]
data_p = data
data_p[:-1,-1] = y_pre
data_p[:-1,:-1] = x
data_p = scaler.inverse_transform(data_p)
p_y_pre = data_p[:-1,-1]
plt.plot(p_x,p_y_real)
plt.plot(p_x,p_y_pre)
plt.legend(['真实','预测'])
plt.title("训练拟合效果图")
plt.show())
遗传算法结构变量寻优
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error
from sklearn.neural_network import MLPRegressor
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error #MAE
from sklearn.metrics import r2_score#R 2
import random
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
'''
研究当工艺参数为多少时,产品的过滤效率将会达到最高
BP 神经网络模型求解
用遗传算法找最优情况
'''
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
data = data[['接收距离(cm)','热风速度(r/min)','过滤效率(%)']]
print(data.head())
# BP 神经网络进行模拟
mlp = MLPRegressor(hidden_layer_sizes=(100,50),
activation='relu',
solver='adam',
alpha=0.01,
batch_size='auto',
learning_rate='constant',
learning_rate_init=0.05,
power_t=0.5, max_iter=2000, shuffle=True, random_state=5, tol=0.0001)
scaler = StandardScaler()
data = np.array(data)
# print(data)
d = np.array([40,800,100])
data = np.append(data,d).reshape(76,3)
data_ori = data
# print(data)
data = scaler.fit_transform((data))
# print(data)
x = data[:-1,:2]
# print(x)
y = data[:-1,2:]
y = y.reshape(len(y),)
mlp.fit(x, y)
def get_fit(p_l):
# 输入归一化 进行模型训练
t = np.array(p_l).reshape(1, 2)
d1 = data_ori
d1[-2,:-1] = t
d1 = scaler.fit_transform(d1)
t1 = d1[-2,:-1]
test_pre = mlp.predict(t1.reshape(1, 2))
# 输出反归一化 获得数值
d1[-2, -1] = test_pre
d3 = scaler.inverse_transform(d1)
ret = d3[-2,-1]
print('输入',t)
print('输出',ret)
# 返回值作为遗传算法的适应度函数
return ret
# !!! 遗传算法部分
def get_fitness(population):
fitness = []
for pop in population:
fitness.append(get_fit(pop))
return fitness
# 累积概率
def cum_sum(fitness):
temp = fitness[:]
for i in range(len(temp)):
fitness[i] = (sum(temp[:i + 1]))
def selection(population, fitness):
p_fit_value = [] # 归一化后的适应度数据的存储
# 适应度总和
total_fit = sum(fitness)
# 归一化,使概率总和为1
for i in range(len(fitness)):
p_fit_value.append(fitness[i] / total_fit)
# 概率求和排序
cum_sum(p_fit_value) # 累积概率
# print(p_fit_value)
pop_len = len(population) # 种群数量
# 类似搞一个转盘吧下面这个的意思
ms = sorted([random.random() for i in range(pop_len)])
# print(ms)
fitin = 0
newin = 0
newpop = population[:] # 新的种群
# 转轮盘选择法
while newin < pop_len:
# 如果这个概率大于随机出来的那个概率,就选这个
if (ms[newin] < p_fit_value[fitin]):
# print(p_fit_value[fitin])
# print("yes")
newpop[newin] = population[fitin]
newin = newin + 1
else:
# print("no")
fitin = fitin + 1
return newpop
def crossover(population, pc):
pop_len = len(population)
for i in range(pop_len - 1):
