






前言
这几天闲得实在无事,想做好多事但是一件也没做哈哈哈,今天抽出时间把前两天看的奇异值分解记录一下。
SVD概述
这个内容我相信很多人都听说过,在很多书中也当做基础知识或者基本内容来讲解,我之前也听过身边的同学讲过,涉及相关的知识也很多,比如主成分分析、本征正交分解、典型相关分析、快速傅里叶变换等等。
首先还是说一些中看不中用的废话吧啦啦啦,奇异值分解(SVD)是计算时代最为重耍的矩阵分解方式之、提供了一种数值稳定的矩阵分解结果,可用于多种应用目的并保证矩阵分解的存在性。我们将用SVD来获得矩阵的低秩近似,并对非方阵求取伪逆来找到方程组Ax=b的解。SVD的另个重要用途是作为主成分分析(PCA)的底层算法,可将高维数据分解为最具统计意义的描述因子,即降维,用少数变盘就能够反映原来众多变量的主要信息。SVD/PCA已广泛应用于理科和工科领域解决各种问题。SVD是一种从数据中提取这些模式的数值鲁棒和有效的方法。
所谓奇异值分解就是把矩阵分解为如下的形式:
X
=
U
Σ
V
T
X=U\Sigma V^{\mathrm{T}}
X=UΣVT,例如
[
x
1
y
1
x
2
y
2
x
3
y
3
x
4
y
4
]
=
[
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
−
]
[
a
0
0
b
0
0
0
0
]
[
−
−
−
−
]
\begin{bmatrix}x_1&y_1\\x_2&y_2\\x_3&y_3\\x_4&y_4\end{bmatrix}=\begin{bmatrix}-&-&-&-\\-&-&-&-\\-&-&-&-\\-&-&-&-\end{bmatrix}\begin{bmatrix}a&0\\0&b\\0&0\\0&0\end{bmatrix}\begin{bmatrix}-&-\\-&-\end{bmatrix}
x1x2x3x4y1y2y3y4
=
−−−−−−−−−−−−−−−−
a0000b00
[−−−−]
其中
U
U
U和
V
V
V都是正交矩阵或者酉矩阵,
Σ
\Sigma
Σ为广义对角矩阵,包括
[
Σ
^
0
]
[
Σ
^
0
]
\quad\begin{bmatrix}\hat{\Sigma}\\0\end{bmatrix}\quad\begin{bmatrix}\hat{\Sigma}\ \ \ 0\end{bmatrix}
[Σ^0][Σ^ 0]两种,其中
Σ
^
\hat{\Sigma}
Σ^是对角矩阵,
M
M
M是
n
×
m
n×m
n×m,当
n
≥
m
n \geq m
n≥m时,
Σ
\Sigma
Σ的对角线上最多有
m
m
m个非零元素,则为第一种情况,反之是第二种,当然如果
M
M
M是方阵则
Σ
\Sigma
Σ就是对角矩阵。SVD可以分为全SVD(full SVD)和经济SVD(economy SCD),其中经济SVD可以表示为:
X
=
U
Σ
V
∗
=
[
U
^
U
^
⊥
]
[
Σ
^
0
]
V
∗
=
U
^
Σ
^
V
∗
