









目录
前言
网络爬虫是一种能够自动浏览、检索和提取网络信息的技术。在Python编程语言中,有许多优秀的库可以用于构建网络爬虫,其中最受欢迎和广泛使用的之一就是 requests。requests 是一个简洁、功能强大的第三方库,为开发人员提供了在网络上进行 HTTP 请求的便捷方式。本文将带您深入探索 requests 库,探讨其背后的原理和使用方法,以及如何通过它来获取、处理和管理网络数据。我们将从基础知识入手,逐步引导您了解如何利用 requests 发起请求、处理响应、处理异常情况。
一、Requests的基本功能
requests 提供了一种便捷的方式来与Web服务器进行通信,从而实现数据的获取、上传、交互等操作。它的直观接口和丰富的功能使得编写和维护HTTP请求变得更加容易和高效。无论您是在构建网络爬虫、与API交互,还是进行数据采集和处理,requests 都是一个强大的工具。
import requests
# 1.准备请求地址
url = 'https://cd.zu.ke.com/zufang'
# 2.发送请求
# requests.get(请求地址) - 对指定地址发送请求,得到服务器返回的数据(响应)
response = requests.get(url)
# 3.获取请求结果
result = response.text
print(result)二、Requests详解
2.1 具体步骤
1)准备请求地址
代码如下(示例):
url = 'https://www.chinanews.com/'2)发送请求
代码如下(示例):
response = requests.get(url)3)获取响应内容
a.获取响应头(响应头中包含了返回的数据的基本信息)
print(response.headers)b.获取状态码
print(response.status_code)
if response.status_code == 200:
pass
else:
pass4)修改编码方式
如果请求结果乱码的时候就修改,要注意的是乱码的时候修改编码方式,必须在获取请求结果之前
response.encoding = 'UTF-8'5)获取请求结果
a. 响应对象.text - 返回字符串类型的请求结果(请求地址是网页地址)
b. 响应对象.content - 返回二进制类型(bytes)的请求结果(请求地址是文件地址-图片,视频,音频)
c. 响应对象.json() - 返回值根据json数据格式的不同可能不一样(请求地址是json数据接口)
print(response.text)2.2 文件下载
1)文件下载的重要性
requests 中的文件下载功能对于从网络上获取各种类型的文件、实现自动化任务、数据处理和资源管理等方面都具有重要性。其简单而强大的接口使得文件下载变得高效、可靠,并可以被集成到各种应用场景中,从而为开发者和数据专业人士带来更多便利。
2)具体步骤
import requests
# 1.准备下载地址
url = 'https://img2.baidu.com/it/u=267632856,3740526320&fm=253&fmt=auto&app=120&f=JPEG?w=1280&h=800'
# 2.发送请求
response = requests.get(url)
# 3.获取请求结果
result = response.content
# 4.讲图片数据写入到文件中
with open('files\艾斯.jpeg', 'wb') as f:
f.write(result)三、浏览器伪装
3.1 介绍
在使用 requests 发起HTTP请求时,您可以通过设置请求头(headers)来模拟不同类型的浏览器,从而实现浏览器伪装。这在许多情况下是有用的,比如访问需要用户代理信息的网站,或者在爬虫中模拟用户访问。
3.2 详细步骤
import requests
# 定义浏览器代理信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.1234.56 Safari/537.36'
}
# 发起请求并添加请求头
url = 'https://example.com'
response = requests.get(url, headers=headers)
# 处理响应
if response.status_code == 200:
# 打印响应内容
print(response.text)
else:
print('请求失败')
3.3 浏览器代理信息获取方法
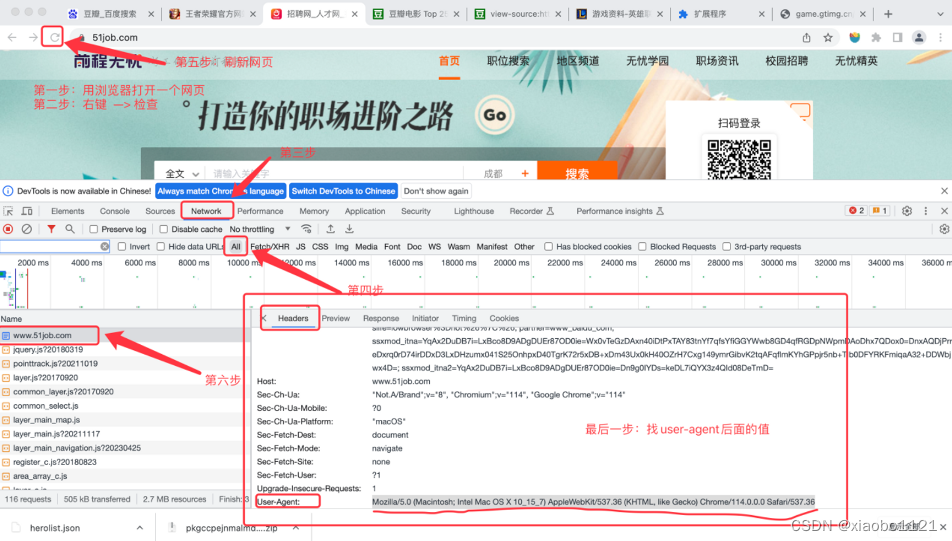

总结
在当今数字时代,requests 作为一个强大而灵活的Python库,为我们提供了便捷的方式来与网络进行交互。通过深入了解并掌握 requests 的基本功能,我们可以在数据获取、网页抓取、API交互等任务中获得更多自主权和灵活性。
文章前文探讨了 requests 的基本功能以及如何通过设置请求头来实现浏览器伪装,以便在发起HTTP请求时模拟不同类型的浏览器。这种技术不仅可以用于访问需要用户代理信息的网站,还可以在爬虫任务中模拟用户的行为,更好地应对反爬措施。
然而,在使用 requests 进行浏览器伪装时,我们也需要注意一些原则。合理合法地进行浏览器伪装,遵守网站的使用条款和规定,避免过度频繁的请求,从而保持良好的网络行为。
在信息获取和数据处理的领域中,requests 是一个不可或缺的工具,能够为我们的工作和项目带来便利和效率。通过继续学习和探索 requests,我们可以更好地利用网络资源,开展更多有益的活动,以应对日益复杂和多样化的数字化挑战。
让我们继续学习和实践,不断挖掘 requests 的更多功能和用途,以在数字世界中取得更大的成功和成就。无论是开发应用、进行数据分析,还是满足其他需求,requests 都将伴随着我们,成为我们在网络探索中的得力助手。















 1421
1421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