if (random.random() < pc):
# 随机选取杂交点,然后交换数组
cpoint = random.randint(0, len(population[0])) # 随机的交换点 根据染色体长度而决定
# print(cpoint)
temp1 = []
temp2 = []
# 基因1的前部分配基因2的后部分
temp1.extend(population[i][0:cpoint]) # extend () 函数用于在列表末尾一次性追加另一个序列中的多个值
temp1.extend(population[i + 1][cpoint:len(population[i])])
temp2.extend(population[i + 1][0:cpoint])
temp2.extend(population[i][cpoint:len(population[i])])
population[i] = temp1[:] # 两两一对进行交叉
population[i + 1] = temp2[:]
return population
def mutation(population, pm):
px = len(population) # 种群数量
py = len(population[0])
for i in range(px):
if (random.random() < pm):
mpoint = random.randint(0, py - 1)
# print(mpoint)
if mpoint == 0:
population[i][mpoint] = np.random.randint(20, 40)
if mpoint == 1:
population[i][mpoint] = np.random.randint(800,1200)
return population
# pop = mutation(pop, MUTATION_RATE)
# print(pop)
def best(population, fitness):
px = len(population)
bestindividual = []
bestfitness = fitness[0]
for i in range(1, px):
# 循环找出最大的适应度,适应度最大的也就是最好的个体
if (fitness[i] >= bestfitness):
bestfitness = fitness[i]
bestindividual = population[i]
return bestindividual, bestfitness
def species_start(POP_size, DNA_size):
pop = []
for i in range(POP_size):
p = []
for j in range(DNA_size):
if j == 0:
p.append(np.random.randint(20, 40))
if j == 1:
p.append(np.random.randint(800,1200))
pop.append(p)
return pop
if __name__ == '__main__':
# 设置参数
DNA_size = 2 # 一天染色体有三个DNA 代表着要优化的三个参数
POP_size = 200 # 种群数量
CROSS_RATE = 0.6 # 交叉率
MUTATION_RATE = 0.01 # 变异率
epoch = POP_size
results = []
fit = []
pop = species_start(POP_size, DNA_size)
print(pop)
for n in range(epoch):
print('GA of cycle : ', n)
print(pop)
fitness = get_fitness(pop)
best_individual, best_fitness = best(pop, fitness)
print('best_fitness',best_fitness)
# print('best_individual',best_individual)
results.append(best_individual)
fit.append(best_fitness)
# 进行选择、交叉、变异操作
pop = selection(pop, fitness)
pop = crossover(pop, CROSS_RATE)
pop = mutation(pop, MUTATION_RATE)
# results.sort()
# print(len(results))
X = []
Y1 = []
Y2 = []
Y_fit = []
for i in range(epoch):
X.append(i)
# print(results[i])
Y1.append(results[i][0])
Y2.append(results[i][1])
Y_fit.append(fit[i])
print("最优结构参数 : ", "接收距离(cm) = ",Y1[-1],' ',"热风速度(r/min) = ",Y2[-1])
print("最优过滤效率 : ",Y_fit[-1])
plt.figure(0)
plt.plot(X, Y1)
plt.plot(X, Y2)
plt.legend(['接收距离(cm)', '热风速度(r/min)']) # 设置折线名称
plt.title('遗传算法-工艺参数')
plt.figure(1)
plt.plot(X, Y_fit)
plt.title('遗传算法-过滤效率')
plt.show()题目4
函数拟合
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn import linear_model