\mathbf{X}=\mathbf{U}\mathbf{\Sigma}\mathbf{V}^{*}=\left[\mathbf{\hat{U}}\quad\mathbf{\hat{U}}^{\perp}\right]\left[\begin{matrix}{\hat{\Sigma}}\\{\mathbf{0}}\\\end{matrix}\right]\mathbf{V}^{*}=\hat{\mathbf{U}}\hat{\mathbf{\Sigma}}\mathbf{V}^{*}
X=UΣV∗=[U^U^⊥][Σ^0]V∗=U^Σ^V∗,这里的
Σ
\Sigma
Σ是第一种,
M
M
M的行数大于列数,示意图如下:
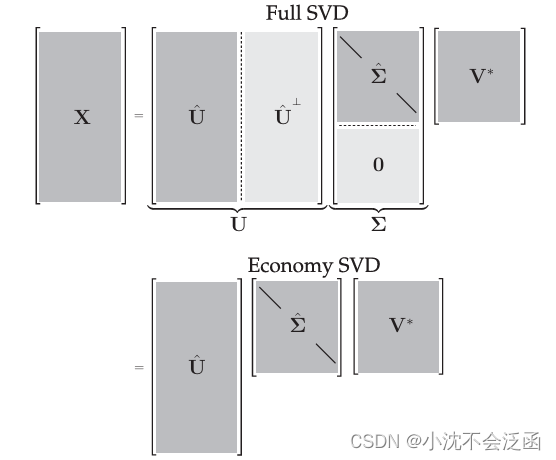
经济SVD保证了
Σ
\Sigma
Σ是对角元素非零的对角矩阵,减少了运算中需要记录和储存的数据,或许是“经济”的内涵吧。
U
U
U的列称为
X
X
X的左奇异向量,
V
V
V的列称为
X
X
X的右奇异向量,
Σ
^
∈
C
m
×
m
\hat{\Sigma}\in\mathbb{C}^{m\times m}
Σ^∈Cm×m的对角线元素被称为奇异值,它们由大到小排列,
X
X
X的秩等于非零奇异值的个数。
SVD计算与几何意义
V
V
V是
X
T
X
X^{\mathrm{T}}X
XTX的特征向量;
U
U
U是
X
X
T
XX^{\mathrm{T}}
XXT的特征向量:
Σ
\Sigma
Σ中的奇异值是
X
T
X
X^{\mathrm{T}}X
XTX和
X
X
T
XX^{\mathrm{T}}
XXT的特征值的算数平方根,二者的特征值相同。若将X视为一个线性变换,则酉矩阵
U
、
V
U、V
U、V可以视为旋转变换,准对角矩阵
Σ
\Sigma
Σ是伸缩变换,具体动画讲解可以看一下b站的视频:学长小课堂:什么是奇异值分解SVD–SVD如何分解时空矩阵对奇异值分解讲解的很清晰,后边的模态分解也很有意思,最重要的是动画制作不错。
书中也举了一个例子,简单来说明一下吧:由
S
n
−
1
=
Δ
{
x
∣
∥
x
∥
2
=
1
}
⊂
R
n
S^{n-1}\stackrel{\Delta}{=}\{\mathbf{x}\mid\parallel\mathbf{x}\parallel_{2}=1\}\subset\mathbb{R}^{n}
Sn−1=Δ{x∣∥x∥2=1}⊂Rn确定的超球体通过
X
X
X影射到由
{
y
∣
y
=
X
x
,
x
∈
S
n
−
1
}
⊂
R
m
\{\mathbf{y}\mid\mathbf{y}=\mathbf{X}\mathbf{x},\mathbf{x}\in S^{n-1}\}\subset\mathbb{R}^{m}
{y∣y=Xx,x∈Sn−1}⊂Rm确定的椭球体,下图展示出了
R
3
R^3
R3中的一个球体和一个具有三个非零奇异值的映射
X
X
X。因为通过
X
X
X的映射(即矩阵乘法)是线性的,所以,知道了如何映射单位球体也就决定了所有其他向量是如何映射的。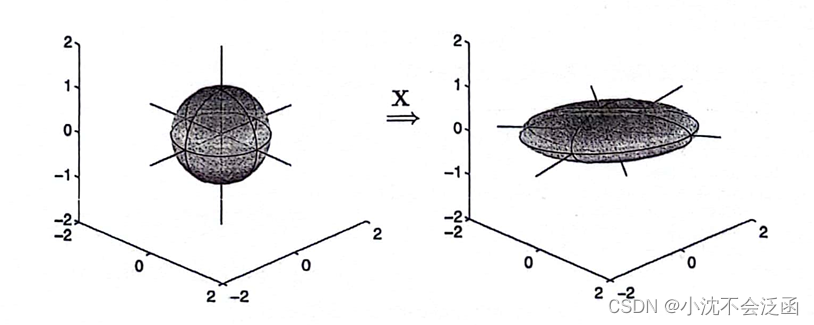
具体来说,利用三个旋转矩阵
R
x
,
R
y
,
R
z
R_{x},R_{y},R_{z}
Rx,Ry,Rz来构造
X
X
X,第四个矩阵用于拉伸和缩放主轴:
X
=
[
cos
(
θ
3
)
−
sin
(
θ
3
)
0
sin
(
θ
3
)
cos
(
θ
3
)
0
0
0
1
]
⏟
