







import pprint
import requests
import csv
import re
url='http://meishi.meituan.com/i/api/channel/deal/list'
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62',
'Referer': 'http://meishi.meituan.com/i/?ci=790&stid_b=1&cevent=imt%2Fhomepage%2Fcategory1%2F1',
'Cookie': '填自己的'}
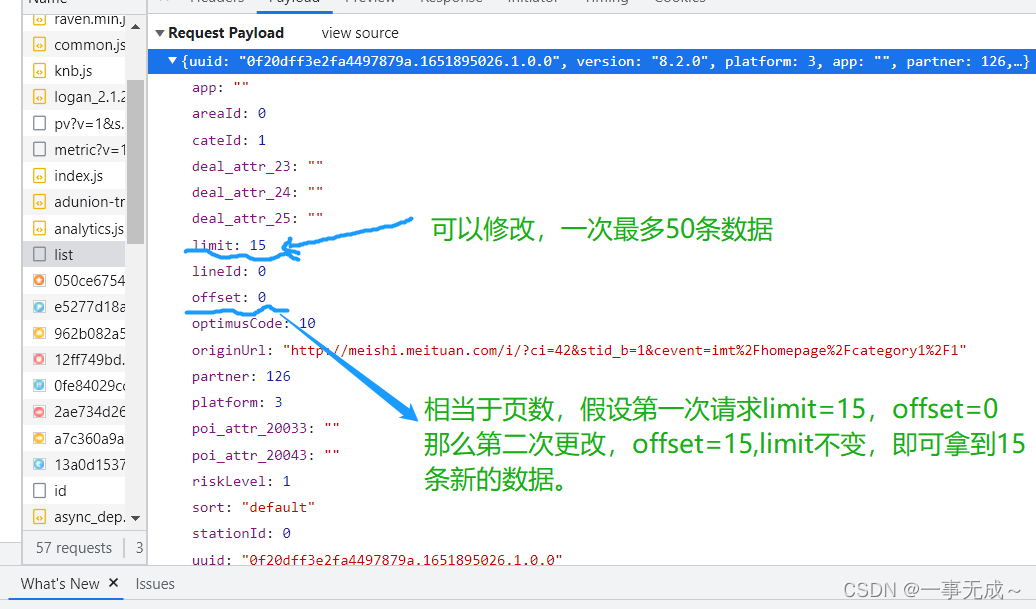
data={
'app': '""',
'areaId': '0',
'cateId': '1',
'deal_attr_23': '""',
'deal_attr_24': '""',
'deal_attr_25': '""',
'limit': '10',
'lineId': '0',
'offset': '0',
'optimusCode': '10',
'originUrl': '"http://meishi.meituan.com/i/?ci=790&stid_b=1&cevent=imt%2Fhomepage%2Fcategory1%2F1"',
'partner': '126',
'platform': '3',
'poi_attr_20033': '""',
'poi_attr_20043': '""',
'riskLevel': '1',
'sort': '"default"',
'stationId': '0',
'uuid': '"0f20dff3e2fa4497879a.1651895026.1.0.0"',
'version': '"8.2.0"',
}
response=requests.post(url=url,data=data,headers=headers).json()
dd=response['data']['poiList']['poiInfos']
f=open('./data.csv','a',encoding='utf-8',newline='')#a 是追加保存
csv_write=csv.DictWriter(f, fieldnames=[
'店铺名',
'饮食类型',
'最低消费',
'评分',
'商圈',
'商家地址',
'商家电话',
'商家网址',
])
csv_write.writeheader()
for i in dd:
dit={
'店铺名':i['name'],
'饮食类型':i['cateName'],
'最低消费':i['avgPrice'],
'评分':i['avgScore'],
'商圈': i['areaName'],
'商家网址':'https://meishi.meituan.com/i/poi/'+i['poiid']
}
header = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36 Edg/98.0.1108.62',
'Cookie':'填自己的',
'Referer':'http://meishi.meituan.com/i/?ci=790&stid_b=1&cevent=imt%2Fhomepage%2Fcategory1%2F1',
}
hh = requests.get(url=dit['商家网址'],headers=header).text
obj = re.compile(r'addr":"(?P<addr>.*?)","phone":"(?P<phone>.*?)"')
result = obj.finditer(hh)
for item in result:
addr = item.group('addr')
phone = item.group('phone')
dit['商家地址']=addr
dit['商家电话']=phone
print(dit)
csv_write.writerow(dit)测试结果:

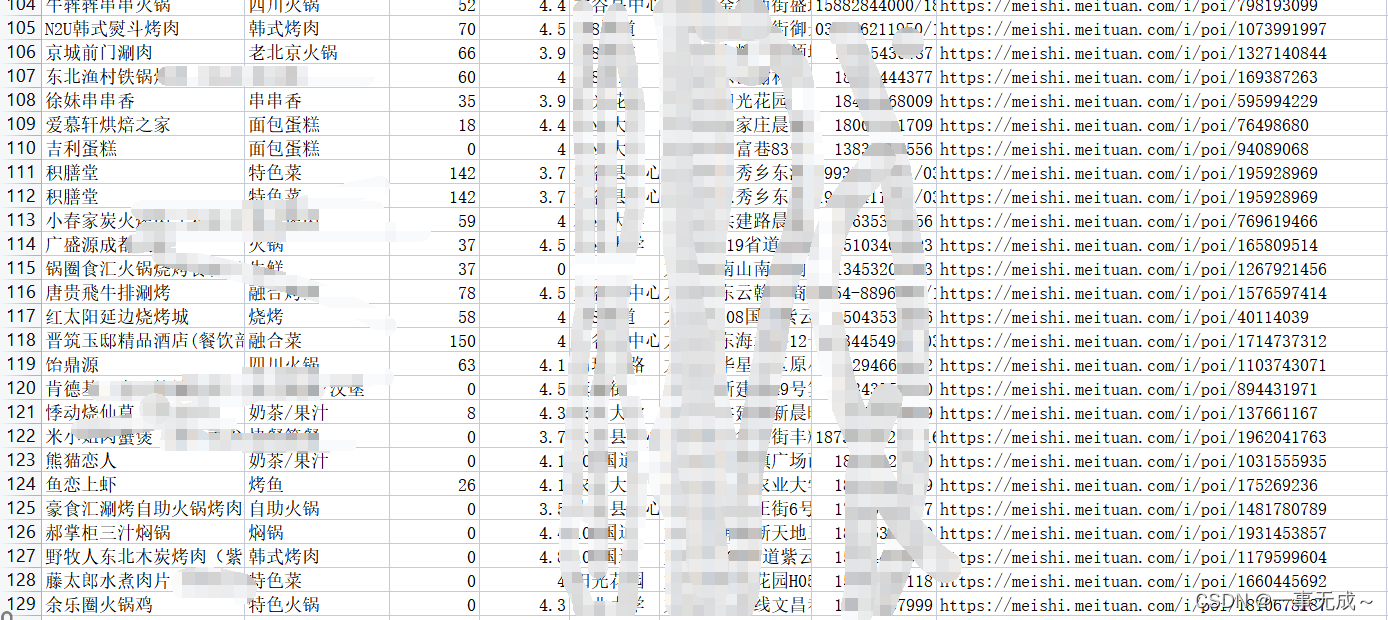
















 1362
1362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