def stdError_func(y_test, y):
return np.sqrt(np.mean((y_test - y) ** 2))
def R2_1_func(y_test, y):
return 1 - ((y_test - y) ** 2).sum() / ((y.mean() - y) ** 2).sum()
def R2_2_func(y_test, y):
y_mean = np.array(y)
y_mean[:] = y.mean()
return 1 - stdError_func(y_test, y) / stdError_func(y_mean, y)
# 先拟合 效率 压缩回弹性率(%)
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
data = data[['接收距离(cm)','热风速度(r/min)','厚度mm']]
print(data.head(5))
x = np.array(data.iloc[:,0:2].values)
# print(x)
y = np.array(data.iloc[:,-1].values)
print(y)
# 多元多项式拟合
poly_reg =PolynomialFeatures(degree=2) #2次多项式
X_ploy =poly_reg.fit_transform(x)
lin_reg_2=linear_model.LinearRegression()
lin_reg_2.fit(X_ploy,y)
predict_y = lin_reg_2.predict(X_ploy)
strError = stdError_func(predict_y, y)
R2_1 = R2_1_func(predict_y, y)
R2_2 = R2_2_func(predict_y, y)
score = lin_reg_2.score(X_ploy, y) ##sklearn中自带的模型评估,与R2_1逻辑相同
print("coefficients", lin_reg_2.coef_)
print("intercept", lin_reg_2.intercept_)
print('degree={}: strError={:.2f}, R2_1={:.2f}, R2_2={:.2f}, clf.score={:.2f}'.format(
2, strError,R2_1,R2_2,score))
'''
intercept -2.9791112261075106
degree=2: strError=0.01, R2_1=1.00, R2_2=0.99, clf.score=1.00
[ 0.00000000e+00 -1.92830817e-02 8.30455891e-03 1.12035413e-03
6.25276844e-06 -3.32529614e-06]
2.7576782919630793
'''
x1 = 40
x2 = 800
i = lin_reg_2.intercept_
c = lin_reg_2.coef_
print(c)
y = i + +c[0]*1+c[1]* x1 +c[2]*x2 +c[3]*x1*x1 + c[4]*x1*x2 + c[5]*x2*x2
print(y)拟合情况绘图
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn import linear_model
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
def stdError_func(y_test, y):
return np.sqrt(np.mean((y_test - y) ** 2))
def R2_1_func(y_test, y):
return 1 - ((y_test - y) ** 2).sum() / ((y.mean() - y) ** 2).sum()
def R2_2_func(y_test, y):
y_mean = np.array(y)
y_mean[:] = y.mean()
return 1 - stdError_func(y_test, y) / stdError_func(y_mean, y)
# 先拟合 效率 压缩回弹性率(%)
# path = 'data_b.xlsx'
# df = pd.ExcelFile(path)
# data = df.parse('data3')
# data = data[['接收距离(cm)', '热风速度(r/min)', '厚度mm']]
# print(data.head(5))
# x = np.array(data.iloc[:, 0:2].values)
# # print(x)
# y = np.array(data.iloc[:, -1].values)
# print(y)
#
# # 多元多项式拟合
# poly_reg = PolynomialFeatures(degree=2) # 2次多项式
# X_ploy = poly_reg.fit_transform(x)
# lin_reg_2 = linear_model.LinearRegression()
# lin_reg_2.fit(X_ploy, y)
# predict_y = lin_reg_2.predict(X_ploy)
# strError = stdError_func(predict_y, y)
# R2_1 = R2_1_func(predict_y, y)
# R2_2 = R2_2_func(predict_y, y)
# score = lin_reg_2.score(X_ploy, y) ##sklearn中自带的模型评估,与R2_1逻辑相同
#
# print("coefficients", lin_reg_2.coef_)
# print("intercept", lin_reg_2.intercept_)
# print('degree={}: strError={:.2f}, R2_1={:.2f}, R2_2={:.2f}, clf.score={:.2f}'.format(
# 2, strError, R2_1, R2_2, score))
'''