R
y
[
cos
(
θ
2
)
0
sin
(
θ
2
)
0
1
0
−
sin
(
θ
2
)
0
cos
(
θ
2
)
]
⏟
R
y
×
[
1
0
0
0
cos
(
θ
1
)
−
sin
(
θ
1
)
0
sin
(
θ
1
)
cos
(
θ
1
)
]
⏟
R
x
[
σ
1
0
0
0
σ
2
0
0
0
σ
3
]
\begin{gathered}\mathbf{X}=\underbrace{\begin{bmatrix}\cos(\theta_3)&-\sin(\theta_3)&0\\\sin(\theta_3)&\cos(\theta_3)&0\\0&0&1\end{bmatrix}}_{\mathbf{R}_{\mathbf{y}}}\underbrace{\begin{bmatrix}\cos(\theta_2)&0&\sin(\theta_2)\\0&1&0\\-\sin(\theta_2)&0&\cos(\theta_2)\end{bmatrix}}_{\mathbf{R}_{\mathbf{y}}}\\\times\underbrace{\begin{bmatrix}1&0&0\\0&\cos(\theta_1)&-\sin(\theta_1)\\0&\sin(\theta_1)&\cos(\theta_1)\end{bmatrix}}_{\mathbf{R}_{\mathbf{x}}}\begin{bmatrix}\sigma_1&0&0\\0&\sigma_2&0\\0&0&\sigma_3\end{bmatrix}\end{gathered}
X=Ry
cos(θ3)sin(θ3)0−sin(θ3)cos(θ3)0001
Ry
cos(θ2)0−sin(θ2)010sin(θ2)0cos(θ2)
×Rx
1000cos(θ1)sin(θ1)0−sin(θ1)cos(θ1)
σ1000σ2000σ3
在本例中,
θ
1
=
π
/
15
,
θ
2
=
−
π
/
9
,
θ
3
=
−
π
/
20
,
σ
1
=
3
,
σ
2
=
1
,
σ
3
=
0.5
\theta_{1}=\pi/15,\theta_{2}=-\pi/9,\theta_{3}=-\pi/20,\sigma_{1}=3,\sigma_{2}=1,\sigma_{3}=0.5
θ1=π/15,θ2=−π/9,θ3=−π/20,σ1=3,σ2=1,σ3=0.5。这些旋转矩阵并不能交换,所以旋转的顺序很重要。如果其中一个奇异值为零,则删除一个维度,椭球体将塌陷到一个低维子空间上。
R
x
,
R
y
,
R
z
R_{x},R_{y},R_{z}
Rx,Ry,Rz是
X
X
X在SVD 中的酉矩阵
U
U
U。矩阵
V
V
V是单位阵。
截断SVD
Schmidt(Gram-Schmidt 正交化方法提出者之一)将 SVD 推广到函数空间,并建立了一个近似定理,将截断 SVD作为基础矩阵
X
X
X的最优低秩近似。Schmidt 的近似定理被Eckart 和 Young 重新发现 ,有时也被称为 Eckart -Young 定理。
定理(Eckart-Young):最小二乘意义下
X
X
X的最优秩
r
r
r近似,由秩
r
r
rSVD 截断给出:
argmin
X
~
,
s
.
