






一.此文章题目(假设前提)
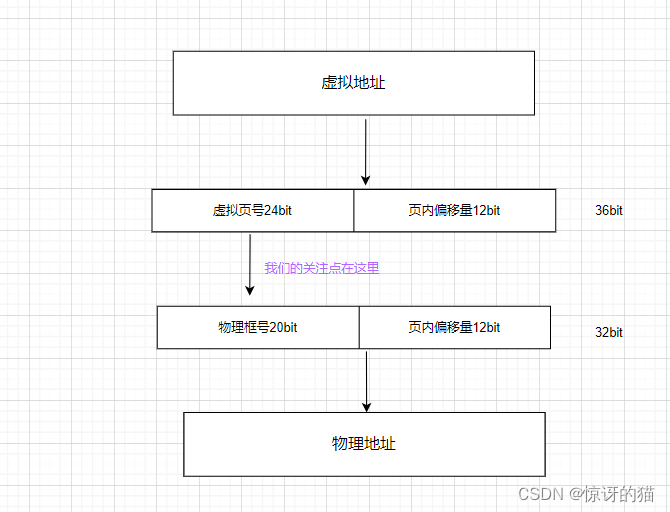
假设:某36位系统,按字节编制,每个⻚⾯⼤⼩为 4KB。则⻚内偏移量占 12 bit,虚拟⻚号24bit。 物理地址空间⼤⼩为 4GB,因此物理地址共32bit,前 20bit 表示物理⻚框号。
1.这里解释一下按字节编址,它是一种计算机内存的编制方式。
在按字节编址的系统中,为每8个字节编一个地址。
而按字编址是另一种内存编址方式,在按字编址的系统中,为一个字的存储空间编一个地址,即一个地址单元对应于一个字(通常是32位或64位)。这意味着每个地址单元会包含多个字节。
2.接下来我们文章的重点是,从虚拟地址到物理地址的转化,然后再利用这个物理地址去访问主存。
二.从虚拟地址到物理地址的转化
1.总述
首先在主存中每个进程都有一张页表,该页表记录了虚拟页号和物理页框号的映射关系。
虚拟地址在逻辑上分为虚拟页号+页内偏移量
1)我们先用虚拟页号查快表,如果快表命中,则直接得到页号
若快表未命中,用虚拟页号查慢表,总而言之,即欲根据虚拟页号获得物理⻚框号
2)将页框号拼接上页内偏移量(还是那12bit)即可得到完整的物理地址
2.查快表过程
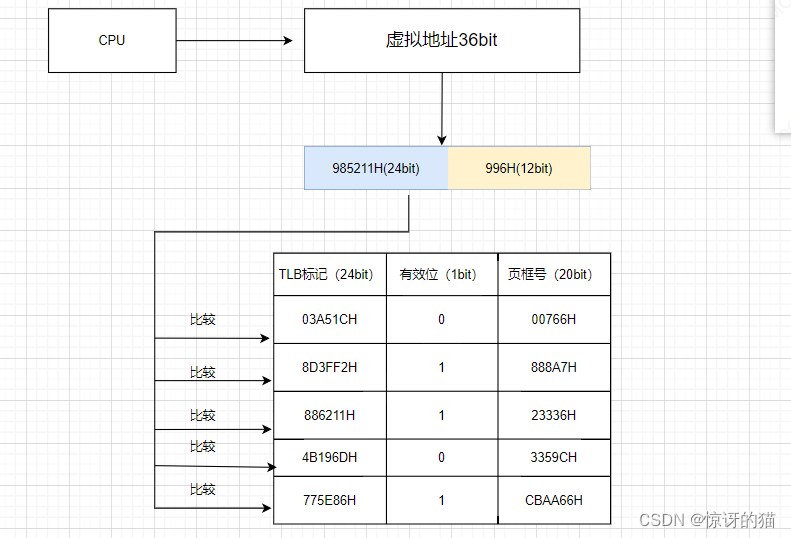
首先根据虚拟页号查快表,这里以全相联映射的方式为例,则我们需要遍历并比较标记(用虚拟页号和TLB标记比较),才能判断所需的页表项是否在快表中。
若快表命中,则直接得到页框号。
若快表未命中,则用虚拟页号查慢表。
可以看到在下面的例子中,在快表中并没有存在TLB标记为985211H的记录,这意味着快表未命中,我们需要到慢表中去查看是否有对应的(虚拟块号,物理页框号)映射的记录。
3.查慢表过程
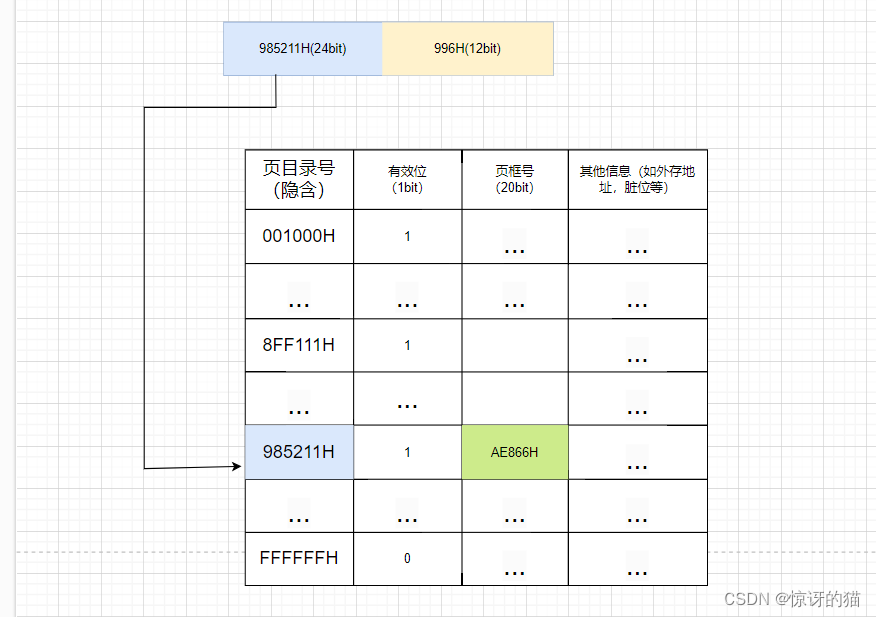
1)我们通常会在系统中设置一个页表寄存器(PTR),存放页表在内存中的起始地址F 和页表长度M。 进程未执行时,页表的始址和页表长度放在进程控制块(PCB)中,当进程被调度时,操作系统内核会把它们放到页表寄存器中。
2)因为每个页表项的长度是相同的,所以页号是“隐含”的,即如果你已经知道了页表在内存中存放的起始地址是X,每个页表项的大小又是相同的,那你自然能够知道其他的页表项的地址,因此页号可以隐含。(各页表项会按顺序连续地存放在内存中)