intercept -2.9791112261075106
degree=2: strError=0.01, R2_1=1.00, R2_2=0.99, clf.score=1.00
[ 0.00000000e+00 -1.92830817e-02 8.30455891e-03 1.12035413e-03
6.25276844e-06 -3.32529614e-06]
2.7576782919630793
'''
# x1 = 40
# x2 = 800
# print(c)
# y = i + +c[0] * 1 + c[1] * x1 + c[2] * x2 + c[3] * x1 * x1 + c[4] * x1 * x2 + c[5] * x2 * x2
# print(y)
# 绘制拟合图像
# y1 = []
# i = lin_reg_2.intercept_
# c = lin_reg_2.coef_
# for j in x:
# x1 = j[0]
# x2 = j[1]
# ys = i + c[0] * 1 + c[1] * x1 + c[2] * x2 + c[3] * x1 * x1 + c[4] * x1 * x2 + c[5] * x2 * x2
# y1.append(ys)
#
# print(y1)
# y2 = y
# print(y2)
# x_p = range(len(x))
# plt.figure(0)
# plt.plot(x_p,y1)
# plt.plot(x_p,y2)
# plt.legend(['拟合','实际'])
# plt.title('厚度拟合')
# plt.show()
p_l = ['厚度mm','压缩回弹性率(%)','过滤阻力Pa','过滤效率(%)']
plt.figure(0,figsize=(12,10))
for p in range(len(p_l)):
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
data = data[['接收距离(cm)', '热风速度(r/min)', p_l[p]]]
x = np.array(data.iloc[:, 0:2].values)
# print(x)
y = np.array(data.iloc[:, -1].values)
poly_reg = PolynomialFeatures(degree=2) # 2次多项式
X_ploy = poly_reg.fit_transform(x)
lin_reg_2 = linear_model.LinearRegression()
lin_reg_2.fit(X_ploy, y)
i = lin_reg_2.intercept_
c = lin_reg_2.coef_
# 绘图
y1 = []
y2 = y
x_p = range(len(x))
for j in x:
x1 = j[0]
x2 = j[1]
ys = i + c[0] * 1 + c[1] * x1 + c[2] * x2 + c[3] * x1 * x1 + c[4] * x1 * x2 + c[5] * x2 * x2
y1.append(ys)
plt.subplot(2,2,p+1)
plt.plot(x_p,y1)
plt.plot(x_p,y2)
plt.legend(['拟合','实际'])
plt.title(p_l[p]+'拟合情况')
plt.show()
遗传算法 优化目标 (带约束条件)
import numpy as np
import pandas as pd
from sklearn.preprocessing import PolynomialFeatures
from sklearn import linear_model
import random
import matplotlib.pyplot as plt
# 中文乱码解决方法
plt.rcParams['font.family'] = ['Arial Unicode MS','Microsoft YaHei','SimHei','sans-serif']
plt.rcParams['axes.unicode_minus'] = False
# 先拟合 效率 压缩回弹性率(%)
path = 'data_b.xlsx'
df = pd.ExcelFile(path)
data = df.parse('data3')
# 获得对应的拟合方程的输出值
def get_func(d,x1,x2):
x = np.array(d.iloc[:, 0:2].values)
y = np.array(d.iloc[:, -1].values)
poly_reg = PolynomialFeatures(degree=2) # 2次多项式
X_ploy = poly_reg.fit_transform(x)
lin_reg_2 = linear_model.LinearRegression()
lin_reg_2.fit(X_ploy, y)
i = lin_reg_2.intercept_
c = lin_reg_2.coef_