t
.
r
a
n
k
(
X
~
)
=
r
∥
X
−
X
~
∥
F
=
U
~
Σ
~
V
~
∗
\underset{\tilde{\mathbf{X}},s.t.\mathrm{rank}(\tilde{\mathbf{X}})=r}{\operatorname*{argmin}}\|\mathbf{X}-\tilde{\mathbf{X}}\|_{F}=\tilde{\mathbf{U}}\tilde{\mathbf{\Sigma}}\tilde{\mathbf{V}}^{*}
X~,s.t.rank(X~)=rargmin∥X−X~∥F=U~Σ~V~∗其中,
U
~
\tilde{\mathbf{U}}
U~和
V
~
\tilde{\mathbf{V}}
V~可分别表示
U
U
U和
V
V
V中前
r
r
r个先导列,包含中的先导
r
×
r
r×r
r×r维子块。
F
F
F范数表示 Frobenius 范数,
∥
X
∥
F
=
∑
i
=
1
n
∑
j
=
1
m
∣
X
i
j
∣
2
\|\mathbf{X}\|_{F}=\sqrt{\sum_{i=1}^{n}\sum_{j=1}^{m}|X_{ij}|^{2}}
∥X∥F=∑i=1n∑j=1m∣Xij∣2。
在这里,我们建立了一种表示形式,即截断SVD基(以及得到的近似矩阵)用
X
~
=
U
~
Σ
~
V
~
∗
\tilde{\mathbf{X}}=\tilde{\mathbf{U}}\tilde{\mathbf{\Sigma}}\tilde{\mathbf{V}}^{*}
X~=U~Σ~V~∗来表示。由于
Σ
\Sigma
Σ是对角矩阵,秩
r
r
rSVD 近似则是由
r
r
r个不同的秩1矩阵的和给出:
X
~
=
∑
k
=
1
r
σ
k
u
k
v
k
∗
=
σ
1
u
1
v
1
∗
+
σ
2
u
2
v
2
∗
+
⋯
+
σ
r
u
r
v
r
∗
\tilde{\mathbf{X}}=\sum_{k=1}^{r}\sigma_{k}\mathbf{u}_{k}\mathbf{v}_{k}^{*}=\sigma_{1}\mathbf{u}_{1}\mathbf{v}_{1}^{*}+\sigma_{2}\mathbf{u}_{2}\mathbf{v}_{2}^{*}+\cdots+\sigma_{r}\mathbf{u}_{r}\mathbf{v}_{r}^{*}
X~=k=1∑rσkukvk∗=σ1u1v1∗+σ2u2v2∗+⋯+σrurvr∗这就是所谓的并向量求和。对于给定的秩
r
r
r,在
l
2
l_2
l2意义下,对于
X
X
X没有比截断 SVD 近似更好的近似。因此,高维数据可由矩阵
U
~
\tilde{\mathbf{U}}
U~和
V
~
\tilde{\mathbf{V}}
V~的列给出的几个主导模式很好地描述。
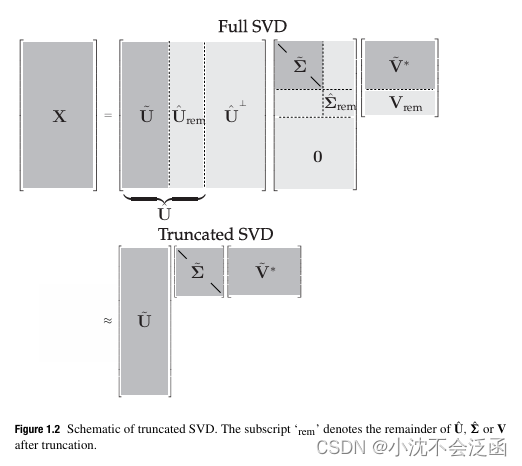