3)如下图所示,我们先在页表中查看有无页号为985211H的页号,发现存在,则定位到相应的记录,取出其对应的页框号为A3866H
4.查二级页表过程
1)二级页表存在的意义
-
在操作系统中,每个进程都有自己的虚拟地址空间,这意味着每个进程可能需要管理大量的页表项,以将虚拟地址映射到物理内存地址。
-
单级页表(即一级页表)的问题在于,它需要连续存放,因此当页表很大时,需要占用很多个连续的页框。这会导致内存浪费。
-
此外,没有必要让整个页表常驻内存,因为进程在一段时间内可能只需要访问某几个特定的页面。
综上,我们可以使用多级页表来优化页表结构。
2)二级页表介绍
a.二级页表是一种多级页表结构,将长长的页表进行分组,使每个内存块刚好可以放入一个分组,再将各组离散地放到各个内存块中。
b.逻辑地址结构为(一级页号,二级页号,页内偏移量)这里我们可以根据逻辑地址位数,页面大小,页表项大小来确定这几part所占的位数
d.地址转化过程:从PCB中读出页目录表始址,根据一级页号查页目录表,找到下一级页表在内存中的存放位置,再根据二级页号查二级页表表,找到最终想访问的内存块号,最后结合页内偏移量得到想要的物理地址。
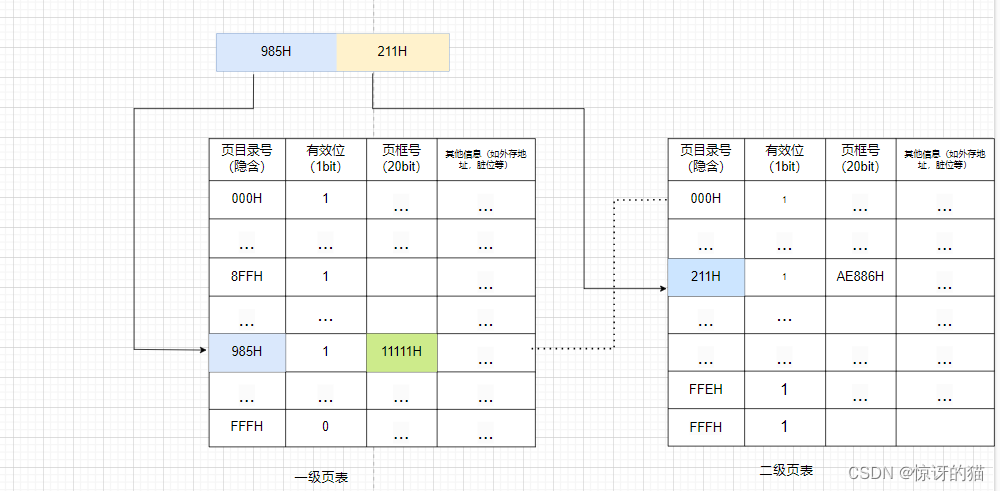
这里我要重点重申: 1)采用二级页表结构的一级页号,二级页号是虚拟页号的细分
2)查询一级页表得到的是二级页表的其实地址(重点)
查询二级页表是根据二级页号去匹配的(重点)
三.用物理地址访问主存
1.总述
首先根据物理地址访问cache,若cache命中,则直接得到目标数据。
若Cache未命中,则⽤物理地址访问主存。
2.访问Cache过程
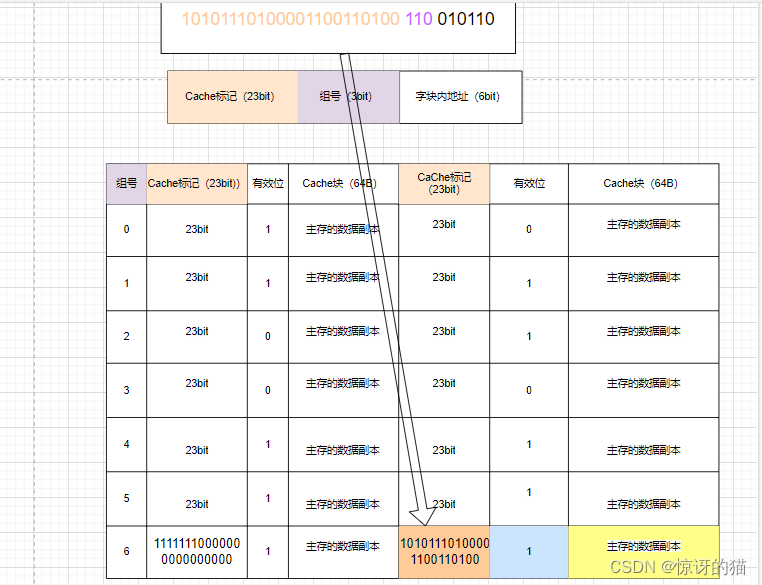
我们以访问主存物理地址为 10101110100001100110100 110 010110 的数据的访问过程为例。这里以2路组相联的映射方式访问Cache为例的方式为例。
1)在2路组相联映射中,Cache被分成多个组,每个组内有2块(或行)。这意味着每个组内有两个Cache行可以存放数据,主存中的每个块可以映射到Cache的某个组中的任意一个行。