y = i + +c[0] * 1 + c[1] * x1 + c[2] * x2 + c[3] * x1 * x1 + c[4] * x1 * x2 + c[5] * x2 * x2
return y
# d = data[['接收距离(cm)','热风速度(r/min)','厚度mm']]
# x1= 40
# x2 = 800
# y = get__func(d,x1,x2)
# print(y)
# 遗传算法寻优部分
# p-种群的个体,包含两个参数 接收距离 热风速度
def get_fit(p):
x1 = p[0] # 接收距离
x2 = p[1] # 热风速度
d1 = data[['接收距离(cm)','热风速度(r/min)','过滤效率(%)']] # 目标之一
d2 = data[['接收距离(cm)','热风速度(r/min)','过滤阻力Pa']] # 目标之一
y1 = get_func(d1,x1,x2)
y2 = get_func(d2,x1,x2)
z = y1-y2 # 最终目标 效率最大 阻力最小 就是差值最大化
print('fit = ',z)
return z
# p = [40,1000]
# test = get_fit(p)
# print(test)
# !!! 遗传算法部分
def get_fitness(population):
fitness = []
for pop in population:
fitness.append(get_fit(pop))
return fitness
# 淘汰 此处的规则淘汰超过约束条件中厚度和回弹性界限的数值
# 厚度尽量不要超过3mm 压缩回弹性率尽量不要低于85%
# 淘汰方法是将适应度值直接置 0
def eliminate(population,fitness):
new_fit = []
for i in range(len(population)):
p = population[i]
temp = fitness[i]
x1 = p[0] # 接收距离
x2 = p[1] # 热风速度
d1 = data[['接收距离(cm)', '热风速度(r/min)', '厚度mm']] # 约束1
d2 = data[['接收距离(cm)', '热风速度(r/min)', '压缩回弹性率(%)']] # 约束2
y1 = get_func(d1, x1, x2) # 厚度
y2 = get_func(d2, x1, x2) # 回弹性 or temp > 70
if y1 > 3 or y2 < 85:
temp = 0
new_fit.append(temp)
return new_fit
# pop = [[40,800],[40,1000],[35,800]]
# fit = get_fitness(pop)
# print(fit)
# new_f = eliminate(pop,fit)
# print(new_f)
'''
[27.123093253541484, 22.265550584021675, 17.540501096444345]
[0, 0, 17.540501096444345]
淘汰成功
'''
# 累积概率
def cum_sum(fitness):
temp = fitness[:]
for i in range(len(temp)):
fitness[i] = (sum(temp[:i + 1]))
def selection(population, fitness):
p_fit_value = [] # 归一化后的适应度数据的存储
# 适应度总和
total_fit = sum(fitness)
# 归一化,使概率总和为1
for i in range(len(fitness)):
p_fit_value.append(fitness[i] / total_fit)
# 概率求和排序
cum_sum(p_fit_value) # 累积概率
# print(p_fit_value)
pop_len = len(population) # 种群数量
# 类似搞一个转盘吧下面这个的意思
ms = sorted([random.random() for i in range(pop_len)])
# print(ms)
fitin = 0
newin = 0
newpop = population[:] # 新的种群
# 转轮盘选择法
while newin < pop_len:
# 如果这个概率大于随机出来的那个概率,就选这个
if (ms[newin] < p_fit_value[fitin]):
# print(p_fit_value[fitin])
# print("yes")
newpop[newin] = population[fitin]
newin = newin + 1
else:
# print("no")
fitin = fitin + 1
return newpop
def crossover(population, pc):
pop_len = len(population)
for i in range(pop_len - 1):
if (random.random() < pc):
# 随机选取杂交点,然后交换数组
cpoint = random.randint(0, len(population[0])) # 随机的交换点 根据染色体长度而决定
# print(cpoint)
temp1 = []
temp2 = []
# 基因1的前部分配基因2的后部分
temp1.extend(population[i][0:cpoint]) # extend () 函数用于在列表末尾一次性追加另一个序列中的多个值
temp1.extend(population[i + 1][cpoint:len(population[i])])
temp2.extend(population[i + 1][0:cpoint])