决定保留多少奇异值,即在何处开始截断,是使用SVD 时最重要和最有争议的决策之一。这其中涉及许多因素,包括对系统期望的秩的具体要求、噪声的大小以及奇异值的分布等。通常将 SVD在秩
r
r
r处截断,以捕获原始数据中预先确定的方差或能量的数量,例如 90% 或 99% 截断。虽然很粗糙,但是这种技术是常用的。截断可被视为一种作用于奇异值上的硬阈值,大于阈值的值被保存下来,而余下的奇异值被截断。这里的最优硬阈值还有更为复杂的理论,这里便不再阐述。
PCA
这一部分也是看了B站上的视频,作者和上边推荐的一样,PCA的目标就是寻求一个坐标系在数据保留更少维度的同时信息的损失最小,目标:只保留一个轴的时候(二维降到一维),信息保留最多,怎么样最好:找到数据分布最分散的方向(方差最大),作为主成分(坐标轴)。
首先:去中心化(把坐标原点放在数据中心),然后:找坐标系(找到方差最大的方向),问题是:怎么找到方差最大的方向?我们需要保存原始的矩阵信息、新坐标系的原点、角度、新坐标点;
我们要求方差最大的方向就是求旋转的角度也就是
R
R
R
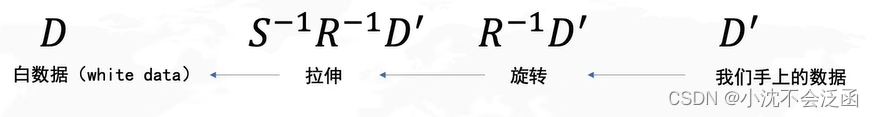
协方差矩阵的特征向量就是
R
R
R,这话可能有些不太恰当,更直白一点就是
R
R
R由特征向量作为列向量构成,两个变量
x
,
y
x,y
x,y的协方差是
c
o
v
(
x
,
y
)
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
y
i
−
y
ˉ
)
n
−
1
cov(x,y)=\frac{\sum_{i=1}^{n}(x_{i}-\bar{x})(y_{i}-\bar{y})}{n-1}
cov(x,y)=n−1∑i=1n(xi−xˉ)(yi−yˉ),这里中心化以后
x
ˉ
\bar{x}
xˉ和
y
ˉ
\bar{y}
yˉ都为0,协方差矩阵(对称矩阵)为
C
=
[
c
o
v
(
x
,
x
)
c
o
v
(
x
,
y
)
c
o
v
(
x
,
y
)
c
o
v
(
y
,
y
)
]
C=\begin{bmatrix}cov(x,x)&cov(x,y)\\cov(x,y)&cov(y,y)\end{bmatrix}
C=[cov(x,x)cov(x,y)cov(x,y)cov(y,y)]代入以后为:
C
=
[
∑
i
=
1
n
x
i
2
n
−
1
∑
i
=
1
n
x
i
y
i
n
−
1
∑
i
=
1
n
x
i
y
i
n
−
1
∑
i
=
1
n
y
i
2
n
−
1
]
=
[
x
1
x
2
x
3
x
4
y
1
y
2
y
3
y
4
]
[
x
1
y
1
x
2
y
2
x
3
y
3
x
4
y
4
]
=
1
n
−
1
D
D
T