2)假设CaChe块的大小为64B,则CaChe块字块内地址占6bit,再往前数3位(得到110)即为该物理地址对应的组号,找到对应的分组号后,找到分组中相匹配的CaChe标记,若其有效位为1,则表示CaChe命中。
这里成功找到对应的记录,我们亦拿到了其对应的主存的数据副本。
四.慢表与快表
1.慢表:
-
慢表和段表都是存放在主存中的。
-
当收到虚拟地址后,操作系统首先要访问主存,查询页表或段表,以进行虚实地址转换。
-
慢表的访问速度较慢,因为它需要从主存中获取数据。
-
每个进程对应一个页表
2.快表:
-
快表是一种高速缓冲存储器,用于存放常用的页表项。
-
它提高了变换速度,因为它存储了当前访问的一部分页表项。
-
快表的访问速度比慢表快得多
3.辨析快表与Cache的联系与区别:
快表用于虚拟存储技术,加快辅存(主存与辅助存储器)之间的地址映射速度,通常集成在CPU内部,由于存储在CPU内部,访问速度非常快 。
而Cache是为了解决CPU与主存速度不匹配的问题,它存放的事 存放最近访问的数据块,以减少对主存的频繁访问。
五.地址映射方式
当谈到高速缓存存储器(Cache)中的地址映射方式时,我们通常会遇到三种不同的方式:全相联映射、组相连映射和直接映射。
全相联映射
主存中的任意一个块可以映射到Cache中的任意一行中。
Cache中的每一行需要增加一个标记部分,用于存放该行内容的主存块的块号。
评价:灵活性好, 要Cache中有空行,就可以调入所需的主存数据块 。但因为存在一个标志位,导致利用效率不高。另每次 访问Cache时,需要遍历并比较标记,才能判断所需主存的字块是否在Cache中 ,即速度较慢。
组相连映射
每个主存块只能复制到Cache中的一个特定行中
映射关系: 主存块号对Cache总行数取模,计算出主存块在Cache中存放的位置 。
评价:这种方式灵活性差,每个主存块只有一个固定的行可以存放,容易发生冲突,频繁替换,效率降低。
直接映射
主存块号对Cache中有多少组取模,计算出主存块在Cache中存放的组,然后在组内可以随意放。
评价:组内有一定的灵活性,空间利用率较高,是全相联和直接映射的折中方案。















 4827
4827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