temp2.extend(population[i][cpoint:len(population[i])])
population[i] = temp1[:] # 两两一对进行交叉
population[i + 1] = temp2[:]
return population
def mutation(population, pm):
px = len(population) # 种群数量
py = len(population[0])
for i in range(px):
if (random.random() < pm):
mpoint = random.randint(0, py - 1)
# print(mpoint)
if mpoint == 0:
population[i][mpoint] = np.random.randint(20, 100)
if mpoint == 1:
population[i][mpoint] = np.random.randint(800,2000)
return population
# pop = mutation(pop, MUTATION_RATE)
# print(pop)
def best(population, fitness):
px = len(population)
bestindividual = []
bestfitness = fitness[0]
for i in range(1, px):
# 循环找出最大的适应度,适应度最大的也就是最好的个体
if (fitness[i] >= bestfitness):
bestfitness = fitness[i]
bestindividual = population[i]
return bestindividual, bestfitness
def species_start(POP_size, DNA_size):
pop = []
for i in range(POP_size):
p = []
for j in range(DNA_size):
if j == 0:
p.append(np.random.randint(20, 100))
if j == 1:
p.append(np.random.randint(800,2000))
pop.append(p)
return pop
if __name__ == '__main__':
# 设置参数
DNA_size = 2 # 一天染色体有三个DNA 代表着要优化的三个参数
POP_size = 100 # 种群数量
CROSS_RATE = 0.6 # 交叉率
MUTATION_RATE = 0.01 # 变异率
epoch = POP_size * 2
results = []
fit = []
pop = species_start(POP_size, DNA_size)
print(pop)
for n in range(epoch):
print('GA of cycle : ', n)
print(pop)
fitness = get_fitness(pop)
fitness = eliminate(pop, fitness) # 根据约束条件进行淘汰
best_individual, best_fitness = best(pop, fitness)
print('best_fitness',best_fitness)
# print('best_individual',best_individual)
results.append(best_individual)
fit.append(best_fitness)
# 进行选择、交叉、变异操作
pop = selection(pop, fitness)
pop = crossover(pop, CROSS_RATE)
pop = mutation(pop, MUTATION_RATE)
# results.sort()
# print(len(results))
X = []
Y1 = []
Y2 = []
Y_fit = []
print(results)
for i in range(epoch):
X.append(i)
# print(results[i])
try:
Y1.append(results[i][0])
Y2.append(results[i][1])
except:
Y1.append(results[100][0])
Y2.append(results[100][1])
Y_fit.append(fit[i])
#
print("最优结构参数 : ", "接收距离(cm) = ",Y1[-1],' ',"热风速度(r/min) = ",Y2[-1])
# print("最优过滤效率 : ",Y_fit[-1])
plt.figure(0)
plt.plot(X, Y1)
plt.plot(X, Y2)
#
plt.legend(['接收距离(cm)', '热风速度(r/min)']) # 设置折线名称
#
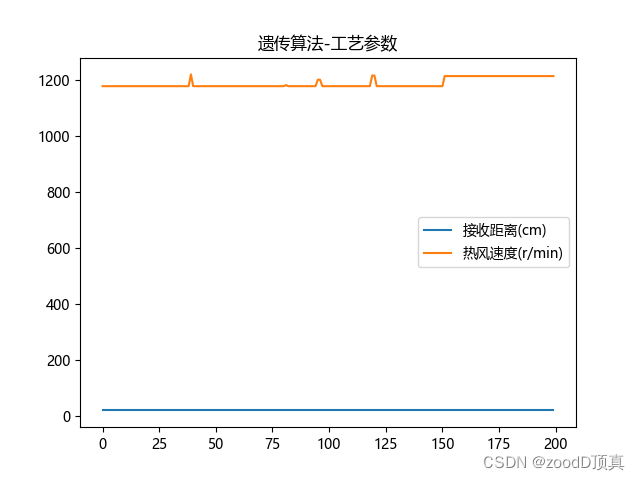
plt.title('遗传算法-工艺参数')
plt.figure(1)
plt.plot(X, Y_fit)
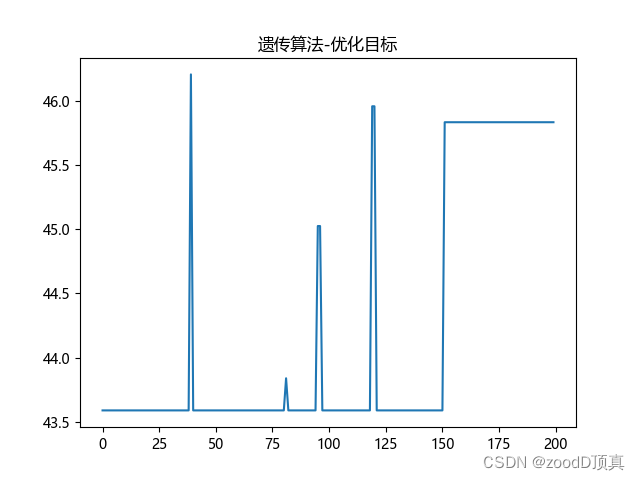
plt.title('遗传算法-优化目标')
#
plt.show()
'''
最优结构参数 : 接收距离(cm) = 21 热风速度(r/min) = 1214
best_fitness 45.83600433090554
'''















 1760
1760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