\begin{aligned} &\text{C} =\begin{bmatrix}\frac{\sum_{i=1}^{n}{x_{i}}^{2}}{n-1}&\frac{\sum_{i=1}^{n}{x_{i}y_{i}}}{n-1}\\\frac{\sum_{i=1}^{n}{x_{i}y_{i}}}{n-1}&\frac{\sum_{i=1}^{n}{y_{i}}^{2}}{n-1}\end{bmatrix}=\begin{bmatrix}x_{1}&x_{2}&x_{3}&x_{4}\\y_{1}&y_{2}&y_{3}&y_{4}\end{bmatrix}\begin{bmatrix}x_{1}&y_{1}\\x_{2}&y_{2}\\x_{3}&y_{3}\\x_{4}&y_{4}\end{bmatrix} = \frac{1}{n-1}DD^{\mathrm{T}}\quad \end{aligned}
C=[n−1∑i=1nxi2n−1∑i=1nxiyin−1∑i=1nxiyin−1∑i=1nyi2]=[x1y1x2y2x3y3x4y4]
x1x2x3x4y1y2y3y4
=n−11DDT其中
D
D
D是服从正态分布的白数据,通过拉伸旋转变换得到我们手上的
D
′
D^{\prime}
D′,接下来的推导过程就看这个图吧,识别不动了哈哈哈:
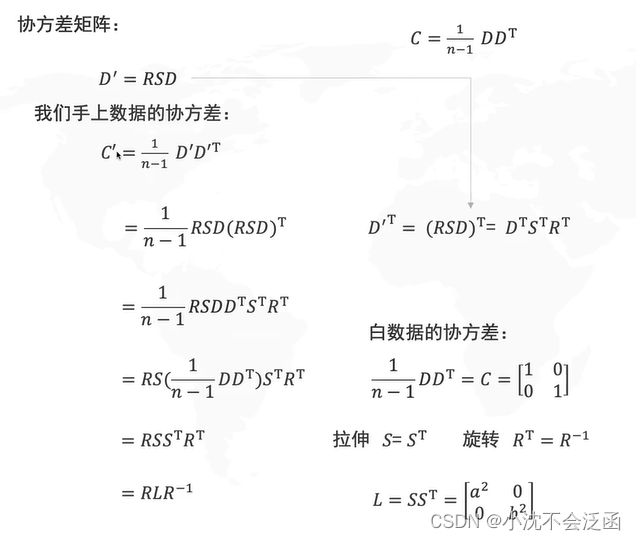
所得的
C
′
=
R
L
R
−
1
C^{\prime}=RLR^{-1}
C′=RLR−1说明
R
R
R确实是协方差矩阵的特征向量,
C
C
C:在原坐标系下的协方差,
L
L
L:在
R
R
R这组基下(新坐标系)的协方差;大致步骤概括如下:
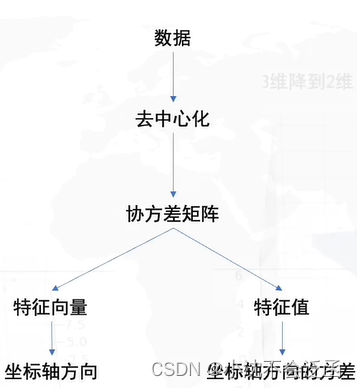
PCA与SVD还是有一定联系的,PCA中要求的
R
R
R矩阵实际上就是SVD分解中的
V
V
V,这句话可能所有写SVD和PCA内容的都有提到,但是很少做出了理论说明,可能没人注意到这个问题,其实我们可以看到上边的推导过程中
C
′
=
1
n
−
1
D
′
D
′
T
=
R
L
R
−
1
C^{\prime}=\frac{1}{n-1}D^{\prime}D^{\prime\mathrm{T}}=RLR^{-1}
C′=n−11D′D′T=RLR−1说明这个
R
R
R是
D
′
D
′
T
D^{\prime}D^{\prime\mathrm{T}}
D′D′T的特征向量,那么由前边的SVD
X
X
T
XX^{\mathrm{T}}
XXT对应的应该是
U
U
U,而不是
V
V
V,这个问题我在李航老师的统计学习方法中找到了答案,在第十六章326页开始:
下面也有更为详细的主成分算法:
好了这篇文章就说到这吧,文中有很多地方还是缺少理论证明,也借鉴了很多专业老师的内容来完成,对此表达崇高的谢意,有不合适的地方也希望批评指正,期待下一篇博客,耶!!!
















 771
771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











